策略模型的训练方法及装置与流程
本申请涉及强化学习领域,以下描述涉及一种策略模型的训练方法及装置。
背景技术:
1、火箭回收技术,是指火箭发射后回收,并重复使用的技术。一次性使用的运载火箭发射成本很高,使用火箭回收技术能够降低发射成本。火箭回收技术的关键在于如何将一级火箭回收到指定地点,并保持一级火箭落地时姿态垂直于地面,且着陆速度不大于指定速度。如果一级火箭可以成功回收,则可以节约99%的火箭发射成本。然而,由于一级火箭回收面临分离一级火箭、旋转一级火箭、重启引擎引导降落,减速进入大气层等多个环节,一级火箭进入大气层,并且在离地面一定高度时,火箭余下的引擎也会全部启动,需要进一步控制火箭的下落速度以便其能以合适的速度降落。由此可见,控制火箭的回收过程一直是一个较为棘手的问题。因此,火箭回收技术是航天航空技术尤其是商业航天航空技术亟待发展的技术之一。
技术实现思路
1、本公开的示例性实施例可至少解决上述问题,也可不解决上述问题。
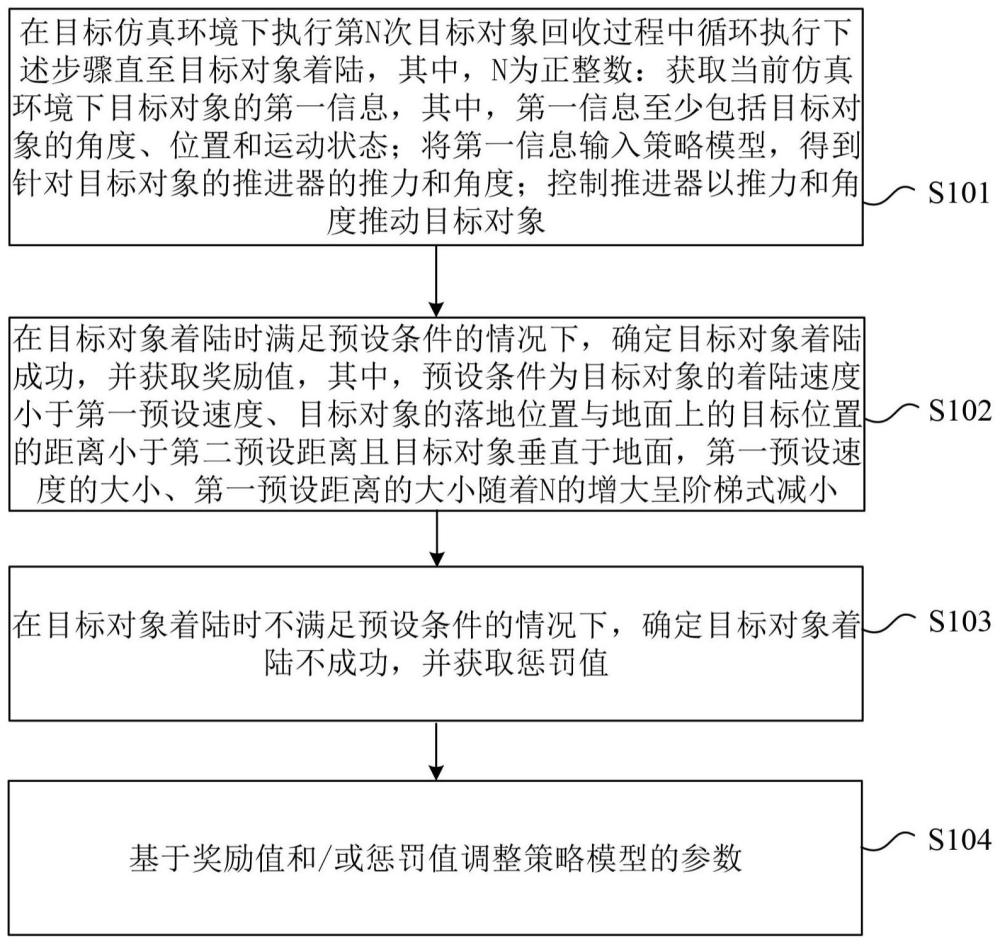
2、根据本公开的第一方面,提供了一种策略模型的训练方法,包括:在目标仿真环境下执行第n次目标对象回收过程中循环执行下述步骤直至目标对象着陆,其中,n为正整数:获取当前仿真环境下目标对象的第一信息,其中,第一信息至少包括目标对象的角度、位置和运动状态;将第一信息输入策略模型,得到针对目标对象的推进器的推力和角度;控制推进器以推力和角度推动目标对象;在目标对象着陆时满足预设条件的情况下,确定目标对象着陆成功,并获取奖励值,其中,预设条件为目标对象的着陆速度小于第一预设速度、目标对象的落地位置与地面上的目标位置的距离小于第二预设距离且目标对象垂直于地面,第一预设速度的大小、第一预设距离的大小随着n的增大呈阶梯式减小;在目标对象着陆时不满足预设条件的情况下,确定目标对象着陆不成功,并获取惩罚值;基于奖励值和/或惩罚值调整策略模型的参数。
3、可选地,惩罚值的大小随着n的增大呈阶梯式增大。
4、可选地,在控制推进器以推力和角度推动目标对象之后,还包括:获取目标对象被推动后的仿真环境下目标对象的第二信息,其中,第二信息至少包括目标对象的角度、位置和运动状态;基于第一信息和第二信息,得到中间奖励值;通过中间奖励值调整策略模型的参数。
5、可选地,基于第二信息,得到中间奖励值,包括:在第二信息中目标对象的角度与第一信息中目标对象的角度相比,目标对象更接近垂直于地面的情况下,中间奖励值增加第一预定值;在第二信息中目标对象的角度与第一信息中目标对象的角度相比,目标对象更不接近垂直于地面,中间奖励值减少第一预定值;在第二信息中目标对象的位置与第一信息中目标对象的位置相比,目标对象更接近地面的目标位置的情况下,中间奖励值增加第二预定值;在第二信息中目标对象的位置与第一信息中目标对象的位置相比,目标对象更不接近地面的目标位置的情况下,中间奖励值减少第二预定值。
6、可选地,第一信息和第二信息还包括耗油量,基于第一信息和第二信息,得到中间奖励值,还包括:在第二信息中耗油量与第一信息中耗油量相比,增加的油量未超过预设油量的情况下,中间奖励值增加第三预定值;在第二信息中耗油量与第一信息中耗油量相比,增加的油量超过预设油量的情况下,中间奖励值减少第三预定值。
7、可选地,基于奖励值和/或惩罚值调整策略模型的参数,包括:在n次目标对象回收过程结束后,基于n次目标对象回收过程中的所有奖励值和惩罚值调整策略模型的参数。
8、根据本公开的第二方面,提供了一种策略模型的训练装置,其中,训练装置包括:循环单元,被配置为在目标仿真环境下执行第n次目标对象回收过程中循环执行下述步骤直至目标对象着陆,其中,n为正整数:获取当前仿真环境下目标对象的第一信息,其中,第一信息至少包括目标对象的角度、位置和运动状态;将第一信息输入策略模型,得到针对目标对象的推进器的推力和角度;控制推进器以推力和角度推动目标对象;奖励值获取单元,被配置为在目标对象着陆时满足预设条件的情况下,确定目标对象着陆成功,并获取奖励值,其中,预设条件为目标对象的着陆速度小于第一预设速度、目标对象的落地位置与地面上的目标位置的距离小于第二预设距离且目标对象垂直于地面,第一预设速度的大小、第一预设距离的大小随着n的增大呈阶梯式减小;惩罚值获取单元,被配置为在目标对象着陆时不满足预设条件的情况下,确定目标对象着陆不成功,并获取惩罚值;训练单元,被配置为基于奖励值和/或惩罚值调整策略模型的参数。
9、可选地,惩罚值的大小随着n的增大呈阶梯式增大。
10、可选地,循环单元,还被配置为在控制推进器以推力和角度推动目标对象之后,获取目标对象被推动后的仿真环境下目标对象的第二信息,其中,第二信息至少包括目标对象的角度、位置和运动状态;基于第一信息和第二信息,得到中间奖励值;通过中间奖励值调整策略模型的参数。
11、可选地,循环单元,还被配置为在第二信息中目标对象的角度与第一信息中目标对象的角度相比,目标对象更接近垂直于地面的情况下,中间奖励值增加第一预定值;在第二信息中目标对象的角度与第一信息中目标对象的角度相比,目标对象更不接近垂直于地面,中间奖励值减少第一预定值;在第二信息中目标对象的位置与第一信息中目标对象的位置相比,目标对象更接近地面的目标位置的情况下,中间奖励值增加第二预定值;在第二信息中目标对象的位置与第一信息中目标对象的位置相比,目标对象更不接近地面的目标位置的情况下,中间奖励值减少第二预定值。
12、可选地,第一信息和第二信息还包括耗油量,循环单元,还被配置为在第二信息中耗油量与第一信息中耗油量相比,增加量未超过预设油量的情况下,中间奖励值增加第三预定值;在第二信息中耗油量与第一信息中耗油量相比,增加量超过预设油量的情况下,中间奖励值减少第三预定值。
13、可选地,训练单元,还被配置为在n次目标对象回收过程结束后,基于n次目标对象回收过程中的所有奖励值和惩罚值调整策略模型的参数。
14、根据本公开的第三方面,提供一种存储指令的计算机可读存储介质,其中,当指令被至少一个计算装置运行时,促使至少一个计算装置执行如上的策略模型的训练方法。
15、根据本公开的第四方面,提供一种包括至少一个计算装置和至少一个存储指令的存储装置的系统,其中,指令在被至少一个计算装置运行时,促使至少一个计算装置执行如上的策略模型的训练方法。
16、根据本公开实施例的策略模型的训练方法及装置,在策略模型的训练过程中着陆次数越靠前的时候,着陆成功的条件越容易,随着着陆次数越来越多,也就是策略模型训练到后期,着陆成功的条件越苛刻,如此可以保证训练的持续进行,避免一直陷入到失败的策略中,提高了目标对象在仿真环境中的回收成功率。
技术特征:
1.一种策略模型的训练方法,其中,所述方法包括:
2.根据权利要求1中所述的训练方法,其中,所述惩罚值的大小随着n的增大呈阶梯式增大。
3.根据权利要求1中所述的训练方法,其中,在控制所述推进器以所述推力和所述角度推动所述目标对象之后,还包括:
4.根据权利要求3中所述的训练方法,其中,所述基于所述第二信息,得到中间奖励值,包括:
5.根据权利要求3中所述的训练方法,其中,所述第一信息和所述第二信息还包括耗油量,
6.根据权利要求1中所述的训练方法,其中,所述基于所述奖励值和/或所述惩罚值调整所述策略模型的参数,包括:
7.一种策略模型的训练装置,其中,所述训练装置包括:
8.根据权利要求7中所述的训练装置,其中,所述循环单元,还被配置为在控制所述推进器以所述推力和所述角度推动所述目标对象之后,获取所述目标对象被推动后的仿真环境下所述目标对象的第二信息,其中,所述第二信息至少包括所述目标对象的角度、位置和运动状态;基于所述第一信息和所述第二信息,得到中间奖励值;通过所述中间奖励值调整所述策略模型的参数。
9.一种存储指令的计算机可读存储介质,其中,当所述指令被至少一个计算装置运行时,促使所述至少一个计算装置执行如权利要求1至6中的任一权利要求所述的策略模型的训练方法。
10.一种包括至少一个计算装置和至少一个存储指令的存储装置的系统,其中,所述指令在被所述至少一个计算装置运行时,促使所述至少一个计算装置执行如权利要求1至6中的任一权利要求所述的策略模型的训练方法。
技术总结
本公开提供了一种策略模型的训练方法及装置,该方法包括:在目标仿真环境下执行第N次目标对象回收过程中循环执行下述步骤直至目标对象着陆:获取当前仿真环境下目标对象的第一信息;将第一信息输入策略模型,得到推进器的推力和角度;控制推进器以推力和角度推动目标对象;在目标对象着陆时满足预设条件的情况下,获取奖励值,其中,预设条件为目标对象的着陆速度小于第一预设速度、目标对象的落地位置与地面上的目标位置的距离小于第二预设距离且目标对象垂直于地面,第一预设速度的大小、第一预设距离的大小随着N的增大呈阶梯式减小;在目标对象着陆时不满足预设条件的情况下,获取惩罚值;基于奖励值和/或惩罚值调整策略模型的参数。
技术研发人员:周浩,涂威威
受保护的技术使用者:第四范式(北京)技术有限公司
技术研发日:
技术公布日:2024/3/4
- 还没有人留言评论。精彩留言会获得点赞!