一种基于LambdaMart的通讯录搜索智能排序方法与流程
一种基于lambdamart的通讯录搜索智能排序方法
技术领域
1.本发明属于大数据技术领域,尤其涉及一种基于lambdamart的通讯录搜索智能排序方法。
背景技术:
2.在互联网应用场景中,排序是非常核心的模块。一个最直接的应用,就是日常生活常用到的搜索引擎。用户通过搜索框提交query,搜索引擎会返回一些与query相关的文档,并根据相关度大小排序后展示给用户。这一应用场景中,最相关的一些文档能否通过排序后优先展示,将直接影响用户。除这些之外,排序算法也应用于在线广告、协同过滤、多媒体检索等领域。传统排序方法,基于人工方式做策略组合,在数据量较小时能够起到作用。随着互联网数据量的增加,这种方法变得越来越困难。因而,更自然的解决方案,是开发基于机器学习的搜索引擎排序算法。这种算法通常称之为learning to rank(ltr)。
3.在实际业务中,集团邮箱通讯录排序功能体验存在缺陷,不符合用户需求,造成用户投诉。这就需要实现一种智能排序方法,来解决该问题。
技术实现要素:
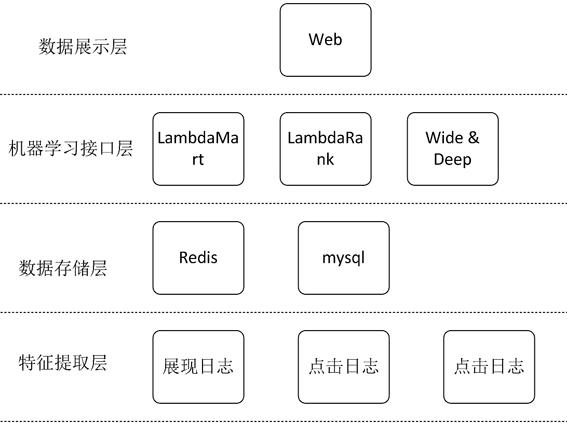
4.本发明的目的是提供一种基于lambdamart的通讯录搜索智能排序方法,解决了传统的搜索系统中基于规则的搜索排序的不准确和比较差的使用体验的技术问题。为实现上述目的,本发明采用如下技术方案:一种基于lambdamart的通讯录搜索智能排序方法,包括如下步骤:步骤1:在特征工程层以用户搜索的行为日志作为数据源进行数据的特征构造,包括如下步骤:步骤s1-1:构造基于细分业务的相关特征;步骤s1-2:构造与搜索行为相关的特征,包括query-doc的相关性、query在文档中出现的次数,还包括査询词的proximity计算结果、doc长度、bm25计算结果和tfidf计算结果;步骤s1-3:以用户的点击行为为日志,搜集记录用户点击的序列、点击先后顺序、观看时间和日志曝光情况,生成label特征;步骤2:在数据存储层对步骤1中构造后的数据进行存储;步骤3:在机器学习接口层构建ndcg排序评估模型,即以top数据的准确率作为训练的指标,最终得到一个排序模型,并对排序模型进行部署;步骤4:在数据展示层利用vue进行数据的展示,并结合element ui进行界面的设计和展示。
5.优选的,在执行步骤s1-1时,所述细分业务包括集团或个人检索通讯录和邮件地址本、往来人员,人力树最短路径和岗级。
6.优选的,在执行步骤2时,采用以下数据格式对步骤1中构造后的数据进行存储:
数据格式:label qid:特征1:特征2:特征3:...特征n。
7.优选的,所述label特征的设置包括long click长点击设置类别为3、middle click中点击设置类别为2、short click短点击设置类别为1和impression曝光未点击设置类别为0。
8.优选的,在处理日志曝光情况时,具体包括如下步骤:步骤s1-3-1:使用曝光日志时选择埋点日志;步骤s1-3-2:在处理用户样本时,包括如下两个方式:方式一:保留有行为的用户的负样本,其他的负样本进行随机负采样;方式二:去除只有曝光但没有点击操作的用户的样本;步骤s1-3-3:根据用户最后一次点击行为的位置,过滤掉最后一次点击之后的展示。
9.优选的,在执行步骤3时,在机器学习接口层采用ranknet、lambdarank、lambdamart和ranksvm算法构建排序模型。
10.本发明所述的一种基于lambdamart的通讯录搜索智能排序方法,解决了传统的搜索系统中基于规则的搜索排序的不准确和比较差的使用体验的技术问题,本发明与基于匹配形式的搜索相比具有更好的泛化能力,大大提高了用户的体验和搜索的速度,从而提高了办公的效率,并且该方法不仅适用于电信领域的通讯录搜索系统,还适应于其他需要智能搜索排序的其他领域。
附图说明
11.图1是本发明的系统框架图;图2是本发明的搜索智能排序流程图;图3是本发明的lambdamart训练的ndcg数据结果图;图4是本发明的lambdarank训练结果图;图5是本发明的ranknet训练结果图;图6是本发明的ranksvm训练结果图。
具体实施方式
12.由图1-图6所示的一种基于lambdamart的通讯录搜索智能排序方法,包括如下步骤:步骤1:在特征工程层以用户搜索的行为日志作为数据源进行数据的特征构造,包括如下步骤:步骤s1-1:构造基于细分业务的相关特征;所述细分业务包括集团或个人检索通讯录和邮件地址本、往来人员,人力树最短路径和岗级。
13.步骤s1-2:构造与搜索行为相关的特征,包括query-doc的相关性、query在文档中出现的次数,还包括査询词的proximity计算结果、doc长度、bm25计算结果和tfidf计算结果;步骤s1-3:以用户的点击行为为日志,搜集记录用户点击的序列、点击先后顺序、观看时间和日志曝光情况,生成label特征;
为了进行基于机器学习的训练,本实施例中需要构造搜索点击的标签数据:用户的点击行为日志,同一个query下用户都点击了哪些answer,以及点击先后顺序和观看时间,曝光情况。这些特征会作为最终的label特征。
14.所述label特征的设置包括long click长点击设置类别为3、middle click中点击设置类别为2、short click短点击设置类别为1和impression曝光未点击设置类别为0。
15.在本实施例中,在处理日志曝光情况时,具体包括如下步骤:步骤s1-3-1:使用曝光日志时选择埋点日志;本实施例中不采用服务器web接口返回的日志,因为web接口返回的日志中的接种是会增加很多无效负样本。
16.步骤s1-3-2:在处理用户样本时,包括如下两个方式:方式一:保留有行为的用户的负样本,其他的负样本(没有过对应的正样本),进行随机负采样(优于只保留有行为的用户的负样本);方式二:去除只有曝光但没有点击操作的用户的样本;本实施例中,如果不过去除,模型就只能够学习到活跃用户的行为习惯,这就导致线下数据与线上数据分布有偏差,可以根据线上的abtest测试效果来决定最终是否去除。
17.步骤s1-3-3:根据用户最后一次点击行为的位置,过滤掉最后一次点击之后的展示。本实施例中,也可以保留最后一次点击后的少数几个。
18.步骤2:在数据存储层对步骤1中构造后的数据进行存储。
19.本发明的数据存储层可以采用redis或mysql的数据库进行数据存储。
20.本实施例中,为了提高搜索的速度和存储每个数据的特征,将其数据和信息存在redis中。
21.具体采用以下数据格式对步骤1中构造后的数据进行存储:数据格式:label qid:特征1:特征2:特征3:...特征n具体的数据格式含义如下表1所示:表1步骤3:在机器学习接口层构建ndcg排序评估模型,即以top数据的准确率作为训练的指标,最终得到一个排序模型,并对排序模型进行部署;在机器学习接口层采用ranknet、lambdarank、lambdamart和ranksvm算法构建排序模型,用这些模型对搜索日志进行训练,并最终得到模型,并将该模型进行部署在服务器中,并提供单独或者集成形式的接口,供用户调度查询搜索。
22.本实施例中,机器学习的训练数据划分8:2的训练和测试数据进行模型的训练和验证。
23.模型的训练和预测:综合人工规则和机器学习两种方式对数据进行预测,并对模型进行上线前的ab test,并观察模型预测的效果并选择最佳的模型或者集成模型进行最
终的部署,并将模型存在服务器中,提供接口,以便于进行随时的调取搜索智能排序。
24.本实施例的模型训练过程和实验数据结果如下:本实施需要5w+的有标签数据集训练,算法的流程:训练数据获取-》特征提取-》模型训练-》测试数据预测-》效果评估。
25.在本实施中,对各个模型进行训练,并进行ndcg指标的比较,其中ndcg的公式如下所示:由于需要考虑文档的位置和相关性的多样性(并非只有相关和不相关这两个选择),在这里选择ndcg(主流搜索优化的评测指标),该衡量指标通过这种归一化的折扣的方式来保证头部的排序的准确性。
26.其中,r(l)代表第i个结果的相关性,i代表i个结果的排序位置。
27.i越小,r(i)越大,ndcg越大,越靠前的结果约相关,这个指标就越高。
28.本实施例对各个模型的数据结果如下表2所示:表2对上数据进行分析,lambdamart和ranknet是比较好的,最差的是lambdarank只有0.56的数据结果,本实施例采用lambdamart的算法。
29.步骤4:在数据展示层利用vue进行数据的展示,并结合element ui进行界面的设计和展示。
30.本发明实现智能排序可以对名字或账号全匹配的优先显示,排序规则改为“来往联系人(最近联系的排前面)-》个人通讯录-》组织路径由近到远。名字或账号模糊的放至名字全匹配后面,排序规则同名字全匹配的。
31.本发明基于lambdamart的算法,采用了机器学习中的gbdt模型不断地对ndcg结果进行梯度下降的残差拟合,和以往的基于匹配式的,更加的注重ndcg指标的优化,即数据展示的准确率和展示顺序的准确度。从而和传统的智能排序相比,有着更好的用户体验。
32.本发明可应用于各种文本类数据的特征构造,可以快速迁移构造不同的特征构造需求,将机器学习中的树的概念引入,具有很深的特征表达和训练拟合效果。同时也具有比较好的泛化模型效果,提出了可以直接表达搜索排序效果的指标,更具有针对性的优化模
型的目标,即每个数据展示的顺序。同时综合比较了各个模型的效果,对其他实验具有参考的实际价值。
33.本发明所述的一种基于lambdamart的通讯录搜索智能排序方法,解决了传统的搜索系统中基于规则的搜索排序的不准确和比较差的使用体验的技术问题,本发明与基于匹配形式的搜索相比具有更好的泛化能力,大大提高了用户的体验和搜索的速度,从而提高了办公的效率,并且该方法不仅适用于电信领域的通讯录搜索系统,还适应于其他需要智能搜索排序的其他领域。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1