一种基于层叠隐马尔科夫的人名识别方法及系统
1.本发明涉及人名识别技术领域,特别是涉及一种基于层叠隐马尔科夫的人名识别方法及系统。
背景技术:
2.人名属于未登录词的重点组成部分,也是主要难点,准确识别未登录词能为自然语言处理系统的性能带来极大提升。单纯基于机器学习的方法需要一个标注了词性的语料库去训练模型,而再庞大的语料库也无法覆盖所有的姓名,人名成员时常与周围其他字词组成新词而被错误切分,或与上下文连接在一起,识别精度不尽人意。
3.因此,亟需提出一种能够准确识别人名的方法及系统。
技术实现要素:
4.本发明的目的是提供一种基于层叠隐马尔科夫的人名识别方法及系统,以提高对人名识别的准确性。
5.为实现上述目的,本发明提供了如下方案:
6.一种基于层叠隐马尔科夫的人名识别方法,所述人名识别方法包括:
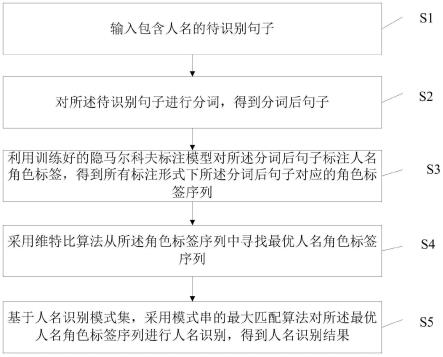
7.输入包含人名的待识别句子;
8.对所述待识别句子进行分词,得到分词后句子;
9.利用训练好的隐马尔科夫标注模型对所述分词后句子标注人名角色标签,得到所有标注形式下所述分词后句子对应的角色标签序列;其中所述人名角色标签根据不同类型的姓名结构、人名中的字与人名相邻上下文的成词关系、相邻人名间的内容以及与人名无关的句子进行设计;
10.采用维特比算法从所述角色标签序列中寻找最优人名角色标签序列;
11.基于人名识别模式集,采用模式串的最大匹配算法对所述最优人名角色标签序列进行人名识别,得到人名识别结果;其中所述人名识别模式集包括人名标签序列。
12.一种基于层叠隐马尔科夫的人名识别系统,所述人名识别系统包括:
13.输入模块,用于输入包含人名的待识别句子;
14.分词模块,用于对所述待识别句子进行分词,得到分词后句子;
15.人名角色标注模块,用于利用训练好的隐马尔科夫标注模型对所述分词后句子标注人名角色标签,得到不同标注形式下分词后句子对应的角色标签序列;其中所述人名角色标签根据不同类型的姓名结构、人名中的字与人名相邻上下文成词关系、相邻人名间的内容以及与人名无关的句子内容进行设计;
16.寻优模块,用于采用维特比算法从所述角色标签序列中寻找最优人名角色标签序列;
17.识别模块,用于基于人名识别模式集,采用模式串的最大匹配算法对所述最优人名角色标签序列进行人名识别,得到人名识别结果,其中所述人名识别模式集包括人名标
进行粗分,得到的粗分结果为“百合/n子
ども
/n
と
/c一緒/vn(百合小孩在一起)”,该粗分过程并未识别出百合子这个人名,因此需要对粗分结果进一步识别,即:
31.s3:利用训练好的隐马尔科夫标注模型对所述分词后句子标注人名角色标签,得到所有标注形式下所述分词后句子对应的角色标签序列;由于不同类型的姓名结构不同,因而识别不同语言的人名需针对不同的姓名结构设计不同的人名角色标签,优选地所述人名角色标签可以根据不同类型的姓名结构、人名中的字与人名相邻上下文的成词关系、相邻人名间的内容以及与人名无关的句子进行设计。
32.以识别日文人名为例,设计的角色标签如表1所示,所述人名角色标包括人名首字标签a、人名中字标签b、人名末字标签c、单名标签d、名后缀标签e、人名上文标签f、人名下文标签g、相邻人名间内容标签h、人名相邻上文与人名首字成词标签i、人名相邻下文与人名末字成词标签j、人名首字与人名中字成词标签k、人名中字与人名末字成词标签l以及与人名无关标签o。
33.表1日本人名的角色标签构成表
[0034][0035]
其中s3具体包括:
[0036]
(1)利用所述训练好的隐马尔科夫标注模型计算所述角色标签序列与所述分词后句子的联合概率;
[0037]
(2)利用维特比算法寻找所述联合概率最大的所述角色标签序列;
[0038]
(3)将所述联合概率最大的所述角色标签序列作为所述最优人名角色标签序列。
[0039]
s4:采用维特比算法从所述角色标签序列中寻找最优人名角色标签序列。
[0040]
为了本领域技术人员更清楚地了解s3和s4的具体过程,下述进行阐释。
[0041]
设s是利用jieba分词工具粗分后的日语token序列,即分词后句子,w是s所有可能
的人名角色标签标注情况,即所有所有标注形式下所述分词后句子对应的角色标签序列,w
*
为最优人名角色标签序列,只要能求出条件概率p(w|s)的最大值,就能获得想要的最优人名角色标签序列w
*
。s、w、w
*
分别表示为:
[0042]
s=(s1,s2,...,sm),m>0,
[0043]
w=(w1,w2,...,wm),m>>0,
[0044][0045]
其中,s1表示所述分词句子中被粗分开的第一个字词;sm表示所述分词句子中被粗分开的第m个字词;w1表示第一个人名角色标签;wm表示第m个人名角色标签;表示第一个字词最正确的人名角色标签;表示第m个字词最正确的人名角色标签。
[0046]
根据贝叶斯公式,w
*
式中的条件概率p(w|s)有:
[0047]
p(w|s)=p(w,s)/p(s)=p(w)
×
p(s|w)/p(s)
[0048]
对于一个特定的句子s来说,概率p(s)是一个常数,因此根据上式可得最优角色标签序列w
*
:
[0049][0050]
此时利用上文中训练好的隐马尔科夫标注模型来计算上式中的p(w)p(s|w),即token序列s和角色标签序列w的联合概率,为
[0051][0052]
所以可得最优角色标签序列w
*
为
[0053][0054]
使用经典的维特比算法进行动态规划,求解出上式最优解的角色标签序列,即w
*
。
[0055]
s5:基于人名识别模式集,采用模式串的最大匹配算法对所述最优人名角色标签序列进行人名识别,得到人名识别结果;其中所述人名识别模式集包括人名标签序列。
[0056]
例如句子“百合子
どもと
一緒(与百合子等人一起)”,标注后的最优人名角色标签序列为abcgoo(百/a合/b子/c
ども
/g
と
/o一緒/o),此时通过模式串的最大匹配算法,识别出人名角色标签abc为人名,即百合子。
[0057]
作为一种可选的实施方式,在s2之后,所述人名识别方法还包括:对隐马尔科夫标注模型进行训练;其中对所述隐马尔科夫标注模型的训练过程,具体包括:
[0058]
(1)将熟语料库中的词性标签转化为所述人名角色标签,得到人名角色标签语料库。
[0059]
准备标注好了词性标签的熟语料库,以日文为例,如edr
コーパス
、日本語話
し
言葉
コーパス
(csj),对熟语料库进行标签转换,即将语料库原本的词性标签(词性标签包括动词、区别词、连词、人名、机构名等几十种)转化为人名角色标签,人名角色标签可以如表1所示进行设计。
[0060]
将词性标签转化为所述人名角色标签,得到人名角色标签语料库,具体过程如下:
[0061]
①
根据词性标签中的/nf(姓氏标签)、/nl(人名标签)定位出人名后,将人名以外的词的标签替换成与人名无关标签o(代表不相关的角色),并将人名切分成粒状,本实施例中姓氏与名字可统一视作人名分别处理。
[0062]
②
判断所述人名的相邻上文m与所述人名的首字n是否形成词语mn(该词语会误导分词器,造成错误切分);如果m与n形成词语mn,则将词语mn标注为所述人名相邻上文与人名首字成词标签i,否则将m标记为所述人名上文标签f(若m原来标注的角色是o)或所述相邻人名间内容标签h(若m原来标注的是g)。
[0063]
③
判断所述人名的末字p与所述人名的相邻下文q是否形成词语pq;如果p和q形成词语pq,则将词语pq标注为所述人名相邻下文与人名末字成词标签j,否则将q标为所述人名下文标签g。
[0064]
④
根据上面表1中人名的类别,分别将人名的首字、中字、末字、单字和姓名后缀相应地标注为角色标签所述人名首字标签a、所述人名中字标签b、所述人名末字标签c、所述单名标签d和所述名后缀标签e。内部成词的情况,即将所述首字和所述中字组成的词语标注为所述人名首字与人名中字成词标签k,将所述中字和所述末字组成的词语标注为所述人名中字与人名末字成词标签l。
[0065]
⑤
在每句语料开头和结尾添加上始##始和末##末这两个特殊单词,即开始标签r和停止标签s。
[0066]
(2)剔除所述人名角色标签语料库中标注所述与人名无关标签o的单词,得到处理后人名角色标签语料库。
[0067]
(3)统计所述处理后人名角色标签语料库中每一个单词、每一个单词对应的所述人名角色标签以及每一所述人名角色标签出现的频次,得到人名识别词典。
[0068]
假设语料库中只有“百合子
どもと
一緒(与百合子等人一起)”一句语料,那么词典将如表2所示。
[0069]
表2日本人名识别词典
[0070][0071]
(4)统计每一个所述人名角色标签的转移频次c(t
i-1
,ti),得到转移频次矩阵;其中所述转移频次是指任意一个所述人名角色标签的下一个所述人名角色标签是指定所述人名角色标签的次数,例如标签d的下一个标签出现e的次数;
[0072]
(5)根据所述人名识别词典和所述转移频次矩阵计算所述隐马尔科夫标注模型的
三元组参数;所述三元组参数包括转移概率矩阵、发射概率矩阵和初始状态概率向量。
[0073]
①
转移概率矩阵的估计
[0074]
根据隐马尔科夫中和转移概率相关的假设理论,ti的状态仅仅取决于t
i-1
,时的状态。
[0075]
该理论在本实施例的实际意义中,ti指句子中的某一人名角色标签,转移概率表示的是一个人名角色标签的下一个人名角色标签是某个人名角色标签的概率。那么人名角色标签之间的转移概率可以构成一个n
×
n的概率方阵,称为转移概率矩阵:
[0076]
[p(ti|t
i-1
)]n×n[0077]
根据极大似然估计,该概率矩阵可由以下公式求得
[0078]
p(ti|t
i-1
)≈c(t
i-1
,ti)/c(t
i-1
),i>1
[0079]
其中c(t
i-1
,ti)为人名角色标签t
i-1
的下一个角色是人名角色标签ti的频次,也就是上文提到的转移频次矩阵,c(t
i-1
)为人名角色标签t
i-1
出现的次数。
[0080]
②
发射概率矩阵的估计
[0081]
根据隐马尔科夫中和发射概率相关的假设理论,当前的观测si仅仅取决于当前的状态ti。
[0082]
该理论在本实施例中的实际意义中,ti同样表示人名角色标签,si代表句子序列中的某个单词,发射概率为给定人名角色标签ti的情况下,该单词为si的概率。
[0083]
这个概率的参数向量构成了n
×
m的矩阵,称为发射概率矩阵:
[0084]
[p(si|ti)]n×m[0085]
根据极大似然估计,该概率矩阵可由以下公式求得
[0086]
p(si|ti)≈c(si,ti)/c(ti)
[0087]
c(si,ti)是单词si作为人名角色标签ti出现的频次,这一频次存储于日本人名识别词典中,c(ti)为人名角色标签ti出现的次数。
[0088]
③
初始状态概率向量的估计
[0089]
系统启动时,进入的第一个角色标签t1称为初始状态,可以将这个初始状态的概率看作是转移概率的一种特例,即第一个角色标签t1由始##始(开始标签r)转移而来,因为开始标签r是固定的,它的概率矩阵只有一行,即一个向量,所以从开始标签r标签到t1的标签转移概率只有一行向量。
[0090]
(6)根据所述三元组参数得到所述训练好的隐马尔科夫标注模型。
[0091]
作为另一种可选的实施方式,在s4之后,所述人名识别方法还包括:对所述最优人名角色标签序列中以片段或词语形式存在的所述人名角色标签进行拆分处理,具体地包括:将其中角色标签标注为i的片段mn分裂为fa(若n为人名首字)或fd(若n为单名),将角色标签标注为j的片段pq分裂为cg(若p为人名末字)或dg(若p为单名)。
[0092]
本实施例在分词处理和人名角色标注处理中都由隐马尔科夫模型驱动,因此称为层叠隐马尔科夫。
[0093]
本实施例根据不同语言的人名设计角色构成表,根据构成表实现词性标签的转换,得到人名角色标签语料库;根据人名角色标签语料库训练人名标注模型,即隐马尔科夫标注模型,并通过维特比算法计算出最优人名角色标签序列,模式匹配后得到人名的识别结果。本实施例以层叠隐马尔科夫框架为基础,辅以自定义人名角色标签和维特比算法解
码,提供了一种高效、准确度高的监督学习的人名识别方法,其优点如下:
[0094]
优点1:基于规则的方法和其他传统的机器学习方法缺乏召回未登录词的能力,本层叠隐马尔科夫框架能根据识别字符在构成人名时充当的角色召回日文人名,在未登录词识别上出现了显著效果。
[0095]
优点2:人们根据场景需要不同的角色标注,本实施例定义的日文人名标注集和自动角色标注方法,填补了目前日语人名标签语料的空缺。
[0096]
实施例2:
[0097]
参阅图2,本实施例提供了一种基于层叠隐马尔科夫的人名识别系统,其特征在于,所述人名识别系统包括:
[0098]
输入模块m1,用于输入包含人名的待识别句子;
[0099]
分词模块m2,用于对所述待识别句子进行分词,得到分词后句子;
[0100]
人名角色标注模块m3,用于利用训练好的隐马尔科夫标注模型对所述分词后句子标注人名角色标签,得到不同标注形式下分词后句子对应的角色标签序列;其中所述人名角色标签根据不同类型的姓名结构、人名中的字与人名相邻上下文成词关系、相邻人名间的内容以及与人名无关的句子内容进行设计;
[0101]
寻优模块m4,用于采用维特比算法从所述角色标签序列中寻找最优人名角色标签序列;
[0102]
识别模块m5,用于基于人名识别模式集,采用模式串的最大匹配算法对所述最优人名角色标签序列进行人名识别,得到人名识别结果,其中所述人名识别模式集包括人名标签序列。
[0103]
作为一种可选的实施方式,所述人名识别系统还包括:训练模块,用于对隐马尔科夫标注模型进行训练。
[0104]
本说明书中每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。对于实施例公开的系统而言,由于其与实施例公开的方法相对应,所以描述的比较简单,相关之处参见方法部分说明即可。
[0105]
本文中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想;同时,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处。综上所述,本说明书内容不应理解为对本发明的限制。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1