一种基于端到端注意力网络的红外与可见光图像融合方法
1.本发明属于图像处理技术领域,尤其涉及一种基于端到端注意力网络的红外与可见光图像融合方法。
背景技术:
2.图像融合是一种用于图像信息增强的图像处理技术,由于硬件设备的理论和技术限制,由单个传感器在特定拍摄设置下无法有效并且全面的描述场景信息,例如,可见光图像包含更多的细节纹理信息,而红外图像则包含更多的幅度信息,所以,图像融合就是为了结合相同场景下不同源图像间的互补信息,生成信息更加丰富的单个图像,以将其应用于许多领域,例如摄影可视化、目标跟踪、医疗诊断和遥感监测。
3.总体来说,图像融合算法可以分为以下两种:传统的方法和深度学习的方法,早期的图像融合方法都采用数学变换的方式生成活性水平图,在空间域和变换域中设计融合规则,具有代表性的传统图像融合方法包括:基于多尺度变换的方法、基于稀疏表示的方法、基于子空间的方法、基于显著性的方法、基于总方差的方法。一方面这些传统的融合算法对于不同的源图像采取相同的特征提取和重建方法,并没有考虑到不同源图像之间的特征差异,从而导致融合效果较差,另一方面,传统的融合算法是由人工设计融合准则,过于简单,融合性能受限严重,且只能应用于特定的融合任务。近些年来,随着深度学习技术的不断发展,其在图像融合的方面的应用也越来越广,目前基于深度学习的融合算法主要由三类,一类是基于gan的生成对抗性网络,一类是基于自动编码器(ae)的网络,最后一类基于常规卷积神经网络(cnn),首先,基于深度学习的方法可以使用不同的网络分支来实现差异化特征提取,从而获得更有针对性的特征。其次,基于深度学习的方法,可以自行设计损失函数,通过反向梯度传播更新网络参数,得到更加合理的特征融合策略,从而实现自适应特征融合。得益于这些优势,深度学习促进了图像融合的巨大进步,获得了远远超过传统方法的性能。
4.尽管深度学习在图像融合领域已经取得了令人满意的结果,但仍有一些不足,(1)这些深度学习网络架构并没有充分考虑中间特征层,只是从最终的融合图像和源图像出发来设计损失函数,(2)大部分融合算法都只是在特征提取和特征重建阶段采用深度学习模型,特征融合采取的还是传统的方法,如特征图相加、取最大值和均值的方式,(3)部分深度学习模型都是采取两阶段训练方法,耗时且难以训练。
技术实现要素:
5.为解决上述技术问题,本发明提出了一种基于端到端注意力网络的红外与可见光图像融合方法,来提升图像融合效果。
6.为实现上述目的,本发明提供了一种基于端到端注意力网络的红外与可见光图像融合方法,包括:
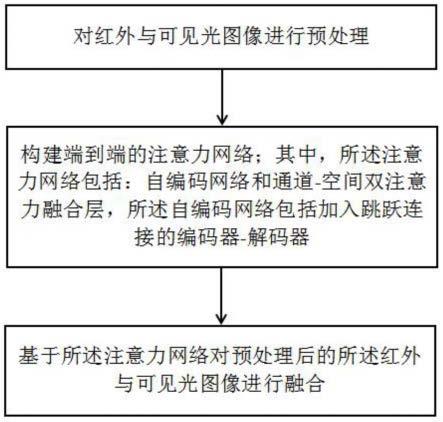
7.对红外图像和可见光图像进行预处理;
8.构建端到端的注意力网络;其中,所述注意力网络包括:自编码网络和通道-空间
双注意力融合层,所述自编码网络包括加入跳跃连接的编码器-解码器;
9.基于所述注意力网络对预处理后的所述红外图像和可见光图像进行融合。
10.可选地,对红外图像和可见光图像进行预处理包括:将所述红外图像和可见光图像转换为灰度图,并进行中心裁剪。
11.可选地,所述自编码网络中的编码器用于提取预处理后图像的多尺度深层语义特征,输出红外特征图和可见光特征图;所述自编码网络中的解码器用于根据所述红外特征图和可见光特征图重建为最终融合图像。
12.可选地,所述编码器包括若干最大池化下采样层和若干卷积块,基于第一预设数设置所述编码器的输入通道数,基于第二预设数设置所述编码器的输出通道数,所述编码器的每个卷积块后均含有batchnorm正则化和relu激活函数;
13.所述解码器包括若干上采样层和若干卷积块,基于第三预设数设置所述解码器的输入通道数,基于第四预设数设置所述解码器的输出通道数,所述解码器的每个卷积块后均含有batchnorm正则化和relu激活函数。
14.可选地,对所述自编码网络加入所述跳跃连接包括:
15.将所述编码器中每一个所述最大池化层的输入同所述解码器中的所述上采样层的输出相连接,连接路径上加入denseblock,在不同的连接路径中,使用不同数量的卷积块来构成denseblock,基于第五预设数来设置所述卷积块的输出通道。
16.可选地,所述通道-空间双注意力融合层包括:通道注意力模块和空间注意力模块;
17.在所述通道-空间双注意力融合层中,将所述红外特征图和可见光特征图在通道维度上进行连接,拼接后的图像分别输入至所述空间注意力模块和通道注意力模块,获取空间权重图和通道权重图,将所述空间权重图和通道权重图与所述红外特征图和可见光特征图相乘,然后将空间和通道注意力融合特征相加,获取中间融合图像。一方面通过中间融合层获得了中间融合图像,另一方面中间融合层能够让网络关注它更需要关注的地方。接着将中间融合图像送入自编码网络的解码器得到最终融合图像。
18.可选地,构建所述注意力网络还包括:设置损失函数;
19.设置所述损失函数包括:加入ssim结构相似度度量函数,引入了梯度算子,引入l2正则化,设计目标特征增强损失函数,最终对各个损失进行加权计算。
20.可选地,所述ssim结构相似度度量函数包括:亮度函数、对比度函数和结构比较函数;
21.所述亮度函数为:
[0022][0023]
其中,μ
x
、μy分别表示两张图像的平均亮度,n为图片的像素点个数,xi为像素值大小,x、y分别表示两张不同的图像,c1为用来防止分母为0的情况,c1=(k1*l)2,k1取0.01,l取255;
[0024]
所述对比度函数为:
[0025][0026]
其中,其中,σ
x
和σy分别表示两张图像的标准差,c2为用来防止分母为0的情况,c2=(k2*l)2,k2取0.03,l取255;
[0027]
所述结构比较函数为:
[0028][0029]
其中,σ
xy
表示两张图片的协方差,c3为用来防止分母为0的情况,c3=c2/2;
[0030]
所述ssim结构相似度度量函数为:
[0031][0032]
可选地,所述梯度算子为:
[0033]
其中,v为可见光源图像,为最终的融合图像,为梯度算符,||||1表示l1范数;
[0034]
所述l2正则化为:其中,x为设置的未知数,代表可见光灰度图和红外灰度图,||||2表示l2范数;
[0035]
所述目标特征增强损失函数为:
[0036][0037]
其中,m表示不同尺度下的融合过程,we为不同尺度下的权重,为第m层特征图的融合结果,和分别为第m层的可见光特征层与红外特征层,w
vi
为可见光特征层的权重,w
ir
为红外特征层的权重,f为frobenius范数。
[0038]
可选地,最终所述损失函数为:
[0039][0040]
其中,i为红外源图像,v为可见光源图像,为最终的融合图像,l1为
α1、α2、α3分别为各个损失函数的权重。
[0041]
与现有技术相比,本发明具有如下优点和技术效果:
[0042]
1.本发明使用编码-解码的网络结构,编码阶段充分提取输入图片的多尺度深层特征,解码阶段则有效的重构多尺度深层特征,接着进一步将跳跃连接引入自编码网络,有效的减缓梯度消失,且复用多尺度特征层,能够有效的增强网络提取特征和重构特征的能力。同时考虑到不同尺度下特征所包含语义信息的不同,不宜直接相连,所以在不同的连接层之间选取不同数量的卷积块来消除、平衡这种差异。
[0043]
2.本发明使用了通道-空间双注意力神经网络融合结构,不同于以往人工设计的融合策略,本发明能够有效的保存红外图像的幅度信息,以及可见光图像的细节纹理信息。
[0044]
3.本发明设计了全新的损失函数,引入ssim结构相似函数、l2正则化、梯度算子和目标特征增强损失函数,能够有效的提取源图像的显著和细节特征,采取一种端到端的网络结构,舍弃了人工设计的中间融合层和双阶段训练策略,使得训练更加快捷,融合结果更加有效。
附图说明
[0045]
构成本技术的一部分的附图用来提供对本技术的进一步理解,本技术的示意性实施例及其说明用于解释本技术,并不构成对本技术的不当限定。在附图中:
[0046]
图1为本发明实施例的一种基于端到端注意力网络的红外与可见光图像融合方法流程示意图;
[0047]
图2为本发明实施例的注意力网络结构示意图;
[0048]
图3为本发明实施例的空间-通道双注意力融合层结构示意图;
[0049]
图4为本发明实施例的一种红外图像;
[0050]
图5为本发明实施例的一种可见光图像。
具体实施方式
[0051]
需要说明的是,在不冲突的情况下,本技术中的实施例及实施例中的特征可以相互组合。下面将参考附图并结合实施例来详细说明本技术。
[0052]
需要说明的是,在附图的流程图示出的步骤可以在诸如一组计算机可执行指令的计算机系统中执行,并且,虽然在流程图中示出了逻辑顺序,但是在某些情况下,可以以不同于此处的顺序执行所示出或描述的步骤。
[0053]
实施例
[0054]
如图1所示,本实施例提供了一种基于端到端注意力网络的红外与可见光图像融合方法,包括:
[0055]
对红外图像和可见光图像进行预处理;
[0056]
构建端到端的注意力网络;其中,所述注意力网络包括:自编码网络和通道-空间双注意力融合层,所述自编码网络包括加入跳跃连接的编码器-解码器;
[0057]
基于所述注意力网络对预处理后的所述红外图像和可见光图像进行融合。
[0058]
进一步地,对红外图像和可见光图像进行预处理包括:将所述红外与可见光图像
转换为灰度图,并进行中心裁剪。
[0059]
进一步地,所述自编码网络包括:编码器和解码器;
[0060]
所述编码器用于提取预处理后图像的多尺度深层语义特征,输出红外特征图和可见光特征图;所述解码器用于根据所述红外特征图和可见光特征图重建为最终融合图像。
[0061]
进一步地,所述编码器由若干最大池化下采样层与若干卷积块构成,基于第一预设数设置所述编码器的输入通道数,基于第二预设数设置所述编码器的输出通道数,所述编码器的每个卷积块后均含有batchnorm正则化和relu激活函数;
[0062]
所述解码器由若干上采样层与若干卷积块构成,基于第三预设数设置所述解码器的输入通道数,基于第四预设数设置所述解码器的输出通道数,所述解码器的每个卷积块后均含有batchnorm正则化和relu激活函数。
[0063]
进一步地,对所述自编码网络加入所述跳跃连接包括:
[0064]
将所述编码器中每一个所述最大池化层的输入同所述解码器中的所述上采样层的输出相连接,连接路径上加入denseblock,在不同的连接路径中,使用不同数量的卷积块来构成denseblock,基于第五预设数来设置所述卷积块的输出通道。
[0065]
进一步地,所述通道-空间双注意力融合层包括:通道注意力模块和空间注意力模块;
[0066]
在所述通道-空间双注意力融合层中,将所述红外特征图和可见光特征图在通道维度上进行连接,拼接后的图像分别输入至所述空间注意力模块和通道注意力模块,获取空间权重图和通道权重图,将所述空间权重图和通道权重图与所述红外特征图和可见光特征图相乘,然后将空间和通道注意力融合特征相加,获取中间融合图像。一方面通过中间融合层获得了中间融合图像,另一方面中间融合层能够让网络关注它更需要关注的地方。接着将中间融合图像送入自编码网络的解码器得到最终融合图像。
[0067]
进一步地,构建所述注意力网络还包括:设置损失函数;
[0068]
设置所述损失函数包括:加入ssim结构相似度度量函数,引入了梯度算子,引入l2正则化,设计目标特征增强损失函数,最终对各个损失进行加权计算。
[0069]
本实施例中提出红外与可见光图像融合方法,其目的是为了融合不同模态图像中的互补和有益信息,更全面地描述成像场景,其分为以下步骤:(1)构建编码器-解码器的自动编码网络,用于提取输入图像的深层语义信息以及融合图像的重建(2)在自编码网络中加入跳跃连接,同时在跳跃连接中引入denseblock来缩小连接层之间语义信息丰富程度的差异(3)构建通道与空间的双注意力融合层,进一步保留可见光图像的纹理信息和红外图像的幅度信息(4)设计合适的损失函数,选择相关的数据集来训练以及测试融合网络的性能。本发明克服了传统融合方法中针对不同源图像采用相同方法提取特征的重复性缺陷,同时缩小了其手动设计融合策略的局限性,最终生成了包含多个源图像特征信息的单个融合图像,其发明可应用于遥感、医疗诊断、监控、目标跟踪等多个领域。其具体实施步骤如下:
[0070]
步骤1:构建编码器-解码器的自编码器网络,编码器用于提取输入图像的深层特征,解码器网络则用于将提取的深层特征重建为最终的融合图像。
[0071]
编码器网络由3个max-pooling下采样层以及9个普通卷积块构成,解码器网络则由3个上采样层以及7个普通卷积块构成,它们相互层层连结,如图2所示自编码网络中第一
个卷积块采用1*1卷积核,且采用反射填充(reflectionpad)以防止融合图像边缘伪影的出现,输入通道数设置为1,输出通道数设置为16,其余普通卷积模块均采用3*3的卷积核,步长设置为1,用0填充,不改变图像分辨率,其中编码器的输入通道数分别设置为16,64,64,128,128,256,256,256,输出通道数分别设置为64,64,128,128,256,256,256,256,编码器阶段设置了三个max-pooling下采样层,步长设置为2,解码器阶段使用双线性插值的方式将特征图的尺寸上采样两倍,解码阶段卷积块的输入通道数分别为512,256,256,128,128,64,输出通道数分别为256、128、128、64、64、64,以上全部的每个卷积块后都跟有batchnorm正则化和relu激活函数。
[0072]
步骤2:在自编码网络中加入跳跃连接,减缓梯度消失以及进一步弥补上采样过程和下采样过程导致的信息丢失,以及减缓深层神经网络的梯度消失问题。同时考虑到连接层之间的语义信息的差异,不宜直接相连,所以在不同的连接层上使用不同的卷积块来实现跳跃连接。
[0073]
如图2所述,将第一个maxpooling层的输入同第三个上采样层的输出通过跳跃连接在通道维度上相连,具体采用4个卷积块,每个卷积块的输入通道分别设置为64,64,128,192,输出通道则全部设置为64,具体连接方式为:将四个卷积块分别设置为a1,a2,a3,a4,则a1的输出作为a2的输入,a1和a2的通道连接作为a3的输入,a1、a2和a3的通道连接作为a4的输入,以上每个卷积块均设置为3*3卷积核,采用0填充,padding设置为1,不改变图像分辨率,其后跟有batchnorm正则化和relu激活函数。第二个max-pooling层的输入同第二个上采样层的输出相连,采取上述相同方式,不过为了平衡深层与浅层之间语义信息的差异,我们采用三个卷积块,第三个max-pooling层的输入同第三个上采样层的输出相连,采取上述相同方式,选取2个卷积块。
[0074]
步骤3:构建通道-空间双注意力融合层(如图3所示),分别提取红外与可见光图像的幅度与细节纹理信息,首先将经过编码器提取的两张源图像的特征信息在通道维度上进行拼接,再分别送入通道和空间注意力层获得相对应的特征图,进一步相加即可获得中间特征层融合图像。
[0075]
计算通道注意力的权重:将拼接的图像(s1)送入globalavergepooling层,再接连经过两个全连接层,其中第一个全连接层后使用h-swish激活函数,其输出通道数为s1通道数的1/4,第二个卷积层后使用sigmoid激活函数来获得0-1数值范围内的权重,其输出通道数等于s1通道数,最后将得到的权重与可见光特征层相乘,进一步保留可见光图像的细节信息。计算空间注意力的权重:将拼接好的图像分别送入avergepooling层和maxpooling层,在通道维度上进行max和averge采样,不改变图像分辨率,将输出的两个特征层在通道维度上进行拼接,接着送入一个7*7的卷积层,采用0填充,padding设置为3,不改变图像分辨率,后面接一个sigmoid激活函数,获得0-1范围内的权重分布图,与红外特征层进行相乘,进一步保留红外源图像的幅度信息。最终将在两个注意力结构上获得的特征图进行相加,得到中间融合图像。
[0076]
步骤4:设计损失函数:我们加入ssim结构相似度量函数,为了进一步保留可见光的细节纹理信息,我们还引入了梯度算子,引入l2正则化,最后还设计了目标特征增强损失函数。
[0077]
上述ssim结构相似度函数,其更能反应人类视觉对两幅图像相似度的判断,该相
似度函数由三个方面组成,分别是图像的亮度、对比度和结构比较函数,其中亮度相似度为:
[0078][0079]
μ
x
、μy分别表示两张图像的平均亮度,n为图片的像素点个数,xi为像素值大小,x、y分别表示两张不同的图像,c1为用来防止分母为0的情况,c1=(k1*l)2,k1取0.01,l取255;接下来是图片对比度,表明图像明暗变化的剧烈程度,对比度相似函数设置为:
[0080][0081]
其中,σ
x
和σy分别表示两张图像的标准差,c2为用来防止分母为0的情况,c2=(k2*l)2,k2取0.03,l取255;
[0082]
结构比较函数为:
[0083][0084]
其中协方差最终得到其中c1、c2、c3都是为了防止分母为0情况的产生,c3=c2/2。ssim的取值范围为-1至1,ssim值越大则说明图片相似程度越高,所以最终ssim度量的损失函数取l
ssim
=1-ssim。
[0085]
上诉梯度算子其中v代表可见光源图像,表示最终的融合图像,为梯度算符,||||1表示l1范数;由于可见图像具有丰富的纹理信息,因此通过梯度惩罚对可见图像的重建进行正则化,以保证纹理一致性。
[0086]
上述l2正则化设置为主要是衡量源图像和融合图像间的强度一致性,x为设置的未知数,代表可见光灰度图和红外灰度图,||||2表示l2范数。
[0087]
上述目标特征增强损失函数,设置为
[0088][0089]wvi
为可见光特征层的权重,w
ir
为红外特征层的权重,f为frobenius范数。因为红外图像比可见光图像具有更加显著的目标特征,所以我们设计此损失函数l2,用来约束融合图像的深度特征,从而保留显著特征。m设置为4,分别表示不同尺度下的融合过程,we代表了不同尺度下的权重,由于不同尺度下的幅度差异,我们将we分别设置为[1,10,100,
1000],代表第m层特征图的融合结果,和分别代表第m层的可见光与红外特征层,由于此损失函数主要是为了保存红外图像的显著特征,所以w
vi
设置的比w
ir
小,分别为3,6。
[0090]
上述对各个损失函数进行加权计算,其中上述对各个损失函数进行加权计算,其中其中最终的损失函数为最终的损失函数为其中,α1,α2和α3分别为各个损失函数的权重占比,α1,α2和α3设置为2,2,10,λ设置为5,we设置为[1,10,100,1000],w
vi
和w
ir
分别设置为3,6。
[0091]
步骤5:选择数据集:实验是在三个数据集上进行的,包括tno、nir和flir。
[0092]
在flir数据集中随机选择了180对图像作为训练样本,其中一种红外和可见光图像例如图4图5所示。在训练之前,将所有图像转换为灰度图。同时,用128
×
128像素对其进行中心裁剪。接着将多对红外和可见光图像送入上述所说网络进行训练,根据上述所说的损失函数计算损失,接着通过反向梯度传播来更新网络参数,其中训练的epoch设置为120,采用adam优化器,学习率设置10-3
,采用multisteplr学习率调整策略,每40个epoch,学习率乘减小10倍。训练完成后,使用剩下的flir数据,tno(40)数据集和nir country数据集来进行验证模型的融合效果。
[0093]
以上,仅为本技术较佳的具体实施方式,但本技术的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本技术揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本技术的保护范围之内。因此,本技术的保护范围应该以权利要求的保护范围为准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1