一种基于YOLO-V5的车辆属性识别方法与流程
一种基于yolo-v5的车辆属性识别方法
技术领域
1.本发明涉及车辆属性识别技术领域,具体涉及到一种基于yolo-v5的车辆属性识别方法。
背景技术:
2.传统的车辆属性识别方法,大多数都是目标检测与细粒度分类的叠加。近年来,随着深度学习技术的发展,越来越多的场景下的车辆检测和识别开始采用基于深度学习模型。比如实拍场景下借助ai技术识别实拍图像中车辆的颜色、车型、车系等车辆属性,比如先用目标深度学习模型检测到车辆,然后再使用细粒度深度学习模型进行车辆属性分析。
3.可知,现存的车辆属性识别方法,多数是采用两个或多个深度学习模型,它们先用检测网络检测出图像中的车辆所在位置,基于该图像然后抠图,使用属性模型进行属性分析,然而,由于属性分析是在车辆图像上做,由于区域的不同,在不同属性的预测时会存在相互之间的干扰,导致最终的识别结果准确度下降。
4.综述,在实际部署使用时,这样的组合不仅存在精度上的差异,还会带来性能上的增加,从而导致不仅增加显存和内存开销,还会增加计算量。基于上述分析,本专利提出了一种基于yolo-v5的车辆属性识别方法。
技术实现要素:
5.针对现有技术所存在的不足,本发明目的在于提出一种基于yolo-v5的车辆属性识别方法,具体方案如下:
6.一种基于yolo-v5的车辆属性识别方法,所述识别方法基于yolo-v5的深度学习网络,搭建多分支网络对样本数据进行车辆整体检测图以及车辆子区域图的划分,样本数据结合多分支训练后得到一个车辆属性识别模型,基于所述车辆属性识别模型对待识别图像同时实现车辆检测分析和车辆属性分析,得到识别结果。
7.进一步的,所述识别方法的具体步骤包括如下:
8.步骤一为训练数据预处理:将样本数据进行图像预处理,之后再对经过图像预处理的样本数据进行数据标定;
9.步骤二为多分支网络构建:以yolo-v5为基础网络搭建多分支网络,所述多分支网络包括检测分支网络以及属性分支网络,所述检测分支网络包括车辆检测框分支网络、车辆局部区域框分支网络;
10.步骤三为多分支网络训练:首先对检测分支网络进行整体的车辆检测框以及各个的车辆局部区域框的检测训练,得到检测模型,然后,对每个车辆局部区域框分支网络添加上对应的属性分支网络以调整检测模型,继续训练属性,当损失函数达到收敛,得到最终的车辆属性识别模型;
11.步骤四为识别效果展示:读入待识别图像,对所述待识别图像进行图像预处理,再基于所述车辆属性识别模型进行识别结果预测,直至输出识别结果。
12.进一步的,所述步骤一中,图像预处理包括有图像缩放、图像格式转换、图像旋转;
13.图像缩放是采用双线性插值算法对获得的抓拍图像进行缩放,模拟得到不同实际场景下的抓拍图;
14.图像格式转换是基于转换公式将不同格式的图像转换呈统一的格式;
15.图像旋转是基于笛卡尔坐标系以图像的重心为圆心进行旋转。
16.进一步的,所述数据标定包括属性标定、检测框标定;
17.所述属性标定可包括车辆颜色标定、车辆年检标签标定、车辆车型标定;
18.所述检测框标定包括车辆位置框标定以及子区域框标定,子区域框标定可包括车脸区域框标定,挡风玻璃区域框标定,车轮区域框标定。
19.进一步的,车辆位置框标定时,框的上下左右边缘要完整包括整个车辆,当车辆在图像上显露的区域少于整个车身面积的三分之一时不做标定;
20.各个子区域框标定时,同样,区域框要完整包括整个对应的车辆零件,当该车辆零件显现的区域少于整个车轮面积的三分之一时,不做标定。
21.进一步的,在所述步骤二中,yolo-v5搭建多分支网络时,yolo-v5作为主干网络首先搭建车辆检测框分支网络,然后在车辆检测框分支网络后再搭建多个车辆局部区域框分支网络,再在每个车辆局部区域框分支网络后搭建数据分支网络;
22.在车辆检测框分支网络后可同时搭建一个专门的简单属性分支网络。
23.进一步的,yolo-v5的网络结构通过通道裁剪以及结构组合的方式,基于所述车辆检测框分支网络得到车辆检测图后,直接得到多个待分析的抠取局部区域图,每个抠取局部区域图再与对应所述车辆局部区域框分支网络配合。
24.进一步的,在所述步骤三中,得到的检测模型需在测试集上进行检测框验证,测试集标定了不同场景下的车辆位置框、子区域框以及部分简单属性作为答案,然后把检测模型预测出来的车辆检测框和车辆位置框进行匹配,检测模型预测出来的各个车辆区域框也和子区域框进行匹配,检测模型预测出来的简单属性和测试集答案进行比对,根据不同的重合度阈值的准确率,判断当前的检测模型是否达到预期效果。
25.进一步的,在所述步骤三中,得到的车辆属性识别模型在测试集上进行属性验证,测试集标定了不同场景下的车辆颜色、车辆年检标签、车辆车型作为答案,然后把车辆属性识别模型预测出来的属性和测试集答案进行比对,根据不同的重合度阈值的准确率,判断当前的车辆属性识别模型是否达到预期效果。
26.与现有技术相比,本发明的有益效果如下:
27.(1)本发明采用基于深度学习网络的结构,搭建多分支网络,融合检测和属性分析,结合多分支训练,同时实现车辆检测和属性分析,有效的提升了准确率和性能。相较于现有技术中只在一张车辆整体检测图中进行车辆属性识别来说,本发明只需要一个模型即可得到最终的属性识别结果,并且车辆属性的识别是在车辆子区域图上进行精确预测分析,减小不同属性检测时的相互干扰,从而提高不同属性识别结果的精准度。
28.(2)本发明基于级联的多分支网络,具体在检测网络的后面添加了属性预测分支,在保证网络结构简便性的基础上,很好的做到了准确率和计算性能的平衡。
附图说明
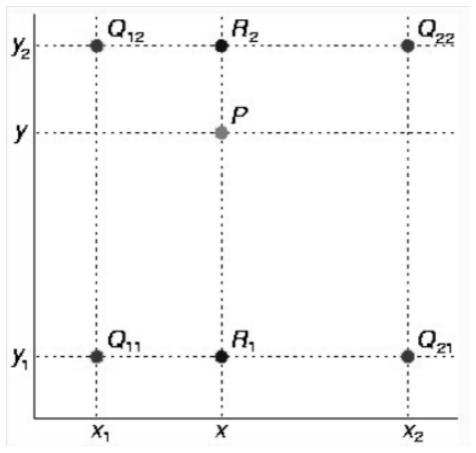
29.图1为本发明中的双线性插值图;
30.图2为图像缩放中x方向进行线性插值得到的公式图;
31.图3为图像缩放中y方向进行线性插值得到的公式图;
32.图4为图像缩放中结果f(x,y)的公示图;
33.图5为图像旋转中的笛卡尔坐标系图;
34.图6为图像旋转中矩阵中点(x',y')转换为笛卡尔坐标系(x,y)的转换关系图;
35.图7为图像旋转中笛卡尔坐标系(x,y)转换为矩阵中点(x',y')的转换关系图;
36.图8为本发明的识别方法的整体工作流程图;
37.图9为原始的yolo-v5的网络结构示意图;
38.图10为本发明整体的网络结构图。
具体实施方式
39.下面结合实施例及附图对本发明作进一步的详细说明,但本发明的实施方式不仅限于此。
40.一种基于yolo-v5的车辆属性识别方法,用于识别实拍图像中的车辆的颜色、车型、车系、年检标签等属性,本发明不做限制。该识别方法考虑到现有技术的缺陷,其改进的实质为基于yolo-v5的深度学习网络,搭建多分支网络对样本数据进行车辆整体检测图以及车辆子区域图的划分,样本数据结合多分支训练后得到一个车辆属性识别模型,基于车辆属性识别模型对待识别图像同时实现车辆检测分析和车辆属性分析,得到识别结果。
41.为得到上述的车辆属性识别模型,如图8所示,本发明的识别方法的具体步骤包括如下,步骤一为训练数据预处理,步骤二为多分支网络构建,步骤三为多分支网络训练,步骤四为识别效果展示。以下针对每个步骤进行详细阐述。
42.训练数据预处理具体为将样本数据进行图像预处理,之后再对经过图像预处理的样本数据进行数据标定。步骤一的设置,仿真不同实际场景下的相机实拍图像,可以有效地增强用于后续步骤三中的样本数据的丰富性和多样性,使训练数据上做到更加的贴近各种实际场景,更加鲁棒。
43.需要说明的是,步骤一中,图像预处理包括有图像缩放、图像格式转换、图像旋转。三种处理方式针对的主体是车辆实拍图像,三种预处理操作可以均进行或者择一进行,视实际需要而定,且三种预处理操作的进行顺序也是视实际需要而定,具体阐述如下:
44.在实际场景中,由于相机抓拍的图像中车辆的位置不固定,车辆在抓拍图像中存在大小不一的情况,为了使得模型能检测到不同场景下的车辆,图像缩放是采用双线性插值算法对获得的抓拍图像进行缩放,模拟得到不同实际场景下的抓拍图,使得训练用的样本数据更丰富,更加贴近实际场景图像。
45.双线性插值又称为双线性内插。在数学上,双线性插值是有两个变量的插值函数的线性插值扩展。其核心思想是在两个方向上分别进行一次线性插值。
46.如图1所示,q11、q12、q21、q22为已知的数据点,p点为待求的点,假如想得到未知函数f在点p=(x,y)的值,已知红色点q11=(x1,y1)、q12=(x1,y2)、q21=(x2,y1)以及q22=(x2,y2)的值。首先在x方向进行线性插值,得到如图2的算法。其次在y方向进行线性插
值,得到如图3的算法。这样,就得到所要的结果f(x,y),如图4的算法。图像缩放基于图4的算法抓拍图像实现缩放。
47.在实际使用过程中,送入车辆属性识别的图像的格式多种多样,比如nv12、rgb、yuv等等,为了有效的避免不同格式图像带来的车辆属性识别结果差异,因此,本发明在图像预处理时增加了图像格式转换操作,以此来增加样本的鲁棒性。图像格式转换是基于转换公式将不同格式的图像转换呈统一的格式,举例来说,rgb转yuv公式如下:
48.y=0.299r+0.587g+0.114b
49.u=-0.1687r-0.3313g+0.5b+128
50.v=0.5r-0.4187g-0.0813b+128
51.yuv转rgb公式如下:
52.r=y+1.402(v-128)
53.g=y-0.34414(u-128)-0.71414(v-128)
54.b=y+1.772(u-128)
55.至于其他格式之间的转换公式本发明不做一一阐述。
56.由于相机架设的角度不同,车辆在图像中呈现的视角也存在各种各样的角度,为了能更好的识别不同角度车辆的属性,本发明对样本数据设置图像旋转的功能,进行了旋转操作,使样本数据更多样化。
57.图像旋转是基于笛卡尔坐标系以图像的重心为圆心进行旋转。具体来说,以图像的中心为圆心进行旋转,如图5所示,在矩阵中坐标系通常是ad和ab方向的,而传统的笛卡尔直角坐标系是以矩阵中心建立坐标系的。令图像表示为m
×
n的矩阵,对于点a而言,两坐标系中的坐标分别是(0,0)和(-n/2,m/2),矩阵中点(x',y')转换为笛卡尔坐标系(x,y)的转换关系为如图6所示。而将笛卡尔坐标系(x,y)转换为矩阵中点(x',y')的逆变换公式如图7所示。如此一来,便可实现前述的图像旋转功能。
58.至于步骤一中的数据标定包括属性标定、检测框标定,此两种标定是为了得到样本数据中关于车辆位置、车辆子局域的检测以及每个子区域对应的属性的正确答案,所有正确答案汇总得到测试集,为后续步骤三的多分支训练的训练过程中的预测结果做参考。
59.属性标定包括但不限于车辆颜色标定、车辆年检标签标定、车辆车型标定,还可包括车系标定。车辆颜色标定包括但不限于黑色、白色、红色、粉色、紫色等颜色,车辆车型标定包括但不限于两厢轿车、三厢车轿车、suv、面包车等,车系标定包括但不限于长安马自达3_2013款、一汽大众奥迪a4_2021款、广汽本田飞度_2019款等。检测框标定包括车辆位置框标定以及子区域框标定,车辆位置框标定即图像中整体车辆的车辆检测框图,子区域框标定即图像中车辆零件的车辆局部区域框图,包括但不限于车脸区域框标定,挡风玻璃区域框标定,车轮区域框标定。
60.需要说明的是,为保证参考答案的标准,车辆位置框标定时,框的上下左右边缘要完整包括整个车辆,当车辆在图像上显露的区域少于整个车身面积的三分之一时不做标定。
61.各个子区域框标定时,同样,区域框要完整包括整个对应的车辆零件,当该车辆零件显现的区域少于整个车轮面积的三分之一时,不做标定。
62.多分支网络构建具体为以yolo-v5为基础网络搭建多分支网络,多分支网络包括
检测分支网络以及属性分支网络,检测分支网络包括车辆检测框分支网络、车辆局部区域框分支网络。正是由于步骤二的设置,使得本发明的识别方法实现采用级联的多分支网络,可将一个图像同时得到车辆整体检测图和多个车辆子区域图。
63.具体来说,在步骤二中,yolo-v5搭建多分支网络时,yolo-v5作为主干网络首先搭建车辆检测框分支网络,然后在车辆检测框分支网络后再搭建多个车辆局部区域框分支网络,再在每个车辆局部区域框分支网络后搭建数据分支网络,每个数据分支网络用于训练对应的属性。在车辆检测框分支网络后可同时搭建一个专门的简单属性分支网络,用于训练简单的属性,比如车辆颜色等。
64.为了在保证检测精度的同时可以有效提升运算速度,本发明对yolo-v5进行了通道裁剪和结构组合,以便于有更快的推理速度。图9为原始的yolo-v5的网络结构示意图。首先更改图像输入分辨率,本发明使用的320*640*3的分辨率图像作为输入,于此同时,为了提升网络运行速度同时减少计算量,本发明对结构中的通道数进行了优化,通过实验得到一组效果和性能匹配的通道数组合方式,与此同时,删除了原有网络结构中的backbone和neck中的部分连接层。在output后面,连接自定义的抠图层,得到待分析的车辆区域图,然后连接了多分支网络结构,进行车辆局部区域框的预测分析。
65.综述,yolo-v5的网络结构通过通道裁剪以及结构组合的方式,基于车辆检测框分支网络得到车辆检测图后,直接得到多个待分析的抠取局部区域图,每个抠取局部区域图再与对应车辆局部区域框分支网络配合。至此得到如图10所示的本发明整体的网络结构图。
66.前面构建了多分支网络结构用于车辆属性的识别,因此,在训练过程中采用了分步训练策略,来提升车辆属性最终的识别结果。多分支网络训练具体为首先对检测分支网络进行整体的车辆检测框以及各个的车辆局部区域框的检测训练,当损失函数达到收敛,得到检测模型,与此同时,还训练了简单的车辆属性,比如车辆颜色等。
67.优化的,得到的检测模型需在测试集上进行检测框验证,测试集标定了不同场景下的车辆位置框、子区域框以及部分简单属性作为答案,然后把检测模型预测出来的车辆检测框和车辆位置框进行匹配,检测模型预测出来的各个车辆区域框也和子区域框进行匹配,检测模型预测出来的简单属性和测试集答案进行比对,根据不同的重合度阈值的准确率,判断当前的检测模型是否达到预期效果。
68.在得到稳定的检测模型后,由于检测模型已经达到预期的效果,此时的网络模型已经可以得到稳定的车辆区域以及各个子区域,此时可继续优化检测模型。然后,对每个车辆局部区域框分支网络添加上对应的属性分支网络以调整检测模型,继续训练属性,当损失函数达到收敛,得到最终的车辆属性识别模型。举例来说,比如在车窗子区域连接年检标签属性,特定区域进行特定属性的识别分析,会更有利于得到精准的识别效果。
69.优化的,得到的车辆属性识别模型在测试集上进行属性验证,测试集标定了不同场景下的车辆颜色、车辆年检标签、车辆车型作为答案,然后把车辆属性识别模型预测出来的属性和测试集答案进行比对,根据不同的重合度阈值的准确率,判断当前的车辆属性识别模型是否达到预期效果。
70.前述的准确率以及预期效果本发明不做限制,具体在实际操作时进行合理的设定。
71.在得到稳定的车辆属性识别模型后,便可进行步骤四的识别效果展示,识别效果展示具体为读入待识别图像,对待识别图像进行图像预处理,再基于车辆属性识别模型进行识别结果预测,直至输出识别结果。读入待识别图像具体可采用搭建调用代码的方式,调用代码包括读入一张图像,然后进行图像预处理,然后加载车辆属性识别模型进行结果预测,最后输出识别结果。为更加直观的展示最终的效果,调用代码最后会保存一张结果图,图的左侧是原始输入的图像,图像中会画出车辆的检测框,图的右侧是对应的各个属性条目。
72.综述,本发明的识别方法,相较于现有技术中只在一张车辆整体检测图中进行车辆属性识别来说,车辆属性识别只需要一个车辆属性识别模型即可得到最终的识别结果,在实际部署使用时,减小显存和内存开销,也减小了算法的计算量。
73.另外,本专利采用级联的多分支网络,具体在检测网络的后面添加了属性预测分支网络,在保证网络结构简便性的基础上,很好的做到了准确率和计算性能的平衡,使得一张图像加载车辆属性识别模型后,不是在车辆检测图上直接进行各种属性的预测分析,而是在车辆子区域图上进行属性的精确预测分析,减小在不同属性的预测时会存在相互之间的干扰,从而提高最终的识别结果的准确度。
74.以上所述仅是本发明的优选实施方式,本发明的保护范围并不仅局限于上述实施例,凡属于本发明思路下的技术方案均属于本发明的保护范围。应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理前提下的若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1