一种在线问答社区中检测欺诈性问答的方法
1.本发明涉及一种在线问答社区中检测欺诈性问答的方法,属于数据挖掘与网络空间安全领域。
技术背景
2.随着信息通信技术的飞速发展与web 2.0的普及,由此支撑的新型在线信息交互平台层出不穷。在此背景下,众多极具影响力的在线问答社区相继涌现,已成为公众利用互联网获取、传播、分享以及创造知识的重要平台。然而,随着在线问答社区规模及影响力的不断扩大,其也不可避免地成为网络水军的关注对象和活动场所,大量欺诈性的问答内容被发布到社区中,用以引导阅读者的价值判断并影响其决策行为,从而达成水军推销或抹黑特定商品与服务的目的,更有甚者通过散播谣言,操控和煽动舆情,引发网络暴力以及群体事件。在线问答社区中的欺诈信息已严重危害到平台的公信力及互联网中的经营、竞争秩序,甚至是社会稳定与国家安全。
3.因此,检测在线问答社区中的欺诈内容,包括欺诈性的问题和答案,已成为净化社区环境,维护平台公信力及网络空间安全亟待解决的重要问题。研究者们提出了一些关于问答社区欺诈检测的方法。chen等人从提问者、回答者以及问答文本角度定义了描述欺诈程度的特征,并利用逻辑回归的方法检测欺诈问答,如文献“the best answers?think twice:online detection of commercial campaigns in the cqa forums”;同样基于逻辑回归方法,li等人定义了提问者的接受率、经验值、信誉点、问答熵等统计指标,与问题的文本信息、发布时间、情感分值等共同构建特征空间识别欺诈问题,如文献“deceptive answer prediction withuser preference graph”。随着众包任务被引入到问答社区,群体性欺诈逐渐占据主流,很多研究工作也开始探索综合使用多种异质数据检测具有协作关系的虚假问答及其发布者,其中一类思路是分别定义文本、行为、关系等类型的特征,然后共同构建特征空间并输入分类器进行检测,如文献“revealing,characterizing,and detecting crowdsourcing spammers:a case study in community q&a”和“面向问答社区的众包网络水军检测研究”,另一类是基于关系数据构建概率描述模型并推理得到优化目标函数,再利用环路信念传播等算法训练参数获得检测器如文献“detecting collusive spamming activities in community question answering”。然而,目前还没有同时利用问答社区不同实体属性,及实体间多种关联关系检测欺诈问答的方法。
技术实现要素:
4.为解决上述问题,本发明提出了一种在线问答社区中检测欺诈性问答的方法,识别问答群组的前提下,同时利用多种实体属性和关联关系识别群体欺诈性问题和答案。本发明所要解决的技术问题在于众包任务驱动下的协同欺诈行为中,问答间不再独立,不应单独判定问答个体的欺诈性,而应充分考虑协作导致的关联关系,对相互关联的问答同时识别其是否欺诈,采用集体分类的方法,克服当前识别方法需要假设问答彼此独立的不足,
在问答存在关联关系的现实环境中,检测欺诈性问题和答案。
5.一种在线问答社区中检测欺诈性问答的方法,针对问答社区中存在关联关系的问答,采用集体分类的方法检测欺诈性问题和答案。本发明所述方法的主要步骤包括:
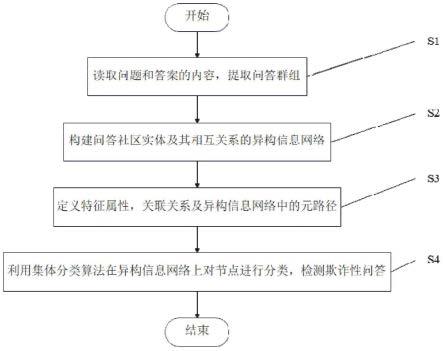
6.步骤s1,读取问题和答案的内容,根据欺诈模式提取问答群组;
7.步骤s2,构建问答社区实体及其相互关系的异构信息网络,所述异构信息网络的节点代表问答社区实体,并包含属性特征,边代表实体间关系,节点附带属性;
8.步骤s3,针对欺诈问答检测,筛选、构建或计算各类实体的具有区分度的属性特征,记录到异构信息网络中对应节点的属性中,并在部分实体间寻找能够描述其同质性的关联关系,据此定义异构信息网络元路径,所述元路径在网络对应着若干条具体路径,所述路径由网络中的多条能够首尾相连的边依次相连组成;
9.步骤s4,依据所述异构信息网络中节点的属性及其相关元路径,利用一种集体分类方法检测欺诈性问题和答案。
10.优选的,步骤s1中,首先对所有问题和答案进行分词,将每条问答都表示为一组词的集合,再根据所有问答中的词共现关系,利用余弦模式挖掘算法提取若干欺诈模式,然后将包含同一欺诈模式的问题与答案提取为问答群组,所述任一欺诈模式d={w1,w2,
…
wn}为一组词的集合,其中w1,w2,
…
wn分别表示构成d的n个词,同时满足以下条件:
11.sp(d)≥τs[0012][0013]
其中,sp(.)表示支持度,0≤τs,τ
t
≤1为预设阈值。
[0014]
优选的:步骤s2中,用于建立异构信息网络节点的问答社区实体包括:问题、答案、问答发布者以及问答群组,用于建立异构信息网络边的实体间关系包括:问答间的提问、回答关系,问答发布者与问答间的发布关系,问答与其所属群组间的属于关系。
[0015]
优选的:步骤s3中,选定的实体属性特征如下:
[0016]
问题属性包括:是否包含标签,是否具有详细描述,是否给予回答者奖励,是否有答案,是否只有唯一答案,是否被标记为已解决;
[0017]
答案属性包括:是否有评论,是否被标记为最佳答案,是否为对应问题的唯一答案,是否包含联系方式,是否标注关注领域,是否匿名作答;
[0018]
群组属性包括:群组中问答对应的发布者既是提问者又是回答者的比例,群组中问题与首个答案间的平均时间间隔,群组中问答发布的突发率。
[0019]
问答对应的发布者既是提问者又是回答者的情况包括三种:
①
发布者在群组中同时发布了问题和答案;
②
发布者在群组中发布了问题,同时回答了群组中的其它问题,但其发布的答案不在群组中;
③
发布者在群组中发布了答案,同时是群组中其它某答案所回答的问题的发布者,尽管该问题不在群组中。
[0020]
群组中问题与首个答案间的平均时间间隔avgqainterval的计算方法如下:
[0021]
[0022][0023]
其中g表示群组g中的成员,t(g)表示其发布的时间,t(g,fa)-t(g)表示当g为问题时与首个答案间的时间间隔,t(g)-t(g,q)分别表示g为答案时与对应问题的时间间隔,t为预设阈值。
[0024]
群组中问答发布的突发率的计算基于核密度估计方法,具体过程为:给定一个问答群组g,包含r个问题{q1,q2,
…
,qr},对应的发布时间为{t1,t2,
…
,tr}。因此,g的持续时间dur为t
r-t1。首先,选择合适的区间bin大小,将g的时间跨度划分为b个更小的子区间。然后,每个区间内的平均问题数可以计算为avgq=r/b。对于每一个bin,使用hi={qj|tj∈(a
i-1
,ai],i∈{1,..,b}}来表示落在这个bin中问答的数量,其中ai=i*bsize为第i个区间的起始点。接着,将g的持续时间标准化为[0,1],将每个间隔除以dur,即ai=ai/dur。本发明在核密度估计中使用高斯核,因此x1=a1,
…
,xr=ar可以作为带有权重w1=|h1|,
…
,wr=|hr|,在[0,1]范围内的区间样本。核密度估计计算公式为:
[0025][0026]
其中,b是带宽,用来控制核密度估计的平滑度,一般通过尝试不同的阈值来实验设置,使核密度估计不会太粗糙或者太平滑。
[0027]
通过计算kde(x)的导数并将其设置为0,找到了一组峰值点x
p1
,
…
,x
pt
,每个峰值点x
pt
落入某个区间i中。忽略落在间隔|hi|≤avgq中的,以及时间间隔范围内只包含一个问答的峰值点,然后对于剩余的每个峰值点,在满足|hb|≠1并且|hb|》avgq的条件下向时间线的前后扩张,得到突发区间。最后,累计所有突发区间中的问答总数,其与群组中问答的总数即为群组中问答发布的突发率。
[0028]
优选的:步骤s3中,选定的关联关系及异构信息网络中用于描述关联关系的元路径如下:
[0029]
问答关系,即问题与答案间简单的提问回答关系,使用元路径:问答关系,即问题与答案间简单的提问回答关系,使用元路径:描述;
[0030]
共同发布用户关系,即问题或答案由同一用户发布,使用元路径:共同发布用户关系,即问题或答案由同一用户发布,使用元路径:描述;
[0031]
共同群组关系,即问题或答案属于同一问答群组,使用元路径:共同群组关系,即问题或答案属于同一问答群组,使用元路径:描述;
[0032]
共同群组用户关系,即问题或答案与所属群组中其它问答发布者所发布的,未包含在该群组中的其它问题或答案间的关系,使用元路径:含在该群组中的其它问题或答案间的关系,使用元路径:描述;
[0033]
优选的:步骤s4中,主要步骤包括:
[0034]
步骤ss1,分别人工挑选少量欺诈性和正常的问题与答案,并对其进行标记,构建训练集,在训练集上,利用所述实体属性特征,分别针对问题和答案训练能够判定问答欺诈性的第一分类器;
[0035]
步骤ss2,利用所述第一分类器对训练集之外的问答实体进行分类,并对其进行标记;
[0036]
步骤ss3,针对每个问题或答案,利用一种基于元路径的特征扩展算法聚合邻居节点的标记,生成问答的扩展特征向量;
[0037]
步骤ss4,利用所述扩展特征向量,在训练集上重新训练判定问答欺诈性的第二分类器;
[0038]
步骤ss5,利用所述第二分类器对训练集之外的问答样本数据进行分类,并更新其标记信息;
[0039]
步骤ss6,依次重复执行步骤ss3,ss4,ss5,直至更新前后所有问答的标记均保持不变,或达到最大迭代次数,跳转至步骤ss7;
[0040]
步骤ss7,根据迭代停止后的问答标记信息,输出欺诈性问题和答案。
[0041]
优选的:步骤ss1,ss2,ss5中的分类器均针对问题和答案分别训练,针对问题的分类器使用问题属性与群组属性,针对答案的分类器使用答案属性和群组属性,具体分类算法不做限制,可采用经典的分类算法,如贝叶斯、支持向量机、随机森林等。
[0042]
优选的:步骤ss3中,主要步骤包括:
[0043]
步骤sss1:针对任一问题或答案e,假设其相关的元路径集合m={m1,m2,
…
,mk},元路径mi,1≤i≤k,包含的路径集合针对每条路径p
j(i)
,1≤j≤l,获取其邻居节点欺诈性的标记n
j(i)
,建立邻居节点标记集合
[0044]
步骤sss2:利用聚合函数对中的标记进行聚合计算,得到e在元路径mi下的邻居聚合标记l(i),聚合函数可选择mode或avg函数;
[0045]
步骤sss3:针对元路径集合m中的每条元路径,重复执行步骤sss1和sss2获得e的所有邻居聚合标记向量《l
(1)
,l
(2)
,
…
,l
(k)
》,将其以拼接方式附加到e的属性特征向量中,获得e的扩展特征向量;
[0046]
步骤sss4:针对异构信息网络中的所有问题和答案,重复执行步骤sss1,sss2,sss3,获得全部扩展特征向量。
[0047]
与现有技术相比,本发明的有益效果体现在:
[0048]
1)本发明在通过群组构建关联关系,群组的提取基于抽取策略而非划分策略,不会将不属于群组的问答强行划分到群组中,有效降低算法过拟合的可能。
[0049]
2)本发明综合利用问答间多种不同类型的关联关系,有利于群体性欺诈问答的准确识别。
[0050]
3)本发明能根据数据特征和实际情况灵活选择基础分类算法,支持新的关联关系的引入,有利于增强检测方法的泛化能力和扩展性。
附图说明
[0051]
图1是本发明所述方法的整体流程图
[0052]
图2是本发明所述方法的细致流程图
具体实施方式
[0053]
下面结合附图对本发明的技术方案进行详细说明:
[0054]
图1显示了检测欺诈性问答的过程,其具体步骤如下:
[0055]
步骤s1,读取问题和答案的内容,根据欺诈模式提取问答群组;
[0056]
步骤s2,构建问答社区实体及其相互关系的异构信息网络,所述异构信息网络的节点代表问答社区实体,并包含属性特征,边代表实体间关系,节点附带属性;
[0057]
步骤s3,针对欺诈问答检测,筛选、构建或计算各类实体的具有区分度的属性特征,记录到异构信息网络中对应节点的属性中,并在部分实体间寻找能够描述其同质性的关联关系,据此定义异构信息网络元路径,所述元路径在网络对应着若干条具体路径,所述路径由网络中的多条能够首尾相连的边依次相连组成;
[0058]
步骤s4,依据所述异构信息网络中节点的属性及其相关元路径,利用一种集体分类方法检测欺诈性问题和答案。
[0059]
实施例
[0060]
下面结合图2详细阐述实施例。本实施例中假设待检测的数据集中包含m条问题{q1,q2,
…
,qm},n条答案{a1,a2,
…
,an}以及s个问答发布者{u1,u2,
…
,us}。
[0061]
步骤s1,对每条问题和答案进行分词并去除停用词,然后将每个词视余弦模式挖掘中的“项”,每条由单词集合构成的问答视为余弦模式挖掘中的“事务”,设定τs,τ
t
的值,使用余弦模式挖掘算法挖掘欺诈模式,假设挖掘出的欺诈模式为d1={w1,w2,
…
wk}和d2={w
k+1
,w
k+2
,
…wk+h
},wi,i∈[1,k+h]为词。假设问题q1,q2,答案a1,a2包含d1中的所有词,问题q3,q4,答案a3,a4,a5包含d2中的所有词,则q1,q2,a1,a2匹配欺诈模式d1,构成群组g1={q1,q2,a1,a2},q3,q4,a3,a4,a5匹配欺诈模式d2,构成群组g2={q3,q4,a3,a4,a5};
[0062]
步骤s2,构建异构信息网络,网络节点代表不同类型的问答社区实体,包括问题q1,q2,
…
,qm,答案a1,a2,
…
,an,问答发布者u1,u2,
…
,us,群组g1,g2;边代表上述实体间的关系,如提问、回答、发布、属于等。
[0063]
步骤s3,分别计算问题、答案、群组节点的属性特征向量vq,va和vg,其中为vq五维向量,包含5个问题属性,va五维向量,包含5个答案属性,vg三维向量,包含3个群组属性。定义元路径m1=q-a,m2=a-q,m3=q/a-u-q/a,m4=q/a-g-q/a,m5=q/a-g-q/a-u-q/a,其中q,a,u,g分别代表问题实体、答案实体、用户实体以及群组实体。
[0064]
步骤s4,假设问题q1,q3,答案a2由用户u1发布,问题q2,q4,答案a1,a4由用户u2发布,a6,a7为q1的答案,利用集体分类方法对所有问题和答案进行欺诈性分类,具体的:
[0065]
步骤ss1,假设通过人工标记问题q2=d,q4=o,q5=d,q6=o,a2=d,a3=o,a6=d,构建训练集t={q2,q4,q5,q6,a2,a3,a6},利用{q2,q4,q5,q6,}和属性特征向量vq,vg训练初始的问题分类器fq,利用{a2,a3,a6}和属性特征向量va,vg和训练初始的答案分类器fa。
[0066]
步骤ss2,利用fq和fa对数据集中剩余的问题和答案进行分类,得到所有问答的标记。
[0067]
步骤ss3,针对所有问题和答案,计算扩展特征向量。以问题q1为例,其相关的元路径为m1,m3,m4和m5:
[0068]
依据元路径m1,相关的具体路径为q1→
a6,q1→
a7,假设在步骤ss2中分类得到的标记a6=d,a7=o,假设聚合函数为avg,即求平均,数值上令d=1,o=0(下同),则获得元路径m1对应的扩展特征:(1+0)/2=0.5;
[0069]
依据元路径m3,相关的具体路径为q1→
u1→
q3,q1→
u1→
a2,假设在步骤ss2中分类得到的标记q3=d,而a2=d为训练集中的标记数据,则获得元路径m2对应的扩展特征:(1+1)/2=1;
[0070]
依据元路径m4,相关的具体路径为q1→
g1→
q2,q1→
g1→
a1,q1→
g1→
a2,假设在步骤ss2中分类得到的标记a1=o,而q2=d和a2=d为训练集中的标记数据,则获得元路径m3对应的扩展特征(0+1+1)/3≈0.67;
[0071]
依据元路径m5,相关的具体路径为q1→
g1→
q2→
u2→
q4,q1→
g1→
q2→
u2→
a4,q1→
g1→
a1→
u2→
q4,q1→
g1→
q2→
u2→
a4,q1→
g1→
a2→
u1→
q3,假设在步骤ss2中分类得到的标记q3=d,a4=o,而q4=o为训练集中的标记数据,则获得元路径m3对应的扩展特征(0+0+0+0+1)/5=0.2。
[0072]
则向量《0.5,1,0.67,0.2》作为扩展特征向量与问题q1和群组g1的属性特征向量v
1q
,v
1g
拼接获得问题q1的十二维扩展特征向量。重复执行上述过程直至获得所有问题和答案的扩展特征向量。
[0073]
步骤ss4,利用获得的扩展特征向量,在训练集上重新训练获得问题分类器f
′q和答案分类器f
′a。
[0074]
步骤ss5,分别利用问题分类器f
′q和答案分类器f
′a对训练集之外的问答进行分类,更新问答的标记信息。
[0075]
步骤ss6,依次重复执行步骤ss3,ss4,ss5,直至更新前后所有问答的标记均保持不变,或达到最大迭代次数,跳转至步骤ss7;
[0076]
步骤ss7,根据迭代停止后的问答标记信息,输出欺诈性问题和答案。
[0077]
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1