一种数据库迁移的方法、装置及存储介质与流程
1.本发明涉及数据库领域,尤其是涉及一种数据库迁移的方法、装置及存储介质。
背景技术:
2.数据库作为项目或应用支撑的后端,随着数据的日益增多,往往需要进行数据库迁移。
3.数据库迁移是将数据和对象从一个数据库迁移到另一个数据库的过程,迁移前后的数据一致性稽查是检查迁移是否成功的标志。
4.现有技术中,大多数的数据库稽查都是在数据迁移结束后进行的,这导致整体的稽查时间较长、稽查效率不高,并且需要重复对源端数据进行访问,加重了源端的压力。
5.鉴于此,如何快速、高效、准确的对数据库进行迁移,成为一个亟待解决的技术问题。
技术实现要素:
6.本发明提供一种数据库迁移的方法、装置及存储介质,用以解决现有技术中存在的数据库迁移速度慢、效率低、不够准确的技术问题。
7.第一方面,为解决上述技术问题,本发明实施例提供的一种数据库迁移的方法的技术方案如下:
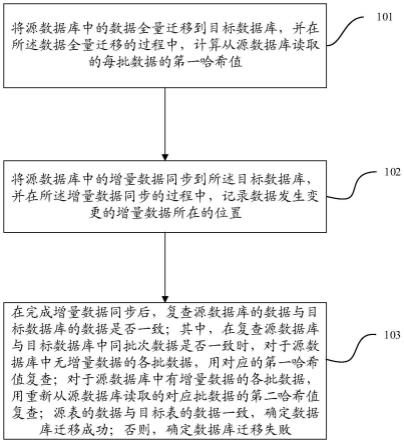
8.将源数据库中的数据全量迁移到目标数据库,并在所述数据全量迁移的过程中,计算从所述源数据库读取的每批数据的第一哈希值;
9.将源数据库中的增量数据同步到所述目标数据库,并在所述增量数据同步的过程中,记录数据发生变更的增量数据所在的位置;
10.在完成所述增量数据同步后,复查所述源数据库的数据与所述目标数据库的数据是否一致;其中,在复查所述源数据库与所述目标数据库中同批次数据是否一致时,对于所述源数据库中无所述增量数据的各批数据,用对应的第一哈希值复查;对于所述源数据库中有所述增量数据的各批数据,用重新从所述源数据库读取的对应批数据的第二哈希值复查;
11.若所述源表的数据与所述目标表的数据一致,确定数据库迁移成功;否则,确定数据库迁移失败。
12.一种可能的实施方式,将源数据库中的数据全量迁移到目标数据库,包括:
13.记录所述源数据库中开始全量迁移的位点信息,并获取对应源数据表的总行数;
14.根据所述总行数及分批大小,将所述源数据表中的数据分为多个批次依次迁移到所述目标数据库中,并在完成所述数据全量迁移后记录所述源数据表中所述数据全量迁移结束的最大主键。
15.一种可能的实施方式,将源数据库中的增量数据同步到所述目标数据库,包括:
16.从所述位点信息对应的位置开始,获取所述源数据表的增量数据,直至所述最大
主键对应的位置;
17.在获取所述增量数据时,确定所述增量数据对应的变更类型是否为数据操作语言类型;若为是,将所述增量数据同步到所述目标数据表中对应位置。
18.一种可能的实施方式,在所述增量数据同步的过程中,记录数据发生变更的增量数据所在的位置,包括:
19.在确定所述增量数据对应的变更类型为所述数据操作语言类型时,进一步确定所述增量数据对应的变更操作是否为更新操作;
20.若确定所述增量数据对应的变更操作为更新操作,则记录所述增量数据变更前后分别对应的批次号;
21.若确定所述增量数据对应的变更操作为插入操作或删除操作,则根据所述增量数据对应的主键,计算并记录对应的批次号,以及行数;
22.对记录的批次号进行去重处理,获得数据发生变更的最终批次号。
23.一种可能的实施方式,复查所述源数据库的数据与所述目标数据库的数据是否一致,包括:
24.判断所述源数据表的总行数与所述目标数据表的总行数是否相同;
25.若所述源数据表的总行数与所述目标数据表的总行数不同,则确定所述源数据库的数据与所述目标数据库的数据不一致;
26.所述源数据表的总行数与所述目标数据表的总行数相同,进一步判断所述源数据表与所述目标数据表中同批次的数据是否相同;
27.若所述源数据表与所述目标数据表中任一同批次的数据不同,则确定所述源数据库的数据与所述目标数据库的数据不一致;
28.若所述源数据表与所述目标数据表中所有同批次的数据相同,则进一步确定所述源数据表与所述目标数据表中记录的相同位置的增量数据是否相同,若所有相同位置的增量数据均相同,则确定所述源数据库的数据与所述目标数据库的数据一致,否则确定源数据库的数据与所述目标数据库的数据不一致。
29.一种可能的实施方式,判断所述源数据表的总行数与所述目标数据表的总行数是否相同,包括:
30.获取所述数据全量迁移过程中迁移数据的第一总行数,以及所述数据增量同步过程中插入和删除分别对应的增量数据的第二总行数和第三总行数;
31.对所述第一总行数与所述第二总行数的和值与所述第三总行数进行差运算,获得所述源数据表的总行数;
32.对所述源数据表的总行数与所述目标数据表的总行数进行差运算,获得差运算结果;若所述差运算结果为0,则确定所述源数据表的总行数与所述目标数据表的总行数相同,否则确定所述源数据表的总行数与所述目标数据表的总行数不同。
33.一种可能的实施方式,判断所述源数据表与所述目标数据表中同批次的数据是否相同,包括:
34.计算所述目标数据库中每批数据的第三哈希值;
35.从所述源数据库中重新获取每个所述最终批次号对应的一批数据,并进行哈希计算,获得对应的第二哈希值;
36.对于所述源数据库中无所述增量数据的各批数据,判断对应批数据的第一哈希值与所述目标数据库中同批次的第三哈希值是否相同,若相同确定所述源数据库与所述目标数据库对应的同批数据相同,否则确定不同;
37.对于所述源数据库中每个所述最终批次号对应的一批数据,判断对应的第二哈希值与所述目标数据库中同批次的第三哈希值是否相同,若相同确定所述源数据库与所述目标数据库对应的同批次数据相同,否则确定不同。
38.第二方面,本发明实施例提供了一种数据库迁移的装置,包括:
39.全量迁移及稽查单元,用于将源数据库中的数据全量迁移到目标数据库,并在所述数据全量迁移的过程中,计算从所述源数据库读取的每批数据的第一哈希值;
40.增量同步单元,用于将源数据库中的增量数据同步到所述目标数据库,并在所述增量数据同步的过程中,记录数据发生变更的增量数据所在的位置;
41.复查单元,用于在完成所述增量数据同步后,复查所述源数据库的数据与所述目标数据库的数据是否一致;其中,在复查所述源数据库与所述目标数据库中同批次数据是否一致时,对于所述源数据库中无所述增量数据的各批数据,用对应的第一哈希值复查;对于所述源数据库中有所述增量数据的各批数据,用重新从所述源数据库读取的对应批数据的第二哈希值复查;若所述源表的数据与所述目标表的数据一致,确定数据库迁移成功;否则,确定数据库迁移失败。
42.一种可能的实施方式,所述全量迁移及稽查单元还用于:
43.记录所述源数据库中开始全量迁移的位点信息,并获取对应源数据表的总行数;
44.根据所述总行数及分批大小,将所述源数据表中的数据分为多个批次依次迁移到所述目标数据库中,并在完成所述数据全量迁移后记录所述源数据表中所述数据全量迁移结束的最大主键。
45.一种可能的实施方式,所述增量同步单元还用于:
46.从所述位点信息对应的位置开始,获取所述源数据表的增量数据,直至所述最大主键对应的位置;
47.在获取所述增量数据时,确定所述增量数据对应的变更类型是否为数据操作语言类型;若为是,将所述增量数据同步到所述目标数据表中对应位置。
48.一种可能的实施方式,所述增量同步单元还用于:
49.在确定所述增量数据对应的变更类型为所述数据操作语言类型时,进一步确定所述增量数据对应的变更操作是否为更新操作;
50.若确定所述增量数据对应的变更操作为更新操作,则记录所述增量数据变更前后分别对应的批次号;
51.若确定所述增量数据对应的变更操作为插入操作或删除操作,则根据所述增量数据对应的主键,计算并记录对应的批次号,以及行数;
52.对记录的批次号进行去重处理,获得数据发生变更的最终批次号。
53.一种可能的实施方式,所述复查单元还用于:
54.判断所述源数据表的总行数与所述目标数据表的总行数是否相同;
55.若所述源数据表的总行数与所述目标数据表的总行数不同,则确定所述源数据库的数据与所述目标数据库的数据不一致;
56.所述源数据表的总行数与所述目标数据表的总行数相同,进一步判断所述源数据表与所述目标数据表中同批次的数据是否相同;
57.若所述源数据表与所述目标数据表中任一同批次的数据不同,则确定所述源数据库的数据与所述目标数据库的数据不一致;
58.若所述源数据表与所述目标数据表中所有同批次的数据相同,则进一步确定所述源数据表与所述目标数据表中记录的相同位置的增量数据是否相同,若所有相同位置的增量数据均相同,则确定所述源数据库的数据与所述目标数据库的数据一致,否则确定源数据库的数据与所述目标数据库的数据不一致。
59.一种可能的实施方式,所述复查单元还用于:
60.获取所述数据全量迁移过程中迁移数据的第一总行数,以及所述数据增量同步过程中插入和删除分别对应的增量数据的第二总行数和第三总行数;
61.对所述第一总行数与所述第二总行数的和值与所述第三总行数进行差运算,获得所述源数据表的总行数;
62.对所述源数据表的总行数与所述目标数据表的总行数进行差运算,获得差运算结果;若所述差运算结果为0,则确定所述源数据表的总行数与所述目标数据表的总行数相同,否则确定所述源数据表的总行数与所述目标数据表的总行数不同。
63.一种可能的实施方式,所述复查单元用于:
64.计算所述目标数据库中每批数据的第三哈希值;
65.从所述源数据库中重新获取每个所述最终批次号对应的一批数据,并进行哈希计算,获得对应的第二哈希值;
66.对于所述源数据库中无所述增量数据的各批数据,判断对应批数据的第一哈希值与所述目标数据库中同批次的第三哈希值是否相同,若相同确定所述源数据库与所述目标数据库对应的同批数据相同,否则确定不同;
67.对于所述源数据库中每个所述最终批次号对应的一批数据,判断对应的第二哈希值与所述目标数据库中同批次的第三哈希值是否相同,若相同确定所述源数据库与所述目标数据库对应的同批次数据相同,否则确定不同。
68.第三方面,本发明实施例还提供一种数据库迁移的装置,包括:
69.至少一个处理器,以及
70.与所述至少一个处理器连接的存储器;
71.其中,所述存储器存储有可被所述至少一个处理器执行的指令,所述至少一个处理器通过执行所述存储器存储的指令,执行如上述第一方面所述的方法。
72.第四方面,本发明实施例还提供一种可读存储介质,包括:
73.存储器,
74.所述存储器用于存储指令,当所述指令被处理器执行时,使得包括所述可读存储介质的装置完成如上述第一方面所述的方法。
75.通过本发明实施例的上述一个或多个实施例中的技术方案,本发明实施例至少具有如下技术效果:
76.在本发明提供的实施例中,通过将源数据库中的数据全量迁移到目标数据库,并在数据全量迁移的过程中,计算从源数据库读取的每批数据的第一哈希值;以及在完成全
量迁移后,将源数据库中的增量数据同步到目标数据库,并在增量数据同步的过程中,记录数据发生变更的增量数据所在的位置;在完成增量数据同步后,复查源数据库的数据与目标数据库的数据是否一致;其中,在复查源数据库与目标数据库中同批次数据是否一致时,对于源数据库中无增量数据的各批数据,用对应的第一哈希值复查;对于源数据库中有增量数据的各批数据,用重新从源数据库读取的对应批数据的第二哈希值复查;若源表的数据与目标表的数据一致,确定数据库迁移成功;否则,确定数据库迁移失败;从而实现迁移的过程中为后续复查提前做一部分工作,在全量迁移及增量同步完成后复查源数据表与目标数据表迁移的数据是否一致,其中在进行同批数据复查的过程中对于有数据变化的源数据库中的一批数据进行重新读取及计算,这样就不要对源数据库中所有批数据进行重新计算,若复查结果不一致也只需重新迁移不一致的这一部分数据,进而能够有效的缩短整体的迁移、复查时间、提高迁移的准确率、迁移的速度以及迁移效率,这样对于源数据库中的大部分数据而言多数只需访问一次,当源数据库中的数据存在热点数据时,能够极大的提高稽查效率及迁移效率。
附图说明
77.图1为本发明实施例提供的一种数据库迁移方法的流程图;
78.图2为本发明实施例提供的一种全量迁移的流程图;
79.图3为本发明实施例提供的一种增量同步的流程图;
80.图4为本发明实施例提供的一种复查迁移前后数据的流程图;
81.图5为本发明实施例提供的一种数据库迁移装置的结构示意图。
具体实施方式
82.本发明实施列提供一种数据库迁移的方法、装置及存储介质,用以解决现有技术中存在的数据库迁移速度慢、效率低、不够准确的技术问题。
83.为了更好的理解上述技术方案,下面通过附图以及具体实施例对本发明技术方案做详细的说明,应当理解本发明实施例以及实施例中的具体特征是对本发明技术方案的详细的说明,而不是对本发明技术方案的限定,在不冲突的情况下,本发明实施例以及实施例中的技术特征可以相互组合。
84.请参考图1,本发明实施例提供一种数据库迁移的方法,该方法的处理过程如下。
85.步骤101:将源数据库中的数据全量迁移到目标数据库,并在所述数据全量迁移的过程中,计算从源数据库读取的每批数据的第一哈希值。
86.将源数据库中的数据全量迁移到目标数据库,可以通过下列方式实现:
87.记录源数据库中开始全量迁移的位点信息,并获取对应源数据表的总行数;根据总行数及分批大小,将源数据表中的数据分为多个批次依次迁移到目标数据库中,并在完成数据全量迁移后记录源数据表中数据全量迁移结束的最大主键。
88.例如,源数据库中需要将位点1开始的数据迁移到目标数据库中,便将位点1记录为源数据库中开始全量迁移的位点信息,源数据库中位点1对应的数据表为源数据表,获取源数据表的总行数(假设为5000),分批大小为1000,则可以将源数据表的数据分为5个批次:批次1对应数据的主键为[1,1000],批次2对应数据的主键为[1001,2000],批次3对应数
据的主键为[2001,3000],批次4对应数据的主键为[3001,4000],批次5对应的数据的主键为[4001,5000],逐批次迁移对应批次的数据,直至完成最后一个批次的数据迁移,在将源数据表中最后一个批次的最后一行数据迁移到目标数据表后,将最后一个批次的最后一行数据的主键记录为最大主键。
[0089]
需要理解的是,在进行源数据表的全量迁移的过程中,可以能有数据插入、删除等,使得源数据表中数据全量迁移结束时的最大主键并非初次统计的总行数。
[0090]
在数据全量迁移的过程中,还需要计算从源数据库读取的每批数据的第一哈希值,以备后续复查使用。
[0091]
在一些实施例中,在数据全量迁移的过程中,计算从源数据库读取的每批数据的第一哈希值,可以通过下列方式实现:
[0092]
在迁移每批数据的过程中,将从源数据表中读取的每批数据拼接为第一字符串,并对第一字符串进行哈希计算,获得第一哈希值。
[0093]
例如,源数据表具有3个字段(对应3列),在源数据表被分为5个批次,每个批次有1000行数据,在从源数据表中每读取一个批次的1000行数据,便将这1000行数据拼接为第一字符串,并对此第一字符串进行哈希计算得到第一哈希值。
[0094]
请参见图2为本发明实施例提供的一种全量迁移的流程图。
[0095]
步骤201:记录源数据库中迁移起始位置的位点信息,获取源数据表的总行数;
[0096]
步骤202:逐批读取数据,将读取的一批数据拼接为第一字符串,并计算第一哈希值;
[0097]
步骤203:将读取的一批数据插入目标数据表;
[0098]
步骤204:判断全量迁移是否结束;
[0099]
可以通过判断当前完成全量迁移的一批数据的批次号是否为最大批次,若为最大批次号,则确定全量迁移结束,执行步骤205;若当前完成全量迁移的一批数据的批次号小于最大批次号,则确定全量迁移未结束,执行步骤202。
[0100]
步骤205:记录全量迁移结束的最大主键。
[0101]
全量迁移源数据表中其它行的数据可以依次类推,在此不再赘述,当将源数据表中最后一个批次中最后一行的数据迁移到目标数据表后,便可执行步骤102。
[0102]
步骤102:将源数据库中的增量数据同步到所述目标数据库,并在增量数据同步的过程中,记录数据发生变更的增量数据所在的位置。
[0103]
在一些实施例中,将源数据库中的增量数据同步到所述目标数据库,可以通过下列方式实现:
[0104]
从位点信息对应的位置开始,获取源数据表的增量数据,直至最大主键对应的位置;在获取增量数据时,确定增量数据对应的变更类型是否为数据操作语言(data manipulation language,dml)类型;若为是,将增量数据同步到目标数据表中对应位置。
[0105]
在确定增量数据对应的变更类型是否为dml类型之前,还可以解析增量数据。增量数据对应的变更类型包括dml类型、数据定义语言(data definition language,ddl)类型,在数据迁移的过程中默认不支持ddl类型。
[0106]
例如,源数据表的数据被分为5个批次,在批次3的数据全量迁移的过程中在源数据表中批次1中3行插入了一行数据,在批次5的数据全量迁移的过程中,批次3中第8行的数
据被删除、批次4中第6行的数据发生了更改。
[0107]
在完成上述5个批次的数据全量迁移(对应的最大主键为5000)后,从位点信息对应的位置开始,获取源数据表的增量数据,可以获取到批次1中第3行数据为增量数据、批次3中第8行为增量数据,批次4中第6行数据为增量数据,当到达最大主键5000时停止获取。由于上述插入、删除、修改郡守dml类型,因此确定上述增量数据对应的变更类型为dml类型,进而可以将上述增量数据同步到目标数据表中。若确定上述增量数据的变更类型不是dml类型,如为ddl类型,则放弃同步。
[0108]
在一些实施例中,在增量数据同步的过程中,记录数据发生变更的增量数据所在的位置,可以通过下列方式实现:
[0109]
在确定增量数据对应的变更类型为数据操作语言类型时,进一步确定增量数据对应的变更操作是否为更新操作;若确定增量数据对应的变更操作为更新操作,则记录增量数据变更前后分别对应的批次号;若确定增量数据对应的变更操作为插入操作或删除操作,则根据增量数据对应的主键,计算并记录对应的批次号,以及行数;对记录的批次号进行去重处理,获得数据发生变更的最终批次号。
[0110]
例如,确定源数据表中批次1中第3行数据为增量数据,且属于dml类型,进一步又确定此增量数据发生的是插入操作,此时记录此增量数据对应的主键及批次号、所在行数(即增量数据所在的位置);并根据上述增量数据所在的位置,将增量数据同步到目标数据表中。
[0111]
确定源数据表中批次3中第8行为增量数据,且属于dml类型,进一步又确定此增量数据发生的是删除操作,此时记录此增量数据对应的主键及批次号、所在行数(即增量数据所在的位置);并根据上述增量数据所在的位置,将增量数据同步到目标数据表中。
[0112]
确定源数据表中批次4中第6行数据为增量数据,且属于dml类型,进一步又确定此增量数据发生的是更改数据,即通过更新操作发生了改变,此时需要记录此增量数据变更前后分别对应的批次号(即此增量数据所在的位置),并根据上述增量数据所在的位置,将增量数据同步到目标数据表中。
[0113]
当达到最大主键后,完成增量数据的同步。
[0114]
最后,对记录的增量数据对应的批次号进行去重,获得数据发生变更的最终批次号。
[0115]
若在全量迁移的过程中,还在最大主键之后产生了增量数据,则暂不进行同步,而是在后续复查阶段进行同步,具体见后续介绍。
[0116]
请参见图3为本发明实施例提供的一种增量同步的流程图。
[0117]
步骤301:获取增量数据;
[0118]
步骤302:判断是否为dml类型;
[0119]
若为是执行步骤303。
[0120]
步骤303:判断增量数据对应的主键是否小于或等于最大主键;
[0121]
增量数据对应的主键小于或等于最大主键说明增量数据是在最大主键对应的数据前发生变更的,即确定增量数据对应的主键小于或等于最大主键,执行步骤304;增量数据对应的主键大于最大主键说明增量数据是在最大主键对应的数据后发生变更的,即确定增量数据对应的主键大于最大主键时,暂不处理,而是在后续的复查过程中进行处理。
[0122]
步骤304:判断是否为更新操作;
[0123]
判断增量数据是否为更新操作产生的,若为是执行步骤305b,若为否执行步骤305a。
[0124]
步骤305a:根据增量数据对应的主键计算并记录对应的批次号,并记录插入或删除的行数;
[0125]
步骤305b:根据增量数据变更前后分别对应的主键,计算并记录对应的两个批次号;
[0126]
执行完步骤305a或步骤305b后便可执行步骤306。
[0127]
步骤306:判断增量同步是否结束;
[0128]
若为是执行步骤307,若为否执行步骤301。
[0129]
步骤307:对记录的批次号去重。
[0130]
在完成增量数据的同步后,便可执行步骤103。
[0131]
步骤103:在完成增量数据同步后,复查源数据库的数据与目标数据库的数据是否一致;其中,在复查源数据库与目标数据库中同批次数据是否一致时,对于源数据库中无增量数据的各批数据,用对应的第一哈希值复查;对于源数据库中有增量数据的各批数据,用重新从源数据库读取的对应批数据的第二哈希值复查;若源表的数据与目标表的数据一致,确定数据库迁移成功;否则,确定数据库迁移失败。
[0132]
在完成全量迁移和增量迁移后,获取源数据表的总行数与目标数据表的总行数,并判断它们的总行数是否相同,若不同确定源数据库的数据与目标数据库的数据不一致,迁移失败。
[0133]
在一些实施例中,判断所述源数据表的总行数与所述目标数据表的总行数是否相同,可以通过下列方式实现:
[0134]
获取数据全量迁移过程中迁移数据的第一总行数,以及数据增量同步过程中插入和删除分别对应的增量数据的第二总行数和第三总行数;对第一总行数与第二总行数的和值与第三总行数进行差运算,获得源数据表的总行数;对源数据表的总行数与目标数据表的总行数进行差运算,获得差运算结果;若差运算结果为0,则确定源数据表的总行数与目标数据表的总行数相同,否则确定源数据表的总行数与目标数据表的总行数不同。
[0135]
如在全量迁移过程中,总共迁移了m行数据,则第一总行数为m,在增量同步过程中,总共插入了n行数据、删除了n行数据,则第二总行数为n,第三总行数为n,进而可以计算出源数据表的总行数为m+n-n;目标数据表的总行数可以直接从目标数据表中读出,这样通过计算源数据表的总行数与目标数据表的总行数的差值,就能判断出它们的总行数是否相同,即差值为0说明它们的总行数相同,否则说明它们的总行不同。
[0136]
若源数据表的总行数与目标数据表的总行数相同,则进一步判断源数据表与目标数据表中同批次的数据是否相同,具体可以通过下列方式实现:
[0137]
计算目标数据库中每批数据的第三哈希值;从源数据库中重新获取每个最终批次号对应的一批数据,并进行哈希计算,获得对应的第二哈希值;对于源数据库中无增量数据的各批数据,判断对应批数据的第一哈希值与目标数据库中同批次的第三哈希值是否相同,若相同确定源数据库与目标数据库对应的同批数据相同,否则确定不同;对于源数据库中每个最终批次号对应的一批数据,判断对应的第二哈希值与目标数据库中同批次的第三
哈希值是否相同,若相同确定源数据库与目标数据库对应的同批次数据相同,否则确定不同。
[0138]
上述计算第二哈希值、第三哈希值的方式与前述计算第一哈希值的方式相同,在此不再赘述。在上述判断同批次数据是否相同的过程中,若其中任一同批次的数据的判断结果为不同,便确定源数据库与目标数据库的数据不一致,迁移失败;
[0139]
若确定源数据表与目标数据表中所有同批次的数据相同,则进一步判断前述记录的源数据表与目标数据表中相同位置的增量数据是否相同,若所有相同位置的增量数据均相同,则确定源数据库的数据与目标数据库的数据一致,迁移成功,否则确定迁移失败。
[0140]
若在最大主键后有增量数据,则将最大主键后的数据分批,并迁移到目标数据表中,对这些新迁入的各批数据进行复查,如计算源数据表和目标数据表中同批次的数据的哈希值,通过判断它们的哈希值是否相同,确定对应批次的数据是否正确迁移。
[0141]
请参见图4为本发明实施例提供的一种复查迁移前后数据的流程图。
[0142]
步骤401:获取源数据表的总行数和目标数据表的总行数;
[0143]
步骤402:判断源数据表的总行数与目标数据表的总行数是否相等;
[0144]
若相等,执行步骤403,若不相等,执行步骤410b。
[0145]
步骤403:从目标数据表依次获取各批次的数据,并计算对应批次的哈希值;
[0146]
对目标数据表中各批此的数据进行哈希计算得到的哈希值为第三哈希值;
[0147]
步骤404:判断当前获得的一批数据在增量同步中是否有变更;
[0148]
若有变更,则执行步骤405,若无则执行步骤406。
[0149]
步骤405:重新从源数据表获取该批数据,并计算哈希值;
[0150]
重新获取的这批数据计算的哈希值为第二哈希值;将之作为与目标数据表进行比较的哈希值。
[0151]
步骤406:判断源数据表和目标数据表中该批数据的哈希值是否相等;
[0152]
若执行了步骤405则用第二哈希值与第三哈希值比,若没执行步骤405则用在数据全量迁移过程中计算出的源数据表对应批数据的第一哈希值,与第三哈希值进行比较。
[0153]
若相等,则执行步骤407,若不相等,则执行步骤410b。
[0154]
步骤407:判断是否所有批次都完成复查;
[0155]
根据当前复查完的批次号是否等于最大批次号,确定是否所有批次都复查完,若当前复查完的批次号等于最大批次号,确定所有批次都复查完,执行步骤408;若当前复查完的批次号小于最大批次号,确定未复查完所有批次,执行步骤403。
[0156]
步骤408:对主键大于最大主键的增量数据进行分批,并计算对应的哈希值;
[0157]
步骤409:判断在源数据表和目标数据表中新分批的数据对应的哈希值是否相同;
[0158]
若相同,执行步骤410a,若不同执行步骤410b。
[0159]
步骤410a:一致;
[0160]
步骤410b:不一致。
[0161]
在本发明提供的实施例中,通过将源数据库中的数据全量迁移到目标数据库,并在数据全量迁移的过程中,计算从源数据库读取的每批数据的第一哈希值;以及在完成全量迁移后,将源数据库中的增量数据同步到目标数据库,并在增量数据同步的过程中,记录数据发生变更的增量数据所在的位置;在完成增量数据同步后,复查源数据库的数据与目
标数据库的数据是否一致;其中,在复查源数据库与目标数据库中同批次数据是否一致时,对于源数据库中无增量数据的各批数据,用对应的第一哈希值复查;对于源数据库中有增量数据的各批数据,用重新从源数据库读取的对应批数据的第二哈希值复查;若源表的数据与目标表的数据一致,确定数据库迁移成功;否则,确定数据库迁移失败;从而实现迁移的过程中为后续复查提前做一部分工作,在全量迁移及增量同步完成后复查源数据表与目标数据表迁移的数据是否一致,其中在进行同批数据复查的过程中对于有数据变化的源数据库中的一批数据进行重新读取及计算,这样就不要对源数据库中所有批数据进行计算,若复查结果不一致也只需重新迁移不一致的这一部分数据,进而能够有效的缩短整体的迁移、复查时间、提高迁移的准确率、迁移的速度以及迁移效率,这样对于源数据库中的大部分数据而言多数只需访问一次,当源数据库中的数据存在热点数据时,能够极大的提高稽查效率及迁移效率。
[0162]
基于同一发明构思,本发明一实施例中提供一种数据库迁移的装置,该装置的数据库迁移方法的具体实施方式可参见方法实施例部分的描述,重复之处不再赘述,请参见图5,该装置包括:
[0163]
全量迁移单元501,用于将源数据库中的数据全量迁移到目标数据库,并在所述数据全量迁移的过程中,计算从所述源数据库读取的每批数据的第一哈希值;
[0164]
增量同步单元502,用于将源数据库中的增量数据同步到所述目标数据库,并在所述增量数据同步的过程中,记录数据发生变更的增量数据所在的位置;
[0165]
复查单元503,用于在完成所述增量数据同步后,复查所述源数据库的数据与所述目标数据库的数据是否一致;其中,在复查所述源数据库与所述目标数据库中同批次数据是否一致时,对于所述源数据库中无所述增量数据的各批数据,用对应的第一哈希值复查;对于所述源数据库中有所述增量数据的各批数据,用重新从所述源数据库读取的对应批数据的第二哈希值复查;若所述源表的数据与所述目标表的数据一致,确定数据库迁移成功;否则,确定数据库迁移失败。
[0166]
一种可能的实施方式,所述全量迁移单元501还用于:
[0167]
记录所述源数据库中开始全量迁移的位点信息,并获取对应源数据表的总行数;
[0168]
根据所述总行数及分批大小,将所述源数据表中的数据分为多个批次依次迁移到所述目标数据库中,并在完成所述数据全量迁移后记录所述源数据表中所述数据全量迁移结束的最大主键。
[0169]
一种可能的实施方式,所述增量同步单元502还用于:
[0170]
从所述位点信息对应的位置开始,获取所述源数据表的增量数据,直至所述最大主键对应的位置;
[0171]
在获取所述增量数据时,确定所述增量数据对应的变更类型是否为数据操作语言类型;若为是,将所述增量数据同步到所述目标数据表中对应位置。
[0172]
一种可能的实施方式,所述增量同步单元502还用于:
[0173]
在确定所述增量数据对应的变更类型为所述数据操作语言类型时,进一步确定所述增量数据对应的变更操作是否为更新操作;
[0174]
若确定所述增量数据对应的变更操作为更新操作,则记录所述增量数据变更前后分别对应的批次号;
[0175]
若确定所述增量数据对应的变更操作为插入操作或删除操作,则根据所述增量数据对应的主键,计算并记录对应的批次号,以及行数;
[0176]
对记录的批次号进行去重处理,获得数据发生变更的最终批次号。
[0177]
一种可能的实施方式,所述复查单元503还用于:
[0178]
判断所述源数据表的总行数与所述目标数据表的总行数是否相同;
[0179]
若所述源数据表的总行数与所述目标数据表的总行数不同,则确定所述源数据库的数据与所述目标数据库的数据不一致;
[0180]
所述源数据表的总行数与所述目标数据表的总行数相同,进一步判断所述源数据表与所述目标数据表中同批次的数据是否相同;
[0181]
若所述源数据表与所述目标数据表中任一同批次的数据不同,则确定所述源数据库的数据与所述目标数据库的数据不一致;
[0182]
若所述源数据表与所述目标数据表中所有同批次的数据相同,则进一步确定所述源数据表与所述目标数据表中记录的相同位置的增量数据是否相同,若所有相同位置的增量数据均相同,则确定所述源数据库的数据与所述目标数据库的数据一致,否则确定源数据库的数据与所述目标数据库的数据不一致。
[0183]
一种可能的实施方式,所述复查单元503还用于:
[0184]
获取所述数据全量迁移过程中迁移数据的第一总行数,以及所述数据增量同步过程中插入和删除分别对应的增量数据的第二总行数和第三总行数;
[0185]
对所述第一总行数与所述第二总行数的和值与所述第三总行数进行差运算,获得所述源数据表的总行数;
[0186]
对所述源数据表的总行数与所述目标数据表的总行数进行差运算,获得差运算结果;若所述差运算结果为0,则确定所述源数据表的总行数与所述目标数据表的总行数相同,否则确定所述源数据表的总行数与所述目标数据表的总行数不同。
[0187]
一种可能的实施方式,所述复查单元503用于:
[0188]
计算所述目标数据库中每批数据的第三哈希值;
[0189]
从所述源数据库中重新获取每个所述最终批次号对应的一批数据,并进行哈希计算,获得对应的第二哈希值;
[0190]
对于所述源数据库中无所述增量数据的各批数据,判断对应批数据的第一哈希值与所述目标数据库中同批次的第三哈希值是否相同,若相同确定所述源数据库与所述目标数据库对应的同批数据相同,否则确定不同;
[0191]
对于所述源数据库中每个所述最终批次号对应的一批数据,判断对应的第二哈希值与所述目标数据库中同批次的第三哈希值是否相同,若相同确定所述源数据库与所述目标数据库对应的同批次数据相同,否则确定不同。
[0192]
需要说明的是,本技术实施例中对单元的划分是示意性的,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式。另外,在本技术各个实施例中的各功能单元可以集成在一个处理单元中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个单元中。上述集成的单元既可以采用硬件的形式实现,也可以采用软件功能单元的形式实现。
[0193]
所述集成的单元如果以软件功能单元的形式实现并作为独立的产品销售或使用
时,可以存储在一个处理器可读取存储介质中。基于这样的理解,本技术的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的全部或部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)或处理器(processor)执行本技术各个实施例所述方法的全部或部分步骤。而前述的存储介质包括:u盘、移动硬盘、只读存储器(read-only memory,rom)、随机存取存储器(random access memory,ram)、磁碟或者光盘等各种可以存储程序代码的介质。
[0194]
在此需要说明的是,本发明实施例提供的上述装置,能够实现上述方法实施例所实现的所有方法步骤,且能够达到相同的技术效果,在此不再对本实施例中与方法实施例相同的部分及有益效果进行具体赘述。
[0195]
基于同一发明构思,本发明实施例中提供了一种数据库迁移的装置,包括:至少一个处理器,以及
[0196]
与所述至少一个处理器连接的存储器;
[0197]
其中,所述存储器存储有可被所述至少一个处理器执行的指令,所述至少一个处理器通过执行所述存储器存储的指令,执行如上所述的数据库迁移的方法。
[0198]
基于同一发明构思,本发明实施例还提一种可读存储介质,包括:
[0199]
存储器,
[0200]
所述存储器用于存储指令,当所述指令被处理器执行时,使得包括所述可读存储介质的装置完成如上所述的数据库迁移方法。
[0201]
所述可读存储介质可以是处理器能够存取的任何可用介质或数据存储设备,包括易失性存储器或非易失性存储器,或者可以包括易失性存储器和非易失性存储器两者。作为例子而非限制性的,非易失性存储器可以包括只读存储器(read-only memory,rom)、可编程rom(programmable read-only memory,prom)、电可编程rom(erasable programmable read-only memory,eprom)、电可擦写可编程rom(electrically erasable programmable read only memory,eeprom)或快闪存储器、固态硬盘(solid state disk或solid state drive,ssd)、磁性存储器(例如软盘、硬盘、磁带、磁光盘(magneto-optical disc,mo)等)、光学存储器(例如cd、dvd、bd、hvd等)。易失性存储器可以包括随机存取存储器(random access memory,ram),该ram可以充当外部高速缓存存储器。作为例子而非限制性的,ram可以以多种形式获得,比如动态ram(dynamic random access memory,dram)、同步dram(synchronous dynamic random-access memory,sdram)、双数据速率sdram(double data rate sdram,ddr sdram)、增强sdram(enhanced synchronous dram,esdram)、同步链路dram(sync link dram,sldram)。所公开的各方面的存储设备意在包括但不限于这些和其它合适类型的存储器。
[0202]
本领域内的技术人员应明白,本发明实施例可提供为方法、系统、或程序产品。因此,本发明实施例可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本发明实施例可采用在一个或多个其中包含有计算机/处理器可用程序代码的可读存储介质(包括但不限于磁盘存储器、cd-rom、光学存储器等)上实施的机程序产品的形式。
[0203]
本发明实施例是参照根据本发明实施例的方法、设备(系统)、和计算机程序产品
的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
[0204]
这些程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的可读存储器中,使得存储在该可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
[0205]
这些程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机/处理器实现的处理,从而在计算机/处理器或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
[0206]
显然,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围。这样,倘若本发明的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包含这些改动和变型在内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1