深度强化学习与PI控制结合的负荷频率控制方法与流程
深度强化学习与pi控制结合的负荷频率控制方法
技术领域
1.本发明属于新型电力技术领域,具体涉及一种深度强化学习与pi控制结合的负荷频率控制方法。
背景技术:
2.新型电力系统中新能源将成为主力电源,高渗透率接入的新能源将深刻改变传统电力系统的形态、特性和机理,新型电力系统将呈现高比例新能源与高比例电力电子特性,将呈现低转动惯量、宽频域振荡等新的动态特征,系统的频率稳定问题也会变得更加复杂。目前构筑于以传统同步发电机为主体之上的系统运行控制理论与技术,难以满足新型电力系统安全运行要求,系统基础理论、分析方法、控制技术亟需全面变革与突破。
3.传统方法以经典机电理论和数学模型为基础,动作时间常数大,系统分析方法建立在慢速系统机电特性基础上,但是弱惯性的新型电力系统由于电力电子设备的控制作用,动作时间常数小,频域分布广,难以建立精确数学模型,给电力系统分析方法带来困难。
4.传统方法中系统稳定性分析和计算以物理模型和时域仿真为基础,通过求解代数或微分方程数值解,分析稳定机理,但是新型电力系统由于海量电力电子化设备接入、运行方式多变,导致基于物理模型的求解面临维数灾难,给电力系统稳定计算带来困难。
5.(1)传统的控制方法如pid,模糊逻辑控制和模型预测控制需要复杂的数学模型,然而,专家的专业知识,这些经验和知识是很难获得的;(2)通过粒子群优化、遗传算法和神经网络优化的最优跟踪曲线网络算法通常只对特定周期有效,缺乏在线学习能力和有限的泛化能力;(3)经典的强化学习方法如q-learning容易出现维度灾难问题,泛化能力不强,通常只对特定任务有用。
技术实现要素:
6.本发明的目的在于解决现有技术由于海量电力电子化设备和新能源接入、运行方式多变,导致基于物理模型的求解面临维数灾难,给电力频率稳定控制带来困难的问题,提供一种深度强化学习与pi控制结合的负荷频率控制方法,通过人工智能和传统pi控制相结合,可以达到较优的频率控制效果。
7.为了实现上述目的,本发明所采用的技术方案如下:
8.一种深度强化学习与pi控制结合的负荷频率控制方法,包括以下步骤:
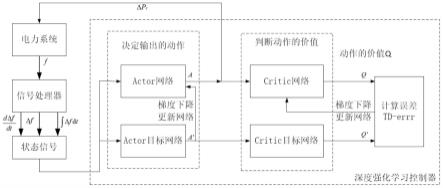
9.s1、构建深度强化学习控制器,包括actor网络、critic网络、actor目标网络和critic目标网络,初始化actor网络和critic网络的参数,将actor网络和critic网络的参数分别赋予actor目标网络和critic目标网络;
10.s2、电力系统将频率信息通过信号处理器处理为频率变化量、频率变化率、频率变化总量,将频率变化量、频率变化率、频率变化总量作为当前状态的状态信号分别输入actor网络和actor目标网络;
11.s3、actor网络根据策略选取一个动作,将该动作作为深度强化学习控制器的动作
信号,分别输入电力系统和critic网络,电力系统进入更新状态,根据状态信号计算当前状态的奖励信息,并分别输入actor网络和actor目标网络;
12.s4、通过critic网络更新当前状态的状态价值,并计算当前状态该动作的动作价值,计算actor网络的梯度并更新actor网络的参数,计算crtic网络的误差,计算crtic网络的梯度并更新crtic网络的参数;
13.s5、分别比较actor网络和actor目标网络的参数、以及critic网络和critic目标网络的参数是否相同,如果参数相同,则停止训练,如果参数不同,则继续通过频率信息对深度强化学习控制器进行训练;
14.s6、将pi控制器和训练完成后的深度强化学习控制器一同接入电力系统,将电力系统的频率变化量与设置的切换频率常数相比较,根据两者的比较结果选取控制器,对电力系统的发电机调速器进行控制。
15.进一步地,奖励信息的计算方法为:
[0016][0017]
其中,r
t
为当前状态的奖励,r
t-1
为上一个状态的奖励,δf为系统的频率变化量,为系统的频率变化率,k1为体现对频率变化量重视程度的常数,k2为对频率变化率重视程度的常数。
[0018]
奖励函数包括三项,第一项r
t-1
为之前的奖励,后两项之和为这一步获得的奖励,这样可以将所有的奖励的信息累加起来,综合评价控制器控制效果的好坏。
[0019]
其中,第二项-k1δf2为对频率变化量的考量,频率变化量越大,这步得到的负奖励就越大,考虑了电力系统本身的特性,允许在一定频率范围内波动,而对频率越限坚决不能容忍,因此采用平方项,当频率变化量较小时,这个量可以忽略不计。第三项为对频率变化率的考量,希望避免出现低频振荡的情况。综上所述,巧妙的奖励函数设计能够更好的反映控制器控制效果的好坏,并用于深度强化学习中。
[0020]
进一步地,当前状态的状态价值的更新方法为:
[0021]
v(s
t
)=v(s
t
)+α[r
t+1
+γv(s
t+1
)-v(s
t
)]
[0022]
其中,v(s
t
)为当前状态的状态价值,r
t+1
为下一个状态的奖励,γ为折扣率,v(s
t+1
)为下一个状态的状态价值,α为学习率。
[0023]
当前状态的价值v(s
t
)一开始为估测值,其并非真实值,通过不断的训练,通过之后的价值对其进行修正,能够得到更准确的状态价值。
[0024]
进一步地,动作价值的计算方法为:
[0025]
q(s,a)=r+γv(s
t+1
)
[0026]
其中,q(s,a)为s状态下动作a的动作价值,r为执行当前动作a得到的奖励。
[0027]
动作价值q(s,a)一开始为估测值,其并非真实值,通过不断的训练,通过之后的价值对其进行修正,能够得到更准确的动作价值。
[0028]
进一步地,actor网络的梯度的计算方法为:
[0029][0030]
其中,为actor网络的梯度,n为随机选取用于计算的相邻的状态数,为对actor网络求关于动作a的梯度,q(s,a∣q)为根据crtic网络的参数q计算出的s状态下动作a的动作价值,si为第i个状态,a为根据策略μ选择的动作,为对策略μ求关于θ的梯度,μ(s∣
μ
)为选择动作的策略。
[0031]
通过求取actor网络的梯度采用梯度下降的方法,能够根据该梯度找到actor网络的参数μ的更新方向,能够快速完成actor网络的参数μ的更新。
[0032]
进一步地,crtic网络的误差的计算方法为:
[0033]
td-error=r+γv'(s
t+1
)-v(s
t
)
[0034]
其中,td-error为crtic网络的误差,v'(s
t+1
)为crtic目标网络计算的下一个状态的状态价值,r为执行当前动作a得到的奖励。
[0035]
crtic网络一开始为估测值,通过确定crtic网络与crtic目标网络的误差td-error,用于权利6的参数修改,当其误差为很小是,则可以认为crtic网络所求得的结果为准确结果。
[0036]
进一步地,crtic网络的梯度计算方法为:
[0037][0038]
其中,为crtic网络的梯度,n为随机选取用于计算的相邻的状态数,为对critic网络的参数q求关于θ的梯度,q(s,a∣q)为根据crtic网络的参数q计算出的s状态下动作a的动作价值,s为状态,si为第i个状态,μ为选择动作的策略,a为根据策略μ选择的动作。
[0039]
通过求取crtic网络的梯度采用梯度下降的方法,能够根据该梯度找到crtic网络的参数q的更新方向,能够快速完成crtic网络参数q的更新。
[0040]
进一步地,将电力系统的频率变化量与设置的切换频率常数相比较的方法为:
[0041]
若电力系统的频率变化量大于或等于设置的切换频率常数,则使用深度强化学习控制器;若电力系统的频率变化量小于设置的切换频率常数,则使用pi控制器。
[0042]
actor网络的参数和critic网络的参数原本都是估测值,将actor目标网络的参数和critic目标网络的参数暂时设置为实际值,当估测值的结果与实际值的结果没有误差的时候,就可以视为actor网络的参数和critic网络的参数收敛,训练完毕,能够准确的反映结果。
[0043]
与现有技术相比,本发明具有以下有益效果:
[0044]
本发明将人工智能的方法引入电力系统频率控制的领域中,设计奖励函数,不仅考虑当前的频率变化量,还考虑频率波动的快慢,能够快速的收敛并产生较好的训练效果;还将深度强化学习方法与传统pi控制相结合,在频率变化量较小时采用简单的传统pi控制,在频率变化量较大时采用深度强化学习控制,有较好的鲁棒性、稳定性和普遍适用性;本发明可以应用在新能源电力系统的负荷频率控制中。
附图说明
[0045]
图1为深度强化学习控制器进行训练的示意图。
具体实施方式
[0046]
下面结合附图和具体实施例对本发明深度强化学习与pi控制结合的负荷频率控制方法作进一步说明。
[0047]
请参阅图1,本发明公开了一种深度强化学习与pi控制结合的负荷频率控制方法,包括以下步骤:
[0048]
s1、构建深度强化学习控制器,包括actor网络、critic网络、actor目标网络和critic目标网络,初始化actor网络和critic网络的参数,将actor网络和critic网络的参数分别赋予actor目标网络和critic目标网络。
[0049]
s2、电力系统将频率信息通过信号处理器处理为频率变化量、频率变化率、频率变化总量,将频率变化量、频率变化率、频率变化总量作为当前状态的状态信号分别输入actor网络和actor目标网络。
[0050]
s3、actor网络根据策略选取一个动作,将该动作作为深度强化学习控制器的动作信号,分别输入电力系统和critic网络,电力系统进入更新状态,根据状态信号计算当前状态的奖励信息,并分别输入actor网络和actor目标网络。
[0051]
s4、通过critic网络更新当前状态的状态价值,并计算当前状态该动作的动作价值,计算actor网络的梯度并更新actor网络的参数,计算crtic网络的误差,计算crtic网络的梯度并更新crtic网络的参数。
[0052]
s5、分别比较actor网络和actor目标网络的参数、以及critic网络和critic目标网络的参数是否相同,如果参数相同,则停止训练,如果参数不同,则继续通过频率信息对深度强化学习控制器进行训练。
[0053]
s6、将pi控制器和训练完成后的深度强化学习控制器一同接入电力系统,将电力系统的频率变化量与设置的切换频率常数相比较,根据两者的比较结果选取控制器,对电力系统的发电机调速器进行控制。
[0054]
本发明中的深度强化学习方法为深度确定策略梯度(deep deterministic policy gradient,ddpg),是将深度学习神经网络融合进强化学习的策略学习方法。采用神经网络作为策略函数μ和q函数的模拟,即策略网络和q网络,然后使用深度学习的方法来训练上述神经网络,采用的双层网络能够更快的加速是的收敛。本发明首先设置巧妙的奖励来衡量控制效果,之后将深度强化学习控制器接入到电力系统的频率控制中进行训练,将训练好的深度强化学习控制器与pi控制器结合,设置切换频率常数,在频率变化量较小时采用简单的传统pi控制,在频率变化量较大时采用深度强化学习控制。
[0055]
具体地,步骤s1中,构建深度强化学习控制器,深度强化学习控制器包括actor网络、critic网络、actor目标网络和critic目标网络。初始化actor网络的参数θu和critic网络的参数θq,并将actor网络的参数θu和critic网络的参数θq分别赋予actor目标网络和critic目标网络,获得actor目标网络的参数θ
q'
和critic目标网络的参数θ
u'
。
[0056]
步骤s2中,电力系统将频率信息f采样给信号处理器,信号处理器将频率信息f处
理为频率变化量δf、频率变化率频率变化总量∫δfdt三个信号。将频率变化量δf、频率变化率频率变化总量∫δfdt三个信号作为状态信号s
t
分别输入到深度强化学习控制器的actor网络和actor目标网络。
[0057]
步骤s3中,actor网络根据策略选取一个动作a,即δpc,将其作为控制器的动作,输入到电力系统,电力系统进入状态s
t+1
,计算奖励信息r
t
,并向其输送到深度强化学习控制器。
[0058]
奖励信息的计算方法为:
[0059][0060]
其中,r
t
为当前状态的奖励,r
t-1
为上一个状态的奖励,δf为系统的频率变化量,为系统的频率变化率,k1为体现对频率变化量重视程度的常数,k2为对频率变化率重视程度的常数。
[0061]
奖励函数包括三项,第一项r
t-1
为之前的奖励,后两项之和为这一步获得的奖励,这样可以将所有的奖励的信息累加起来,综合评价控制器控制效果的好坏。其中,第二项-k1δf2为对频率变化量的考量,频率变化量越大,这步得到的负奖励就越大,考虑了电力系统本身的特性,允许在一定频率范围内波动,而对频率越限坚决不能容忍,因此采用平方项,当频率变化量较小时,这个量可以忽略不计。第三项为对频率变化率的考量,希望避免出现低频振荡的情况。本发明巧妙的奖励函数设计能够更好的反映控制器控制效果的好坏,并用于深度强化学习中。
[0062]
步骤s4中,每过一定训练回合,将actor网络的参数θu和critic网络的参数θq分别赋予actor目标网络和critic目标网络,得到目标网络critic的参数θ
u'
和目标网络的参数θ
q'
。
[0063]
状态价值的更新方法为:
[0064]
v(s
t
)=v(s
t
)+α[r
t+1
+γv(s
t+1
)-v(s
t
)]
[0065]
其中,v(s
t
)为当前状态的状态价值,r
t+1
为下一个状态的奖励,γ为折扣率,v(s
t+1
)为下一个状态的状态价值,α为学习率。当前状态的状态价值v(s
t
)一开始为估测值,其并非真实值,通过不断的训练,通过之后的价值对其进行修正,能够得到更准确的状态价值。
[0066]
动作价值的计算方法为:
[0067]
q(s,a)=r+γv(s
t+1
)
[0068]
其中,q(s,a)为s状态下动作a的动作价值,r为执行当前动作a得到的奖励。动作价值q(s,a)一开始为估测值,其并非真实值,通过不断的训练,通过之后的价值对其进行修正,能够得到更准确的动作价值。
[0069]
actor网络的梯度的计算方法为:
[0070][0071]
其中,为actor网络的梯度,n为随机选取用于计算的相邻的状态数,为对actor网络求关于动作a的梯度,q(s,a∣q)为根据crtic网络的参数q计算出的s状态下动作a的动作价值,si为第i个状态,a为根据策略μ(即actor网络的参数μ)选择的动作,为对策略μ求关于θ的梯度,μ(s∣
μ
)为选择动作的策略(即actor网络的参数)。通过求取actor网络的梯度采用梯度下降的方法,能够根据该梯度找到actor网络的参数μ的更新方向,能够快速完成actor网络的参数θu的更新。
[0072]
crtic网络的误差的计算方法为:
[0073]
td-error=r+γv'(s
t+1
)-v(s
t
)
[0074]
其中,td-error为crtic网络的误差,v'(s
t+1
)为crtic目标网络计算的下一个状态的状态价值,r为执行当前动作a得到的奖励。crtic网络一开始为估测值,通过确定crtic网络与crtic目标网络的误差td-error,用于crtic网络的参数修改,当其误差为很小时,则可以认为crtic网络所求得的结果为准确结果。
[0075]
crtic网络的梯度的计算方法为:
[0076][0077]
其中,为crtic网络的梯度,n为随机选取用于计算的相邻的状态数,为对critic网络的参数q求关于θ的梯度,q(s,a∣q)为根据crtic网络的参数q计算出的s状态下动作a的动作价值,s为状态,si为第i个状态,μ为选择动作的策略(即actor网络的参数),a为根据策略μ(即actor网络的参数μ)选择的动作。通过求取crtic网络的梯度采用梯度下降的方法,能够根据该梯度找到crtic网络的参数q的更新方向,能够快速完成crtic网络参数θq的更新。
[0078]
步骤s5中,分别比较actor网络的参数θu和actor目标网络的参数θ
u'
、以及critic网络的参数θq和critic目标网络的参数θ
q'
是否相同,如果参数相同,则停止训练,如果参数不同,则继续通过频率信息f对深度强化学习控制器进行训练。
[0079]
actor网络的参数θu和critic网络的参数θq原本都是估测值,将actor目标网络的参数θ
u'
和critic目标网络的参数θ
q'
暂时设置为实际值,当估测值的结果与实际值的结果没有误差的时候,就可以视为actor网络的参数θu和critic网络的参数θq收敛,训练完毕,能够准确的反映结果。
[0080]
步骤s6中,将pi控制器和训练完成后深度强化学习控制器一同接入电力系统,将电力系统的频率变化量与设置的切换频率常数δfref相比较。若电力系统的频率变化量大于或等于设置的切换频率常数,则使用深度强化学习控制器。若电力系统的频率变化量小于设置的切换频率常数,则使用pi控制器。根据两者的比较结果选取控制器,以控制调频发电机的调速器。这样既能利用深度强化学习的在频率波动较大时候的高鲁棒性,又能利用pi控制器在频率波动小的时候的稳定性。
[0081]
综上所述,本发明将人工智能的方法引入电力系统频率控制的领域中,设计奖励函数,不仅考虑当前的频率变化量,还考虑频率波动的快慢,能够快速的收敛并产生较好的
训练效果;还将其与传统的pi控制相结合,在频率变化量较小时采用简单的传统pi控制,在频率变化量较大时采用深度强化学习控制,有较好的鲁棒性、稳定性和普遍适用性;本发明可以应用在新能源电力系统的负荷频率控制中。
[0082]
上述说明是针对本发明较佳可行实施例的详细说明,但实施例并非用以限定本发明的专利申请范围,凡本发明所揭示的技术精神下所完成的同等变化或修饰变更,均应属于本发明所涵盖专利范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1