基于门控交叉单词-视觉注意力驱动的文本生成图像方法
1.本发明涉及计算机视觉及图像处理技术领域,具体涉及一种基于门控交叉单词-视觉注意力驱动的文本生成图像方法。
背景技术:
2.在爆发性的数据增长前提下,人们急需一种更高效的信息接收方式,文本可视化便是其中一种,它更容易让人们获取和理解复杂的文本信息,因此将文本转化成与之相符的图像成为了近年来一个重要的研究热点。
3.为加强文本信息和图像信息的融合,生成具有丰富细粒度信息的图像,目前的研究方法主要采用注意力机制,通过关注文本描述中的相关单词,在不同的图像子区域生成细粒度信息。然而若注意力机制不能一次性对每个单词在不同图像子区域的重要性产生准确的估计,那么重要的单词将被忽略,容易导致细粒度信息丢失。
技术实现要素:
4.本发明的目的是为了解决现有技术中的上述缺陷,提供一种基于门控交叉单词-视觉注意力驱动的文本生成图像方法,实现文本生成图像方法的基本单元为门控交叉单词-视觉注意力单元,该单元由单词到视觉注意力块、选择门、视觉到单词注意力块串联而成。其中,先通过单词到视觉注意力块得到生成图像上包含的相关单词的语义信息量,为选择重要的单词提供依据;然后通过选择门比较每个单词包含的语义信息量和生成图像上包含的相关单词的语义信息量来确定每个单词的重要性,选择出图像生成过程中重要的单词;再通过视觉到单词注意力块在图像子区域上生成相关单词的细粒度信息。通过多个阶段使用门控交叉单词-视觉注意力单元,并引入改进的目标函数,保证选择的重要单词不会丢失,生成细粒度信息更丰富,更符合文本描述的图像。
5.本发明的目的可以通过采取如下技术方案达到:
6.一种基于门控交叉单词-视觉注意力驱动的文本生成图像方法,所述文本生成图像方法包括以下步骤:
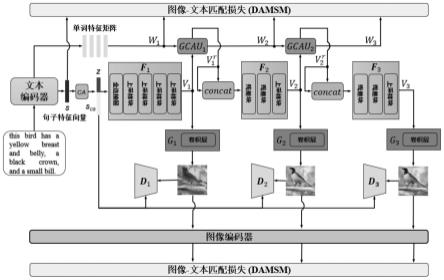
7.s1、从文本描述中提取句子特征向量和第一阶段的单词特征矩阵,并将句子特征向量通过条件增强处理得到条件特征向量,然后将条件特征向量和随机噪声向量一起输入第一阶段的视觉特征转换器,得到第一阶段的视觉特征矩阵,再将第一阶段的视觉特征矩阵输入第一阶段的生成器,得到第一分辨率图像,第一分辨率图像的分辨率为64
×
64;
8.s2、将第一阶段的单词特征矩阵和视觉特征矩阵输入第一阶段的门控交叉单词-视觉注意力单元,得到第一阶段细化的单词特征矩阵和细化的视觉特征矩阵,并将第一阶段细化的单词特征矩阵作为第二阶段的单词特征矩阵,然后将第一阶段细化的视觉特征矩阵输入第二阶段的视觉特征转换器,得到第二阶段的视觉特征矩阵,再将第二阶段的视觉特征矩阵输入第二阶段的生成器,得到第二分辨率图像,第二分辨率图像的分辨率为128
×
128;
9.s3、将第二阶段的单词特征矩阵和视觉特征矩阵输入第二阶段的门控交叉单词-视觉注意力单元,得到第二阶段细化的单词特征矩阵和细化的视觉特征矩阵,并将第二阶段细化的单词特征矩阵作为第三阶段的单词特征矩阵,然后将第二阶段细化的视觉特征矩阵输入第三阶段的视觉特征转换器,得到第三阶段的视觉特征矩阵,再将第三阶段的视觉特征矩阵输入第三阶段的生成器,得到第三分辨率图像,第三分辨率图像的分辨率为256
×
256;
10.s4、引入改进的目标函数,通过最小化目标函数增强每个阶段生成图像的真实性以及生成图像与文本描述的语义一致性,并将第三阶段生成的第三分辨率图像作为最终生成的高质量图像。
11.进一步地,所述第一、第二、第三阶段的单词特征矩阵均分别由多个单词特征向量构成,使用nw表示第一、第二、第三阶段单词特征矩阵中单词特征向量的个数,dw表示第一、第二、第三阶段单词特征向量的维度;所述第一、第二、第三阶段的视觉特征矩阵均分别由多个视觉特征向量构成,使用分别表示第一、第二、第三阶段视觉特征矩阵中视觉特征向量的个数,dv表示第一、第二、第三阶段视觉特征向量的维度。
12.进一步地,所述第一、第二阶段的门控交叉单词-视觉注意力单元均分别由单词到视觉注意力块、选择门、视觉到单词注意力块串联而成;所述第一阶段的视觉特征转换器由1个全连接层和4个上采样块串联而成,所述第二、第三阶段的视觉特征转换器均分别由2个残差块和1个上采样块串联而成;所述第一、第二、第三阶段的生成器均分别由1个3
×
3卷积层构成。
13.进一步地,所述第一阶段门控交叉单词-视觉注意力单元中的单词到视觉注意力块以第一阶段的视觉特征矩阵和单词特征矩阵作为输入,输出为第一阶段的局部视觉特征矩阵;所述第二阶段门控交叉单词-视觉注意力单元中的单词到视觉注意力块以第二阶段的视觉特征矩阵和单词特征矩阵作为输入,输出为第二阶段的局部视觉特征矩阵;单词到视觉注意力块的计算过程为:首先将输入的视觉特征矩阵通过1
×
1卷积层进行特征映射,得到处于单词特征语义空间的视觉特征矩阵;然后将输入的单词特征矩阵和处于单词特征语义空间的视觉特征矩阵通过矩阵乘法相乘,得到相似度矩阵;再沿最后一个维度对相似度矩阵进行归一化,得到注意力权重系数矩阵;接着将处于单词特征语义空间的视觉特征矩阵和注意力权重系数矩阵通过矩阵乘法相乘,得到视觉上下文特征矩阵;最后对视觉上下文特征矩阵和输入的单词特征矩阵进行特征拼接,并通过两个线性变换层和sigmoid激活函数,得到局部视觉特征矩阵;表达式如下:
[0014]vi
′
=mv(vi),i=1,2;
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(1)
[0015]
αi=softmax(w
itvi
′
),i=1,2;
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(2)
[0016][0017]
其中,vi表示输入的第i阶段的视觉特征矩阵,维度为wi表示输入的第i阶段的单词特征矩阵,维度为dw×nw
;vi′
表示第i阶段处于单词特征语义空间的视觉特征矩阵,维度为w
itvi
′
表示第i阶段的相似度矩阵,维度为αi表示第i阶段
的注意力权重系数矩阵,维度为vi′
α
it
表示第i阶段的视觉上下文特征矩阵,维度为dw×nw
;v
il
表示输出的第i阶段的局部视觉特征矩阵,维度为dw×nw
;mv()表示1
×
1卷积层,右下标v表示输入特征处于视觉特征语义空间;和表示第一、第二线性变换层,右下标w表示输入特征处于单词特征语义空间,的维度为dw×dw
,的维度为dw;σ()表示sigmoid激活函数,表示元素相乘,右上标t表示矩阵倒置。
[0018]
进一步地,所述第一、第二阶段门控交叉单词-视觉注意力单元中的单词到视觉注意力块首先通过注意力权重系数矩阵区分了包含相关单词语义信息的图像子区域,对于缺少或包含较少相关单词语义信息的图像子区域,其注意力权重系数更小,而对于包含较多相关单词语义信息的图像子区域,其注意力权重系数更大,然后通过视觉上下文特征矩阵融合了每个图像子区域包含的相关单词语义信息,再通过局部视觉特征矩阵,进一步抑制了缺乏或包含较少相关单词语义信息的图像子区域的注意力权重系数,更加准确地确定了生成图像包含的相关单词的语义信息量,从而为选择重要的单词提供基础。
[0019]
进一步地,所述第一阶段门控交叉单词-视觉注意力单元中的选择门以第一阶段的局部视觉特征矩阵和单词特征矩阵作为输入,输出为第一阶段细化的单词特征矩阵;所述第二阶段门控交叉单词-视觉注意力单元中的选择门以第二阶段的局部视觉特征矩阵和单词特征矩阵作为输入,输出为第二阶段细化的单词特征矩阵;选择门的计算过程为:将输入的局部视觉特征矩阵和单词特征矩阵通过两个线性变换层和sigmoid激活函数,得到细化的单词特征矩阵;表达式如下:
[0020][0021]
其中,v
il
表示输入的第i阶段的局部视觉特征矩阵,维度为dw×nw
;wi表示输入的第i阶段的单词特征矩阵,维度为dw×nw
;w
ir
表示输出的第i阶段细化的单词特征矩阵,维度为dw×nw
;和表示第一、第二线性变换层,右下标w表示输入特征处于单词特征语义空间,的维度为1
×dw
;σ()表示sigmoid激活函数。
[0022]
进一步地,所述第一、第二阶段的门控交叉单词-视觉注意力单元中的选择门通过两个线性变换层和sigmoid激活函数,比较每个单词包含的语义信息量和生成图像上包含的相关单词的语义信息量,当生成图像包含的相关单词的语义信息量远少于单词包含的语义信息量时,该单词的重要性显著提高,从而实现了重要单词的选择。
[0023]
进一步地,所述第一阶段门控交叉单词-视觉注意力单元中的视觉到单词注意力块以第一阶段细化的单词特征矩阵和视觉特征矩阵作为输入,输出为第一阶段细化的视觉特征矩阵;所述第二阶段门控交叉单词-视觉注意力单元中的视觉到单词注意力块以第二阶段细化的单词特征矩阵和视觉特征矩阵作为输入,输出为第二阶段细化的视觉特征矩阵;视觉到单词注意力块的计算过程为:首先将输入的细化的单词特征矩阵通过1
×
1卷积层进行特征映射,得到处于视觉特征语义空间的单词特征矩阵;然后将处于视觉特征语义空间的单词特征矩阵和输入的视觉特征矩阵通过矩阵乘法相乘,得到相似度矩阵;再沿最后一个维度对相似度矩阵进行归一化,得到注意力权重系数矩阵;接着将处于视觉特征语义空间的单词特征矩阵和注意力权重系数矩阵通过矩阵乘法相乘,得到单词上下文特征矩
表示第一阶段生成器输出的第一分辨率图像;concat()表示特征拼接函数,将多个输入特征矩阵拼接为一个输出特征矩阵。
[0036]
进一步地,所述步骤s2过程如下:
[0037]
定义第一阶段的门控交叉单词-视觉注意力单元使用公式(1)-(7)输出第一阶段细化的单词特征矩阵和细化的视觉特征矩阵的过程为gcau1(),定义第二阶段的视觉特征转换器输出第二阶段的视觉特征矩阵的过程为f2(),定义第二阶段的生成器输出第二分辨率图像的过程为g2(),表达式如下:
[0038][0039][0040][0041]
i2=g2(v2).
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(15)
[0042]
其中,表示第一阶段细化的单词特征矩阵,维度为dw×nw
;表示第一阶段细化的视觉特征矩阵,维度为w2表示第二阶段的单词特征矩阵,维度为dw×nw
;v2表示第二阶段的视觉特征矩阵,维度为i2表示第二阶段生成器输出的第二分辨率图像;concat()表示特征拼接函数,将多个输入特征矩阵拼接为一个输出特征矩阵。
[0043]
进一步地,所述步骤s3过程如下:
[0044]
定义第二阶段的门控交叉单词-视觉注意力单元使用公式(1)-(7)输出第二阶段细化的单词特征矩阵和细化的视觉特征矩阵的过程为gcau2(),定义第三阶段的视觉特征转换器输出第三阶段的视觉特征矩阵的过程为f3(),定义第三阶段的生成器输出第三分辨率图像的过程为g3(),表达式如下:
[0045][0046][0047][0048]
i3=g3(v3).
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(19)
[0049]
其中,表示第二阶段细化的单词特征矩阵,维度为dw×nw
;表示第二阶段细化的视觉特征矩阵,维度为w3表示第三阶段的单词特征矩阵,维度为dw×nw
;v3表示第三阶段的视觉特征矩阵,维度为i3表示第三阶段生成器输出的第三分辨率图像,也表示最终生成的高质量图像;concat()表示特征拼接函数,将多个输入特征矩阵拼接为一个输出特征矩阵。
[0050]
进一步地,步骤s3中第二阶段的单词特征矩阵即为第一阶段细化的单词特征矩阵,这样保证了第一阶段选择的重要单词在第二阶段的图像生成过程中不会丢失,从而可以继续丰富图像的细粒度信息。
[0051]
进一步地,所述步骤s4过程如下:
[0052]
定义改进的目标函数为l,表达式如下:
[0053][0054]
其中,表示第i阶段生成器的对抗损失函数,l
ca
表示条件增强损失函数;表示第i阶段改进的图像-文本匹配损失函数;λ1,λ2表示权重系数。
[0055]
进一步地,定义第i阶段生成器的对抗损失函数表达式如下:
[0056][0057]
其中,di()表示一个0~1之间的概率值,ii表示第i阶段生成器输出的图像,ii来自于第i阶段生成器生成的数据分布s表示句子特征向量。
[0058]
进一步地,定义条件增强损失函数为标准高斯分布和训练数据的高斯分布之间的kl散度,表达式如下:
[0059][0060]
其中,表示训练数据的高斯分布,μ(s)和∑(s)分别表示句子特征向量s的均值和对角线协方差矩阵;表示标准高斯分布。
[0061]
进一步地,定义第i阶段改进的图像-文本匹配损失函数表达式如下:
[0062][0063]
其中,表示第i阶段的单词级图像-文本匹配损失,表示第i阶段的句子级图像-文本匹配损失。
[0064]
进一步地,第i阶段单词级图像-文本匹配损失函数计算过程为:首先将第i阶段生成器输出的图像输入图像编码器,得到第i阶段的区域特征矩阵;然后将第i阶段的单词特征矩阵和区域特征矩阵通过矩阵乘法相乘,得到第i阶段的相似度矩阵;再沿每个维度对相似度矩阵进行归一化,得到第i阶段的注意力权重系数矩阵;接着将第i阶段的区域特征矩阵和注意力权重系数矩阵通过矩阵乘法相乘,得到第i阶段的区域上下文特征矩阵;最后将第i阶段的区域上下文特征矩阵和单词特征矩阵输入区域-单词匹配得分函数,得到第i阶段的单词级图像-文本匹配损失值;表达式如下:
[0065]
γi=softmax(θ1softmax(w
itri
)),i=1,2,3;
ꢀꢀꢀꢀꢀꢀꢀ
(24)
[0066]ci
=riγ
it
,i=1,2,3;
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(25)
[0067][0068][0069]
其中,wi表示第i阶段的单词特征矩阵,维度为dw×nw
;ri表示第i阶段的区域特征矩阵,维度为dw×
289;w
itri
表示第i阶段的相似度矩阵,维度为nw×
289;γi表示第i阶段的注意力权重系数矩阵,维度为nw×
289;ci表示第i阶段的区域上下文特征矩阵,维度为dw×nw
;表示第i阶段的区域上下文特征矩阵中第n个区域上下文特征向量,维度为dw;表
示第i阶段的单词特征矩阵中第n个单词特征向量,维度为dw;表示第i阶段的区域-单词匹配得分函数;表示m对区域-单词对,只有匹配w
ik
,其他的m-1对视为不匹配的区域-单词对;θ1,θ2,θ3分别表示第一、第二、第三超参数。
[0070]
进一步地,第i阶段句子级图像-文本匹配损失函数计算过程为:首先将第i阶段生成器输出的图像输入图像编码器,得到第i阶段的全局图像特征向量,然后将第i阶段的句子特征向量和全局图像特征向量输入图像-句子匹配得分函数,得到第i阶段的句子级图像-文本匹配损失值,表达式如下:
[0071][0072][0073]
其中,si表示第i阶段的句子特征向量,维度为ds;gi表示第i阶段的全局图像特征向量,维度为ds;表示第i阶段的图像-句子匹配得分函数;表示m对图像-句子对,只有匹配其他的m-1对视为不匹配的图像-句子对;θ4表示第四超参数。
[0074]
进一步地,生成器的对抗损失函数鼓励生成的图像尽可能真实,所述条件增强损失函数避免训练出现过拟合,图像-文本匹配损失函数的改进之处在于,单词级图像-文本匹配损失函数通过使用第一、第二、第三阶段的单词特征矩阵计算单词级图像-文本匹配损失值,鼓励每个单词尽可能匹配所关注的图像子区域,句子级图像-文本匹配损失函数鼓励生成的图像尽可能匹配文本描述。通过最小化所述的改进目标函数,保证生成细节更丰富、更真实、更符合文本描述的图像。
[0075]
本发明相对于现有技术具有如下的优点及效果:
[0076]
(1)本发明通过在文本生成图像的过程中使用门控交叉单词-视觉注意力单元,首先得到生成图像上包含的相关单词的语义信息量,然后选择重要的单词,进而在图像子区域上生成重要的细粒度信息。
[0077]
(2)通过多个阶段使用门控交叉单词-视觉注意力单元,并引入改进的目标函数,保证了选择的重要单词不会丢失,丰富了生成图像的细粒度信息,增强了生成图像与文本描述的匹配性。
[0078]
(3)在文本生成图像的基准数据集cub和ms-coco进行了实验,结果表明,与其他先进方法相比,本发明方法在图像质量和多样性评价指标is、fid以及图像-文本语义一致性评价指标r-precision上取得了领先性能,而且均优于segan和dm-gan,同时本发明的方法生成的图像细节更丰富,与真实图像更接近,与文本描述更加匹配。
附图说明
[0079]
此处所说明的附图用来提供对本发明的进一步理解,构成本技术的一部分,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。在附图中:
[0080]
图1是本发明公开的基于门控交叉单词-视觉注意力驱动的文本生成图像方法的流程图;
[0081]
图2是实施例二中的基于门控单词-视觉注意力驱动的文本生成图像方法的流程图;
[0082]
图3是本发明中的门控交叉单词-视觉注意力单元框架图;
[0083]
图4是本发明中的单词到视觉注意力框架图;
[0084]
图5是本发明中的视觉到单词注意力框架图;
[0085]
图6是实施例二中的门控单词-视觉注意力单元框架图。
具体实施方式
[0086]
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0087]
实施例一
[0088]
如图1所示,本实施例提供了一种基于门控交叉单词-视觉注意力驱动的文本生成图像方法,首先得到生成图像上包含的相关单词的语义信息量,然后选择重要的单词,进而在图像子区域上生成重要的细粒度信息。通过在多个阶段中使用门控交叉单词-视觉注意力单元,并引入改进的目标函数,保证了选择的重要单词不会丢失,丰富生成图像的细粒度信息,增强生成图像与文本描述的匹配性。具体包括以下步骤:
[0089]
s1、从文本描述中提取句子特征向量和第一阶段的单词特征矩阵,并将句子特征向量通过条件增强处理得到条件特征向量,然后将条件特征向量和随机噪声向量一起输入第一阶段的视觉特征转换器,得到第一阶段的视觉特征矩阵,再将第一阶段的视觉特征矩阵输入第一阶段的生成器,得到分辨率为64
×
64的图像,具体为:
[0090]
第一阶段的视觉特征转换器和生成器如图1所示,视觉特征转换器由1个全连接层和4个上采样块串联而成,生成器由1个3
×
3卷积层构成。
[0091]
定义提取句子特征向量和第一阶段的单词特征矩阵的过程为enc(),定义条件增强处理得到条件特征向量的过程为ca();定义第一阶段的视觉特征转换器输出第一阶段的视觉特征矩阵的过程为f1(),定义第一阶段的生成器输出分辨率为64
×
64的图像的过程为g1(),表达式如下:
[0092]
(s,w1)=enc(text);
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(1)
[0093]sca
=ca(s);
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(2)
[0094]v1
=f1(concat(s
ca
,z));
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(3)
[0095]
i1=g1(v1).
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(4)
[0096]
其中,text表示文本描述;s表示句子特征向量,维度为ds;w1表示第一阶段的单词特征矩阵,维度为dw×nw
;s
ca
表示条件特征向量,维度为ds;z表示服从标准正态分布的随机噪声向量,维度为dz;v1表示第一阶段的视觉特征矩阵,维度为i1表示第一阶段生成器输出的分辨率为64
×
64的图像;concat()表示特征拼接函数,将多个输入特征矩阵拼接为一个输出特征矩阵。
[0097]
s2、将第一阶段的单词特征矩阵和视觉特征矩阵输入第一阶段的门控交叉单词-视觉注意力单元,得到第一阶段细化的单词特征矩阵和细化的视觉特征矩阵,并将第一阶段细化的单词特征矩阵作为第二阶段的单词特征矩阵,然后将第一阶段细化的视觉特征矩阵输入第二阶段的视觉特征转换器,得到第二阶段的视觉特征矩阵,再将第二阶段的视觉特征矩阵输入第二阶段的生成器,得到分辨率为128
×
128的图像,具体为:
[0098]
第一阶段的门控交叉单词-视觉注意力单元如图3所示,由单词到视觉注意力块、选择门、视觉到单词注意力块串联而成;第二阶段的视觉特征转换器和生成器如图1所示,视觉特征转换器由2个残差块和1个上采样块串联而成,生成器由1个3
×
3卷积层构成。
[0099]
第一阶段门控交叉单词-视觉注意力单元中的单词到视觉注意力块如图4所示,以第一阶段的视觉特征矩阵和单词特征矩阵作为输入,输出为第一阶段的局部视觉特征矩阵,其计算过程为:首先将输入的视觉特征矩阵通过1
×
1卷积层进行特征映射,得到处于单词特征语义空间的视觉特征矩阵;然后将输入的单词特征矩阵和处于单词特征语义空间的视觉特征矩阵通过矩阵乘法相乘,得到相似度矩阵;再沿最后一个维度对相似度矩阵进行归一化,得到注意力权重系数矩阵;接着将处于单词特征语义空间的视觉特征矩阵和注意力权重系数矩阵通过矩阵乘法相乘,得到视觉上下文特征矩阵;最后对视觉上下文特征矩阵和输入的单词特征矩阵进行特征拼接,并通过两个线性变换层和sigmoid激活函数,得到局部视觉特征矩阵;表达式如下:
[0100]v′1=mv(v1);
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(5)
[0101]
α1=softmax(w
1tv′1);
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(6)
[0102][0103]
其中,v1表示输入的第一阶段的视觉特征矩阵,维度为w1表示输入的第一阶段的单词特征矩阵,维度为dw×nw
;v
′1表示第一阶段处于单词特征语义空间的视觉特征矩阵,维度为w
1tv′1表示第一阶段的相似度矩阵,维度为α1表示第一阶段的注意力权重系数矩阵,维度为v
′1α
1t
表示第一阶段的视觉上下文特征矩阵,维度为dw×nw
;表示输出的第一阶段的局部视觉特征矩阵,维度为dw×nw
;mv()表示1
×
1卷积层,右下标v表示输入特征处于视觉特征语义空间;和表示第一、第二线性变换层,右下标w表示输入特征处于单词特征语义空间,的维度为dw×dw
,的维度为dw;σ()表示sigmoid激活函数,表示元素相乘,t表示矩阵倒置。
[0104]
第一阶段门控交叉单词-视觉注意力单元中的选择门如图3所示,以第一阶段的局部视觉特征矩阵和单词特征矩阵作为输入,输出为第一阶段细化的单词特征矩阵,其计算过程为:将输入的局部视觉特征矩阵和单词特征矩阵通过两个线性变换层和sigmoid激活函数,得到细化的单词特征矩阵;表达式如下:
[0105][0106]
其中,表示输入的第一阶段的局部视觉特征矩阵,维度为dw×nw
;w1表示输入的
第一阶段的单词特征矩阵,维度为dw×nw
;表示输出的第一阶段细化的单词特征矩阵,维度为dw×nw
;和表示第一、第二线性变换层,右下标w表示输入特征处于单词特征语义空间,的维度为1
×dw
;σ()表示sigmoid激活函数。
[0107]
第一阶段门控交叉单词-视觉注意力单元中的视觉到单词注意力块如图5所示,以第一阶段细化的单词特征矩阵和视觉特征矩阵作为输入,输出为第一阶段细化的视觉特征矩阵,其计算过程为:首先将输入的细化的单词特征矩阵通过1
×
1卷积层进行特征映射,得到处于视觉特征语义空间的单词特征矩阵;然后将处于视觉特征语义空间的单词特征矩阵和输入的视觉特征矩阵通过矩阵乘法相乘,得到相似度矩阵;再沿最后一个维度对相似度矩阵进行归一化,得到注意力权重系数矩阵;接着将处于视觉特征语义空间的单词特征矩阵和注意力权重系数矩阵通过矩阵乘法相乘,得到单词上下文特征矩阵;最后对单词上下文特征矩阵和输入的视觉特征矩阵进行特征拼接,并通过两个线性变换层和sigmoid激活函数,得到细化的视觉特征矩阵;表达式如下:
[0108][0109][0110][0111]
其中,表示输入的第一阶段细化的单词特征矩阵,维度为dw×nw
;v1表示输入的第一阶段的视觉特征矩阵,维度为的第一阶段的视觉特征矩阵,维度为表示第一阶段处于视觉特征语义空间的单词特征矩阵,维度为dv×nw
;表示第一阶段的相似度矩阵,维度为β1表示第一阶段的注意力权重系数矩阵,维度为表示第一阶段的注意力权重系数矩阵,维度为表示第一阶段的单词上下文特征矩阵,维度为上下文特征矩阵,维度为表示输出的第一阶段细化的视觉特征矩阵,维度为mw()表示1
×
1卷积层,右下标w表示输入特征处于单词特征语义空间;和表示第一、第二线性变换层,右下标v表示输入特征处于视觉特征语义空间,的维度为dv×dv
,的维度为dv;σ()表示sigmoid激活函数,表示元素相乘,t表示矩阵倒置。
[0112]
定义第一阶段的门控交叉单词-视觉注意力单元使用公式(5)-(11)输出第一阶段细化的单词特征矩阵和细化的视觉特征矩阵的过程为gcau1(),定义第二阶段的视觉特征转换器输出第二阶段的视觉特征矩阵的过程为f2(),定义第二阶段的生成器输出分辨率为128
×
128的图像的过程为g2(),表达式如下:
[0113][0114]
[0115][0116]
i2=g2(v2).
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(15)
[0117]
其中,表示第一阶段细化的单词特征矩阵,维度为dw×nw
;表示第一阶段细化的视觉特征矩阵,维度为w2表示第二阶段的单词特征矩阵,维度为dw×nw
;v2表示第二阶段的视觉特征矩阵,维度为i2表示第二阶段生成器输出分辨率为128
×
128的图像;concat()表示特征拼接函数,将多个输入特征矩阵拼接为一个输出特征矩阵。
[0118]
s3、将第二阶段的单词特征矩阵和视觉特征矩阵输入第二阶段的门控交叉单词-视觉注意力单元,得到第二阶段细化的单词特征矩阵和细化的视觉特征矩阵,并将第二阶段细化的单词特征矩阵作为第三阶段的单词特征矩阵,然后将第二阶段细化的视觉特征矩阵输入第三阶段的视觉特征转换器,得到第三阶段的视觉特征矩阵,再将第三阶段的视觉特征矩阵输入第三阶段的生成器,得到分辨率为256
×
256的图像,具体为:
[0119]
第二阶段的门控交叉单词-视觉注意力单元如图3所示,由单词到视觉注意力块、选择门、视觉到单词注意力块串联而成;第三阶段的视觉特征转换器和生成器如图1所示,视觉特征转换器由2个残差块和1个上采样块串联而成,生成器由1个3
×
3卷积层构成。
[0120]
第二阶段的门控交叉单词-视觉注意力单元中的单词到视觉注意力块如图4所示,以第二阶段的视觉特征矩阵和单词特征矩阵作为输入,输出为第二阶段的局部视觉特征矩阵,其计算过程参照步骤s2第一阶段门控交叉单词-视觉注意力单元中单词到视觉注意力块的计算过程,表达式如下:
[0121]v′2=mv(v2);
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(16)
[0122]
α2=softmax(w
2tv′2);
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(17)
[0123][0124]
其中,v2表示输入的第二阶段的视觉特征矩阵,维度为w2表示输入的第二阶段的单词特征矩阵,维度为dw×nw
;v
′2表示第二阶段处于单词特征语义空间的视觉特征矩阵,维度为w
2tv′2表示第二阶段的相似度矩阵,维度为α2表示第二阶段的注意力权重系数矩阵,维度为v
′2α
2t
表示第二阶段的视觉上下文特征矩阵,维度为dw×nw
;表示输出的第二阶段的局部视觉特征矩阵,维度为dw×nw
;mv()表示1
×
1卷积层,右下标v表示输入特征处于视觉特征语义空间;和表示第一、第二线性变换层,右下标w表示输入特征处于单词特征语义空间,的维度为dw×dw
,的维度为dw;σ()表示sigmoid激活函数,表示元素相乘,t表示矩阵倒置。
[0125]
第二阶段的门控交叉单词-视觉注意力单元中的选择门如图3所示,以第二阶段的局部视觉特征矩阵和单词特征矩阵作为输入,输出为第二阶段细化的单词特征矩阵,其计算过程参照步骤s2第一阶段门控交叉单词-视觉注意力单元中选择门的计算过程,表达式
如下:
[0126][0127]
其中,表示输入的第二阶段的局部视觉特征矩阵,维度为dw×nw
;w2表示输入的第二阶段的单词特征矩阵,维度为dw×nw
;表示输出的第二阶段细化的单词特征矩阵,维度为dw×nw
;和表示第一、第二线性变换层,右下标w表示输入特征处于单词特征语义空间,的维度为1
×dw
;σ()表示sigmoid激活函数。
[0128]
第二阶段的门控交叉单词-视觉注意力单元中的视觉到单词注意力块如图5所示,以第二阶段细化的单词特征矩阵和视觉特征矩阵作为输入,输出为第二阶段细化的视觉特征矩阵,其计算过程参照步骤s2第一阶段门控交叉单词-视觉注意力单元中视觉到单词注意力块的计算过程,表达式如下:
[0129][0130][0131][0132]
其中,表示输入的第二阶段细化的单词特征矩阵,维度为dw×nw
;v2表示输入的第二阶段的视觉特征矩阵,维度为的第二阶段的视觉特征矩阵,维度为表示第二阶段处于视觉特征语义空间的单词特征矩阵,维度为dv×nw
;表示第二阶段的相似度矩阵,维度为β2表示第二阶段的注意力权重系数矩阵,维度为表示第二阶段的注意力权重系数矩阵,维度为表示第二阶段的单词上下文特征矩阵,维度为上下文特征矩阵,维度为表示输出的第二阶段细化的视觉特征矩阵,维度为mw()表示1
×
1卷积层,右下标w表示输入特征处于单词特征语义空间;和表示第一、第二线性变换层,右下标v表示输入特征处于视觉特征语义空间,的维度为dv×dv
,的维度为dv;σ()表示sigmoid激活函数,表示元素相乘,t表示矩阵倒置。
[0133]
定义第二阶段的门控交叉单词-视觉注意力单元使用公式(16)-(22)输出第二阶段细化的单词特征矩阵和细化的视觉特征矩阵的过程为gcau2(),定义第三阶段的视觉特征转换器输出第三阶段的视觉特征矩阵的过程为f3(),定义第三阶段的生成器输出分辨率为256
×
256的图像的过程为g3(),表达式如下:
[0134][0135][0136]
[0137]
i3=g3(v3).
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(26)
[0138]
其中,表示第二阶段细化的单词特征矩阵,维度为dw×nw
;表示第二阶段细化的视觉特征矩阵,维度为w3表示第三阶段的单词特征矩阵,维度为dw×nw
;v3表示第三阶段的视觉特征矩阵,维度为i3表示第三阶段生成器输出的分辨率为256
×
256的图像,也表示最终生成的高质量图像;concat()表示特征拼接函数,将多个输入特征矩阵拼接为一个输出特征矩阵。
[0139]
s4、引入改进的目标函数,通过最小化目标函数来增强每个阶段生成图像的真实性以及生成图像与文本描述的语义一致性,并将第三阶段生成的分辨率为256
×
256的图像作为最终生成的高质量图像,具体为:
[0140]
定义改进的目标函数为l,表达式如下:
[0141][0142]
其中,表示第i阶段生成器的对抗损失函数,l
ca
表示条件增强损失函数;表示第i阶段改进的图像-文本匹配损失函数;λ1,λ2表示权重系数。
[0143]
定义第i阶段生成器的对抗损失函数表达式如下:
[0144][0145]
其中,di()表示一个0~1之间的概率值,ii表示第i阶段生成器输出的图像,ii来自于第i阶段生成器生成的数据分布s表示句子特征向量。
[0146]
定义条件增强损失函数为标准高斯分布和训练数据的高斯分布之间的kl散度,表达式如下:
[0147][0148]
其中,表示训练数据的高斯分布,μ(s)和∑(s)分别表示句子特征向量s的均值和对角线协方差矩阵;表示标准高斯分布。
[0149]
定义第i阶段改进的图像-文本匹配损失函数表达式如下:
[0150][0151]
其中,表示第i阶段的单词级图像-文本匹配损失,表示第i阶段的句子级图像-文本匹配损失。
[0152]
第i阶段单词级图像-文本匹配损失函数计算过程为:首先将第i阶段生成器输出的图像输入图像编码器,得到第i阶段的区域特征矩阵;然后将第i阶段的单词特征矩阵和区域特征矩阵通过矩阵乘法相乘,得到第i阶段的相似度矩阵;再沿每个维度对相似度矩阵进行归一化,得到第i阶段的注意力权重系数矩阵;接着将第i阶段的区域特征矩阵和注意力权重系数矩阵通过矩阵乘法相乘,得到第i阶段的区域上下文特征矩阵;最后将第i阶段的区域上下文特征矩阵和单词特征矩阵输入区域-单词匹配得分函数,得到第i阶段的单词级图像-文本匹配损失值;表达式如下:
coco上的is指标达到31.19,fid指标达到24.39,r-precision指标达到90.92。进一步地,与该实施例最为接近的方法segan和dm-gan进行了对比,该实施例取得了更好的结果。首先,该实施例在基准数据集cub上的is指标(高优指标)比segan高2.78%,比dm-gan高1.05%,在基准数据集ms-coco上的is指标比segan高11.95%,比dm-gan高2.30%;其次,该实施例在基准数据集cub上的fid指标(低优指标)比segan低18.27%,比dm-gan低7.70%,在ms-coco数据集上的fid指标比segan低24.44%,比dm-gan低25.27%。
[0164]
实施例二
[0165]
如图2所示,本实施例提供了一种基于门控单词-视觉注意力驱动的文本生成图像方法,参照实施例一,本实施例技术手段有三处不同,第一处是该实施例中第一、第二阶段的门控单词-视觉注意力单元去除了单词到视觉注意力块;第二处是该实施例中第二阶段的门控单词-视觉注意力单元以第一阶段的单词特征矩阵和第二阶段的视觉特征矩阵作为输入;第三处是图像-文本匹配损失函数中单词级图像-文本匹配损失函数的计算过程不同;具体包括以下步骤:
[0166]
s1、参照实施例一中步骤s1;
[0167]
s2、将第一阶段的单词特征矩阵和视觉特征矩阵输入第一阶段的门控单词-视觉注意力单元,得到第一阶段细化的视觉特征矩阵,然后将第一阶段细化的视觉特征矩阵输入第二阶段的视觉特征转换器,得到第二阶段的视觉特征矩阵,再将第二阶段的视觉特征矩阵输入第二阶段的生成器,得到分辨率为128
×
128的图像,具体为:
[0168]
第一阶段的门控单词-视觉注意力单元如图6所示,由选择门、视觉到单词注意力块串联而成;第二阶段的视觉特征转换器和生成器如图2所示,视觉特征转换器由2个残差块和1个上采样块串联而成,生成器由1个3
×
3卷积层构成。
[0169]
第一阶段门控单词-视觉注意力单元中的选择门如图6所示,以第一阶段的单词特征矩阵和视觉特征矩阵作为输入,输出为第一阶段细化的单词特征矩阵,其计算过程为:首先将输入的视觉特征矩阵通过平均池化,得到全局视觉特征矩阵,然后将全局视觉特征矩阵和输入的单词特征矩阵通过两个线性变换层和sigmoid激活函数,得到细化的单词特征矩阵;表达式如下:
[0170][0171][0172]
其中,表示输入的第一阶段视觉特征矩阵中第n个视觉特征向量,维度为dv;v
1g
表示第一阶段的全局视觉特征矩阵,维度为dv×nw
;w1表示输入的第一阶段的单词特征矩阵,维度为dw×nw
;表示输出的第一阶段细化的单词特征矩阵,维度为dw×nw
;mv()表示1
×
1卷积层,右下标v表示输入特征处于视觉特征语义空间;和表示第一、第二线性变换层,右下标w表示输入特征处于单词特征语义空间,右下标v表示输入特征处于视觉特征语义空间,的维度为1
×dw
,的维度为1
×dv
;repeat()表示矩阵列复制,σ()表示sigmoid激活函数。
[0173]
第一阶段门控单词-视觉注意力单元中的视觉到单词注意力块参照实施例一步骤
s2第一阶段门控交叉单词-视觉注意力单元中的视觉到单词注意力块。
[0174]
定义第一阶段的门控单词-视觉注意力单元使用公式(37),(38),(9)-(11)输出第一阶段细化的视觉特征矩阵的过程为gau1(),定义第二阶段的视觉特征转换器输出第二阶段的视觉特征矩阵的过程为f2(),定义第二阶段的生成器输出分辨率为128
×
128的图像的过程为g2(),表达式如下:
[0175][0176][0177]
i2=g2(v2).
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(41)
[0178]
其中,表示第一阶段细化的视觉特征矩阵,维度为v2表示第二阶段的视觉特征矩阵,维度为i2表示第二阶段生成器输出的分辨率为128
×
128的图像;concat()表示特征拼接函数,将多个输入特征矩阵拼接为一个输出特征矩阵。
[0179]
s3、将第一阶段的单词特征矩阵和第二阶段的视觉特征矩阵输入第二阶段的门控单词-视觉注意力单元,得到第二阶段细化的视觉特征矩阵,然后将第二阶段细化的视觉特征矩阵输入第三阶段的视觉特征转换器,得到第三阶段的视觉特征矩阵,再将第三阶段的视觉特征矩阵输入第三阶段的生成器,得到分辨率为256
×
256的图像,具体为:
[0180]
第二阶段的门控单词-视觉注意力单元如图6所示,由选择门、视觉到单词注意力块串联而成;第三阶段的视觉特征转换器和生成器如图2所示,视觉特征转换器由2个残差块和1个上采样块串联而成,生成器由1个3
×
3卷积层构成。
[0181]
第二阶段的门控单词-视觉注意力单元中的选择门如图6所示,以第一阶段的单词特征矩阵和第二阶段的视觉特征矩阵作为输入,输出为第二阶段细化的单词特征矩阵,其计算过程参照步骤s2第一阶段门控单词-视觉注意力单元中选择门的计算过程,表达式如下:
[0182][0183][0184]
其中,表示输入的第二阶段的视觉特征矩阵中第n个视觉特征向量,维度为dv;v
2g
表示第二阶段的全局视觉特征矩阵,维度为dv×nw
;w1表示输入的第一阶段的单词特征矩阵,维度为dw×nw
;表示输出的第二阶段细化的单词特征矩阵,维度为dw×nw
;mv()表示1
×
1卷积层,右下标v表示输入特征处于视觉特征语义空间;和表示第一、第二线性变换层,右下标w表示输入特征处于单词特征语义空间,右下标v表示输入特征处于视觉特征语义空间,的维度为1
×dw
,的维度为1
×dv
;repeat()表示矩阵列复制,σ()表示sigmoid激活函数。
[0185]
第二阶段门控单词-视觉注意力单元中的视觉到单词注意力块参照实施例一步骤s3第二阶段门控交叉单词-视觉注意力单元中的视觉到单词注意力块。
[0186]
定义第二阶段的门控单词-视觉注意力单元使用公式(42),(43),(20)-(22)输出
第二阶段细化的视觉特征矩阵的过程为gau2(),定义第三阶段的视觉特征转换器输出第三阶段的视觉特征矩阵的过程为f3(),定义第三阶段的生成器输出分辨率为256
×
256的图像的过程为g3(),表达式如下:
[0187][0188][0189]
i3=g3(v3).
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(46)
[0190]
其中,表示第二阶段细化的视觉特征矩阵,维度为v3表示第三阶段的视觉特征矩阵,维度为i3表示第三阶段生成器输出的分辨率为256
×
256的图像;concat()表示特征拼接函数,将多个输入特征矩阵拼接为一个输出特征矩阵。
[0191]
s4、参照实施例一中步骤s4,唯一不同的是第i阶段单词级图像-文本匹配损失函数的计算过程:首先将第i阶段生成器输出的图像输入图像编码器,得到第i阶段的区域特征矩阵;然后将第一阶段的单词特征矩阵和第i阶段的区域特征矩阵通过矩阵乘法相乘,得到第i阶段的相似度矩阵;再沿每个维度对相似度矩阵进行归一化,得到第i阶段的注意力权重系数矩阵;接着将第i阶段的区域特征矩阵和注意力权重系数矩阵通过矩阵乘法相乘,得到第i阶段的区域上下文特征矩阵;最后将第i阶段的区域上下文特征矩阵和第一阶段的单词特征矩阵输入区域-单词匹配得分函数,得到第i阶段的单词级图像-文本匹配损失值;表达式如下:
[0192]
γi=softmax(θ1softmax(w
1tri
)),i=1,2,3;
ꢀꢀꢀꢀꢀ
(47)
[0193]ci
=riγ
it
,i=1,2,3;
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(48)
[0194][0195][0196]
其中,w1表示第一阶段的单词特征矩阵,维度为dw×nw
;ri表示第i阶段的区域特征矩阵,维度为dw×
289;w
1tri
表示第i阶段的相似度矩阵,维度为nw×
289;γi表示第i阶段的注意力权重系数矩阵,维度为nw×
289;ci表示第i阶段的区域上下文特征矩阵,维度为dw×nw
;表示第i阶段的区域上下文特征矩阵中第n个区域上下文特征向量,维度为dw;表示第一阶段的单词特征矩阵中第n个单词特征向量,维度为dw;表示第i阶段的区域-单词匹配得分函数;表示m对区域-单词对,只有匹配其他的m-1对视为不匹配的区域-单词对;θ1,θ2,θ3分别表示第一、第二、第三超参数。
[0197]
使用该实施例对基准数据集cub和ms-coco分别进行文本到图像的生成,并将该结果与实施例一的结果进行了对比。该实施例在基准数据集cub上的is指标、fid指标、r-precision指标均差于实施例一,其中is指标(高优指标)达到4.72,降低了1.67%,fid指标(低优指标)达到15.95,提高了6.9%,r-precision指标(高优指标)达到77.21,降低了1.62%。结果表明了本发明方法的有效性。
[0198]
上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的
限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1