一种开放域语料关系联合抽取方法
1.本发明涉及自然语言处理技术领域,特别涉及一种开放域语料关系联合抽取方法。
背景技术:
2.随着互联网技术的快速发展,信息技术产生海量无结构化数据,信息抽取技术已经被广泛应用于从无结构化数据中抽取出结构化且有用的数据信息。与传统的信息抽取技术不同,开放域关系抽取不需要定义关系类型,此外,不受特定领域数据集的限制,可以从非结构化数据中抽取出关系三元组,较好地应用于数据转变、场景切换等情况下的信息抽取。随着研究的深入,基于深度学习的开放域关系抽取技术逐渐成为主流趋势。
3.目前,基于深度学习的开放域关系抽取技术主要采用序列标注的方法、抽取式或生成式的方法,这些方法技术把抽取关系三元组的过程分为两个步骤,首先抽取语料中的关系短语,再根据抽取的关系短语结果,抽取可能对应的实体对短语。传统的开放域关系抽取方法主要存在三个问题:(1)主观地将实体对短语的抽取、关系短语的抽取划分为两个子任务,忽视了两者之间的内在语义联系及语法结构上的依存关系,容易产生误差传播,导致开放域关系抽取结果准确率不高;(2)忽略实体短语存在于多个关系三元组中的实体短语重叠等问题,导致开放域关系抽取结果语义不充分,影响抽取准确率;(3)未充分考虑语料中语句词之间的依赖关系,部分关系三元组序列冗余,导致误差积累,影响开放域关系抽取的准确率与效率。
4.针对上述传统开放域关系抽取技术存在的问题,本发明创新性地提出一种基于多链路图注意力网络的开放域关系联合抽取方法,采用实体对短语和关系短语联合学习的方式,实现开放域关系三元组的联合抽取;此外,采用图注意力网络融合语料中语句字符级的依赖关系,通过多链路解码三元组的机制,解决关系三元组冗余过长等问题。
技术实现要素:
5.本发明针对现有技术中的不足,提供一种开放域语料关系联合抽取方法;针对开放域关系抽取普遍存在的关系三元组序列冗余、关系三元组重叠、关系三元组抽取准确率低等问题。
6.为实现上述目的,本发明采用以下技术方案:
7.一种开放域语料关系联合抽取方法,包括以下步骤:
8.s1、提取语料中字符的特征向量:将语料输入至bert预训练语言模型中对语料进行编码,并得到语料中字符的特征向量;
9.s2、在图注意力网络中进行特征融合:基于图注意力网络将字符的特征向量中所包含的特征进行融合,并学习字符间的依赖关系;
10.s3、将语料中的关系短语进行抽取:通过设计关系短语序列标注模型抽取语料中存在的关系短语,其中关系短语的含义为语料句子中的谓语部分;
11.s4、将语料中的实体对短语进行抽取:由于关系短语的含义为语料句子中的谓语部分,因此每个关系短语都有对应的实体对短语,其中实体对短语包括首实体短语和尾实体短语,首实体短语的含义为语料句子中的主语,尾实体短语的含义为语料句子中的宾语;根据步骤s2的字符间依赖关系以及通过基于图注意力网络预测每个关系短语所对应的实体对短语,并进行抽取;
12.s5、根据步骤s3抽取的关系短语以及步骤s4抽取对应的实体对短语,将其组成三元组,并确定该三元组的置信度,若置信度大于或等于设定置信度阈值时,则将该三元组作为输入语料的开放域关系三元组。
13.为优化上述技术方案,采取的具体措施还包括:
14.进一步地,步骤s2中所述学习字符间的依赖关系的具体计算公式为:
[0015][0016]
式中,表示第i个字符在第t层的隐层状态向量,其体现了字符间的依赖关系;表示第i个字符在第t-1层的隐层状态向量,σ表示为sigmoid激活函数,n表示输入语料的长度,m
ij
表示为图注意力网络的依赖权重,w
t
和b
t
分别是图注意力网络的参数矩阵和偏置向量。
[0017]
进一步地,步骤s3的具体内容为:
[0018]
s3.1、设计关系短语序列标注模型,以计算某一字符是关系短语的起始位置或结束位置的概率,该模型具体计算公式为:
[0019][0020][0021]
式中,和分别代表输入语料的序列中,第i个字符作为关系短语的开始位置和结束位置的概率,xi代表第i个词的编码序列,w
start
表示计算关系短语起始位置的权重,w
end
表示计算关系短语结束位置的权重,b
start
表示计算关系短语起始位置的偏差,b
end
表示计算关系短语结束位置的偏差,σ表示sigmoid激活函数;
[0022]
s3.2、在步骤s3.1所计算的和中,若概率值大于概率阈值,则该位置设为1,反之设为0,以此确定关系短语的位置,实现语料中关系短语的抽取。
[0023]
进一步地,步骤s4的具体内容为:步骤s4中根据步骤s2的字符间依赖关系以及通过基于图注意力网络预测每个关系短语所对应的实体对短语,并进行抽取的具体内容为:
[0024]
s4.1、设定在步骤s3中,所抽取出的某个关系短语,其在关系短语集合中的索引为λ,通过关系嵌入表示为向量h
λ
;
[0025]
s4.2、将向量h
λ
和步骤s2求出的隐层状态向量一起输入到解码器中,并通过图注意力网络处理获得融合卷积层特征的解码器输出;
[0026]
s4.3、将步骤s4.2的输出输入到图注意力网络中的预测层,实现实体对短语中的首实体短语和尾实体短语的预测,并进行抽取。
[0027]
进一步地,步骤s4.3中所述“实现实体对短语中的首实体短语和尾实体短语的预测,并进行抽取”的具体计算公式为:
[0028]
抽取的首实体短语位置计算公式如下:
[0029][0030][0031]
式中,表示抽取的首实体短语的起始位置概率值,表示抽取的首实体短语的结束位置概率值,表示抽取首实体短语起始位置权重,表示抽取首实体短语结束位置权重,表示抽取首实体短语起始位置偏差,表示抽取首实体短语结束位置偏差,hg表示经过图注意力网络处理的上下文特征;
[0032]
抽取的尾实体短语位置计算公式如下:
[0033][0034][0035]
式中,表示抽取的尾实体短语的起始位置概率值,表示抽取的尾实体短语的结束位置概率值,表示抽取尾实体短语起始位置权重,表示抽取尾实体短语结束位置权重,表示抽取尾实体短语起始位置偏差,表示抽取尾实体短语结束位置偏差,hg表示经过图注意力网络处理的上下文特征。
[0036]
进一步地,步骤s5中所述置信度阈值为0.8。
[0037]
本发明的有益效果是:本发明采用关系短语与实体对短语联合抽取的方式,建立实体对短语与关系短语的内在深度语义依赖关系。此外,通过多链路图注意力网络融合语料字符级特征联系,更好地解决实体短语重叠,关系三元组序列冗余等问题,提升开放域关系抽取结果的语义可靠性与简洁性。
附图说明
[0038]
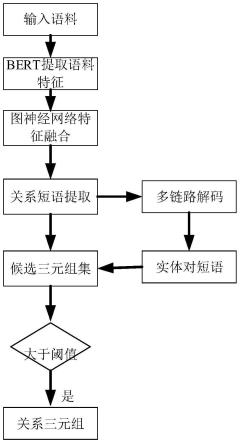
图1是本发明整体方式框架示意图。
[0039]
图2是本发明整体抽取方案的流程示意图。
具体实施方式
[0040]
现在结合附图对本发明作进一步详细的说明。
[0041]
参考图1,本技术的整体技术方案为,包括:
[0042]
步骤1.语料特征提取。语料输入现有的bert预训练语言模型对语料进行编码,提取语料字符级特征,得到语料的特征向量。
[0043]
h0=sws+w
p
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(1)
[0044]
hα=trans(h
α-1
),α∈[1,n]
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(2)
[0045]
其中,s代表输入的句子中词的one-hot向量矩阵,ws代表词嵌入矩阵,w
p
代表位置嵌入矩阵,其中p表示输入句子中的位置索引;hα代表隐藏状态向量,即输入句子在第α层的上下文表示,n代表transformer块的数量。
[0046]
其中,公式(1)表示提取语料的特征向量;公式(2)表示隐藏状态向量,h0代表得到的语料特征向量;公式(1)、公式(2)是bert提取语料特征向量的具体体现,bert为通用模
型。
[0047]
步骤2.图注意力网络特征融合。通过图注意力网络融合语料中字符级的特征,学习语料字符间的依赖关系。
[0048][0049]
其中,m
ij
表示输入图注意力网络的依赖权重,w
t
和b
t
分别是图卷积神经网络的参数矩阵和偏置向量。当t=0时,表示进行图卷积操作前第i个节点的初始隐层向量。
[0050]
其中,代表第i个字符在第t层的隐层状态向量,体现了语料间的字符依赖关系;n代表输入语料的长度;代表第i个字符在第t-1层的隐层状态向量,公式中m
ij
代表了图注意力网络的依赖权重,而该权重正是语料字符间的依赖权重矩阵。
[0051]
步骤3.关系短语抽取。通过关系短语序列标注模型,抽取语料可能存在的关系短语。
[0052][0053][0054]
其中,分别代表输入句子序列中,第i个词作为关系短语的开始位置和结束位置的概率。在关系短语序列标注模型中,若概率值大于阈值,则该位置设为1,反之设为0。xi代表第i个词的编码序列,w表示权重,b表示偏差,σ表示sigmoid激活函数。
[0055]
步骤4.实体对短语抽取。通过多链路解码,预测每个关系短语对应的实体对短语的起止位置,进而解码得到每个关系短语对应的实体对短语(关系短语表示语料中可以代表实体对关系的短语,如:动词、动词短语、等;亦可以理解为简单句中的谓语;实体对短语表示语料中关系存依托存在的名词短语;亦可以理解为句子中的主语和宾语)。
[0056]
假设在上一阶段中抽取出某个关系短语,其在关系集合中的索引为λ,通过关系嵌入表示为向量h
λ
,将其和(3)中的隐向量输入到解码器中,通过图注意力机制获得融合卷积层特征的解码器输出,最后将其输入首实体短语首、尾位置的预测层。抽取首实体短语起止位置的公式如下:
[0057]os
,hs=bert
decoder
(h
λ
,h
t
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(6)
[0058]
o,as=attention(os,hg)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(7)
[0059][0060][0061]
其中,os,hs表示解码后的图注意力网络特征输出与隐向量输出,hg表示经过图注意力网络的上下文特征,w表示权重,b表示偏差,和分别表示抽取的首实体短语的起始位置的概率值,o代表卷积层特征的解码器输出;as代表注意力机制参数。
[0062]
抽取尾实体短语起止位置的公式如下:
[0063][0064]
[0065]
其中,和分别表示抽取的尾实体短语的起止位置的概率值。
[0066]
步骤5.选定关系三元组。根据抽取的关系三元组置信度筛选语料的候选关系三元组集,将置信度大于阈值0.8的关系三元组作为语料的开放域关系三元组抽取结果。
[0067]
参考图2,下面以一个具体的实施例进行说明:
[0068]
给定输入语料s={吕ab博士毕业于cde工业大学,现任部门高级研究员}
[0069]
步骤1.语料信息编码,提取输入语料的特征信息。通过bert预训练模型编码,提取语料的特征向量为[0.50451,0.68607,-0.59517,-0.022801,0.60046,-0.13498,-0.08813,0.47377,-0.61798,-0.31012,-0.076666,1.493,-0.034189,-0.98173,0.68229,0.81722,-0.51874,-0.31503,-0.55809,0.66421,0.1961,-0.13495,-0.11476,-0.30344];
[0070]
步骤2.图注意力网络特征融合。将bert编码输入语料得到的特征向量通过图卷积神经网络得到语料的字符融合特征为[0.41177,-2.223,-1.0756,-1.0783,-0.34354,0.33505,1.9927,-0.04234,-0.64319,0.71125,0.49159,0.16754,0.34344,-0.25663,-0.8523,0.1661,0.40102,1.1685,-1.0137,-0.21585,-0.15155,0.78321,-0.91241,-1.6106,-0.64426,-0.51042];
[0071]
步骤3.关系短语抽取。抽取输入语料可能存在的关系短语,结果为{毕业于,现任,任};
[0072]
步骤4.实体对短语抽取。通过多链路解码,分别抽取关系短语结果集对应的实体对短语,得到输入语料的候选关系三元组集为{(吕ab,毕业于,cde工业大学),(吕ab,现任,部门高级研究员),(吕ab,任,部门高级研究员),(吕ab,任,研究员),(吕ab,毕业于,部门)};
[0073]
步骤5.选定关系三元组。根据置信度筛选输入语料的候选关系三元组集,对于输入语料得到的候选关系三元组集中(吕ab,毕业于,cde工业大学),(吕ab,现任,部门高级研究员),(吕ab,任,部门高级研究员),(吕ab,任,研究员),(吕ab,毕业于,部门)对应的置信度分别为0.82,0.86,0.74,0.48,0.33。选择置信度大于阈值0.8的关系三元组(吕ab,毕业于,cde工业大学),(吕ab,现任,部门高级研究员)作为输入语料的放域关系三元组。
[0074]
需要注意的是,发明中所引用的如“上”、“下”、“左”、“右”、“前”、“后”等的用语,亦仅为便于叙述的明了,而非用以限定本发明可实施的范围,其相对关系的改变或调整,在无实质变更技术内容下,当亦视为本发明可实施的范畴。
[0075]
以上仅是本发明的优选实施方式,本发明的保护范围并不仅局限于上述实施例,凡属于本发明思路下的技术方案均属于本发明的保护范围。应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理前提下的若干改进和润饰,应视为本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1