一种提高网络嵌入算法可扩展性的方法
1.本发明属于网络表示学习领域,涉及一种提高网络嵌入算法可扩展性的方法。
背景技术:
2.近年来,网络嵌入因其广泛适用于网络角色发现、社会推荐系统和社会影响力预测等一系列任务而引起了极大关注。虽然,这些新的嵌入方法往往比传统方法具有显而易见的优势,但是,当前的图嵌入方法在准确性和可扩展性方面仍存在一些缺陷。
3.一方面,deepwalk、node2vec这类基于随机游走的嵌入算法,在不包含节点属性特征的情况下只基于网络的拓扑结构进行网络嵌入,这大大限制了它们的嵌入能力。随后,基于节点嵌入在整个图上平滑的概念,出现了图卷积网络gcn,虽然gcn在每一层都利用拓扑和节点特征信息来简化图卷积,但它可能会在初始节点特征中受到高频噪声的影响,这会影响嵌入质量。
4.另一方面,大多数嵌入算法计算成本很高,而且通常是内存密集型的,很难扩展到大型网络数据集(如具有超过100万个节点的网络)。对于几乎所有的网络嵌入算法来说,如何在真实的社交网络、通讯网络或引文网络等大规模网络下应用嵌入算法一直是一个关键问题。图神经网络(gnn)也不例外,扩展图神经网络十分困难,因为在大数据量的情况下,许多核心计算步骤都需要相当长的时间开销,例如graphsage需要共同聚合来自邻域的特征信息,当存在多个叠加的gnn层时,一个节点的最终嵌入向量涉及从其相邻节点计算大量中间嵌入,这不仅会导致节点之间的计算量急剧增加,而且会导致存储中间结果的内存使用率很高。出现这种现象是由于网络并不是常见的欧式数据,每个节点的邻域结构并不相同,因此无法直接应用于批处理,并且当存在上百万个节点和边时,图的拉普拉斯算子也难以计算。可以说可扩展性将决定网络嵌入算法能否应用到真实世界的大型网络中。
技术实现要素:
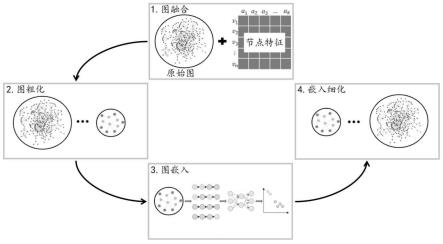
5.为解决现有技术存在的问题,本发明提出了一种提高网络嵌入算法可扩展性的方法,适用于大规模图网络表示学习,通过图融合、图粗化、图嵌入和嵌入细化操作,提高网络嵌入的可扩展性,并提高嵌入质量,嵌入结果可用于网络角色发现、社会推荐系统和社会影响力预测等图下游任务。
6.为实现上述目的,本发明所采取的技术方案是:
7.一种提高网络嵌入算法可扩展性的方法,包括图融合、图粗化、图嵌入和嵌入细化,包括以下步骤:
8.步骤1:对于一个原始图原始图为无向图,将其节点特征矩阵转换为特征图并与原始图的原始拓扑融合,计算a
fusion
=f(a
topo
,x),其中,表示为邻接矩阵,表示为节点特征矩阵,表示加权图的邻接矩阵;
9.步骤2:使用混合粗化将原始图粗化为是经过第一次粗化的图,是经过m次粗化后的最终的最粗图;
10.步骤3:在最粗图上执行图嵌入方法g(
·
),获得嵌入结果ε;
11.步骤4:根据步骤3得出的嵌入结果ε,获得原始图的嵌入ε0。
12.所述步骤1,具体包括以下步骤:
13.步骤1.1:对于|v|个节点的原始图其邻接矩阵表示为其节点特征矩阵为其中,k表示对应节点特征向量的维度;
14.步骤1.2:利用局部谱聚类算法,根据每个节点对的属性向量之间的l2-范数生成k最近邻图,将原始图的初始特征矩阵x转换为节点特征图其中,所述l2-范数为欧式距离;
15.步骤1.3:根据原始图中任意两个节点的属性向量之间的余弦相似度给k最近邻图的每条边分配权重,即其中,x
i,:
和x
j,:
是节点i和j的属性向量;
16.步骤1.4:组合拓扑图和属性图,通过加权构造融合图,如式(1)所示:
17.a
fusion
=a
topo
+βa
feat
ꢀꢀꢀ
(1)
18.其中,β用于在融合过程中平衡拓扑结构信息和节点特征信息,代表加权图的邻接矩阵,a
feat
为k最近邻图的节点特征矩阵。
19.所述步骤1.2中生成k最近邻图,具体包括以下步骤:
20.步骤1.2.1:将随机图信号x作为随机向量,结合图拉普拉斯算子的特征向量u的线性组合表示;
21.步骤1.2.2:采用低通图滤波器滤除随机图信号x的高频分量,所述随机图信号x的高频分量为图拉普拉斯算子高特征值对应的特征向量,通过对随机图信号x应用平滑函数,得到一个平滑向量如式(2)所示:
[0022][0023]
步骤1.2.3:用高斯-赛德尔迭代求解线性方程组得到t个初始随机向量t=(x(1),...,x
(t)
),其中,代表原始图的拉普拉斯矩阵;
[0024]
步骤1.2.4:基于初始随机向量t,将每个节点嵌入到t维空间中,计算节点p和节点q的低维嵌入向量和相似度,若相似度满足相似度阈值,则节点p和节点q为同类节点;
[0025]
所述的节点相似度由相邻节点p和q的谱节点亲和度确定,如式(3)所示:
[0026][0027]
其中:
[0028]
[0029]
其中,a
p,q
为相邻节点p和q的谱节点亲和度,为节点p第k个低维嵌入向量为节点p第k个低维嵌入向量为节点q第k个低维嵌入向量所述相似度阈值设定为大于60%;
[0030]
步骤1.2.5:迭代步骤1.2.1至步骤1.2.4,聚合后的节点集作为一个超节点进行进一步聚合,直至原始图中没有任意两节点间的节点相似度满足相似度阈值,确定最终节点集群,选择每个集群内的前k个最近邻居,构建k最近邻图。
[0031]
所述步骤2为图粗化,具体包括以下步骤:
[0032]
步骤2.1:输入原始图和设定总粗化层数m,其中,0≤i≤m-1;
[0033]
步骤2.2:通过投影矩阵m
i,i+1
保存混合粗化中将多个节点粗化成超节点的粗化信息,其中,
[0034]
步骤2.3:通过矩阵运算构建在i+1层的图的邻接矩阵a
i+1
,计算a
i+1
=m
i,i+1taimi,i+1
,其中,m
i,i+1
为从到的映射矩阵,ai为的邻接矩阵;
[0035]
步骤2.4:计算在i-1层的图的二阶邻居粗化映射矩阵标记矩阵中的节点,初始化用于存储一阶邻居粗化映射的按节点度升序对v
i-1
进行排序;
[0036]
步骤2.5:若v和u没有被标记,且u是v的邻居节点,则找到v的一阶粗化节点u,根据信息交互概率t
i,j
,最终标记节点u和节点v;
[0037]
步骤2.6:基于和通过矩阵运算计算出映射矩阵m
i-1,i
,即,如果将中的节点a,b,c粗化成中的超节点d,则映射矩阵m
i-1,i
中的a行d列、b行d列、c行d列的值为1,否则值为0;在m
i-1,i
中每一列代表下一层图中的一个超节点,这一列中粗化成超节点的节点值为1,其他为0;
[0038]
步骤2.7:计算得到的邻接矩阵ai,如式(5)所示:
[0039]ai
=m
i-1,itai-1mi-1,i
ꢀꢀꢀ
(5)
[0040]
其中,m
i-1,i
为从到的映射矩阵,a
i-1
为的邻接矩阵;
[0041]
步骤2.8:重复步骤2.5至步骤2.7,对升序后的所有节点进行遍历;
[0042]
步骤2.9:重复步骤2.1至步骤2.8,直至达到总粗化层数m;
[0043]
步骤2.10:得到0≤i≤m-1次粗化的和m
i,i+1
。
[0044]
所述步骤2.5中信息交互概率t
i,j
,衡量节点间的相似度,确定是否合并节点,包括以下步骤:
[0045]
步骤2.5.1:遍历原始图中所有节点对;
[0046]
步骤2.5.2:对原始图进行二阶邻居粗化,将拥有相同邻居节点集的两个节点合并;
[0047]
步骤2.5.3:遍历二阶邻居粗化后的图;
[0048]
步骤2.5.4:计算节点对之间的信息交互概率t
i,j
,如式(6)所示:
[0049][0050]
其中,为节点i与节点j之间边的权重,di为节点i的度,dj为节点j的度;
[0051]
步骤2.5.5:对图进行一阶邻居粗化,将未粗化且t
i,j
最大的邻居节点将进行合并。
[0052]
所述步骤3为图嵌入,具体包括以下步骤:
[0053]
步骤3.1:在最粗图上应用图嵌入g(
·
);
[0054]
步骤3.2:若图嵌入方法g(
·
)为无监督嵌入方法,则扩展最粗图和原始图之间节点标签和特征的对应关系;
[0055]
步骤3.3:若图嵌入方法g(
·
)为有监督嵌入方法,则无需扩展。
[0056]
所述步骤3.2中图嵌入方法g(
·
)为无监督嵌入方法,具体包括以下步骤:
[0057]
步骤3.2.1:根据原始图中lb种节点标签,构建原始图的标签矩阵矩阵的每一行是一个节点one-hot形式的标签向量;
[0058]
步骤3.2.2:构建原始图到最粗图的映射矩阵m
0,i
,即m
0,i
=m
0,1m1,2
…mi,i-1m0,i
;m
0,i
矩阵中行是one-hot形式,列是被粗化的节点;
[0059]
步骤3.2.3:通过标签矩阵lb0得到被粗化节点的标签,将每列标签取众数,作为粗化后节点的标签,得到标签矩阵
[0060]
步骤3.2.4:原始图的节点属性特征f0,原始图到最粗图的特征映射矩阵m
0,i
;先对m
0,i
进行归一化,然后通过矩阵运算得到最粗图的特征矩阵
[0061]
所述步骤4,具体包括以下步骤:
[0062]
步骤4.1:使用由吉洪诺夫正则化(tikhonov regularization)驱动的局部细化过程,通过最小化公式平滑图上的节点嵌入,如式(7)所示:
[0063][0064]
其中,li是归一化拉普拉斯矩阵,为用于平滑第i层的嵌入,εi为第i层的嵌入;
[0065]
步骤4.2:取步骤4.1中方程中目标函数的导数等于0,如式(8)所示:
[0066][0067]
其中,εi为第i层的嵌入,i是单位矩阵,li是归一化拉普拉斯矩阵,为用于平滑第i层的嵌入;
[0068]
步骤4.3:利用低通图滤波器来平滑映射的嵌入矩阵,如式(9)所示:
[0069][0070]
其中,为第i层做了两次归一化的度矩阵,为第i层归一化后的邻接矩阵,为从到的投影矩阵,ε
i+1
为第i+1层的嵌入;
[0071]
步骤4.4:通过迭代步骤4.2获得原始图的嵌入ε0。
[0072]
采用上述技术方案所产生的有益效果在于:
[0073]
1、本发明提出了一种提高网络嵌入算法可扩展性的方法。使用基于二阶邻居粗化和一阶邻居粗化的混合粗化策略进行图粗化,在最粗图上计算嵌入后,使用有效的图滤波器进行嵌入细化。并通过大量实验证明本算法相比其他多层策略有更先进的性能。
[0074]
2、通过计算出的原始图的标签矩阵和原始图与最粗图的映射矩阵来获得最粗图中超节点的标签,并作为以gcn为代表的有监督图嵌入算法的训练标签参与模型训练,解决了现有多层策略无法处理有监督图嵌入算法的问题。
[0075]
3、提高了图嵌入算法的可扩展性。本策略与底层图嵌入算法无关,并提高图嵌入算法处理大规模网络的能力。最后在大规模图数据集friendster上进行实验证明了本策略的可扩展性。
附图说明
[0076]
图1本发明的一种提高网络嵌入算法可扩展性的方法示意图;
[0077]
图2本发明中图粗化阶段的混合粗化策略示意图;
[0078]
图3本发明在结合各类图嵌入的基线算法后,在不同粗化层下的micro-f1值示意图;
[0079]
图4本发明在结合各类图嵌入的基线算法后,在不同粗化层下的cpu时间对比图;
[0080]
图5本发明在大规模网络上的可扩展性实验,在不同粗化层下的micro-f1值示意图;
[0081]
图6本发明在大规模网络上的可扩展性实验,粗化后图的节点数和边数变化图;
[0082]
图7本发明中所开发的原型系统的系统用例图;
[0083]
图8本发明中所开发的原型系统的系统功能模块示意图;
[0084]
图9本发明中所开发的原型系统的模型训练生命周期时序图;
[0085]
图10本发明中所开发的原型系统的数据集上传时序图;
[0086]
图11本发明中所开发的原型系统的数据集上传界面截图;
[0087]
图12本发明中所开发的原型系统的静态网络数据来源介绍界面截图;
[0088]
图13本发明中所开发的原型系统的静态网络数据详情介绍界面截图;
[0089]
图14本发明中所开发的原型系统的模型训练模块界面截图;
[0090]
图15本发明中所开发的原型系统的节点分类任务结果界面截图;
[0091]
图16本发明中所开发的原型系统的当前服务器的资源占用率界面截图。
具体实施方式
[0092]
下面结合附图和实施例,对本发明的具体实施方式作进一步详细描述。以下实施例用于说明本发明,但不用来限制本发明的范围。
[0093]
本实施例提出了一种提高网络嵌入算法可扩展性的方法,如图1所示,包括以下步骤:
[0094]
步骤1:对于一个原始图原始图为无向图,将其节点特征矩阵转换为特征图并与原始图的原始拓扑融合,计算a
fusion
=f(a
topo
,x),其中,表示为邻接矩阵,表示为节点特征矩阵,表示加权图的邻接矩阵;具体包括以下步骤:
[0095]
步骤1.1:对于|v|个节点的原始图其邻接矩阵表示为
其节点特征矩阵为其中,k表示对应节点特征向量的维度;
[0096]
步骤1.2:利用局部谱聚类算法,根据每个节点对的属性向量之间的l2-范数生成k最近邻图,将原始图的初始特征矩阵x转换为节点特征图其中,所述l2-范数为欧式距离;
[0097]
所述步骤1.2中生成k最近邻图,具体包括以下步骤:
[0098]
步骤1.2.1:将随机图信号x作为随机向量,结合图拉普拉斯算子的特征向量u的线性组合表示;
[0099]
步骤1.2.2:采用低通图滤波器滤除随机图信号x的高频分量,所述随机图信号x的高频分量为图拉普拉斯算子高特征值对应的特征向量,通过对随机图信号x应用平滑函数,得到一个平滑向量如式(1)所示:
[0100][0101]
步骤1.2.3:用高斯-赛德尔迭代来求解线性方程组以得到t个初始随机向量t=(x
(1)
,...,x
(t)
),其中,代表原始图的拉普拉斯矩阵;
[0102]
步骤1.2.4:基于初始随机向量t,将每个节点嵌入到t维空间中,计算节点p和节点q的低维嵌入向量和相似度,若相似度满足相似度阈值,则节点p和节点q为同类节点,所述的节点相似度由相邻节点p和q的谱节点亲和度确定,如式(2)所示;
[0103][0104]
其中:
[0105][0106]
其中,a
p,q
为相邻节点p和q的谱节点亲和度,为节点p第k个低维嵌入向量为节点p第k个低维嵌入向量为节点q第k个低维嵌入向量所述相似度阈值设定为大于60%;
[0107]
步骤1.2.5:迭代步骤1.2.1至步骤1.2.4,聚合后的节点集作为一个超节点进行进一步聚合,直至原始图中,没有任意两节点间的节点相似度满足相似度阈值,确定最终节点集群,选择每个集群内的前k个最近邻居,构建k最近邻图;
[0108]
步骤1.3:根据原始图中任意两个节点的属性向量之间的余弦相似度给k最近邻图的每条边分配权重,即其中,x
i,:
和x
j,:
是节点i和j的属性向量;
[0109]
步骤1.4:组合拓扑图和属性图,通过加权构造融合图,如式(4)所示:
[0110]afusion
=a
topo
+βa
feat
ꢀꢀꢀ
(4)
[0111]
其中,β用于在融合过程中平衡拓扑结构信息和节点特征信息,代表加权图的邻接矩阵,a
feat
为k最近邻图的节点特征矩阵;
[0112]
步骤2:使用混合粗化将原始图粗化为是经过第1次粗化的图,是经过m次粗化后的最终的最粗图;
[0113]
本实施例中,采用混合粗化策略将原始图反复粗化为更小的图;两阶邻居粗化策略,可以有效地粗化图,同时保留全局结构;如图2所示;
[0114]
二阶邻居粗化;由于共享相似相邻节点的节点具有更高的二阶相似性,因此我们将拥有相同邻居节点集的两个节点合并;如图2所示,节点v1,v2和v3将被合并,因为它们都连接到节点v4并且有一个公共邻居集{v4},节点v5与它们的邻居集不同;
[0115]
一阶邻居粗化;二阶粗化之后仍有许多未粗化且相邻的节点,它们也有很高的概率进行信息交换从而具有相似特征,因此本策略通过信息交互概率来衡量两个未粗化的邻居节点是否应该合并;如果在节点vi的邻居中,从节点vi到节点vj的信息传播概率最大,则节点vj是节点vi最有概率传播信息的,但这并不意味着节点vj也最有概率向节点vi传播信息;本策略使用信息交互概率t
i,j
来衡量两个节点的相似度,如式(5)所示;未粗化且t
i,j
最大的邻居节点将进行合并;如图2所示,在二阶折叠之后,权重节点度d7=4,d8=2,d9=2,所以t
7,8
=1/8和t
8,9
=1/4,因此节点v8和v9将被合并;
[0116][0117]
具体包括如下步骤:
[0118]
步骤2.1:输入原始图和设定总粗化层数m,其中,0≤i≤m-1;
[0119]
步骤2.2:通过投影矩阵m
i,i+1
保存混合粗化中将多个节点粗化成超节点的粗化信息,其中,
[0120]
步骤2.3:通过矩阵运算构建在i+1层的图的邻接矩阵a
i+1
,计算a
i+1
=m
i,i+1taimi,i+1
,其中,m
i,i+1
为从到的映射矩阵,ai为图的邻接矩阵;
[0121]
步骤2.4:计算在i-1层的图的二阶邻居粗化映射矩阵标记矩阵中的节点,初始化用于存储一阶邻居粗化映射的按节点度升序对v
i-1
进行排序;
[0122]
步骤2.5:如果v和u没有被标记,并且u是v的邻居节点,则找到v的一阶粗化节点u,根据信息交互概率t
i,j
,最终标记节点u和节点v;
[0123]
所述步骤2.5中信息交互概率t
i,j
,衡量节点间的相似度,确定是否合并节点,包括以下步骤:
[0124]
步骤2.5.1:遍历原始图中所有节点对;
[0125]
步骤2.5.2:对图进行二阶邻居粗化,将拥有相同邻居节点集的两个节点合并;
[0126]
步骤2.5.3:遍历二阶邻居粗化后的图;
[0127]
步骤2.5.4:计算节点对之间的信息交互概率t
i,j
,如式(6)所示:
[0128][0129]
其中,为节点i与节点j之间边的权重,di为节点i的度,dj为节点j的度;
[0130]
步骤2.5.5:对图进行一阶邻居粗化,将未粗化且t
i,j
最大的邻居节点将进行合并;
[0131]
步骤2.6:基于和通过矩阵运算计算出映射矩阵m
i-1,i
,即,如果将中的节点a,b,c粗化成中的超节点d,则映射矩阵m
i-1,i
中的a行d列、b行d列、c行d列的值为
1,否则值为0;在m
i-1,i
中每一列代表下一层图中的一个超节点,这一列中粗化成超节点的节点值为1,其他为0;
[0132]
步骤2.7:计算得到的邻接矩阵ai,如式(7)所示:
[0133]ai
=m
i-1,itai-1mi-1,i
ꢀꢀꢀ
(7)
[0134]
其中,m
i-1,i
为从到的映射矩阵,a
i-1
为图的邻接矩阵;
[0135]
步骤2.8:重复步骤2.5至步骤2.7,对升序后的所有节点进行遍历;
[0136]
步骤2.9:重复步骤2.1至步骤2.8,直至达到总粗化层数m;
[0137]
步骤2.10:得到0≤i≤m-1次粗化的和m
i,i+1
;
[0138]
步骤3:在最粗图上执行图嵌入方法g(
·
),获得嵌入结果ε;
[0139]
具体包括以下步骤:
[0140]
步骤3.1:在最粗图上应用图嵌入g(
·
);
[0141]
步骤3.2:若图嵌入方法g(
·
)为无监督嵌入方法,则扩展最粗图和原始图之间节点标签和特征的对应关系;
[0142]
所述步骤3.2针对图嵌入方法g(
·
)为无监督嵌入方法,具体包括以下步骤:
[0143]
步骤3.2.1:根据原始图中lb种节点标签,构建原始图的标签矩阵矩阵的每一行是一个节点one-hot形式的标签向量;
[0144]
步骤3.2.2:构建原始图到最粗图的映射矩阵m
0,i
,即m
0,i
=m
0,1m1,2
…mi,i-1m0,i
;m
0,i
矩阵中行是one-hot形式,列是被粗化的节点;
[0145]
步骤3.2.3:通过标签矩阵lb0得到被粗化节点的标签,将每列标签取众数,作为粗化后节点的标签,得到标签矩阵
[0146]
步骤3.2.4:原始图的节点属性特征f0,原始图到最粗图的特征映射矩阵m
0,i
;先对m
0,i
进行归一化,然后通过矩阵运算得到最粗图的特征矩阵
[0147]
步骤3.3:若图嵌入方法g(
·
)为有监督嵌入方法,则无需扩展;
[0148]
在最粗图上进行网络嵌入,可以直观地捕获原始图的全局结构;对图进行了m次迭代粗化,并在最粗图上应用图嵌入方法g(
·
);将上的嵌入表示为εm,因此由于本发明与采用的图嵌入方法无关,可以使用任何图嵌入算法进行基本嵌入;
[0149]
值得关注的是原有多层方法的研究是无法处理gcn等有监督嵌入算法,原因是无法找到最粗图和原始图之间节点标签和特征的对应关系,本发明通过矩阵运算扩宽了这一限制;
[0150]
步骤4:根据步骤3得出的嵌入结果ε,获得原始图的嵌入ε0;
[0151]
所述步骤4为图细化,通过低通图滤波器将嵌入细化回原始图,同时确保嵌入在原始图上的平滑;具体包括以下步骤:
[0152]
步骤4.1:使用由吉洪诺夫正则化(tikhonov regularization)驱动的局部细化过程,通过最小化公式平滑图上的节点嵌入,如式(8)所示:
[0153]
[0154]
其中,li是归一化拉普拉斯矩阵,为用于平滑第i层的嵌入,εi为第i层的嵌入;
[0155]
步骤4.2:取步骤4.1中方程中目标函数的导数等于0,如式(9)所示:
[0156][0157]
其中,εi为第i层的嵌入,i是单位矩阵,li是归一化拉普拉斯矩阵,为用于平滑第i层的嵌入;
[0158]
步骤4.3:利用低通图滤波器来平滑映射的嵌入矩阵,如式(10)所示:
[0159][0160]
其中,为第i层做了两次归一化的度矩阵,为第i层归一化后的邻接矩阵,为从到的投影矩阵,ε
i+1
为第i+1层的嵌入;
[0161]
步骤4.4:通过迭代步骤4.2获得原始图的嵌入ε0。
[0162]
为了说明本发明方法的有效性,我们做了以下实验:
[0163]
实验分析对比各类图嵌入的基线算法,在不同粗化层下的准确率和用时,实验结果如附图3-图4所示,包括如下步骤:
[0164]
步骤s1:实验选取pubmed数据集;
[0165]
步骤s1.1:选取基线算法包括deepwalk、node2vec、grarep和netmf;
[0166]
步骤s1.2:超参数设置;所有基本嵌入方法,嵌入维度d设置为128;deepwalk和node2vec算法的每个节点进行10次随机游走,游走长度为80,窗口大小为10,并且node2vec中的返回参数p=1.0,进出参数q=0.5;
[0167]
步骤s1.3:在运行该方法和各类图嵌入的基线算法后,得出在不同粗化层下的micro-f1值和用时;micro-f1的计算过程如下公式:
[0168][0169][0170][0171]
步骤s1.4:不同算法的cpu时间process_time(当前进程的系统和用户cpu时间总和的值),这个时间值常用于代码时间的测试,并且报告的时间包括模型的所有阶段用时;
[0172]
步骤s1.5:对micro-f1值和用时进行可视化,并对比分析;
[0173]
图3是本发明方法(mlage)结合各类图嵌入的基线算法后,在不同粗化层下的micro-f1值和用时,这里的基线算法包括deepwalk、node2vec、grarep和netmf,实验使用的是pubmed数据集;
[0174]
图3(a)可以看出mlage对嵌入质量的提升,横坐标是粗化层数,纵坐标是micro-f1值,层数等于0代表不使用mlage的原始嵌入算法,可以观察到使用mlage后的嵌入在所有的方法中总是最优的;图3(b)可以看到mlage对运行时间的影响,横坐标是粗化层数,纵坐标
是执行时间,这里使用cpu时间作为执行时间,mlage的执行时间是各阶段的cpu时间之和;可见随着粗化层数的增加,时间消耗几乎是指数下降的;总的来说,使用mlage不止嵌入速度更快,还能提高嵌入质量;
[0175]
图4是deepwalk、netmf和粗化后的mlage(dw,l=7)、mlage(nmf,l=7)的耗时对比,可以看到多层方法只增添了少量的图融合,粗化和细化的时间,就使嵌入的耗时急剧下降,总用时仅为原本的1/67和1/373;
[0176]
实验分析对比其他多层方法在不同粗化层下的准确率和用时,实验结果如附表1-表5所示;包括如下步骤:
[0177]
步骤s2:实验选取cora、citeseer和pubmed数据集;
[0178]
步骤s2.1:使用基于随机游走的deepwalk、基于矩阵分解的grarep、基于图神经网络的dgi和基于图神经网络的半监督嵌入算法的gcn为嵌入内核,本发明方法也是用同样的嵌入内核;
[0179]
步骤s2.2:超参数设置;除了dgi之外的嵌入维度d设置为128,dgi的嵌入维度d是512,deepwalk算法的每个节点进行10次随机游走,游走长度为80,窗口大小为10,gcn和dgi都使用了提前停止策略,其学习率分别为0.01和0.001,并且epoch迭代次数都设置为200;在graphsage的配置方面,每个epoch都会训练了一个两层模型,学习率为0.00001,批次大小为256;
[0180]
步骤s2.3:设置不同粗化层;l=1、2、3;
[0181]
步骤s2.4:在运行本发明方法(mlage)和步骤s2.1中各类图嵌入的基线算法后,得出在不同粗化层下的micro-f1值和用时;
[0182]
步骤s2.5:获取不同算法的cpu时间(process_time),即当前进程的系统和用户cpu时间总和的值;
[0183]
步骤s2.6:对micro-f1值和用时进行可视化,并对比分析;
[0184]
对于mlage和其他多层方法对比,在直推式节点分类实验展示了三个粗化层数的结果,在归纳式节点分类实验展示了两个粗化层数的结果;在各类网络嵌入上的结果表明mlage与底层嵌入方法无关,并且能够在各种数据上提高嵌入的准确性和速度,甚至能提高现有最先进的网络嵌入算法的性能;实验结果见附表1-表5,其中gzoom代表graphzoom多层方法,l代表粗化层数;
[0185]
具体来说,对于直推式学习任务,mlage在cora、citeseer和pubmed数据集上对于deepwalk的分类micro-f1值分别提高了0.025、0.043和0.064,同时实现了最高8.1倍的运行时间缩减,见表1;对于grarep的分类micro-f1值分别提高了0.047、0.036、0.045,同时实现了最高5倍cpu运行时间缩减,见表2,此外,通过以grarep为嵌入内核在cora和citeseer数据集上的实验可发现在原本运行时间极短的情况下,多层方法的加速效果并不明显;与dgi相比,mlage也实现了更高的精度,加速比高达8.4
×
,见表3;
[0186]
表1基于随机游走的图嵌入算法deepwalk和以deepwalk为嵌入内核的多层方法的对比实验结果
[0187][0188]
表2基于矩阵分解的图嵌入算法grarep和以grarep为嵌入内核的多层方法的对比实验结果
[0189][0190]
表3基于图神经网络的无监督嵌入算法dgi和以dgi为嵌入内核的多层方法的对比实验结果
[0191][0192]
mlage在大多数情况下对于半监督学习的网络嵌入也能有准确性和可扩展性的提升,见表4,但在小数据集上由于gcn运行太快,无法提升其速度,并且citeseer数据集上的实验结果显示mlage(gcn)比gcn用时更长,其原因在于半监督算法计算嵌入前需要花费一点时间构建粗图的超节点标签矩阵,这点时间在节点较多,边较少的citeseer小型图数据
集上表现的更加明显,因为边少导致粗化的速度优势无法体现,节点多又导致构建超节点标签矩阵的用时比重更大,最终导致mlage(gcn)比gcn用时更长的结果;
[0193]
表4基于图神经网络的半监督嵌入算法gcn和以gcn为嵌入内核的mlage的对比实验结果
[0194][0195]
对于归纳学习任务,mlage在ppi和citeseer上的表现全都分别优于graphsage四种聚合函数的micro-f1值,加速比高达4.0
×
,见表5;
[0196]
表5归纳任务的micro-f1值和cpu时间,基线是具有四种不同聚合函数的graphsage的实验结果
[0197][0198]
这些结果表明,一种提高网络嵌入算法可扩展性的方法(mlage)提高了嵌入速度和质量,因为只在最粗的层次上对最小的粗化图训练嵌入模型,除了减少图的大小,mlage的粗化方法进一步过滤掉原始图中的冗余信息,使嵌入方法可以更直观的捕获原始图的全局结构;
[0199]
实验验证在大规模网络上的可扩展性,实验结果如附图5-图6所示,包括如下步骤:
[0200]
步骤s3:选取200多万个节点和700多万条边的friendster数据集进行实验;
[0201]
步骤s3.1:本发明的方法(mlage)使用deepwalk作为嵌入内核;
[0202]
步骤s3.2:设置超参数;嵌入维度d设置为128,deepwalk算法的每个节点进行10次随机游走,游走长度为80,窗口大小为10;
[0203]
步骤s3.3:设置不同粗化层;l=1、2、3、4、5、6;
[0204]
步骤s3.4:在运行该方法和各类图嵌入的基线算法后,得出在不同粗化层下的micro-f1值和用时;
[0205]
步骤s3.5:得出不同算法的cpu时间process_time;
[0206]
步骤s3.6:获得不同粗化后图的节点数变化和图的边数变化;
[0207]
步骤s3.7:对micro-f1值、用时、不同粗化后图的节点数变化和图的边数变化进行可视化,并对比分析;
[0208]
实验中mlage使用deepwalk作为嵌入内核,如图5所示,在1层粗化后,mlage和deepwalk的micro-f1得分相当,但大幅加速了cpu时间,加速比达到了3.2
×
;图6显示了粗化图的节点数和边数,可以清楚的展示mlage的粗化能力,在6层粗化后节点数降低至162,604个,仅为原图节点数的8.0%;边数降低至2,636,275条,仅为原始图边数的35.7%;此外,随着粗化层数的增加,mlage的嵌入精度只会优雅的降低,并且在5层粗化内仍保有很高的嵌入质量;这显示出了mlage的核心优势:通过合并具有相似信息的冗余节点来有效地粗化大型网络,从而保留对底层的基本嵌入模型很重要的图结构属性,在最粗图上应用基本嵌入时,可以直观地捕获图的全局结构,从而实现高质量的嵌入;
[0209]
本发明中所开发的原型系统的系统功能模块部分界面截图,如图7、图8、图9、图10、图11、图12、图13、图14、图15、图16所示,目的是通过清晰的系统页面去训练和测试模型,支持超参数的调整、数据集的管理、训练过程的可视化和测试结果的图表展示等功能;包括如下步骤:
[0210]
步骤s4:构建原型系统;原型系统的系统用例图如图7所示,系统功能模块如图8所示,模型训练生命周期时序图如图9所示,数据集上传时序图如图10所示;
[0211]
步骤s4.1:上传数据集,如图11所示;
[0212]
步骤s4.2:查看数据集,如图12-13所示;
[0213]
步骤s4.3:通过下拉框选择数据集和下游任务;如图14所示;
[0214]
步骤s4.4:设置超参数,超参数的输入也提供了输入限制和提示,避免因错误输入导致训练崩溃;如图14所示;
[0215]
步骤s4.5:点击开始训练将自动跳转到训练过程页面,页面最上方显示训练总进度,下面显示训练过程;根据指标变化趋势可为实验提供许多参考;如图15-16所示;
[0216]
步骤s4.6:训练结束将自动下载网络嵌入文件embedding.npy到本地,并执行测试任务;
[0217]
步骤s4.7:系统会将详细测试结果的log文件自动下载到本地。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1