一种基于答题卡的学生作业时长采集方法与流程
1.本发明涉及教育信息化技术领域,具体地说,是一种基于答题卡的学生作业时长采集方法。
背景技术:
2.现有技术采集学生作业时长的方法分为手动识别和自动识别,手动识别是通过学生填写时长数字到纸质登记卡上,教师通过电脑手动录入excel后进行统计保存。自动识别的方法目前通常使用神经网络模型,通过采集的数据学习手写数字的特征。
3.手动识别的方法中,通过人工录入采集学生作业时长的方法效率低下,并且严重占用教师的额外教学时间,无法及时上报和存储学生作业时长数据。自动识别的方法中现有识别对噪声污染遮挡的优化方式存在固有缺陷,通过前期图像处理去噪等方法可能破坏手写图像本身的完整性,影响识别结果;且提高识别精度一般需要增加识别模型参数量,影响效率增加硬件成本。
4.为克服相关技术中存在的问题,本专利提供一种方法,实现了学生作业时长数据高效采集,解决了手写体本身多样性和噪声污染导致的识别不准确问题,同时优化了识别效率。
技术实现要素:
5.本发明的目的在于提供一种基于答题卡的学生作业时长采集方法,实现了学生作业时长数据高效采集,解决了手写体本身多样性和噪声污染导致的识别不准确问题,同时优化了识别效率。
6.本发明通过下述技术方案实现:一种基于答题卡的学生作业时长采集方法,包括以下步骤:步骤s1,将双重注意力机制加入训练识别模型生成的双重注意力识别模型;步骤s2,训练双重注意力识别模型并验证双重注意力识别模型的准确性后,输出训练好的双重注意力识别模型;步骤s3,获取学生作业答题卡的图像,将图像输入进训练好的双重注意力识别模型中,使用轻量级神经网络模型和转换的推理框架对输入的图像进行识别,并进行容错处理;步骤s4,将识别后的图像特征与双重注意力识别模型中的特征进行推理运算后,输出学生作答分类、数值和学生作业时长。
7.为了更好地实现本发明,进一步地,所述步骤s1包括:步骤s11,制作包含作业时长记录的答题卡;步骤s12,将答题卡打印分发给学生后通过扫描仪扫描上传答题卡图像;步骤s13,对答题卡图像进行图像预处理,获取第一学生作业时长填写区域及其对应的第一特征;
步骤s14,基于通道注意力机制和空间注意力机制对第一学生作业时长填写区域进行二次处理,第一次处理获取第二学生作业时长填写区域及其对应的第二特征,第二次处理获取第三学生作业时长填写区域及其对应的第三特征;步骤s15,根据双重注意力机制的二次处理构造完成双重注意力识别模型。
8.为了更好地实现本发明,进一步地,所述步骤s13包括:步骤s131,答题卡图像上传后对答题卡图像进行图像二值化处理将答题卡图像呈现为图a;步骤s132,通过傅里叶变化将图a转化为频域图像图b;步骤s133,采用低通滤波去除图b中的噪声,再使用傅里叶反变换将图b恢复为图c;步骤s134,使用连通域的几何约束在图c中判断定位点坐标,由坐标透视变换实现扫描的答题卡图像相比于图c的纠偏;步骤s135,根据纠偏后的答题卡图像获取第一学生作业时长填写区域及其对应的第一特征。
9.为了更好地实现本发明,进一步地,所述步骤s14包括:步骤s141,输入预处理后的图像,使用通道注意力机制将预处理后的图像进行卷积,获取多个通道c,每个通道c的分量组合起来形成整张图像的特征图,即第一学生作业时长填写区域及其对应的第一特征;步骤s142,将第一学生作业时长填写区域对应的第一特征进行全局最大池化和全局平均池化;再送入两层的神经网络中进行基于双重注意力机制的第一次处理,并输出第二学生作业时长填写区域及其对应的第二特征;步骤s143,将输出的第二特征基于点乘的加和操作和sigmoid激活函数激活操作生成最终的通道注意力特征mc;步骤s144,将最终的通道注意力特征mc和输入的第一特征进行点乘操作,生成第一次处理中通道注意力机制的输出特征ma;步骤s145,将所述第一次处理中通道注意力机制的输出特征ma作为第一次处理中空间注意力机制的输入特征;步骤s146,经过通道的全局最大池化和全局平均池化,得到两个尺寸相同的特征图。
10.为了更好地实现本发明,进一步地,所述步骤s15包括:步骤s151,将两个特征图在通道维度做拼接再进行卷积操作,降维为1个通道,再经过sigmoid激活函数生成空间注意力特征ms;步骤s152,最后空间注意力特征ms和空间注意力机制的输入特征做乘法,得到最终生成的第三特征。
11.为了更好地实现本发明,进一步地,所述步骤s2包括:使用pytorch框架和学习率预热机制训练双重注意力识别模型。
12.为了更好地实现本发明,进一步地,所述步骤s2还包括:在训练双重注意力识别模型的过程中,对双重注意力识别模型进行可视化分析,
并引入注意力机制后的神经网络对双重注意力识别模型进行验证。
13.为了更好地实现本发明,进一步地,所述步骤s3中的容错处理包括:当识别到只填写了十位,认为是个位数;当个位十位均未填写或者填写00,认为异常不记录该时长;返回的每一位数字输出其概率,当识别概率低于50%时抛出异常进入手动校验。
14.本发明与现有技术相比,具有以下优点及有益效果:(1)本发明通过图像预处理能够相对准确找到作答时长的区域;(2)本发明通过加入双重注意力机制,对图像遮挡,无关噪声的影响有较好的鲁棒性;(3)本发明选择轻量级神经网络模型以及对推理框架的转换实现了识别性能的提升;(4)本发明在答题卡上增加作答时长区,学生填写后系统扫描识别后自动识别时长数据的设计;(5)本发明优化采集作业时长过程中提供了提高手写识别准确性的算法。
附图说明
15.本发明结合下面附图和实施例做进一步说明,本发明所有构思创新应视为所公开内容和本发明保护范围。
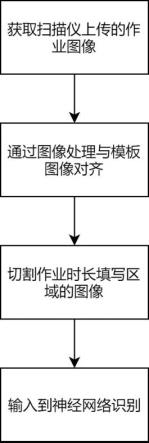
16.图1为本发明提供的一种基于答题卡的学生作业时长采集方法的整体流程图。
17.图2为本发明提供的作业时长采集的答题卡示意图。
18.图3为本发明提供的使用通道注意力机制的流程图。
19.图4为本发明提供的使用空间注意力机制的流程图。
20.图5为本发明提供的双重注意力识别模型的结构示意图。
具体实施方式
21.为了更清楚地说明本发明实施例的技术方案,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,应当理解,所描述的实施例仅仅是本发明的一部分实施例,而不是全部的实施例,因此不应被看作是对保护范围的限定。基于本发明中的实施例,本领域普通技术工作人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
22.实施例1:本实施例的一种基于答题卡的学生作业时长采集方法,如图2所示,在答题卡上方一区域制作两个并列矩形框作为填写区,记录矩形框在答题卡图像中的坐标信息,作为模板图像;作业打印分发给学生,学生在作业答题卡上作答完成后经过扫描仪扫描上传。
23.如图1-图5所示,上传后的图像通过图像处理算法与模板图像对齐,获取到作答时长填写框的真实坐标,然后切割填写的图像,通过数据增强获取训练图像。上传后的图像通过图像处理算法与模板图像对齐,获取到作答时长填写框的真实坐标,然后切割填写的图像,通过数据增强获取训练图像。在学校应用中,针对学生整个学期的单元作业制作专属的附带作业时长填涂区的答题卡,学生每次作业完成后进行填写,教师收集后通过高速扫描
仪扫描答题卡,扫描后通过图像配准等方法分割出作答时长区域,然后使用深度学习模型识别填写的数字并上传统计,省去了教师手动采集作业时长数据的时间,并且教师可及时查看结果数据。
24.在本发明中,将双重注意力机制加入训练识别模型生成双重注意力识别模型中的过程主要包括制作包含作业时长记录的答题卡;将答题卡打印分发给学生后通过扫描仪扫描上传答题卡图像;对答题卡图像进行图像预处理,此时是第一次图像预处理,会根据扫描仪扫描上传答题卡图像,如图2所示,第一次图像预处理先粗略扫描出大于作业时长采集框的部分,即获取第一学生作业时长填写区域及其对应的第一特征;具体过程为:答题卡图像上传后对答题卡图像进行图像二值化处理将答题卡图像呈现为图a;通过傅里叶变化将图a转化为频域图像图b;采用低通滤波去除图b中的噪声,再使用傅里叶反变换将图b恢复为图c;使用连通域的几何约束在图c中判断定位点坐标,由坐标透视变换实现扫描的答题卡图像相比于图c的纠偏;根据纠偏后的答题卡图像获取第一学生作业时长填写区域及其对应的第一特征。
25.第二次对图像处理是指对粗略扫描出的大于作业时长采集框的部分进行细致扫描,即基于通道注意力机制和空间注意力机制对第一学生作业时长填写区域进行二次处理,第一次处理获取第二学生作业时长填写区域及其对应的第二特征,第二次处理获取第三学生作业时长填写区域及其对应的第三特征;具体过程为:输入预处理后的图像,使用通道注意力机制将预处理后的图像进行卷积,获取多个通道c,每个通道c的分量组合起来形成整张图像的特征图,即第一学生作业时长填写区域及其对应的第一特征;将第一学生作业时长填写区域对应的第一特征进行全局最大池化和全局平均池化;再送入两层的神经网络中进行基于双重注意力机制的第一次处理,并输出第二学生作业时长填写区域及其对应的第二特征;将输出的第二特征基于点乘的加和操作和sigmoid激活函数激活操作生成最终的通道注意力特征mc;将最终的通道注意力特征mc和输入的第一特征进行element-wise操作,生成第一次处理中通道注意力机制的输出特征ma;将所述第一次处理中通道注意力机制的输出特征ma作为第一次处理中空间注意力机制的输入特征;经过通道的global max pooling 和global average pooling,得到两个的特征图;第三次对图像处理是指根据双重注意力机制的二次处理构造完成双重注意力识别模型。即将两个特征图在通道维度做拼接再进行卷积操作,降维为1个通道,再经过sigmoid激活函数生成空间注意力特征ms;最后空间注意力特征ms和空间注意力机制的输入特征做乘法,得到最终生成的第三特征。
26.实施例2:本实施例在实施例1的基础上做进一步优化,在本实施例中,首先进行数据准备,如图2所示,制作包含作答时长记录的答题卡,在答题卡上方一区域制作两个并列矩形框作为填写区,记录矩形框在答题卡图像中的坐标信息。作业打印分发给学生,学生作答完成后经过扫描仪扫描上传,上传后的图像通过图像处理算法与模板图像对齐,获取到作答时长填写框的真实坐标。然后切割填写的图像,通过数据增强获取训练图像。
27.本实施例的其他部分与实施例1相同,故不再赘述。
28.实施例3:本实施例在上述实施例1或2的基础上做进一步优化,通过一系列图像预处理以及
改进轻量级卷积神经网络mobilenet模型(轻量级卷积神经网络mobilenet模型即训练识别模型),进而识别图像。通过对轻量级卷积神经网络mobilenet模型引入双重注意力机制模块,提升网络识别的准确性。该模块由通道注意力机制和空间注意力机制两部分组成。
29.图像预处理的过程为:图像上传后首先做图像二值化,通过傅里叶变换转为频域图像,噪声主要由高频组成,采用低通滤波去除噪声,再使用傅里叶反变换恢复图像,去噪后的图像经过连通域的几何约束判断定位点坐标,由坐标透视变换实现扫描图像的纠偏,纠偏后的作业可获取到学生作答时长填写区域。
30.本实施例的其他部分与上述实施例1或2相同,故不再赘述。
31.实施例4:本实施例在上述实施例1-3任一项的基础上做进一步优化,本实施例训练卷积神经网络识别模型,在作业采集识别的图像中,只有填写的数字是真正有用的信息,而其它的区域边界框和噪声属于不需要关注的信息。真实场景中的采集区域经常有无关手写体的干扰,基于此,在网络中新增以下两个机制,提升网络识别准确性。
32.如图3所示,加入通道注意力机制:输入图像经过卷积之后得到多个通道c,每个通道的分量组合起来形成整张图像特征,但生成的每个通道对图像关键信息的贡献量是不同的,因此将生成的每个通道增加一个权重代表其与关键信息的相关度,权重越高的通道特征得到加强,无关通道的输出特征减弱。为有效计算通道注意力,使用平均池化对输入特征的空间维度压缩,最大池化收集通道独特的物体特征。输入的特征图f(h
×w×
c)分别经过global max pooling(全局最大池化)和global average pooling(全局平均池化),得到两个1
×1×
c的特征图,然后将它们分别送入一个两层的神经网络(mlp),之后将mlp输出的特征进行基于element-wise(点乘)的加和操作,再经过sigmoid激活操作,生成最终的通道注意力特征,即mc。最后,将mc和输入特征图f做element-wise操作,生成通道注意力模块需要的输入特征。
33.如图4所示,加入空间注意力机制:空间注意力聚焦图像特征中最具信息量的部分,聚焦手写图像本身,抑制作业采集框及打印扫描过程的噪声。将通道注意力的输出作为空间注意力的输入特征图。首先经过通道的global max pooling 和global average pooling,得到两个h
×w×
1 的特征图,然后将这两个特征图在通道维度做拼接。然后经过一个7
×
7卷积操作,降维为1个通道,即h
×w×
1。再经过sigmoid激活函数生成空间注意力特征,即ms。最后将该特征和该模块的输入特征做乘法,得到最终生成的特征。
34.本实施例采用两种注意力机制的组合提高识别的鲁棒性。
35.本实施例的其他部分与上述实施例1-3任一项相同,故不再赘述。
36.实施例5:本实施例在上述实施例1-4任一项基础上做进一步优化,双重注意力识别模型使用pytorch框架,包含7万张手写图像,刚开始训练时由于权重随机初始化,此时如果一个较大学习率可能导致模型不稳定,因此我们采用了学习率预热机制,在训练开始的时候使用较小的学习率,训练一个epoch(完成一次前向计算和反向传播的过程),之后使用0.001的学习率逐步衰减,每10个epoch学习率衰减为一半,一共迭代训练100个epoch。
37.双重注意力识别模型在第5个epoch时准确率达到95.2%,在第10个epoch时达到99.2%,模型收敛后的准确率在99.97%。通过对模型特征的可视化分析,在引入注意力机制
后的神经网络中,特征覆盖到了图像的更多关键区域,说明该网络注意到更加有用的局部特征,忽略了更多不相关信息,判别正确的可能性更高。
38.本实施例的其他部分与上述实施例1-4任一项相同,故不再赘述。
39.实施例6:本实施例在上述实施例1-5任一项基础上做进一步优化,一般来讲神经网络模型参数量大,在cpu上运算速度较慢。为了在cpu上实现快速识别,本文采用轻量级网络模型,并且通过转化为onnx(开放神经网络交换格式),转换过程加入常量折叠,相较于原生pytorch框架在识别速度上提升了约10倍。
40.本实施例还公开了一种识别后容错处理的方法:(1)当识别到只填写了十位,认为是个位数;(2)当个位十位均未填写或者填写00,认为异常不记录该时长;(3)返回的每一位数字输出其概率,当识别概率低于50%时抛出异常进入手动校验。
41.本实施例的其他部分与上述实施例1-5任一项相同,故不再赘述。
42.以上所述,仅是本发明的较佳实施例,并非对本发明做任何形式上的限制,凡是依据本发明的技术实质对以上实施例所做的任何简单修改、等同变化,均落入本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1