一种基于元数据的知识图谱处理方法与流程
1.本发明涉及一种数据生成及检索分析方法,尤其涉及一种基于元数据的知识图谱处理方法。
背景技术:
2.元数据又称中介数据、中继数据,为描述数据的数据(data about data),主要是描述数据属性(property)的信息,用来支持如指示存储位置、历史数据、资源查找、文件记录等功能。
3.知识图谱的核心基本单位,是“实体(entity)-关系(relationship)-实体(entity)”构成的三元组,通过知识图谱显示知识发展进程与结构关系,用可视化技术描述知识资源及其载体,挖掘、分析、构建、绘制和显示知识及它们之间的相互联系。
4.随着时间的推移,数据量的不断增大,数据属性不断变化,数据的关系日益复杂。元数据描述数据的数据,包括元数据的属性、元数据的关系,就有效的抽象了数据模型,对数据进行管理。但随着数据种类的继续膨胀,元数据、以及元数据之间的关系也必然发生膨胀,慢慢形成元数据的网状结构,从这网状数据中无法快速定位元数据以及元数据的影响范围;从而导致无法快速定位、分析、展现数据属性以及数据关系。
技术实现要素:
5.本发明所要解决的技术问题是提供一种基于元数据的知识图谱处理方法,能够合理存储元数据网状关系,并能更好地进行检索和分析;从而通过元数据知识图谱,快速发现元数据所对应的数据的属性,以及发现其对应数据的关系网。
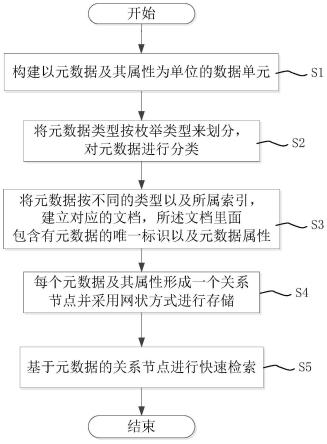
6.本发明为解决上述技术问题而采用的技术方案是提供一种基于元数据的知识图谱处理方法,包括如下步骤:s1)构建以元数据及其属性为单位的数据单元;s2)将元数据类型按枚举类型来划分,对元数据进行分类;s3)将元数据按不同的类型以及所属索引,建立对应的文档,所述文档里面包含有元数据的唯一标识以及元数据属性;s4)每个元数据及其属性形成一个关系节点并采用网状方式进行存储;s5)基于元数据的关系节点进行快速检索。
7.上述的基于元数据的知识图谱处理方法,其中,所述步骤s1中每个元数据具有一个或者多个属性,每个元数据的存储单元具有唯一标识性,并具备列扩展性进行增加、删除、修改和查询操作。
8.上述的基于元数据的知识图谱处理方法,其中,所述步骤s4中元数据在底层采用map集合进行存储,包括如下过程:对每个关系节点先判断是否在map集合中存在;如果不存在,则为第一次存储该节点关系,对元数据关系进行1对1的预处理形成key-value的键值对;如果存在,则为1对n节点关系,先存储1对1映射关系后,再创建有序数组存储对应的n-1个节点,形成key-list《key》的存储结构。
9.上述的基于元数据的知识图谱处理方法,其中,所述步骤s4采用mapsize《key,
size》和maplink《sizekey,nextkey》存储方式,当size=1时,则maplink《sizekey,nextkey》为maplink《key,nextkey》;第一次存储该节点关系时,size为1,存储mapsize(key,1);对于1对n节点关系,存储1对1映射关系后,以size值为种子,size加key生成基于key对应的唯一的sizekey,生成sizekey后把nextkey一起放入maplink(sizekey,nextkey)进而存储创建有序数组存储对应的n-1个节点,形成maplink(sizekey,nextkey)的存储结构;其中sizekey为原始key加上size序号,生成的sizekey,nextkey为原始key对应链路下个节点对应的节点的元数据的唯一标识码。
10.上述的基于元数据的知识图谱处理方法,其中,所述步骤s5基于每个关系节点指向的相邻节点进行快速检索,使得元数据的查找复杂度为o(1),关系查找复杂度为o(n)。
11.本发明对比现有技术有如下的有益效果:本发明提供的基于元数据的知识图谱处理方法,能够有效存储元数据网状结构,并能更好地进行检索和分析;每个元数据及其属性形成一个关系节点并采用网状方式进行存储,每个关系节点都具有指向相邻节点;使得元数查找关系复杂度最差情况为有序数组查找,时间复杂度为o(n),最优情况为o(1)。
附图说明
12.图1为本发明基于元数据的知识图谱处理流程图。
具体实施方式
13.下面结合附图和实施例对本发明作进一步的描述。
14.图1为本发明基于元数据的知识图谱处理流程图。
15.请参见图1,本发明提供的基于元数据的知识图谱处理方法,包括两部分要素节点与关系,形成网状数据存储。节点在本发明中为元数据及其属性;关系在本发明方法中为元数据之间的关系。
16.1、元数据及其属性。构建以元数据及其属性为单位的数据单元,每个元数据具有一个或者多个属性,属性可能各不相同,具有列不确定性。所以元数据存储单元需具备唯一标识性,用来作为这类元数据的唯一声明,其次元数据存储单元还要具备列扩展性,属性可以方便的进行增、删、改、查等操作用于存储元数据属性。
17.2、元数据关系。元数据之间的关系具有方向性关系、无方向性、以及两个元数据之间具有多种不同的关系;所以构建的元数据关系的存储层能存储元数据唯一标识及其属性、以及存储元数据存储单元之间的关系,满足关系的方向性,无向性,以及多样性。
18.3、元数据检索分析。网状关系型数据具有关系深度和关系复杂度的特性。在大数据量和关系复杂度较高的情况下,通过本发明可以快速检索出以指定元数据为数据中心的数据关系网以及关系网节点的元数据属性,从而实现点到网的快速检索分析。
19.实施方案:
20.1、元数据及其属性存储单元。存储元数据节点信息以及节点属性信息。
21.2、按元数据类型建立不同的类型(type)。元数据类型可按枚举类型来划分,对元数据进行分类。
22.3、构建元数据关系存储,本发明底层采用mapsize《key,size》、maplink《sizekey,nextkey》存储方式。其中当size=1,则maplink《sizekey,nextkey》为maplink《key,
nextkey》。通过原始key加上size序号生成基于原始key的新的唯一key,进而在链路map保证key不重复,从而解决1对多链路问题。
23.具体构建存储过程如下:每个关系先判断是否在map集合中存在:
24.如果不存在,则为第一次存储该节点关系,存储map集合,对元数据关系数据为1对1的简单数据进行预处理,根据每个元数据的唯一标识,并设置为key值,且size为1,存储mapsize(key,1);maplink存储链路,构建形成key-nextkey的键值对,nextkey为和key链路下一个节点对应元数据节点的唯一标识码;
25.如果存在,则为1对n节点关系,先存储1对1映射关系后,再根据size,循环size,以size值为种子,size加key生成基于key对应的唯一的sizekey,生成sizekey后把nextkey一起放入maplink(sizekey,nextkey)进而存储创建有序数组存储对应的n-1个节点,形成maplink(sizekey,nextkey)的存储结构。其中sizekey为原始key加上size序号,生成的sizekey。nextkey为原始key对应链路下个节点对应的节点的元数据的唯一标识码。
26.4、元数据关系检索。可对任意元数据节点进行检索,search_node(key)其时间复杂度为o(1)。可对任意元数据节点进行关系检索,search_relation(key),时间复杂度为o(n),最优情况为o(1)。
27.虽然本发明已以较佳实施例揭示如上,然其并非用以限定本发明,任何本领域技术人员,在不脱离本发明的精神和范围内,当可作些许的修改和完善,因此本发明的保护范围当以权利要求书所界定的为准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1