一种基于样本数据增强的篇章级合同抽取方法及系统与流程
1.本技术涉及神经网络技术领域,特别是涉及一种基于样本数据增强的篇章级合同抽取方法及系统。
背景技术:
2.在实际需求中,合同文件存在类型多样、格式不一,甲乙双方基础信息错位、要素抽取字段多、粒度更细、手写体、章印等问题,导致现有的合同要素抽取产品平均准确在80%左右,合同编号、地址等字段仅有70%左右的准确率。因此,需要提高对合同要素的识别准确率。而现有的合同要素抽取模型主要存在以下问题:(1)合同类型多,格式复杂多样,现有的模型泛化能力不强。(2)合同甲乙双方基本信息错位,模型抽取也存在错位问题,无纠正能力。(3)合同要素抽取字段过多,粒度也更细,某些字段数据占比较少,模型抽取不到或抽取错误。(4)合同章印部分的字段信息,受ocr影响,模型抽取不全或抽取错误。
技术实现要素:
3.鉴于以上所述现有技术的缺点,本技术的目的在于提供一种基于样本数据增强的篇章级合同抽取方法及系统,用于解决现有的合同要素抽取模型存在的问题。
4.为实现上述目的及其他相关目的,本技术提供一种基于样本数据增强的篇章级合同抽取方法,所述方法包括以下步骤:
5.获取待处理合同,并判断所述待处理合同的文本类型;
6.基于所述待处理合同的文本类型确定所述待处理合同的文本抽取方式;
7.按照确定的文本抽取方式对所述待处理合同进行段落和章节信息抽取,并根据章节分级标志使用正则匹配进行划分,将划分后的章节信息分别加在所属的句子开头;
8.根据要素数据类型,对划分后的章节信息进行数据加强;
9.采用预设网络模型从完成数据增强后的章节信息进行信息抽取,并将预设网络模型抽取的信息通过规则进行错误纠正、相似匹配和错位纠正,输出最终结果。
10.可选地,所述待处理合同的文本类型包括:图像格式的pdf文本类型、可编辑格式的pdf文本类型和word文本类型。
11.可选地,对划分后的章节信息进行数据加强的过程包括:对划分后的章节信息进行同义词替换、随机插入、随机替换与随机删除,以对划分后的章节信息进行数据扩充。
12.可选地,采用预设网络模型从完成数据增强后的章节信息进行信息抽取的过程包括:
13.对合同文本信息每个字符或词增加起始位置和终止位置;
14.基于合同文本信息进行建模,得到批次大小*文本长度的二维矩阵,并将字或词组成的新短语结构进行扁平化处理,通过预训练模型得到三维矩阵;
15.根据自注意力机制实现字和词之间的信息交互,得到合同文本的表征;
16.将得到的表征输入到条件随机场中,抽取出合同文本中的各个要素字段信息。
17.可选地,抽取的要素字段信息包括以下至少之一:合同名称、甲方账户名、乙方账户名、合同税率、金额币种、金额是否含税、开始时间、截止日期、甲方银行账号、乙方银行账号、甲方税号、乙方税号、甲方法人、乙方法人。
18.本技术还提供一种基于样本数据增强的篇章级合同抽取系统,所述系统包括有:
19.数据采集模块,用于获取待处理合同,并判断所述待处理合同的文本类型;
20.抽取方式模块,用于根据所述待处理合同的文本类型确定所述待处理合同的文本抽取方式;
21.划分模块,用于按照确定的文本抽取方式对所述待处理合同进行段落和章节信息抽取,并根据章节分级标志使用正则匹配进行划分,将划分后的章节信息分别加在所属的句子开头;
22.数据加强模块,用于根据要素数据类型,对划分后的章节信息进行数据加强;
23.信息抽取模块,用于采用预设网络模型从完成数据增强后的章节信息进行信息抽取,并将预设网络模型抽取的信息通过规则进行错误纠正、相似匹配和错位纠正,输出最终结果。
24.可选地,所述待处理合同的文本类型包括:图像格式的pdf文本类型、可编辑格式的pdf文本类型和word文本类型。
25.可选地,对划分后的章节信息进行数据加强的过程包括:对划分后的章节信息进行同义词替换、随机插入、随机替换与随机删除,以对划分后的章节信息进行数据扩充。
26.可选地,采用预设网络模型从完成数据增强后的章节信息进行信息抽取的过程包括:
27.对合同文本信息每个字符或词增加起始位置和终止位置;
28.基于合同文本信息进行建模,得到批次大小*文本长度的二维矩阵,并将字或词组成的新短语结构进行扁平化处理,通过预训练模型得到三维矩阵;
29.根据自注意力机制实现字和词之间的信息交互,得到合同文本的表征;
30.将得到的表征输入到条件随机场中,抽取出合同文本中的各个要素字段信息。
31.可选地,抽取的要素字段信息包括以下至少之一:合同名称、甲方账户名、乙方账户名、合同税率、金额币种、金额是否含税、开始时间、截止日期、甲方银行账号、乙方银行账号、甲方税号、乙方税号、甲方法人、乙方法人。
32.如上所述,本技术提供一种基于样本数据增强的篇章级合同抽取方法及系统,具有以下有益效果:
33.本技术首先获取待处理合同,并判断所述待处理合同的文本类型;然后基于所述待处理合同的文本类型确定所述待处理合同的文本抽取方式;再按照确定的文本抽取方式对所述待处理合同进行段落和章节信息抽取,并根据章节分级标志使用正则匹配进行划分,将划分后的章节信息分别加在所属的句子开头;再然后根据要素数据类型,对划分后的章节信息进行数据加强;最后采用预设网络模型从完成数据增强后的章节信息进行信息抽取,并将预设网络模型抽取的信息通过规则进行错误纠正、相似匹配和错位纠正,输出最终结果。通过本技术记载的技术方案,本技术可以从合同中抽取出合同名称、甲方账户名、乙方账户名、合同税率、金额币种、金额是否含税、开始时间、截止日期、甲方银行账号、乙方银行账号、甲方税号、乙方税号、甲方法人以及乙方法人等要素信息,而且对于合同名称、甲方
账户名、乙方账户名、合同税率、金额币种、金额是否含税、开始时间和截止日期这8个核心字段可达到92.3%的准确率,对于甲方银行账号、乙方银行账号、甲方税号、乙方税号、甲方法人、乙方法人等25个字段可以实现75.8%的准确率。
附图说明
34.图1为一实施例提供的基于样本数据增强的篇章级合同抽取方法的流程示意图;
35.图2为一实施例提供的预设网络模型的结构示意图;
36.图3为一实施例提供的基于样本数据增强的篇章级合同抽取系统的硬件结构示意图。
具体实施方式
37.以下通过特定的具体实例说明本技术的实施方式,本领域技术人员可由本说明书所揭露的内容轻易地了解本技术的其他优点与功效。本技术还可以通过另外不同的具体实施方式加以实施或应用,本说明书中的各项细节也可以基于不同观点与应用,在没有背离本技术的精神下进行各种修饰或改变。需说明的是,在不冲突的情况下,以下实施例及实施例中的特征可以相互组合。
38.需要说明的是,以下实施例中所提供的图示仅以示意方式说明本技术的基本构想,遂图式中仅显示与本技术中有关的组件而非按照实际实施时的组件数目、形状及尺寸绘制,其实际实施时各组件的型态、数量及比例可为一种随意的改变,且其组件布局型态也可能更为复杂。
39.请参阅图1,本技术提供一种基于样本数据增强的篇章级合同抽取方法,包括以下步骤:
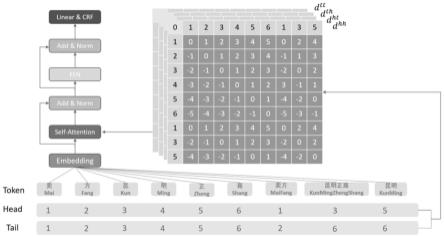
40.s110,获取待处理合同,并判断所述待处理合同的文本类型。在本实施例中,所述待处理合同的文本类型包括:图像格式的pdf文本类型、可编辑格式的pdf文本类型和word文本类型。其中,文件类型和合同抽取之间的关联主要是文件中文本的获取方式。word是可读文件,可以直接获取相应的文本信息。pdf分为可读文件和不可读文件,其中可读文件可以直接获取到文本信息;不可读文件如png图片等格式需要通过ocr识别获取到文本信息。word和pdf的文本获取成功后的处理是一样的。
41.s120,基于所述待处理合同的文本类型确定所述待处理合同的文本抽取方式。在本实施例中,pdf分两类只是为了区分pdf内文本的获取方式不同,一个可直接读取文本内容,一个需要通过ocr识别的文本,且两类pdf文本后续的文本处理过程一样。
42.s130,按照确定的文本抽取方式对所述待处理合同进行段落和章节信息抽取,并根据章节分级标志使用正则匹配进行划分,将划分后的章节信息分别加在所属的句子开头;
43.s140,根据要素数据类型,对划分后的章节信息进行eda数据增强。作为示例,本实施例对划分后的章节信息进行数据加强的过程可以包括:对划分后的章节信息进行同义词替换、随机插入、随机替换与随机删除,以对划分后的章节信息进行数据扩充。作为示例,具体地,要增强的数据指:标注数据量较少的字段类型,如法人、委托代理人、项目经理、乙方地址等字段。eda数据增强,就是将这些较少标注数据,通过同义词替换、随机插入、随机替
换与随机删除等方法将数据进行扩充,起到数据增强的作用。
44.s150,采用预设网络模型从完成数据增强后的章节信息进行信息抽取,并将预设网络模型抽取的信息通过规则进行错误纠正、相似匹配和错位纠正,输出最终结果。作为示例,具体地,错误纠正:主要是对于pdf为图片,要经过ocr识别出文本,对于识别的错别字进行纠正,受ocr识别错误而影响字段,如合同名称、甲方、乙方等。因为ocr受图片质量、翻转、章印等因素的影响。对于模型抽取的结果,进行正则优化,如税号、银行账号、联系方式,去除模型多抽的错误字符等情况。相似匹配:对于pdf为图片的合同,通过difflib等相似算法,对于甲乙方建立字典库,进行相似匹配,字典库也可以完善甲乙方的其他信息,如法人、税号等,也可以利用相似匹配,对模型抽取的结果进行纠正。错位纠正:主要是对模型抽取的结果使用正则进行纠正,问题如甲乙方错位,通过特定甲乙方的标志,如甲方、委托人、买方等。
45.根据上述记载,在一示例性实施例中,预设网络模型的网络结构如图2所示。在图2中,图中参数定义:d
tt
表示尾实体尾实体的位置矩阵。d
th
表示尾实体头实体的位置矩阵。d
ht
表示头实体尾实体的位置矩阵。d
hh
表示头实体头实体的位置矩阵。linear&crf表示线性条件随机场,一种判别式概率模型,其参数优化方法是针对目标函数的极大似然估计。add&norm表示求和与归一化。ffn表示全连接层。add&norm表示求和与归一化。self-attention表示自注意力机制,能够无视词之间的距离直接计算依赖关系,学习一个句子的内部结构。embedding表示嵌入层,将字/词转换为实向量。token表示文本中各个字/词。head表示头实体。tail表示尾实体。
46.其中,采用预设网络模型从完成数据增强后的章节信息进行信息抽取的过程包括:对合同文本信息每个字符或词增加起始位置和终止位置;基于合同文本信息进行建模,得到批次大小*文本长度的二维矩阵,并将字或词组成的新短语结构进行扁平化处理,通过预训练模型得到三维矩阵;根据自注意力机制实现字和词之间的信息交互,得到合同文本的表征;将得到的表征输入到条件随机场中,抽取出合同文本中的各个要素字段信息。作为示例,在本实施例中,抽取的要素字段信息包括以下至少之一:合同名称、甲方账户名、乙方账户名、合同税率、金额币种、金额是否含税、开始时间、截止日期、甲方银行账号、乙方银行账号、甲方税号、乙方税号、甲方法人、乙方法人。
47.通过本实施例记载的技术方案,本实施例可以从合同中抽取出合同名称、甲方账户名、乙方账户名、合同税率、金额币种、金额是否含税、开始时间、截止日期、甲方银行账号、乙方银行账号、甲方税号、乙方税号、甲方法人以及乙方法人等要素信息,而且对于合同名称、甲方账户名、乙方账户名、合同税率、金额币种、金额是否含税、开始时间和截止日期这8个核心字段可达到92.3%的准确率,对于甲方银行账号、乙方银行账号、甲方税号、乙方税号、甲方法人、乙方法人等25个字段可以实现75.8%的准确率。
48.此外,发明人发现,合同文本中存在大量的半结构化文本和少量的表格,如甲乙双方的基本信息等,其中表格信息、段落信息和章节信息,现有任务无法很好的利用这三者的联系,主要方法是将合同文本按段落划分区间,再结合章节信息来进行组合,将组合信息输入模型中,而表格信息没有结合章节、段落信息处理,容易产生错位、混淆等问题。
49.因此,本技术还提供另一示例性实施例,该实施例包括一种基于bert-flat-crf的基于样本数据增强的篇章级合同抽取方法,包括以下步骤:
50.判断文件类型,分为pdf和word分别解析,其中pdf分为png图片格式和pdf可编辑文件。其中,文件类型和合同抽取之间的关联主要是文件中文本的获取方式。word是可读文件,可以直接获取相应的文本信息。pdf分为可读文件和不可读文件,其中可读文件可以直接获取到文本信息;不可读文件如png图片等格式需要通过ocr识别获取到文本信息。word和pdf的文本获取成功后的处理是一样的。pdf分两类只是为了区分pdf内文本的获取方式不同,一个可直接读取文本内容,一个需要通过ocr识别的文本,且两类pdf文本后续的文本处理过程一样。
51.段落和章节信息抽取,根据章节分级标志使用正则匹配进行划分,划分后将章节信息分别加在所属的句子开头。
52.数据增强,根据要素数据类型,进行eda数据增强,增加语料的多样性。其中,要增强的数据指:标注数据量较少的字段类型,如法人、委托代理人、项目经理、乙方地址等字段。eda数据增强,就是将这些较少标注数据,通过同义词替换、随机插入、随机替换与随机删除等方法将数据进行扩充,起到数据增强的作用。
53.模型结构,采用bert-flat-crf模型,可以强化实体,特别是span较长的实体,同时引入词汇信息,对小样本ner增益明显。span较长的实体是指区间较长的实体,简单理解就是长度较长的实体。小样本ner是指标注数据较少的要素抽取。bert-flat-crf模型结构如图2所示。其中,模型细节如下:对合同文本信息每个token(字符/词)增加起始(head)和终止(tail)位置,将合同文本信息建模,得到batc_sice(批次大小)*max_len(文本长度)的二维矩阵,并将lattice结构扁平化,通过预训练模型得到三维矩阵,由self-attention实现字和词之间的信息交互,充分得到合同文本的表征,最后将表征输入到crf(条件随机场)来抽取出合同文本中的各个要素字段信息。lattice表示字/词组成的新短语,如和平、饭店组合的和平饭店就是lattice。此外,bert-flat模型中,bert生成语义稠密矩阵,flat将文字的词汇进行编码,引入词汇信息和相对位置信息,对小样本的中文ner增益明显,同时采用eda数据增强,增加语料的多样性。最后结合后处理规则,对错位字段信息进行纠正,对模型未抽取的字段信息进行规则匹配,通过构建匹配库,对章印等问题进行相似度匹配的修复。
54.后处理优化,将模型抽取后的信息,通过规则进行错误纠正,相似匹配,错位纠正等操作,输出最终结果。具体地,错误纠正:主要是对于pdf为图片,要经过ocr识别出文本,对于识别的错别字进行纠正,受ocr识别错误而影响字段,如合同名称、甲方、乙方等。因为ocr受图片质量、翻转、章印等因素的影响。对于模型抽取的结果,进行正则优化,如税号、银行账号、联系方式,去除模型多抽的错误字符等情况。相似匹配:对于pdf为图片的合同,通过difflib等相似算法,对于甲乙方建立字典库,进行相似匹配,字典库也可以完善甲乙方的其他信息,如法人、税号等,也可以利用相似匹配,对模型抽取的结果进行纠正。错位纠正:主要是对模型抽取的结果使用正则进行纠正,问题如甲乙方错位,通过特定甲乙方的标志,如甲方、委托人、买方等。
55.本实施例采用bert-flat模型结合数据增强技术eda和后处理规则将抽取的要素核心字段提升到92.3%,非核心字段提升到75.8%。
56.综上所述,本技术提供一种基于样本数据增强的篇章级合同抽取方法,通过获取待处理合同,并判断所述待处理合同的文本类型;然后基于所述待处理合同的文本类型确定所述待处理合同的文本抽取方式;再按照确定的文本抽取方式对所述待处理合同进行段
落和章节信息抽取,并根据章节分级标志使用正则匹配进行划分,将划分后的章节信息分别加在所属的句子开头;再然后根据要素数据类型,对划分后的章节信息进行数据加强;最后采用预设网络模型从完成数据增强后的章节信息进行信息抽取,并将预设网络模型抽取的信息通过规则进行错误纠正、相似匹配和错位纠正,输出最终结果。通过本方法记载的技术方案,本方法可以从合同中抽取出合同名称、甲方账户名、乙方账户名、合同税率、金额币种、金额是否含税、开始时间、截止日期、甲方银行账号、乙方银行账号、甲方税号、乙方税号、甲方法人以及乙方法人等要素信息,而且对于合同名称、甲方账户名、乙方账户名、合同税率、金额币种、金额是否含税、开始时间和截止日期这8个核心字段可达到92.3%的准确率,对于甲方银行账号、乙方银行账号、甲方税号、乙方税号、甲方法人、乙方法人等25个字段可以实现75.8%的准确率。
57.如图3所示,本技术还提供一种基于样本数据增强的篇章级合同抽取系统,所述方法包括有:
58.数据采集模块310,用于获取待处理合同,并判断所述待处理合同的文本类型。在本实施例中,所述待处理合同的文本类型包括:图像格式的pdf文本类型、可编辑格式的pdf文本类型和word文本类型。其中,文件类型和合同抽取之间的关联主要是文件中文本的获取方式。word是可读文件,可以直接获取相应的文本信息。pdf分为可读文件和不可读文件,其中可读文件可以直接获取到文本信息;不可读文件如png图片等格式需要通过ocr识别获取到文本信息。word和pdf的文本获取成功后的处理是一样的。
59.抽取方式模块320,用于根据所述待处理合同的文本类型确定所述待处理合同的文本抽取方式。在本实施例中,pdf分两类只是为了区分pdf内文本的获取方式不同,一个可直接读取文本内容,一个需要通过ocr识别的文本,且两类pdf文本后续的文本处理过程一样。
60.划分模块330,用于按照确定的文本抽取方式对所述待处理合同进行段落和章节信息抽取,并根据章节分级标志使用正则匹配进行划分,将划分后的章节信息分别加在所属的句子开头;
61.数据加强模块340,用于根据要素数据类型,对划分后的章节信息进行数据加强。作为示例,本实施例对划分后的章节信息进行数据加强的过程可以包括:对划分后的章节信息进行同义词替换、随机插入、随机替换与随机删除,以对划分后的章节信息进行数据扩充。作为示例,具体地,要增强的数据指:标注数据量较少的字段类型,如法人、委托代理人、项目经理、乙方地址等字段。eda数据增强,就是将这些较少标注数据,通过同义词替换、随机插入、随机替换与随机删除等方法将数据进行扩充,起到数据增强的作用。
62.信息抽取模块350,用于采用预设网络模型从完成数据增强后的章节信息进行信息抽取,并将预设网络模型抽取的信息通过规则进行错误纠正、相似匹配和错位纠正,输出最终结果。作为示例,具体地,错误纠正:主要是对于pdf为图片,要经过ocr识别出文本,对于识别的错别字进行纠正,受ocr识别错误而影响字段,如合同名称、甲方、乙方等。因为ocr受图片质量、翻转、章印等因素的影响。对于模型抽取的结果,进行正则优化,如税号、银行账号、联系方式,去除模型多抽的错误字符等情况。相似匹配:对于pdf为图片的合同,通过difflib等相似算法,对于甲乙方建立字典库,进行相似匹配,字典库也可以完善甲乙方的其他信息,如法人、税号等,也可以利用相似匹配,对模型抽取的结果进行纠正。错位纠正:
主要是对模型抽取的结果使用正则进行纠正,问题如甲乙方错位,通过特定甲乙方的标志,如甲方、委托人、买方等。
63.根据上述记载,在一示例性实施例中,预设网络模型的网络结构如图2所示。在图2中,图中参数定义:d
tt
表示尾实体尾实体的位置矩阵。d
th
表示尾实体头实体的位置矩阵。d
ht
表示头实体尾实体的位置矩阵。d
hh
表示头实体头实体的位置矩阵。linear&crf表示线性条件随机场,一种判别式概率模型,其参数优化方法是针对目标函数的极大似然估计。add&norm表示求和与归一化。ffn表示全连接层。add&norm表示求和与归一化。self-attention表示自注意力机制,能够无视词之间的距离直接计算依赖关系,学习一个句子的内部结构。embedding表示嵌入层,将字/词转换为实向量。token表示文本中各个字/词。head表示头实体。tail表示尾实体。
64.其中,采用预设网络模型从完成数据增强后的章节信息进行信息抽取的过程包括:对合同文本信息每个字符或词增加起始位置和终止位置;基于合同文本信息进行建模,得到批次大小*文本长度的二维矩阵,并将字或词组成的新短语结构进行扁平化处理,通过预训练模型得到三维矩阵;根据自注意力机制实现字和词之间的信息交互,得到合同文本的表征;将得到的表征输入到条件随机场中,抽取出合同文本中的各个要素字段信息。作为示例,在本实施例中,抽取的要素字段信息包括以下至少之一:合同名称、甲方账户名、乙方账户名、合同税率、金额币种、金额是否含税、开始时间、截止日期、甲方银行账号、乙方银行账号、甲方税号、乙方税号、甲方法人、乙方法人。
65.通过本实施例记载的技术方案,本实施例可以从合同中抽取出合同名称、甲方账户名、乙方账户名、合同税率、金额币种、金额是否含税、开始时间、截止日期、甲方银行账号、乙方银行账号、甲方税号、乙方税号、甲方法人以及乙方法人等要素信息,而且对于合同名称、甲方账户名、乙方账户名、合同税率、金额币种、金额是否含税、开始时间和截止日期这8个核心字段可达到92.3%的准确率,对于甲方银行账号、乙方银行账号、甲方税号、乙方税号、甲方法人、乙方法人等25个字段可以实现75.8%的准确率。
66.此外,发明人发现,合同文本中存在大量的半结构化文本和少量的表格,如甲乙双方的基本信息等,其中表格信息、段落信息和章节信息,现有任务无法很好的利用这三者的联系,主要方法是将合同文本按段落划分区间,再结合章节信息来进行组合,将组合信息输入模型中,而表格信息没有结合章节、段落信息处理,容易产生错位、混淆等问题。
67.因此,本技术还提供另一示例性实施例,该实施例包括一种基于bert-flat-crf的基于样本数据增强的篇章级合同抽取系统,用于执行以下步骤:
68.判断文件类型,分为pdf和word分别解析,其中pdf分为png图片格式和pdf可编辑文件。其中,文件类型和合同抽取之间的关联主要是文件中文本的获取方式。word是可读文件,可以直接获取相应的文本信息。pdf分为可读文件和不可读文件,其中可读文件可以直接获取到文本信息;不可读文件如png图片等格式需要通过ocr识别获取到文本信息。word和pdf的文本获取成功后的处理是一样的。pdf分两类只是为了区分pdf内文本的获取方式不同,一个可直接读取文本内容,一个需要通过ocr识别的文本,且两类pdf文本后续的文本处理过程一样。
69.段落和章节信息抽取,根据章节分级标志使用正则匹配进行划分,划分后将章节信息分别加在所属的句子开头。
70.数据增强,根据要素数据类型,进行eda数据增强,增加语料的多样性。其中,要增强的数据指:标注数据量较少的字段类型,如法人、委托代理人、项目经理、乙方地址等字段。eda数据增强,就是将这些较少标注数据,通过同义词替换、随机插入、随机替换与随机删除等方法将数据进行扩充,起到数据增强的作用。
71.模型结构,采用bert-flat-crf模型,可以强化实体,特别是span较长的实体,同时引入词汇信息,对小样本ner增益明显。span较长的实体是指区间较长的实体,简单理解就是长度较长的实体。小样本ner是指标注数据较少的要素抽取。bert-flat-crf模型结构如图2所示。其中,模型细节如下:对合同文本信息每个token(字符/词)增加起始(head)和终止(tail)位置,将合同文本信息建模,得到batc_sice(批次大小)*max_len(文本长度)的二维矩阵,并将lattice结构扁平化,通过预训练模型得到三维矩阵,由self-attention实现字和词之间的信息交互,充分得到合同文本的表征,最后将表征输入到crf(条件随机场)来抽取出合同文本中的各个要素字段信息。lattice表示字/词组成的新短语,如和平、饭店组合的和平饭店就是lattice。此外,bert-flat模型中,bert生成语义稠密矩阵,flat将文字的词汇进行编码,引入词汇信息和相对位置信息,对小样本的中文ner增益明显,同时采用eda数据增强,增加语料的多样性。最后结合后处理规则,对错位字段信息进行纠正,对模型未抽取的字段信息进行规则匹配,通过构建匹配库,对章印等问题进行相似度匹配的修复。
72.后处理优化,将模型抽取后的信息,通过规则进行错误纠正,相似匹配,错位纠正等操作,输出最终结果。具体地,错误纠正:主要是对于pdf为图片,要经过ocr识别出文本,对于识别的错别字进行纠正,受ocr识别错误而影响字段,如合同名称、甲方、乙方等。因为ocr受图片质量、翻转、章印等因素的影响。对于模型抽取的结果,进行正则优化,如税号、银行账号、联系方式,去除模型多抽的错误字符等情况。相似匹配:对于pdf为图片的合同,通过difflib等相似算法,对于甲乙方建立字典库,进行相似匹配,字典库也可以完善甲乙方的其他信息,如法人、税号等,也可以利用相似匹配,对模型抽取的结果进行纠正。错位纠正:主要是对模型抽取的结果使用正则进行纠正,问题如甲乙方错位,通过特定甲乙方的标志,如甲方、委托人、买方等。
73.本实施例采用bert-flat模型结合数据增强技术eda和后处理规则将抽取的要素核心字段提升到92.3%,非核心字段提升到75.8%。
74.综上所述,本技术提供一种基于样本数据增强的篇章级合同抽取方法,通过获取待处理合同,并判断所述待处理合同的文本类型;然后基于所述待处理合同的文本类型确定所述待处理合同的文本抽取方式;再按照确定的文本抽取方式对所述待处理合同进行段落和章节信息抽取,并根据章节分级标志使用正则匹配进行划分,将划分后的章节信息分别加在所属的句子开头;再然后根据要素数据类型,对划分后的章节信息进行数据加强;最后采用预设网络模型从完成数据增强后的章节信息进行信息抽取,并将预设网络模型抽取的信息通过规则进行错误纠正、相似匹配和错位纠正,输出最终结果。通过本方法记载的技术方案,本方法可以从合同中抽取出合同名称、甲方账户名、乙方账户名、合同税率、金额币种、金额是否含税、开始时间、截止日期、甲方银行账号、乙方银行账号、甲方税号、乙方税号、甲方法人以及乙方法人等要素信息,而且对于合同名称、甲方账户名、乙方账户名、合同税率、金额币种、金额是否含税、开始时间和截止日期这8个核心字段可达到92.3%的准确率,对于甲方银行账号、乙方银行账号、甲方税号、乙方税号、甲方法人、乙方法人等25个字
段可以实现75.8%的准确率。
75.需要说明的是,上述实施例所提供基于样本数据增强的篇章级合同抽取系统与上述实施例所提供的基于样本数据增强的篇章级合同抽取方法属于同一构思,其中各个模块和单元执行操作的具体方式已经在方法实施例中进行了详细描述,此处不再赘述。上述实施例所提供的基于样本数据增强的篇章级合同抽取系统在实际应用中,可以根据需要而将上述功能分配由不同的功能模块完成,即将系统的内部结构划分成不同的功能模块,以完成以上描述的全部或者部分功能,本处也不对此进行限制。
76.上述实施例仅例示性说明本技术的原理及其功效,而非用于限制本技术。任何熟悉此技术的人士皆可在不违背本技术的精神及范畴下,对上述实施例进行修饰或改变。因此,举凡所属技术领域中具有通常知识者在未脱离本技术所揭示的精神与技术思想下所完成的一切等效修饰或改变,仍应由本技术的权利要求所涵盖。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1