一种基于有利特征提取的图片域自适应网络结构与方法
本发明属于深度学习领域,涉及一种图片分类的领域自适应方法和装置,具体涉及一种基于有利特征提取的图片域自适应网络结构与方法。
背景技术:
1、在生物神经系统的研究基础上,通过对生物神经系统的神经细胞为基础的神经元进行建模,得到基于神经元的计算模型-神经网络,神经网络是实现机器学习任务的一种重要方法。受硬件技术和数据量的限制,早期对神经网络的研究停留在浅层网络,重点研究网络的内部构成和运算方式。由于浅层的神经网络参数量有限,其学习能力非常弱,要实现复杂的机器学习任务,使用简单的浅层神经网络已经很难实现了。
2、21世纪以来,在生物神经网络的研究中,发现神经元与神经元之间是相互连接的,科学家试图加深神经网络,解决浅层神经网络学习能力弱的限制,依托于硬件技术的进步和数据的迅速膨胀,深度学习脱颖而出,深度学习的出现是社会进入大数据时代的一个重要标志。深度学习方法已经成为现代机器学习一个最重要的分支,并且取得了重大成就,例如深度卷积神经网络(convolutional neural networks,cnn)在多媒体和计算机视觉领域的各种图像分类和视觉识别任务中取得了显著的成功。
3、计算能力和数据量的增长在促进深度学习崛起的同时,也成为限制深度学习得以推广的主要障碍。深度学习,特别是有监督深度学习存在的问题可以归结为三个方面:
4、(1)计算能力的问题。随着人们对模型预测精度的不断提高,使用的训练数据和模型的复杂程度也随之提升,训练模型的服务器的计算能力达到一定的标准才能满足以上要求。目前,用于深度学习的大型服务器由于价格的原因很难做到推广,工业界和学术界的大型实验室之外的从业者想要设计验证训练数据大、复杂程度高的网络模型依然是很困难的;
5、(2)数据的收集和标注问题。要训练一个好的模型,必须要有足够多且类别分布尽可能均匀的数据集。如果样本数据不足,则可能导致模型过拟合,如果类别分布不均匀,则可能导致模型的准确率下降。数据的收集和标注需要大量的人力花费,并且标注的结果将直接影响模型的预测效果。此外,数据具有时效性,以前的数据集往往很难处理目前需要的任务。
6、(3)数据集之间的分布问题。深度监督学习的潜在条件是训练数据和测试数据源于相同的联合概率分布,在该条件下,利用海量的已标记的训练数据训练模型,得到的模型可以对未标记的测试数据具有较好的预测效果。然而,在现实情况下,数据集的来源是多种多样的,想要找到一个与我们任务使用的测试集独立同分布的训练数据集是十分困难的,这将导致训练的模型难以达到预想的结果。
7、为了解决以上问题,提出了领域自适应算法(domain adaptation,da)。领域自适应方法的主要研究内容是通过减少源域和目标域数据之间的分布差异来达到知识迁移的目的,大部分研究成果旨在寻找一个跨域分布差异最小化的共性空间,根据寻找共性空间的不同方式。近年来领域自适应算法已经达到了一定水平,国内外学者对领域自适应展开了广泛的研究,取得了众多的研究成果。
8、1.1领域自适应算法研究现状
9、总体上,根据寻找共性空间的不同方式,所有现存方法大致可分为以下三类:
10、(1)度量法
11、通过最小化源域和目标域分布间的距离,减少两个数据域之间的分布差异,达到知识迁移的目的。源域和目标域分布间的距离选择包括最大均值差异(maximum meandiscrepancy,mmd)[1],协方差对齐(correlation alignment,coral)[2],对比域差异(contrastive domain discrepancy,ccd)[3],图匹配损失[4]等。
12、mmd是一个在观测样本分布等价的假设下的两样本统计检验,分别获取两个领域样本上平滑函数的平均值,如果这两个平均值不相等,则样本的来源分布不同;coral用于计算源域特征和目标域特征协方差之间的距离,类似于多项式核的mmd,在深度学习中,使用从两个域提取特征的输出之间的coral损失作为对齐方式;ccd方法是在mmd的基础上,添加了标签信息,最小化ccd,相同标签的数据之间的差距减小,不同标签的数据之间的差距增大;图匹配是关于寻找图之间的最佳对应的问题。
13、(2)重建法
14、与特征提取网络不同,该方法不是最小化分布差异,而是通过重建网络来重新创建特征[5]。这种方法可以通过学习某种特征表示来实现源域和目标域的特征对齐,这种特征表示既可以对源域已标记数据进行很好地分类,也能很好地对目标域数据或目标域数据和源域数据进行重建,重建网络作为其对齐组件。
15、(3)对抗法
16、通过对抗的思想来使得源域和目标域分布对齐[6,7]。这种方法的出现在很大程度上归功于对抗生成对抗网络(gan),使用域分类器作为对齐组件,用于判断某个分布的来源。与一般的gan不同,对抗自适应方法的域分类器不再是判别生成数据还是真实数据,其判别该特征是提取自源域还是目标域。
技术实现思路
1、本发明的目的是提供一种基于有利特征提取的图片域自适应网络结构与方法。由源域有利特征编码器、目标域有利特征编码器、源域冗余特征编码器、目标域冗余特征编码器、领域混淆器、重构特征解码器、分类器组成。源域和目标域的有利特征编码器各自编码其有利分类特征,将不利分类特征、冗余特征都压缩至其各自的冗余特征空间;通过领域混淆器混淆源域与目标域的特征,达到特征分布对齐的目的,实现知识从源域向目标域的迁移;通过重构特征编码器旨在保证信息的完整性;分类器用于对提取特征进行分类。手动标注目标域中的少量数据,为了保留源域中不存在但是对目标域分类有利的特征,独立编码源域和目标域的各类特征空间;在有利特征编码器中添加特征精简功能,实现特征的精简压缩,使得有利编码器中尽可能只保留有利分类特征;由于总体模型包含多个模块,使用分块训练的方式迭代训练模型,然后使用总体损失函数对整个模型进行微调,这种方法可以使得模型收敛速度更快。
2、一种基于有利特征提取的图片域自适应网络结构,包括领域混淆器、重构特征解码器、分类器,其特征在于,还包括源域有利特征编码器、目标域有利特征编码器、源域冗余特征编码器、目标域冗余特征编码器;所述的图片域自适应网络的整体是基于对抗网络来实现源域和目标域特征分布对齐,基于软子空间正交性约束实现有利分类特征和不利分类或冗余特征的分离,基于重构网络保证特征对齐和分离过程中信息完整性;
3、一种基于有利特征提取的图片域自适应网络结构,其特征在于,在训练阶段,源域有利特征编码器用于提取源域的有利分类特征,目标域有利特征编码器用于提取目标域域的有利分类特征,通过最小化差异函数将其他不利分类特征或冗余特征压缩至其各自的冗余特征编码器;在源域和目标域的有利特征编码器中添加特征精简模块,使得其有利特征编码器中尽可能只保留各自的有利分类特征;通过对抗网络实现源域和目标域的有利特征分布对齐,知识可以实现从源域到目标域的迁移;最小化重构损失函数,保证信息经过特征提取分离后的完整性;最小化分类损失函数以实现对提取的特征进行分类;迭代训练各个模块直至收敛,然后使用总体损失函数对整个网络进行微调;测试阶段:所述的图片域自适应网络会根据源域的知识对目标域中的样本进行分类;
4、所述源域有利特征编码器,其特征在于,使用多层卷积神经网络,提取源域中对图片分类有利的特征,独立编码源域有利分类特征映射空间;由于手动标注了目标域中的少量标注,不同于传统的领域自适应方法,将源域和目标域映射到相同的共享特征空间,为了保留源域中不存在但是对目标域分类有利的特征,独立编码源域和目标域共享特征映射空间;源域有利特征编码器接收源域样本图片作为输入,输出源域有利于分类的隐层特征表示其中为源域数据样本,为源域有利特征编码器的模型参数;
5、所述目标域有利特征编码器,其特征在于,使用多层卷积神经网络,提取目标域中对图片分类有利的特征,独立编码目标域有利分类特征映射空间;由于手动标注了目标域中的少量标注,不同于传统的领域自适应方法,将源域和目标域映射到相同的共享特征空间,为了保留源域中不存在但是对目标域分类有利的特征,独立编码源域和目标域共享特征映射空间;目标域有利特征编码器接收源域样本图片作为输入,输出目标域有利于分类的隐层特征表示其中为源域数据样本,为源域有利特征编码器的模型参数;
6、一种基于有利特征提取的图片域自适应方法,其特征在于,为了使得源域和目标域有利特征编码器中尽可能只保留其各自的有利分类特征,在源域和目标域有利特征编码器中添加特征精简模块实现特征的精简,其中λ1、λ2是特征精简系数,∑||·||1表示所求值的所有元素的绝对值之和;
7、所述源域冗余特征编码器,其特征在于,使用多层卷积神经网络,用于提取源域中对图片分类不利或冗余的特征;源域冗余特征编码器接收源域样本图片作为输入,输出源域不利或冗余特征的隐层特征表示其中为源域数据样本,为源域冗余特征编码器的模型参数;
8、所述目标域冗余特征编码器,其特征在于,使用多层卷积神经网络,用于提取目标域中对图片分类不利或冗余的特征;目标域冗余特征编码器接收目标域样本图片作为输入,输出目标域不利或冗余特征的隐层特征表示其中为目标域数据样本,为目标域冗余特征编码器的模型参数;
9、通过最小化差异损失函数对提取的图片特征进行分离,使得源域和目标域的有利分类特征保留在其各自的有利特征编码器中,不利分类或冗余特征压缩至其各自的冗余特征编码器;和的行分别为源数据样本和目标数据样本有利分类的隐层表示和同样,和的行分别是源数据样本和目标数据样本的冗余特征的隐层表示和是frobenius范数的平方;
10、所述领域混淆器通过对抗的思想来对齐源域和目标域的有利特征分布,达到源域知识迁移至目标域的目的,该网络接收源域和目标域的有利特征隐层表示和作为输入,输出域的来源最大化域混淆损失函数用于训练模型不能辨别该隐层表示来自哪个域,使用一个梯度反转层(grl)和一个预测领域产生隐藏表示的域分类器来实现最大化这种混淆,最终使得数据样本在不考虑域的情况下尽可能相似;其中di是域来源的真实标签,是模型对域来源的预测标签;ns、nt分别为源域和目标域的样本总数,·包括源域和目标域数据样本有利分类的隐层特征表示和θq为领域混淆器的模型参数;
11、所述重构特征解码器用于对输入样本进行重构,源域和目标域的有利特征编码器与冗余特征编码器提取的特征经过解码器后,仍然能够重构出原始的输入样本,保证在特征提取分离过程中输入样本信息的完整性;通过最小化重构损失函数输出对原始输入的重构特征;其中k是输入x的像素数,ns和nt分别是源域和目标域数据样本总数,1k是一个长度为k的1向量。是l2范数的平方,θd为重构特征解码器的模型参数;
12、所述分类器用于对提取到的有利分类特征进行分类预测;由于样本的类别大于两类,使用one-hot编码方式来编码类别标签,分类器的最后一层激活函数采用softmax函数,损失函数采用交叉熵损失函数;通过最小化分类损失函数实现对有利分类特征进行正确的分类预测;其中yi是第i个样本真实类别标签的one-hot编码,是模型的多分类预测类别标签的one-hot编码,·包括源域和目标域数据样本有利分类的隐层特征表示和θg为分类器的模型参数;
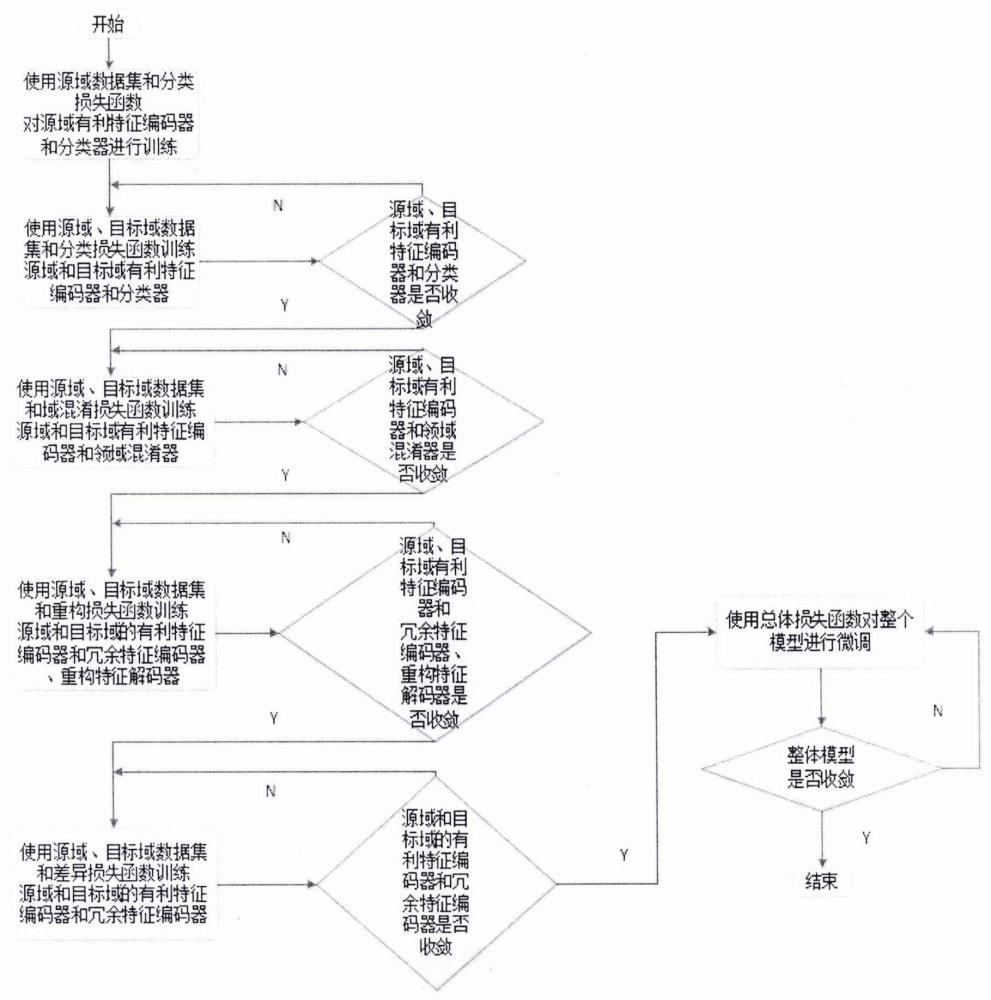
13、对于该模型的训练流程图如图9所示。
14、所述一种基于有利特征提取的图片域自适应方法,其训练过程包括如下步骤:
15、步骤1:使用源域数据对源域的有利特征编码器和分类器进行训练,通过预训练初始化模型的参数,预训练可以在一定程度上抑制模型进入局部最优解;
16、
17、其中k是输入到模型的数据批次编号,
18、步骤2:固定源域和目标域的有利特征编码器和分类器之外的模型参数,训练这两个模块直至收敛;
19、
20、其中
21、步骤3:固定源域和目标域的有利特征编码器和领域混淆器之外的模型参数,训练这两个模块直至收敛;
22、
23、其中
24、步骤4:固定源域和目标域的有利特征编码器和冗余特征编码器、重构特征解码器之外的模型参数,训练其直至收敛;
25、
26、其中
27、步骤5:固定源域和目标域的有利特征编码器和冗余特征编码器之外的模型参数,训练其直至收敛,源域和目标域分别训练;
28、
29、
30、其中
31、步骤6:使用总体函数l=lclass+αldifference+βlrecon+γlsimilarity对整体模型进行微调,直至模型收敛;其中α,β,γ是控制各项损失函数相互作用的权重;
32、如图1所示,对于以上训练步骤,不同于传统的模型训练方式,其特征在于,对于多模块的模型,采用分块训练的方式,模型可以更快更准确的收敛到最优解;传统的训练方式使用总体损失函数训练整个模型,模型对超参数的选取非常敏感,并且模型参数很容易陷入局部最优解;我们使用每个模块对应的损失函数单独迭代训练各个模块,最后使用总体损失函数对整个模型进行微调,这种方法可以缓解模型对超参数的敏感性,同时可以有效避免模型的参数陷入局部最优解;
33、所述步骤2中,提取源域和目标域中的有利分类特征,通过分类器,对提取到的特征进行分类预测;其特征在于,由于对目标域中的少量样本数据进行了手动标注,独立编码源域和目标域中有利特征共享映射空间,这样可以在目标域有利特征编码器中保留源域中不存在但是对目标域分类有利的特征,从而提高对目标域样本数据的分类精度;
34、所述步骤5中,通过特征之间的软子空间正交性约束来进行特征分离,实现有利分类特征保留在各自的有利特征编码器中,不利分类或冗余特征压缩至其各自的冗余特征编码器中;其特征在于,我们在源域和目标域的有利特征编码器中添加特征精简模块,实现特征的自动选择,使得源域和目标域的有利特征编码器中尽可能只保留各自的有利分类特征。
35、本发明一种基于有利特征提取的图片域自适应网络结构与方法的优点在于:
36、(1)由于手动标注少量目标域标签信息后,现有的模型使用共享特征编码器编码源域和目标域的共有信息,会丢掉源域中不存在但是对目标域数据分类有利的信息,这种方法不能充分利用目标域的标签信息。提出一种基于独立编码共享空间的领域自适应方法,目的是在源域和目标域特征对齐和尽可能的保留有利于目标域分类特征之间取得一个平衡,通过独立编码共享特征的方法,充分利用目标域标签的信息;
37、(2)通过在源域和目标域的有利特征编码器中添加特征精简模块,实现特征的自动选择,使得源域和目标域的有利特征编码器中尽可能只保留各自的有利分类特征,如背景颜色等冗余和不利于图片分类的特征尽可能的被压缩到其各自的冗余特征编码器中。
- 还没有人留言评论。精彩留言会获得点赞!