一种热点话题的获取方法、系统及其存储介质与流程
1.本发明涉及自然语言处理领域,具体涉及一种热点话题的获取方法、系统及其存储介质。
背景技术:
2.当今社会互联网发展迅速,新闻、社交媒体的数量数以万计,针对海量的新闻数据如何抽取当前的热门话题,是现有技术的难题。基于此,本技术提出了相关技术方案解决此问题。
技术实现要素:
3.本发明的目的在于克服上述技术不足,提供一种热点话题的获取方法、系统及其存储介质,解决现有技术中难以从海量的新闻数据抽取当前的热门话题的技术问题。
4.为达到上述技术目的,本发明的技术方案提供一种热点话题的获取方法,包括以下步骤:
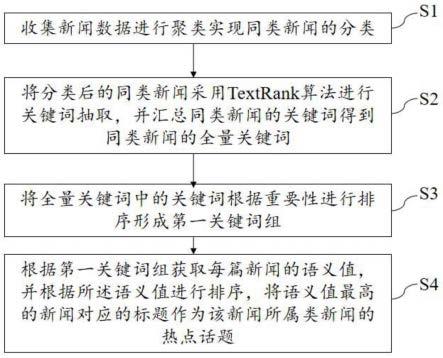
5.s1、收集新闻数据进行聚类实现同类新闻的分类;
6.s2、将分类后的同类新闻采用textrank算法进行关键词抽取,并汇总同类新闻的关键词得到同类新闻的全量关键词;
7.s3、将全量关键词中的关键词根据重要性进行排序形成第一关键词组;
8.s4、根据第一关键词组获取每篇新闻的语义值,并根据所述语义值进行排序,将语义值最高的新闻对应的标题作为该新闻所属类新闻的热点话题。
9.进一步地,在步骤s3中,所述全量关键词中的每个关键词的重要性根据词频逆文档频率值判断得到,词频逆文档频率值越高其关键词的重要性越大。
10.进一步地,在步骤s3中,所述词频逆文档频率值的计算方法为:
11.词频逆文档频率值=词频*逆文档频率;
12.其中,
13.其中,
14.进一步地,在步骤s4中,所述每篇新闻的语义值由以下步骤得到:获取每篇新闻的第二关键词组,结合每篇新闻所属的该类新闻的第一关键词组获得每篇新闻的共有关键词组,累加共有关键词组与其对应的词频逆文档概率得到每篇新闻的语义值。
15.进一步地,在步骤s4中,所述共有关键词组为所述第二关键词组和所述第一关键词组的交集。
16.进一步地,在步骤s1中,采用隐含狄利克雷分布算法进行所述聚类实现同类新闻的分类。
17.进一步地,在步骤s4之后还包括:步骤s5、收集新的新闻数据重复步骤s1-s4获得
所述热点话题。
18.此外,本发明还提出一种热点话题的获取系统,包括:
19.收集单元,用于收集新闻数据进行聚类实现同类新闻的分类;
20.抽取单元,用于将分类后的同类新闻采用textrank算法进行关键词抽取,并汇总同类新闻的关键词得到同类新闻的全量关键词;
21.第一排序单元,用于将全量关键词中的关键词根据重要性进行排序形成第一关键词组;
22.第二排序单元,用于根据第一关键词组获取每篇新闻的语义值,并根据所述语义值进行排序,将语义值最高的新闻对应的标题作为该新闻所述类别新闻的热点话题。
23.进一步地,本发明还提出一种存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现上述热点话题的获取方法的步骤。
24.与现有技术相比,本发明的有益效果包括:收集新闻数据进行聚类实现同类新闻的分类,将新闻数据分为不同的类,便于后续关键词的抽取;将分类后的同类新闻采用textrank算法进行关键词抽取,并汇总同类新闻的关键词得到同类新闻的全量关键词;将全量关键词中的关键词根据重要性进行排序形成第一关键词组;根据第一关键词组获取每篇新闻的语义值,并根据所述语义值进行排序,将语义值最高的新闻对应的标题作为该新闻所属类新闻的热点话题,从而实现可从海量的新闻数据抽取当前的热门话题。
25.现有技术通过海量的新闻数据通过算法得到相似类型的新闻数据,最终通过人工方式进行校正、总结话题,规模大、过程繁杂、成本较高但效果好。本发明通过算法无需人工干预通过从海量新闻数据中自动分类并从每种类别中选出具有代表性的新闻标题作为话题,此方式流程简单高效、省去人工成本、效果也较好。
附图说明
26.图1是本发明实施例1提出的热点话题的获取方法的流程图。
27.图2是本发明实施例1提出的热点话题的获取系统的结构框图。
具体实施方式
28.为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
29.实施例1
30.结合图1,本实施例提出了一种热点话题的获取方法,包括以下步骤:
31.s1、收集新闻数据采用隐含狄利克雷分布算法(latent dirichlet allocation,lda)进行聚类实现同类新闻的分类;隐含狄利克雷分布算法可以将大量新闻共有主题按照概率分布的形式给出,即将相似的新闻划分为同一类;
32.s2、将分类后的同类新闻采用textrank算法进行关键词抽取,并汇总同类新闻的关键词得到同类新闻的全量关键词;
33.s3、将全量关键词中的关键词根据重要性进行排序形成第一关键词组,本实施例按照重要性由高到底筛选重要性较高的关键词形成关键词组,关键词组即通过将中文句子
进行切词并将不同的词进行词性合并得到一些能够代表本句话含义的关键词,多个关键词构成关键词组,本实施例中可以使用两种方式选择关键词,一种是只选择前15个关键词,一种是通过选择词频逆文档频率值为0.1-0.3的关键词;所述全量关键词中的每个关键词的重要性根据词频逆文档频率值判断得到,词频逆文档频率值越高其关键词的重要性越大;所述词频逆文档频率值的计算方法为:
34.词频逆文档频率值=词频*逆文档频率;
35.其中,
36.其中,
37.s4、根据第一关键词组获取每篇新闻的语义值,并根据所述语义值进行排序,将语义值最高的新闻对应的标题作为该新闻所属类新闻的热点话题;所述每篇新闻的语义值由以下步骤得到:获取每篇新闻的第二关键词组,结合每篇新闻所属的该类新闻的第一关键词组获得每篇新闻的共有关键词组,累加共有关键词组与其对应的词频逆文档概率得到每篇新闻的语义值;所述共有关键词组为所述第二关键词组和所述第一关键词组的交集。
38.s5、收集新的新闻数据重复步骤s1-s4获得所述热点话题,通常收集新的新闻数据的间隔时间为4-6天,本实施例的间隔时间为5天。
39.结合图2,本实施例还提出一种热点话题的获取系统,包括:
40.收集单元,用于收集新闻数据进行聚类实现同类新闻的分类;
41.抽取单元,用于将分类后的同类新闻采用textrank算法进行关键词抽取,并汇总同类新闻的关键词得到同类新闻的全量关键词;
42.第一排序单元,用于将全量关键词中的关键词根据重要性进行排序形成第一关键词组;
43.第二排序单元,用于根据第一关键词组获取每篇新闻的语义值,并根据所述语义值进行排序,将语义值最高的新闻对应的标题作为该新闻所述类别新闻的热点话题。
44.本实施例还提出一种存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现上述热点话题的获取方法的步骤。
45.以上所述本发明的具体实施方式,并不构成对本发明保护范围的限定。任何根据本发明的技术构思所做出的各种其他相应的改变与变形,均应包含在本发明权利要求的保护范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1