基于对比学习远距离监督的机器阅读理解模型训练方法
本发明涉及一种机器阅读理解模型训练方法,特别是一种基于对比学习远距离监督的机器阅读理解模型训练方法,属于自然语言处理。
背景技术:
1、机器阅读理解技术是指给定一个文本段落和一个相关的问题,利用机器学习的方法训练模型,使模型能够从文本段落中提取问题的答案。
2、通常,有监督的机器阅读理解模型使用人工标注的<问题,答案位置>数据进行训练。但是,标注训练数据耗费大量人力和时间。在低资源环境下学习机器阅读理解模型常常使用远距离监督(distant supervision)技术。远距离监督使用的是<问题,答案>数据,相较于精确地标注文档中的答案位置,<问题,答案>数据易于获得。具体地,给定一个<问题,答案>对,远距离监督机器阅读理解模型系统检索相关文本段落,在文本段落中寻找与答案匹配的字符串作为答案位置,并使用带有噪声的答案位置数据训练机器阅读理解模型。
3、但是,远距离监督数据包含许多错误标注的训练实例。如图1所示,段落2中的字符串“1990”与正确答案一致,但是它的上下文与问题无关,因此该段落并不是一个正确的训练实例。远距离监督数据中的错误标注问题将会给机器阅读理解模型的训练带来噪声和偏差。
4、一方面,由于错误标注段落的内容与问题以及正确段落的内容不一致,机器阅读理解模型倾向于学习答案位置的捷径(shortcut),而无法获得准确匹配上下文语义的能力。这是由于正确和错误标注的训练实例的上下文中最明显的共同之处是答案本身。例如,图1中的段落1和段落2都被远距离监督系统标注为该问题的正确段落,因此模型倾向于在答案预测中直接使用“1990”作为问题的答案。
5、另一方面,机器阅读理解模型会在问题和错误标注实例的上下文之间建立错误的语义关联,导致错误标注实例的语义表示过于接近问题语义,并且远离内容相似但不包含答案的负样例段落的表示。例如,如图1所示,段落2和段落3包含相似的信息。但是,由于段落2包含了答案而段落3不包含答案,在学习过程中段落2的表示会逐渐接近问题和段落1的表示,而段落3的表示会偏离问题和段落1的表示。因此,尽管段落2和段落3描述的内容相似,但其表示之间的距离会被拉大。
6、对比学习是指通过扩大正样本之间的相似度并最小化正样本与负样本的相似度,学习样本的表示分布的技术。
技术实现思路
1、为更有效地训练远距离监督机器阅读理解模型,本发明提供了一种基于对比学习远距离监督的机器阅读理解模型训练方法。
2、本
技术实现要素:
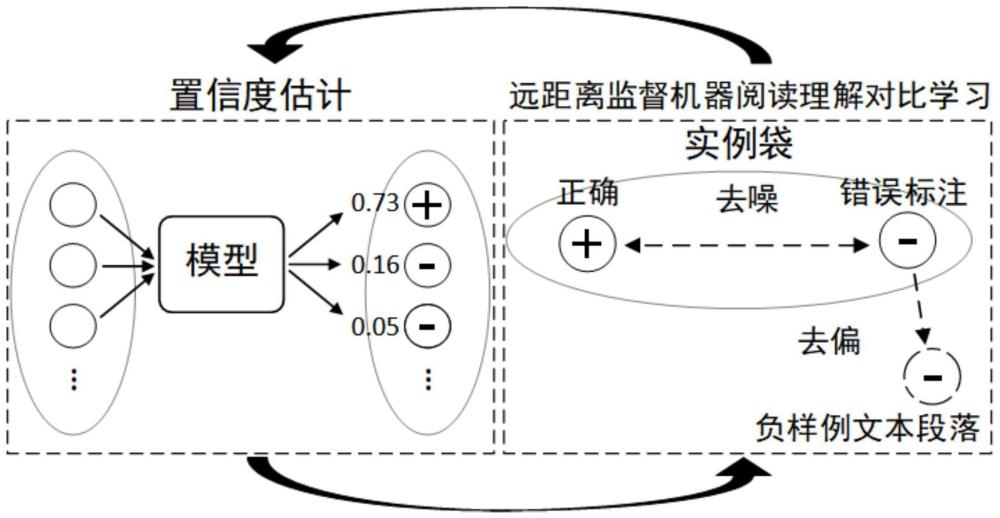
主要包括:(一)针对远距离监督机器阅读理解的训练实例置信度估计方法;(二)基于置信度的远距离监督机器阅读理解对比学习技术。针对远距离监督机器阅读理解的训练实例置信度估计方法将一个问题对应的所有<问题,文本段落,答案位置>训练实例作为实例袋,能够自动估计实例袋中训练实例的置信度,从而区分实例袋中正确和错误标注的实例。基于置信度的远距离监督机器阅读理解对比学习技术在模型训练过程中,通过对比实例袋内高置信度和低置信度的训练实例,对实例袋进行降噪;并通过混淆实例袋内低置信度的训练实例与实例袋外不包含答案的文本段落,消除实例上下文表示的偏差。
3、因为错误标注实例在模型训练中被用作正确实例,模型会错误地在问题和错误标注实例的上下文语义之间建立关联。这种错误的关联使得错误标注样本的语义表示存在偏差:错误标注样本的语义表示偏向问题语义,而远离了实例袋外表述了类似内容但是不包含答案的文本段落。本发明通过混淆实例袋内低置信度的训练实例与实例袋外不包含答案的文本段落,拉近了错误标注样本和不包含答案的文本段落的语义表示的距离,从而消除了由于错误标注导致的语义表示的偏差。模型训练过程中通过对比学习调整正负例样本表示的分布,即利用对比学习损失函数训练模型。
4、本发明所采用的技术方案概述如下:
5、一种基于对比学习远距离监督的机器阅读理解模型训练方法,其步骤包括:
6、1)对于每一给定的<问题,答案>对,首先从文本语料中检索包含该<问题,答案>对的文本段落,并在所述文本段落中查找并定位答案字符串,作为答案位置的标注,得到针对该<问题,答案>对的训练实例袋;将不包含该<问题,答案>对中答案的文本段落作为负样例文本段落;所述训练实例袋中的每一训练实例包括<问题,文本段落,答案位置>;
7、2)将所述训练实例中的问题、文本段落输入机器阅读理解模型,根据预测输出所述训练实例中的答案开始和结束位置概率分布,得到所述训练实例的答案位置;并根据答案开始和结束位置概率分布更新所述训练实例的置信度;
8、3)基于置信度更新后的所述训练实例对所述机器阅读理解模型进行训练;其中,训练过程所采用的损失函数为lcds=lce+μlscl;其中,为负样例文本段落的语义表示,表示第i个问题qi对应的负样例文本段落的集合,f(·)是调节表示相似度敏感性的函数,μ是一个超参数,n为<问题,答案>对的总数,为第i个实例袋中第j个训练实例的答案开始位置词,为第i个实例袋中第j个训练实例的答案结束位置词,ri,j为第i个实例袋中第j个训练实例的向量表示,ri,k为第i个实例袋中第k个训练实例的向量表示,ci,j表示第i个问题qi对应的第j个训练实例的置信度,ci,k表示第i个问题qi对应的第k个训练实例的置信度,j为第i个实例袋中训练实例的总数,和分别表示第i个问题qi对应的第j个训练实例中标注的答案开始和结束位置,代表机器阅读理解模型预测作为答案开始的概率,代表机器阅读理解模型预测
9、作为答案结束的概率。
10、进一步的,更新所述训练实例的置信度的方法为:第i个实例袋中第j个训练实例更新后的置信度ci,j=λci,j′+(1-λ)zi,j;其中,λ∈(0,1)表示滑动平均加权常量,ci,j′为第i个实例袋中第j个训练实例更新前的置信度。
11、进一步的,更新所述训练实例的置信度的方法为:更新所述训练实例的置信度的方法为:第i个实例袋中第j个训练实例更新后的置信度ci,j=λci,j′+(1-λ)zi,j;其中,λ∈(0,1)表示滑动平均加权常量,ci,j′为第i个实例袋中第j个训练实例更新前的置信度,和分别表示第i个问题qi对应的第k个训练实例中标注的答案开始和结束位置,代表机器阅读理解模型预测作为答案开始的概率,代表机器阅读理解模型预测作为答案结束的概率。
12、进一步的,更新所述训练实例的置信度的方法为:更新所述训练实例的置信度的方法为:第i个实例袋中第j个训练实例更新后的置信度ci,j=λci,j′+(1-λ)zi,j;其中,λ∈(0,1)表示滑动平均加权常量,ci,j′为第i个实例袋中第j个训练实例更新前的置信度,pstart(c)。代表机器阅读理解模型预测位置c作为答案开始的概率,pend(c)代表机器阅读理解模型预测c作为答案结束的概率。
13、进一步的,步骤1)中,根据问题与段落之间的检索匹配度,初始化每个训练实例的置信度分数。
14、进一步的,使用负样例文本段落的[cls]标签的向量表示作为r-。
15、进一步的,所述机器阅读理解模型包括但不限于基于bert预训练语言模型的机器阅读理解模型。
16、一种答案预测方法,其特征在于,将目标问题和所选文本段落输入到上述方法得到的机器阅读理解模型,输出所选文本段落中该目标问题对应的答案。
17、一种服务器,其特征在于,包括存储器和处理器,所述存储器存储计算机程序,所述计算机程序被配置为由所述处理器执行,所述计算机程序包括用于执行上述方法中各步骤的指令。
18、一种计算机可读存储介质,其上存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现上述方法的步骤。
19、一种基于对比学习远距离监督的机器阅读理解模型训练方法,包括以下关键技术:
20、1)针对远距离监督机器阅读理解的训练实例置信度估计方法:将一个问题对应的所有<问题,文本段落,答案位置>训练实例作为实例袋(instance bag),迭代地利用当前机器阅读理解模型预测输出的答案开始和结束位置概率估计实例袋中每个训练实例的置信度,并基于估计的置信度对模型进行训练。
21、2)基于置信度的远距离监督机器阅读理解对比学习模型训练技术:在模型训练过程中,通过对比实例袋内高置信度和低置信度的训练实例,对实例袋进行降噪;并通过混淆实例袋内低置信度的训练实例与实例袋外不包含答案的文本段落,消除实例上下文表示的偏差。
22、进一步地,技术1)部分使用问题与文本段落的检索匹配度对训练实例的置信度进行初始化。
23、进一步地,技术1)部分包含由模型输出结果更新实例袋中训练实例置信度的三种方法:
24、1)软权重(soft weighting):根据机器阅读理解模型对答案的预测概率,为每一个训练实例计算一个连续的置信度分数。
25、2)最大概率(hard max):假设每个实例袋中只有一个实例是标注正确的,则选择概率最高的实例作为正确的实例;实例袋中其他训练实例的置信度全部标注为0。
26、3)正确答案平均(positive average):如果模型预测的答案位置与标记的答案位置一致,则实例被标记为正确,正确的训练实例置信度分数均匀分布,即将正确的训练实例置信度都设置为相同值。
27、进一步地,技术2)部分包括由两部分组成的损失函数:
28、1)基于置信度的远距离监督机器阅读理解对比学习损失函数。
29、2)基于置信度加权的机器阅读理解交叉熵损失函数。
30、进一步地,技术2)部分包括对实例袋进行降噪:
31、通过最小化实例袋中高置信度和低置信度训练样例语义表示的相似度,对实例袋进行降噪,避免模型学习预测答案位置的错误捷径。
32、进一步地,技术2)部分包括消除训练过程中实例上下文表示的偏差:
33、通过最大化实例袋中低置信度训练实例与实例袋外不包含答案的负样例文本段落的语义表示的相似度,混淆低置信度训练实例与负样例文本段落,避免训练实例上下文语义漂移问题。
34、与现有技术相比,本发明的有益效果是:
35、1)针对低资源监督机器阅读理解,提出了对比学习远距离监督方法,通过实例袋级实例对比策略自动判别错误标注实例,并对远距离监督过程进行去噪和去偏。
36、2)设计了基于置信度的对比学习策略,根据估计的置信度得分对齐训练实例之间的距离,从而优化训练实例语义表示的分布,避免由错误标注实例带来的预测捷径和语义漂移问题。
- 还没有人留言评论。精彩留言会获得点赞!