一种基于聚类和特征空间修正的病理全切片图像分类方法
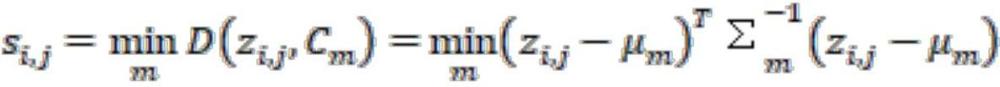
本发明属于图像处理及应用领域,涉及病理全切片图像分类方法。具体涉及一种基于聚类和特征空间修正的病理全切片图像分类方法,本方法操作简单,具有精度和鲁棒性,节省时间,降低病理诊断的成本。
背景技术:
1、现有技术公开了组织病理学图像分析对于癌症诊断、预后和治疗反应预测至关重要。近些年,随着数字病理学技术的兴起,组织病理学图像可以通过数字切片扫描仪数字化为全切片病理图像,从而促进了深度学习技术在自动化病理图像分析中的应用。使用深度学习进行全切片病理图像分析有两个主要的挑战,第一是全切片病理图像的尺寸非常巨大(通常达到50000×50000像素)从而无法直接将整张图像作为深度学习模型的输入。因此,全切片病理图像通常被切分成很多小斑块进行处理,以减少计算负担。第二是由于细粒度的人工标注太昂贵且耗时,每个斑块的标签通常是不可知的,只有每个切片的标签可知,所以传统的强监督学习不能使用。在此基础上,多实例学习作为一种有效的弱监督算法成为了基于深度学习的全切片病理图像分析的主流方法。遗憾的是,当前几乎所有的多实例学习方法均没有显示地建模数据的分布,而只是仅仅通过训练分类器判别式地学习切片级或实例级的决策分界面。具体来说,现有的方法学习切片级或实例级分类器的过程均是判别式地使两个类别的特征在特征空间中分别聚集的过程,然而由于弱标签能够提供的监督信息很少,在没有显示地建模数据分布的情况下,该聚集过程并不充分,导致了它们性能的受限。
2、因此开发一种能够显示建模数据分布的深度多实例方法用于病理全切片图像自动化诊断是目前急需解决的问题。
3、基于现有技术的现状,本技术的发明人拟提供一种病理全切片图像分类方法,具体涉及一种基于聚类和特征空间修正的病理全切片图像分类方法,本方法操作简单,具有精度和鲁棒性,节省时间,降低病理诊断的成本。
技术实现思路
1、本技术的目的是基于现有技术的现状,提供一种病理全切片图像分类方法,具体涉及一种基于聚类和特征空间修正的病理全切片图像分类方法,尤其是一种新的基于特征分布引导的用于全切片病理图像自动化分类和定位的深度多实例方法。本方法操作简单,具有精度和鲁棒性,节省时间,降低病理诊断的成本。
2、本发明提供了一种基于特征分布引导的用于全切片病理图像自动分类和定位的深度多实例学习方法,其中包括,首先,分别将训练集和测试集中所有全切片病理图像切为不重叠的斑块,之后使用掩膜自编码器进行自监督训练并将所有实例都映射到初始特征空间中,然后,提出了一种基于聚类的特征空间建模方法和一种基于伪标签的特征空间修正方法,通过特征空间的迭代建模和修正,网络可以自动学习到全切片病理图像中的异常斑块,从而自动完成病理图像的自动诊断和异常区域定位。本技术能够实现全切片病理图像的自动诊断和异常区域定位。
3、具体的,本技术提供的一种基于特征分布引导的用于全切片病理图像分类和定位的深度多实例学习框架,其包括步骤:
4、首先,分别将训练集和测试集中所有全切片病理图像切为不重叠的斑块,之后使用掩膜自编码器进行自监督训练并将所有实例都映射到特征空间中,该特征空间为方法的初始特征空间,之后将迭代式的对该特征空间进行建模和修正,在一次迭代中,首先使用k-means算法对训练集中所有来自阴性切片的实例进行聚类,然后分别计算所有来自阴性切片和阳性切片的实例关于该分布的马氏距离,该距离称为阳性分数,然后,分别挑选一定比例来自阳性切片中阳性分数最高的实例和来自阴性切片中阳性分数最低的实例作为极端样本,阳性分数最高的实例被直接赋予伪标签1,而阳性分数最低的实例被赋予伪标签0。
5、然后,定义了一个简单的二分类器,由一层全连接层组成的线性映射层和一个一层全连接层的分类层组成。通过这些极端样本和伪标签对该二分类器进行一次有监督的训练,然后摈弃其中的分类层,使用线性映射层对当前特征空间进行重新映射。以上的一次迭代过程称为对当前特征空间的一次建模和修正。然后重复以上迭代过程,直至二分类器的训练收敛而结束。注意,整个迭代过程中只有切片级的标注被使用。
6、最后,在测试时,将所有测试实例映射到修正后的特征空间并计算每个实例的阳性分数完成异常区域定位任务。对于切片级别的分类,仅使用最简单的平均池化方法对一个切片中的所有实例的阳性分数进行聚合。
7、更具体的,
8、本技术的基于特征分布引导的用于全切片病理图像自动分类和定位的深度多实例学习方法,其包括步骤:
9、(1)使用自监督掩膜自编码器进行特征空间的初始化;
10、(2)使用基于聚类和马氏距离的特征分布建模方法进行特征空间建模;
11、(3)基于伪标签迭代的特征空间修正;
12、(4)基于阳性分数的测试。
13、所述的方法中,自监督掩膜自编码器进行特征空间的初始化:
14、使用自监督学习框架掩膜自编码器(mae)提取所有实例的特征表征并完成特征空间的初始化,掩膜自编码器通过随机遮盖高比例的输入图像的斑块并基于transformer重建缺失像素的方式学习鲁棒的特征表示而不需要人工标注。
15、所述的方法中,掩膜自编码器使用一个非对称的编解码结构,其中编码器用于提取可见的未遮盖的切片特征,解码器通过处理可见切片的特征编码和掩膜编码向量逐像素重建输入图像,其中,首先使用来自阴性和阳性切片的所有的实例训练掩膜自编码器,然后使用训练得到的编码器作为实例级别的特征提取器分别提取所有实例的特征,从而完成特征空间的初始化。
16、所述的方法中,基于聚类和马氏距离的特征分布建模方法进行特征空间建模:
17、首先使用k-means算法将训练集中所有阴性实例聚为m类,其中每个cluster记作cm,继而,使用马氏距离对训练集中所有来自阴性切片和阳性切片的实例计算阳性分数si,j,
18、
19、其中,d(·)表示距离度量,μm和∑m是该类簇中所有阴性实例的均值和协方差,阳性分数代表一个实例为阳性的信心程度,阳性分数越大表明该实例属于阳性的概率越大,反之则越小。
20、所述的方法中,基于伪标签迭代的特征空间修正:
21、以掩膜自编码器构建的特征空间为初始特征空间,进一步提出基于伪标签的特征空间修正方法;该方法是一种迭代的方法,在每次迭代中,基于聚类的特征建模方法对当前特征空间进行建模并得到当前训练集中所有实例的阳性分数,然后,分别挑选一定比例来自阳性切片中阳性分数最高的实例和来自阴性切片中阳性分数最低的实例作为极端样本,阳性分数最高的实例被直接赋予伪标签1,而阳性分数最低的实例被赋予伪标签0,之后,定义一个简单的二分类器,包括由一层全连接层组成的线性映射层和一个一层全连接层的分类层,其中,线性映射层用于将当前特征空间进行等维度映射,分类层用于对极端样本和相应伪标签进行监督训练,在每次迭代中,对该二分类器进行一次训练,之后摈弃其中的分类层,使用线性映射层对当前特征空间进行重新映射,以上的一次迭代过程称为对当前特征空间的一次修正,之后重复以上迭代过程,直至二分类器的训练收敛而结束。
22、所述的方法中,基于阳性分数的测试:将所有测试实例映射到修正后的特征空间并计算每个实例的阳性分数完成定位任务,对于切片级别的分类,仅使用最简单的平均池化方法对一个切片中的所有实例的阳性分数进行聚合。
23、本发明具有以下有益效果:
24、本发明提供的基于特征分布引导的用于病理全切片图像自动化分类和定位的深度多实例方法能够实现全切片病理图像的自动诊断和异常区域定位。本发明提供的方法操作简单,具有目前国际上最高的精度和鲁棒性,自动化的检测可节省时间节约费用,显著降低病理诊断的成本。
- 还没有人留言评论。精彩留言会获得点赞!