一种基于交叉注意力的多模态融合小波知识蒸馏的视频行为识别方法及系统
1.本发明涉及一种基于交叉注意力的多模态融合小波知识蒸馏的视频行为识别方法及系统,属于行为识别、传感器技术、机器学习等交叉技术领域。
背景技术:
2.随着深度学习和计算机视觉的发展,行为识别由于其在视频监控系统、视频检索、人机交互等领域的广泛应用而受到广泛关注,尤其是基于视频和图像的行为识别方法和模型被广泛应用到现实生活领域。然而,首先,基于视觉传感器的方法很大程度上依赖视频、图像的质量。若摄像头分辨率低或被遮挡,获取的图像或视频质量差,很容易影响行为识别的效果,这也是视频行为识别方法在实际应用中的瓶颈。其次,基于视频的行为识别方法计算量大,需要有复杂计算能力的硬件设备支持,增加了成本。除此之外,针对像银行等需要隐私保护的场所,视觉传感器数据不可得的情况下,基于视频的行为识别方法便无法实现。基于可穿戴传感器方法可以解决视频行为识别方法的问题。通过智能手表或者智能手机中的传感器获得基于时间的三轴加速度、陀螺仪、方向信号等一维数据来获取人的行为变化。基于可穿戴传感器的行为识别方法不依赖于视频和图像,提供了在隐私保护的场景下进行行为识别的可能性。
3.随着智慧城市和智慧医疗的普及和需求的增加,基于可穿戴传感器的人体行为识别已经成为了人类活动认知的关键研究领域。虽然已经提出了一些基于可穿戴传感器的行为识别方法,并取得了良好的效果,但这些方法大多只考虑了可穿戴传感器的时间序列数据,对视觉传感器与可穿戴传感器数据之间的互补关系考虑较少。因此,利用来自视觉传感器和可穿戴传感器不同模态的动作信息,来提高行为的识别性能是相当重要的。
技术实现要素:
4.针对现有技术的不足,本发明提出了一种基于交叉注意力的多模态融合小波知识蒸馏的视频行为识别方法。
5.本发明提出了一种基于交叉注意力的多模态小波知识蒸馏算法,充分利用可穿戴传感器和视觉传感器信息,通过多模态交叉注意力进行不同模态信息的充分融合,利用小波知识蒸馏指导视频进行识别。
6.本发明提出了一种用于可穿戴传感器和视频数据的基于交叉注意力的多模态小波知识蒸馏模型。该模型的贡献是:1)通过空洞卷积、注意力机制构造卷积网络对可穿戴传感器数据进行特征提取,增大感受野;2)通过交叉注意力模块针对多个模态的可穿戴传感器数据进行融合,以获取到不同模态的互补信息,为下一步蒸馏提供更多的先验知识;3)通过离散小波变换将教师网络和学生网络的最后一个池化层替换,为了减少噪声,只保留低频特征,提取有用信息,再通过蒸馏来指导学生网络的视频数据进行行为识别,提高识别性能。
7.术语解释:
8.1、imagenet数据集,是一个计算机视觉数据集,是由斯坦福大学的李飞飞教授带领创建。该数据集包合14,197,122张图片和21,841个synset索引。synset是wordnet层次结构中的一个节点,它又是一组同义词集合。imagenet数据集一直是评估图像分类算法性能的基准。imagenet数据集是为了促进计算机图像识别技术的发展而设立的一个大型图像数据集。2016年imagenet数据集中已经超过干万张图片,每一张图片都被手工标定好类别。imagenet数据集中的图片涵盖了大部分生活中会看到的图片类别。imagenet最初是拥有超过100万张图像的数据集。
9.2、bninception网络,是cnn分类器发展史上一个重要的里程碑。在inception出现之前,大部分流行cnn仅仅是把卷积层堆叠得越来越多,使网络越来越深,以此希望能够得到更好的性能。inception的第二个版本也称作bn-inception,主要是引入了深度学习的一项重要的技术 batch normalization(bn)批处理规范化。bn技术的使用,使得数据在从一层网络进入到另外一层网络之前进行规范化,可以获得更高的准确率和训练速度。
10.3、vgg网络,是牛津大学计算机视觉组和google deepmind公司的研究员仪器研发的深度卷积神经网络。vgg主要探究了卷积神经网络的深度和其性能之间的关系,通过反复堆叠3*3的小卷积核和2*2的最大池化层,vggnet成功的搭建了16-19层的深度卷积神经网络。与之前的网络结构相比,错误率大幅度下降;同时,vgg的泛化能力非常好,在不同的图片数据集上都有良好的表现。到目前为止,vgg依然经常被用来提取特征图像。
11.4、resnet网络,由微软研究院的何恺明、张祥雨、任少卿、孙剑提出。研究动机是为了解决深度网络的退化问题,不同于过去的网络是通过学习去拟合一个分布,resnet通过学习去拟合相对于上一层输出的残差。
12.本发明的技术方案为:
13.一种基于交叉注意力的多模态融合小波知识蒸馏的视频行为识别方法,包括步骤如下:
14.获取可穿戴传感器数据并进行处理:将可穿戴传感器数据的一维时间序列信号转换为二维图像表示;
15.搭建多模态注意力空洞卷积核残差网络即教师网络;
16.训练教师网络;
17.搭建学生网络;
18.最小化小波蒸馏损失、交叉熵损失来训练学生网络;
19.通过训练好的学生网络对可穿戴传感器-视频行为进行识别,得到识别结果。
20.根据本发明优选的,可穿戴传感器数据处理,包括:
21.首先,可穿戴传感器数据有三个轴向时间序列信号(x,y,z),定义其中一个轴向信号为 x={x1,
…
,xn},使用最小-最大归一化方法将原始信号x归一化到区间[-1,1]中,得到归一化信号如式(i)所示:
[0022][0023]
然后,用变换函数g将归一化信号变换到极坐标系统,它表示归一化振幅的余弦
角和从时间t开始的半径,如式(ⅱ)所示:
[0024][0025]
ti是指时间戳,θi是指归一化振幅的余弦角;
[0026]
通过点和点之间的三角和获取时间间隔之间的相关系数,相关系数通过向量之间夹角的余弦计算,时间i和j之间的相关系数用cos(φi+φj)来计算,φi、φj分别为时间i和j的归一化振幅的余弦角;
[0027]
格莱姆角场的矩阵定义为g,如式(iii)所示:
[0028][0029]
假设每个长度为m的三轴传感器数据都转化为一个大小为m
×
m的gaf矩阵,将三轴传感器数据的gaf矩阵g组装为大小为m
×m×
3的三通道图像表示p={g
x
,gy,gz};m为三轴传感器数据的长度,g
x
、gy、gz分别是三轴传感器数据x轴、y轴和z轴的gaf矩阵;
[0030]
根据本发明优选的,多模态注意力空洞卷积核残差网络包括1个卷积层、1个bn层、1个激活函数层、4个max pooling层、5个sadrm模块、1个dwt模块、1个模态融合模块、1个全连接层;模态融合模块包括多个cva模块;
[0031]
通过卷积层、bn层、激活函数层、sadrm模块、max pooling层、dwt模块的搭建进行可穿戴传感器数据的特征提取,max pooling层进行下采样操作,dwt模块进行小波变换,多个cva模块处理不同模态间的融合,从多个cva模块获取的融合后的特征通过级联输入到全连接层。
[0032]
进一步优选的,sadrm模块包括1*1卷积层、堆叠的一个1*1卷积层和一个3*3卷积层、一个lka模块、堆叠的2个扩张率为2的3*3空洞卷积层和堆叠的2个扩张率为4的3*3空洞卷积层;
[0033]
教师网络的上一层特征图输入到sadrm模块中,分别经过上述各部分的计算处理,将得到的5 个计算结果和输入特征图进行相加,形成快捷连接,最终得到sadrm模块的输出stage,如式(ⅵ) 所示:
[0034][0035]
式(ⅵ)中,x为上一个阶段的输入,conv1×1表示1
×
1卷积操作,conv3×3表示3
×
3卷积操作, lka表示large kernel attention操作,dila3×3表示3
×
3空洞卷积操作。
[0036]
进一步优选的,sadrm模块中,对于堆叠的卷积层,假设第i层的感受野为rfi=a
1,i
×a2,i
,a
1,i
、 a
2,i
分别指感受野的长和宽,第i+1层的卷积核尺寸为k
i+1
×ki+1
,第i+1层的空洞卷积扩张率为d
i+1
,则第i+1层的感受野rf
i+1
如式(v)所示:
[0037]
rf
i+1
=[a
1,i
+(k
i+1-1)d
i+1
]
×
[a
2,i
+(k
i+1-1)d
i+1
]
ꢀꢀ
(v)
[0038]
式(v)中,rf0=1
×
1代表输入层的感受野。
[0039]
进一步优选的,lka模块如式(vi)、式(vii)所示:
[0040]
atten=conv1×1(dw-d-conv(dw-conv(x)))
ꢀꢀ
(vi)
[0041][0042]
式(vi)、式(vii)中,是输入特征,dw-conv是深度卷积,dw-d-conv是深度膨胀卷积,conv1×1代表一维通道卷积,是注意力映射,代表每个特征的重要性,代表元素积,y是指大内核注意力模块的输出。
[0043]
根据本发明优选的,dwt模块将数据按照不同的频率间隔分解成不同的分量,用于信号处理中的抗混叠,给定输入图像p,使用haar小波沿着行和列分别进行小波变换,分解成式(
ⅷ
)、式(
ⅸ
)、式(
ⅹ
)、式(
ⅺ
):
[0044]
p
ll
=lpl
t
ꢀꢀ
(
ⅷ
)
[0045]
p
lh
=hpl
t
ꢀꢀ
(
ⅸ
)
[0046]
p
hl
=lph
t
ꢀꢀ
(
ⅹ
)
[0047]
p
hh
=hph
t
ꢀꢀ
(
ⅺ
)
[0048]
式(
ⅷ
)、式(
ⅸ
)、式(
ⅹ
)、式(
ⅺ
)中,l为低通滤波矩阵,h为高通滤波矩阵,p是指给定输入图像,p
ll
、p
lh
、p
hl
和p
hh
分别是图像分解后的低频分量、水平高频分量、垂直高频分量和对角高频分量;选取低频分量p
ll
的作为dwt模块的输出;在教师网络的最后一个阶段用小波变换代替步长为2的最大池化层,如式(
ⅻ
)所示:
[0049]
maxpool
s=2
→
dwt
ll
ꢀꢀ
(
ⅻ
)
[0050]
式(
ⅻ
)中,maxpool
s=2
代表步长为2的最大池化层,dwt
ll
代表特征映射到低频分量的变换映射。
[0051]
根据本发明优选的,cva模块通过交叉注意力方法进行不同模态之间的信息融合,如式(xiii) 所示:
[0052][0053]
式(xiii)中,x,y代表不同的模态,wq、wk、wv为cva模块中计算query、key、value的权重矩阵、cva(x,y)代表交叉视角注意力,dk代表key的维度,softmax()代表softmax函数。
[0054]
根据本发明优选的,训练教师网络,包括:
[0055]
将可穿戴传感器数据转换成二维图像,二维图像送入搭建好的教师网络中进行迭代训练100 次,获得行为分类结果。
[0056]
根据本发明优选的,学生网络使用通过imagenet数据集预训练后的bninception网络、vgg 网络或resnet网络。
[0057]
根据本发明优选的,最小化小波蒸馏损失、交叉熵损失来训练学生网络,包括步骤如下:
[0058]
(1)获取教师网络和学生网络的小波蒸馏损失;
[0059]
(2)获取教师网络和学生网络的交叉熵损失;
[0060]
(3)通过梯度下降方法以总损失为目标来训练学生网络,得到训练好的学生网络。
[0061]
根据本发明优选的,教师网络和学生网络的小波蒸馏损失l
wkd
为教师网络的dwt模块的输出与学生网络的dwt模块的输出之间的l1损失,如式(xiv)所示:
[0062][0063]
式(xiv)中,ψs为学生网络小波变换层的输出,为教师网络i的小波变换层的输出,||
·
||1代表l1范数;
[0064]
教师网络和学生网络的交叉熵损失l
ce
如式(xv)所示:
[0065][0066]
式(xv)中,qc为第c类真实标签,为学生网络softmax层输出的对应行为类别c的概率;
[0067]
总损失l为如式(xvi)所示:
[0068]
l=(1-α)l
ce
+αl
wkd
ꢀꢀꢀꢀꢀ
(xvi)
[0069]
式(xvi)中,α为超参数。
[0070]
一种基于交叉注意力的多模态融合小波知识蒸馏的视频行为识别系统,包括:
[0071]
可穿戴传感器数据获取与处理模块,被配置为:获取可穿戴传感器数据并进行处理,将可穿戴传感器数据的一维时间序列信号转换为二维图像表示;
[0072]
多模态注意力空洞卷积核残差网络搭建模块,被配置为:搭建多模态注意力空洞卷积核残差网络;
[0073]
教师网络训练模块,被配置为:训练教师网络;
[0074]
学生网络搭建模块,被配置为:搭建学生网络;
[0075]
学生网络训练模块,被配置为:最小化小波蒸馏损失、交叉熵损失来训练学生网络;
[0076]
识别模块,被配置为:通过训练好的学生网络对可穿戴传感器-视频行为进行识别,得到识别结果。
[0077]
一种计算机设备,包括存储器和处理器,所述存储器存储有计算机程序,所述处理器执行所述计算机程序时实现基于交叉注意力的多模态融合小波知识蒸馏的视频行为识别方法的步骤。
[0078]
一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现基于交叉注意力的多模态融合小波知识蒸馏的视频行为识别方法的步骤。
[0079]
本发明的有益效果为:
[0080]
1、本发明为了考虑视觉传感器与可穿戴传感器数据之间的互补关系,提出了一种基于交叉注意力的多模态小波知识蒸馏算法。与现有的多数基于可穿戴传感器的行为识别方法相比,充分利用可穿戴传感器和视觉传感器信息,通过多模态交叉注意力进行不同模态信息的充分融合,利用小波知识蒸馏指导视频进行识别。
[0081]
2、本发明提出了多模态注意力空洞卷积核残差网络,将注意力机制从单模态扩展到多模态特征融合,将大内核注意力模块、空洞卷积、交叉注意力集成到多注意力空洞卷积核残差模块中,增加模态信息和不同模态信息的融合。
[0082]
3、本发明提出了使用可穿戴传感器数据指导视频数据进行行为识别的思想,通过小波蒸馏方法学习可穿戴传感器数据中的补充知识,通过小波变换过滤噪声,鲁棒性强。
[0083]
4、本发明利用知识蒸馏方法训练小型网络,对硬件要求小,可移植性强,有很大的
应用前景。
[0084]
5、本发明的知识蒸馏网络,不仅可以应用在识别方向,还可拓展到其他深度学习领域。
附图说明
[0085]
图1为本发明sadrm模块的结构示意图;
[0086]
图2为本发明cva模块通过交叉注意力方法进行不同模态之间的信息融合的示意图;
[0087]
图3为本发明多模态注意力空洞卷积核残差网络的结构示意图;
[0088]
图4为本发明一种基于交叉注意力的多模态融合小波知识蒸馏的视频行为识别方法的总体框图;
[0089]
图5为本发明教师网络和学生网络训练流程示意图。
具体实施方式
[0090]
下面结合说明书附图和实施例对本发明作进一步限定,但不限于此。
[0091]
实施例1
[0092]
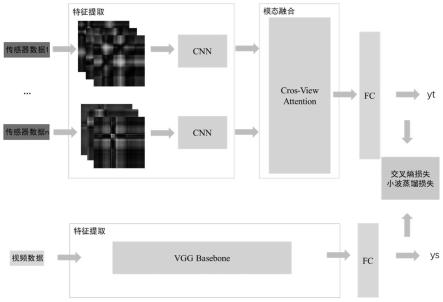
一种基于交叉注意力的多模态融合小波知识蒸馏的视频行为识别方法,如图4所示,包括步骤如下:
[0093]
获取可穿戴传感器数据并进行处理:为了使可穿戴式传感器的一维动作数据保持局部时间关系,将可穿戴传感器数据的一维时间序列信号转换为二维图像表示;
[0094]
搭建多模态注意力空洞卷积核残差网络即教师网络;
[0095]
训练教师网络;
[0096]
搭建学生网络;
[0097]
最小化小波蒸馏损失、交叉熵损失来训练学生网络;
[0098]
通过训练好的学生网络对可穿戴传感器-视频行为进行识别,得到识别结果。识别结果是指将输入的视频按照行为进行分类,比如视频中的行为是“扔东西”,通过训练好的网络识别后就归类到“扔东西”的类别中。
[0099]
实施例2
[0100]
根据实施例1所述的一种基于交叉注意力的多模态融合小波知识蒸馏的视频行为识别方法,其区别在于:
[0101]
可穿戴传感器数据处理,包括:
[0102]
首先,可穿戴传感器数据(包括加速度传感器、陀螺仪传感器、方向传感器等获取的数据)有三个轴向时间序列信号(x,y,z),定义其中一个轴向信号为x={x1,
…
,xn},使用最小-最大归一化方法将原始信号x归一化到区间[-1,1]中,得到归一化信号如式(i)所示:
[0103][0104]
然后,用变换函数g将归一化信号变换到极坐标系统,它表示归一化振幅的余弦
角和从时间t开始的半径,如式(ⅱ)所示:
[0105][0106]
ti是指时间戳,θi是指归一化振幅的余弦角;
[0107]
通过点和点之间的三角和获取时间间隔之间的相关系数,相关系数通过向量之间夹角的余弦计算,时间i和j之间的相关系数用cos(φi+φj)来计算,φi、φj分别为时间i和j的归一化振幅的余弦角;
[0108]
格莱姆角场(gaf)的矩阵定义为g,如式(iii)所示:
[0109][0110]
通过这种方法,格莱姆角场提供了一种新的表示风格,可以在时间戳增加以时间相关性的形式保存局部时间关系。基于可穿戴传感器的数据例如加速度、陀螺仪和方向信号的数据都是三轴样式的。因此,假设每个长度为m的三轴传感器数据都转化为一个大小为m
×
m的gaf矩阵,将三轴传感器数据的gaf矩阵g组装为大小为m
×m×
3的三通道图像表示p={g
x
,gy,gz};m为三轴传感器数据的长度,g
x
、gy、gz分别是三轴传感器数据x轴、y轴和z轴的gaf矩阵;
[0111]
如图3所示,多模态注意力空洞卷积核残差网络包括1个卷积层(convolution 7
×
7stride 2)、 1个bn层(batch normal)、1个激活函数层(leaky relu)、4个max pooling层、5个sadrm模块、1个dwt模块、1个模态融合模块、1个全连接层;模态融合模块包括多个cva模块;
[0112]
如图3所示,通过卷积层、bn层、激活函数层、sadrm模块、max pooling层、dwt模块的搭建进行可穿戴传感器数据的特征提取,max pooling层进行下采样操作,dwt模块进行小波变换,多个cva模块处理不同模态间的融合,从多个cva模块获取的融合后的特征通过级联输入到全连接层。
[0113]
因为传感器数据中包括多种模态,需要提取并融合多个模态中的最具代表性的特征。为了充分利用多个教师网络中各个模态的互补信息,将注意力机制从单模态扩展到多模态特征融合,将大内核注意力模块(large kernel attention,lka)、空洞卷积层(dilation convolution)、交叉注意力集成到多模态注意力空洞卷积核残差网络中。
[0114]
自注意力空洞卷积模块类似inception结构,如图1所示,sadrm模块(自注意力空洞卷积模块,self-attention dilation convolution residual model)包括1*1卷积层、堆叠的一个1*1 卷积层和一个3*3卷积层、一个lka模块(large kernel attention,大内核注意力模块)、堆叠的2个扩张率为2的3*3空洞卷积层(dilation convolution)和堆叠的2个扩张率为4的3*3 空洞卷积层;在网络中使用空洞卷积层可以在保持特征图中空间分辨率的前提下提取更全面的动作特征信息。
[0115]
教师网络的上一层特征图输入到sadrm模块中,分别经过上述各部分的计算处理,将得到的5 个计算结果和输入特征图进行相加,形成快捷连接,最终得到sadrm模块的输出stage,如式(ⅵ) 所示:
[0116][0117]
式(ⅵ)中,x为上一个阶段的输入,conv1×1表示1
×
1卷积操作,conv3×3表示3
×
3卷积操作, lka表示large kernel attention操作,dila3×3表示3
×
3空洞卷积操作。在sadrm模块中,通过同时使用lka模块、多个正常卷积和空洞卷积层,增加了网络的宽度和适应性,提高了网络提取不同尺度特征的能力,同时由于没有采用大的卷积核,有效控制了模型的参数,减少了计算量。另外,将残差网络中的快捷连接引入到sadrm模块中,抑制了深度神经网络常见的退化问题和梯度消失现象,增加了网络的深度,提高了模型的拟合能力。
[0118]
以往普通的卷积网络架构,通常由于卷积步长和反卷积操作丢失运动细节,会影响最终的行为识别效果。在行为识别的过程中需要详细的空间信息。为了解决这个问题,一种策略是保持特征图的分辨率不变,但是会增加模型的参数数量和计算量。而空洞卷积可以在不降低特征分辨率的前提下增加卷积核的感受野。在网络中使用空洞卷积可以在保持特征图空间分辨率的前提下提取更全面的动作特征信息,这对动作的识别具有重要的意义。因此,本发明在教师网络中使用了空洞卷积来提取更多的互补信息。
[0119]
每个sadrm模块中添加4个空洞卷积层,在图1中,每个sadrm模块中都添加了4个3*3的空洞卷积层,在图1中的第四条分支上的空洞卷积的膨胀率为2;第五条分支上的空洞卷积的膨胀率为4。sadrm模块中,对于堆叠的卷积层,假设第i层的感受野为rfi=a
1,i
×a2,i
,a
1,i
、a
2,i
分别指感受野的长和宽,比如3
×
3是指长和宽都为3的感受野大小。第i+1层的卷积核尺寸为k
i+1
×ki+1
,第i+1 层的空洞卷积扩张率为d
i+1
,则第i+1层的感受野rf
i+1
如式(v)所示:
[0120]
rf
i+1
=[a
1,i
+(k
i+1-1)d
i+1
]
×
[a
2,i
+(k
i+1-1)d
i+1
]
ꢀꢀ
(v)
[0121]
式(v)中,rf0=1
×
1代表输入层的感受野。
[0122]
考虑自注意力机制在2d图像问题上简单地处理成1d序列,忽视了图像的2d结构;针对高分辨率图像,计算量成指数爆炸,对处理器要求高,只考虑了空间维度信息,忽略了通道维度上的信息。为了解决这个问题,本发明使用包括注意力和卷积结合的大内核注意力模块,不仅具有自我注意力机制的适应性和长期依赖性,还具有卷积的优点,可以利用上下文信息。lka模块如式(vi)、式(vii)所示:
[0123]
atten=conv1×1(dw-d-conv(dw-conv(x)))
ꢀꢀ
(vi)
[0124][0125]
式(vi)、式(vii)中,是输入特征,dw-conv是深度卷积,dw-d-conv是深度膨胀卷积,conv1×1代表一维通道卷积,是注意力映射,代表每个特征的重要性,代表元素积,y是指大内核注意力模块的输出。
[0126]
dwt模块(discrete wavelet transform,离散小波变换)将数据按照不同的频率间隔分解成不同的分量,用于信号处理中的抗混叠,给定输入图像p,使用haar小波沿着行和列分别进行小波变换,分解成式(
ⅷ
)、式(
ⅸ
)、式(
ⅹ
)、式(
ⅺ
):
[0127]
p
ll
=lpl
t
ꢀꢀꢀ
(
ⅷ
)
[0128]
p
lh
=hpl
t
ꢀꢀꢀ
(
ⅸ
)
[0129]
p
hl
=lph
t
ꢀꢀꢀ
(
ⅹ
)
[0130]
p
hh
=hph
t
ꢀꢀ
(
ⅺ
)
[0131]
式(
ⅷ
)、式(
ⅸ
)、式(
ⅹ
)、式(
ⅺ
)中,l为低通滤波矩阵,h为高通滤波矩阵,p是指给定输入图像,p
ll
、p
lh
、p
hl
和p
hh
分别是图像分解后的低频分量、水平高频分量、垂直高频分量和对角高频分量;低频分量p
ll
代表着灰度或者亮度变化比较平缓的位置,高频分量中p
lh
、p
hl
和p
hh
则对应着图像中灰度或者亮度变化明显的位置,例如,噪声。为此,本发明考虑选取低频分量p
ll
的作为dwt模块的输出;一方面,低频分量按照规定的规则保持输入层的结构,使得输入图像补丁有更好的表示。另一方面,通过失去高频分量,可以抑制一些噪声。在教师网络的最后一个阶段用小波变换代替步长为2的最大池化层,如式(
ⅻ
)所示:
[0132]
maxpool
s=2
→
dwt
ll
ꢀꢀꢀꢀ
(
ⅻ
)
[0133]
式(
ⅻ
)中,maxpool
s=2
代表步长为2的最大池化层,dwt
ll
代表特征映射到低频分量的变换映射。
[0134]
在经过前面几个模块的特征提取后,cva模块(cross-view attention,交叉注意力)通过交叉注意力方法进行不同模态之间的信息融合,如式(xiii)所示:
[0135][0136]
式(xiii)中,x,y代表不同的模态,wq、wk、wv为cva模块中计算query、key、value的权重矩阵、cva(x,y)代表交叉视角注意力,dk代表key的维度,softmax()代表softmax函数。区别于以往的特征融合方法,这个方法通过注意力权重来确定模态信息的重要性。在交叉视角融合过程中,保持加速度、角速度等模态的嵌入维度和深度相似。多个cva模块通过图2的形式相互作用,以3个数据模态(m1,m2,m3)为例,其中任意2个模态(m1和m2,m1和m3,m2和m3) 的交叉视角注意力(cva)融合表示如式(xiii)所示,然后将3个cva结果通过级联的方法连在一起,再输入到全连接层。
[0137]
训练教师网络,如图5所示,包括:
[0138]
将可穿戴传感器数据(加速度、陀螺仪数据)通过格莱姆角场(gaf)的方法转换成二维图像,二维图像送入搭建好的教师网络中进行迭代训练100次,获得行为分类结果。
[0139]
学生网络使用通过imagenet数据集预训练后的bninception网络、vgg网络或resnet网络。
[0140]
最小化小波蒸馏损失、交叉熵损失来训练学生网络,如图5所示,包括步骤如下:
[0141]
(1)获取教师网络和学生网络的小波蒸馏损失;
[0142]
(2)获取教师网络和学生网络的交叉熵损失;
[0143]
(3)通过梯度下降方法以总损失为目标来训练学生网络,得到训练好的学生网络。
[0144]
一般的知识蒸馏损失为学生网络输出与教师网络输出之间的kl(kullback-leibler divergence)散度。和普通的知识蒸馏相比,教师网络和学生网络的小波蒸馏损失l
wkd
为教师网络的dwt模块的输出与学生网络的dwt模块的输出之间的l1损失,如式(xiv)所示:
[0145][0146]
式(xiv)中,ψs为学生网络小波变换层的输出,ψ
it
为教师网络i的小波变换层的
输出,||
·
||1代表l1范数;
[0147]
训练学生网络(如bninception网络)时,总损失除了包括小波知识蒸馏损失外,还包含学生网络输出与真实标签之间的交叉熵损失,教师网络和学生网络的交叉熵损失l
ce
如式(xv)所示:
[0148][0149]
式(xv)中,qc为第c类真实标签,为学生网络softmax层输出的对应行为类别c的概率;
[0150]
总损失l为如式(xvi)所示:
[0151]
l=(1-α)l
ce
+αl
wkd
ꢀꢀꢀꢀꢀꢀ
(xvi)
[0152]
式(xvi)中,α为超参数。
[0153]
选择公开数据集utd-mhad中的rgb视频数据和2个不同的可穿戴传感器模态数据(加速度和陀螺仪数据)。数据集包含27个不同的动作类别,由8名受试者重复4次。这个数据集有5种模式: rgb、深度、骨骼、kinect和惯性数据。视觉传感器的数据由kinect摄像头获得,而可穿戴传感器的数据由惯性传感器获得。
[0154]
将该发明中的方法与tsn、tsm、mflf、logits、at、cc方法做对比。
[0155]
tsn全名为temporal segment networks,采用稀疏采样的策略利用整个视频的信息,把视频分为3段,每个片段均匀地随机采样一个视频片段,并使用双流网络进行分类。
[0156]
tsm全名为temporal shift module,将部分信道沿时间维度进行移位,加强相邻帧之间的信息交互,具有高效、高性能的特点。
[0157]
mflf全名为multimodal feature-level fusion,提供了一种基于rgb、深度和惯性传感器的特征级融合方法,提高了人体动作分类的精度。
[0158]
logits、at和cc三种方法是知识蒸馏方法。
[0159]
本发明提出的方法设置如下:初始学习率为0.0002,迭代160次,α设为0.1。
[0160]
使用utd-mhad数据集进行,在utd-mhad数据集上各个方法的识别效果(%)如表1所示。
[0161]
表1
[0162][0163]
本发明的方法达到了98.61%的准确率,明显优于所列出的方法。
[0164]
实施例3
[0165]
一种基于交叉注意力的多模态融合小波知识蒸馏的视频行为识别系统,包括:
[0166]
可穿戴传感器数据获取与处理模块,被配置为:获取可穿戴传感器数据并进行处理,将可穿戴传感器数据的一维时间序列信号转换为二维图像表示;
[0167]
多模态注意力空洞卷积核残差网络搭建模块,被配置为:搭建多模态注意力空洞卷积核残差网络;
[0168]
教师网络训练模块,被配置为:训练教师网络;
[0169]
学生网络搭建模块,被配置为:搭建学生网络;
[0170]
学生网络训练模块,被配置为:最小化小波蒸馏损失、交叉熵损失来训练学生网络;
[0171]
识别模块,被配置为:通过训练好的学生网络对视频行为进行识别,得到识别结果。
[0172]
实施例4
[0173]
一种计算机设备,包括存储器和处理器,存储器存储有计算机程序,处理器执行计算机程序时实现实施例1或2所述基于交叉注意力的多模态融合小波知识蒸馏的视频行为识别方法的步骤。
[0174]
实施例5
[0175]
一种计算机可读存储介质,其上存储有计算机程序,计算机程序被处理器执行时实现实施例1 或2所述基于交叉注意力的多模态融合小波知识蒸馏的视频行为识别方法的步骤。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1