基于无数据知识蒸馏的文本验证码识别方法
1.本发明涉及一种基于无数据知识蒸馏的文本验证码识别方法,属于机器学习和网络安全技术领域。
背景技术:
2.验证码(completely automated public turing test to tell computers and humans apart,captcha)是设计用于区分计算机与人类用户的安全机制,它被广泛应用于网银登录、账号注册、密码找回等验证环节,以防止网站受到恶意程序的自动攻击。
3.现有验证码机制可以划分为三类:文本验证码、图像验证码和语音验证码,其中文本验证码以其方便快捷的特点被大多数主流网站使用,是当下使用最广泛的验证码机制,目前对于它的识别研究已经成为了一个比较热门的领域。文本验证码由多个随机产生的字符组生成。现阶段虽然有很多文本验证码替代方案,但许多网站和应用程序仍然使用其作为安全和身份验证的主要手段。
4.目前,为了增加计算机程序对文本类验证码自动识别的难度,设计时普遍将复杂干扰信息、字符扭曲、粘连和旋转、不同类型字体等安全性特征随机组合使用,由于组合了多种安全特征,传统的验证码识别方法对此类验证码的识别率非常低。因此在验证码识别领域引入了深度学习卷积神经网络,虽然取得了不错的效果,但如果想要获得更高的识别率,就需要增加卷积神经网络的层数,层数的增多使得卷积神经网络的规模太过于巨大,构建网络也就更加困难,识别起来速度也会很慢,使得识别过程变得复杂;同时由于卷积神经网络需要反向传播的算法,这并不是一个深度学习中的高效算法,因为它对数据量的需求很大,然而当前各大网站的验证码图片收集起来比较困难,即使可以收集下来,为验证码图片打标签也是一件耗时耗力的工作。
技术实现要素:
5.本发明要解决的技术问题是提供一种获取验证码方便、加快文本验证码识别的速率的基于无数据知识蒸馏的文本验证码识别方法。
6.本发明采用如下技术方案:
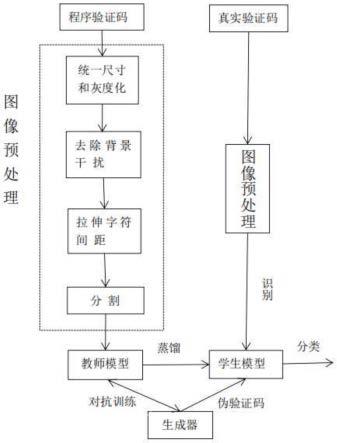
7.本发明基于无数据知识蒸馏的文本验证码识别方法,包括如下步骤:
8.步骤1、构建验证码数据集;
9.1.1)利用python的captcha库生成程序验证码图片作为训练集;
10.1.2)从网站获取真实验证码打好标签作为测试集;
11.步骤2、图像预处理,将步骤1.1得到的程序验证码图片去除会造成识别干扰的信息;
12.2.1)程序验证码图片统一尺寸,灰度化处理;
13.2.2)利用条件生成对抗网络的方法对验证码图片去除背景干扰信息并拉伸字符间距;
14.2.3)将步骤2.2处理好的验证码图片分割为单个字符;
15.步骤3、构建教师模型并使用预处理后的程序验证码训练;
16.步骤4、构建一个生成器,将训练好的教师模型作为鉴别器,生成器与鉴别器对抗生成训练样本,使生成器生成的伪验证码教师模型无法判别;
17.步骤5、初始化一个学生模型,使用步骤4中生成器生成的伪验证码作为训练集,与教师模型的蒸馏损失来共同训练学生模型;
18.步骤6、将步骤1.2中得到的真实验证码预处理之后放入训练好的学生模型识别。
19.本发明步骤4的生成器由三个损失函数构成;具体为
20.①
one-hot loss:在图像分类任务中,对于真实的数据,卷积神经网络最后的输出层的输出接近一个one-hot向量,其中,在分类正确类别上的输出接近1,其它类别的输出接近0;因此,如果生成器生成的图片接近真实数据,那么它在教师网络上的输出应该同样接近于一个one-hot向量;采用如下公式:
[0021][0022]
公式中:h
cross
表示交叉熵损失函数,用于衡量教师模型的输出与预测标签的差异;n表示最终输出图片的数量;
[0023]
将生成器与教师模型分别表示为g和n
t
,给定一组随机向量{z1,z2,
…
,zn},将这些向量生成的图像输入到教师模型n
t
中,得到教师模型n
t
的输出预测标签{t1,t2,
…
,tn}是中的最大值;其中,如果生成器g生成的图像与教师模型的训练数据具有相同的分布,则它们也应该具有与训练数据类似的输出;
[0024]
②
激活损失函数:除了深度神经网络预测的类标签外,卷积层提取的中间特征也是输入图像的重要表示,卷积滤波器提取的特征也包含有价值的输入图像信息;由于教师模型中的过滤器已被训练以提取训练数据中的固有模式,如果输入图像是真实的,而不是一些随机向量,则特征映射往往会收到更高的激活值;则采用activation loss来约束生成数据,采用如下公式:
[0025][0026]
其中‖
·
‖1是传统的l1范数,表示教师模型提取的特征,它对应于全连接层之前的输出;
[0027]
③
生成图像信息熵损失函数:为简化深度神经网络的训练过程,每个类别中的训练示例数通常是平衡的,采用信息熵损失来衡量生成图像的类别平衡,当loss最小时,生成器生成的每个类别的图片的概率大致相等;给定概率向量p=(p1,p2,
…
,pk),测量p的混淆程度的信息熵计算为h
info
(p)的值表示p拥有的信息量,当所有变量都等于时,信息量将取最大值;给定一组输出向量其中每类生成图像的频率分布为则生成图像的信息熵损失定义为:
[0028][0029]
当损失取最小值时,向量中的每个元素都将等于即生成器g可以以大致相同的概率生成每个类别的图像;则最小化生成图像的信息熵可以得到一组平衡的合成图像;
[0030]
综上,适用于生成器的总体损失函数为:
[0031]
l
total
=l
oh
+αla+βl
ie
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(4)
[0032]
通过设置上述三个损失函数训练生成器,使其生成教师模型,判断不出真假的伪验证码。
[0033]
本发明步骤5具体为:
[0034]
s1:将步骤4中生成的伪验证码作为学生模型的训练集,用教师模型在引入温度参数t后产生的softmax输出作为软标签,学生模型在与教师模型相同温度t条件下的softmax输出和教师模型中得到的软标签的交叉熵作为loss函数的第一部分l
soft
,具体公式如下:
[0035][0036]
公式中指教师模型在温度t的条件下softmax输出在第i类上的值,指学生模型在温度t的条件下softmax输出在第i类上的值;
[0037]
s2:学生模型在引入温度参数t的条件下的softmax输出和ground truth的交叉熵损失函数就是loss函数的第二部分l
hard
,其公式如下:
[0038][0039]
公式中,3i指在第i类上的ground truth值,3i∈{0,1},正标签取1,负标签取0。
[0040]
本发明知识蒸馏采用软硬标签加权结合的交叉熵损失函数来训练学生模型,引入参数α之后,总体加权函数形式如下:
[0041]
loss=α*l
soft
+(1-α)*l
hard
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(7)。
[0042]
本发明步骤2.2中,构建两个生成对抗网络,其中用于去除背景干扰信息的网络定义为rbnet,用于拉伸字符间距的网络定义为csnet,这两个网络都使用程序验证码作为样本进行训练;训练rbnet时,其约束条件为含有干扰信息的验证码,监督标签为无干扰信息的验证码,生成器在约束条件的约束下生成无干扰信息的验证码,csnet则是以字符粘连的验证码作为约束条件,以不含粘连字符的验证码作为监督标签,通过生成式模型来生成字符间距较大的验证码,由于csnet对字符间距的有效拉伸,可以消除字符粘连。
[0043]
本发明积极效果如下:本发明通过构建生成器生成大量伪验证码,代替真实验证码训练学生模型,也解决了真实验证码难以大量获取以及打标签所耗费成本过于巨大的问题;知识蒸馏方法的使用本身就可以大大加快文本验证码识别的速率,无数据知识蒸馏更是可以做到不使用真实验证码,这样不仅降低了采集大量真实数据的困难,而且性能也能保持在很高的水平。
[0044]
本发明教师模型学习到的知识去指导学生模型训练,使得学生模型具有与教师模型相当的性能,使参数数量大幅降低,从而实现模型压缩与加速。
附图说明
[0045]
图1是本发明的方法流程图。
具体实施方式
[0046]
下面结合附图和具体实施方式对本发明作进一步详细的说明。
[0047]
如图1所示,基于无数据知识蒸馏的文本验证码识别方法包括如下步骤:
[0048]
步骤1、构建验证码数据集:
[0049]
1.1)利用python的captcha库生成程序验证码作为训练集;
[0050]
1.2)利用爬虫技术从各网站爬取一些真实验证码打好标签作为测试集,本发明爬取了新浪,知网和360等网站的验证码;
[0051]
步骤2、图像预处理,将步骤1.1得到的程序验证码图片去除可能会造成识别干扰的信息;
[0052]
2.1)统一尺寸,灰度化处理;
[0053]
统一尺寸可以通过等比例扩大或缩小至长边达到预设值后,对短边两侧同时使用白色填充的方法进行扩大或缩小;灰度化,采用如下公式:
[0054]
gray=r*0.299+g*0.587+b*0.114
[0055]
将某一像素点三个分量值中的加权值当作灰度图中的像素值,人眼对绿色和蓝色的敏感度最高,因此,b的值是最小的,g的值是最大的;固定的长宽作为超参数方便后续的网络对其训练,然后再进行灰度化处理,减少颜色对网络的影响,提高网络的鲁棒性;
[0056]
2.2)利用条件生成对抗网络的方法对验证码图片去除背景干扰信息并拉伸字符间距,条件生成对抗网络(cgan)的具体实现过程如下:
[0057]
传统的生成式对抗网络(gan)根据随机噪声z来生成图片的方式太自由,缺乏用户控制能力,通过在生成式模型和判别式模型中加入约束条件来解决该问题,即条件生成对抗网络(cgan),其训练时是在生成器g和判别器d中分别加入约束条件y,g(z|y)是指生成式模型在约束条件的约束下生成的数据,和约束条件同时输入判别式模型之后输出条件概率为d(g(z|y)),真实数据x和约束条件y同时输入判别式模型后输出条件概率为d(x|y),
[0058]
cgan的训练过程和gan的训练过程相同,依次固定生成式模型来优化判别式模型,固定判别式模型来优化生成式模型,其优化问题可视为一个带条件概率的最小最大值问题,其整体目标函数可描述为:
[0059][0060]
公式中:g表示为生成式模型,d表示为判别式模型,x表示为输出图像(真实图像),y表示为约束条件,z表示随机噪声,e(
·
)表示计算期望值,r
dta
表示分布函数。真实图像x和约束条件y同时输入判别式模型d后输出条件概率为d(x|y),g(z|y)是指生成式模型在约束条件y的约束下生成的数据,和约束条件同时输入判别式模型之后输出条件概率为d(g(z|y));
[0061]
优化过程中当判别式模型的输入为真实数据x和约束条件y时,判别式模型需使得条件概率d(x|y)趋近于1,当判别式模型的输入为生成数据g(z|y)和约束条件y时,判别式模型需使得条件概率d(g(z|y))趋近于0,此时生成式模型则需要使得条件概率d(g(z|y))
趋近于1,来提高生成效果。
[0062]
本发明采用条件生成对抗网络的方法对验证码图片去除背景干扰信息并拉伸字符间距,其中去除背景干扰信息网络定义为rbnet,拉伸字符间距网络定义为csnet,这两个网络都使用程序验证码作为样本进行训练;训练rbnet时,其约束条件为含有干扰信息的验证码,监督标签为无干扰信息的验证码,生成式模型在约束条件的约束下生成无干扰信息的验证码,csnet则是以字符粘连的验证码作为约束条件,以不含粘连字符的验证码作为监督标签,通过生成式模型来生成字符间距较大的验证码,由于csnet对字符间距的有效拉伸,基本可以消除字符粘连的问题。
[0063]
2.3)将步骤2.2中处理好的验证码图片进行分割,分割为单个字符;
[0064]
对处理后的图像进行二值化处理,即将图像由灰度模式转化至黑白模式,选择二值化的阈值为200;在二值化处理后的图片中提取单个字符,利用opencv中的最小外接矩形函数来提取,对提取后的字符图片要有一定要求,如图片的大小要超过100,否则可能会得到其他不想要的图片;
[0065]
步骤3、构建教师模型并使用预处理后的程序验证码训练;
[0066]
教师模型的选择,主要考虑的参数为模型对于验证码的识别准确率,与其他传统卷积神经网络模型相比,resnet-34网络模型的分类效果最佳,因而本发明教师模型采用resnet-34网络模型;
[0067]
本发明教师模型所用的训练数据来自python的captcha库生成的程序验证码预处理之后的单个字符图片,为了提高机器学习的效率,需要构建队列模式来减少机器读取数据的等待时间;tensorflow提供了tfrecord格式文件,结合队列模式能够方便数据的读取操作;将处理好的验证码图片转换成tfrecord格式文件;将每1000张图片制作成一个tfrecord文件,图片的像素矩阵和图片的标签都做成了二进制的数据流,存入tfrecord文件中;采用线程来管理队列,每20步输出一次loss值,每100步输出一次准确率,每20000步保存一次模型,batchsize设为2,按照整个流程训练了14万步停止;
[0068]
步骤4、构建生成器并训练;
[0069]
在生成对抗网络中,鉴别器d可以从样本中学习表示的层次结构,这有助于鉴别器d在图像分类等其他任务中的泛化。由于深度神经网络已经在大规模数据集上进行了良好的训练,因此它也可以从图像中提取语义特征,而不是像一般的生成对抗网络那样训练一个新的鉴别器。本发明将给定的训练好的深度神经网络视为一个固定的鉴别器,直接构建并优化一个生成器g,而无需同时训练鉴别器d,即在训练生成器g期间,鉴别器d的参数是固定的,此外,由于鉴别器的输出是一个概率,指示输入图像是真是假,然而,一般的深度神经网络作为鉴别器,其输出是将图像分类为不同的类别,而不是指示图像的真实性,一般生成对抗网络中的损失函数不适用于此网络中生成器的训练。
[0070]
因此,本发明将预训练好的教师模型作为鉴别器,引入三个新的损失函数来构造一个生成器,使其与鉴别器对抗生成训练样本,下面是训练生成器的三个损失函数:
[0071]
①
one-hot loss:在图像分类任务中,对于真实的数据,网络的输出往往接近一个one-hot向量,其中,在分类正确类别上的输出接近1,其它类别的输出接近0。因此,如果生成器生成的图片接近真实数据,那么它在教师网络上的输出应该同样接近于一个one-hot向量;采用如下公式:
[0072][0073]
公式中:h
cross
表示交叉熵损失函数,用于衡量教师模型的输出与预测标签的差异;n表示最终输出图片的数量;
[0074]
将生成器与教师模型分别表示为g和n
t
,给定一组随机向量{z1,z2,
…
,zn},将这些向量生成的图像输入到教师模型h
t
中,得到教师模型n
t
的输出预测标签ti={t1,t2,
…
,tn}是中的最大值;其中,如果生成器g生成的图像与教师模型的训练数据具有相同的分布,则它们也应该具有与训练数据类似的输出;
[0075]
②
激活损失函数:除了深度神经网络预测的类标签外,卷积层提取的中间特征也是输入图像的重要表示。卷积滤波器提取的特征也包含有价值的输入图像信息。由于教师模型中的过滤器已被训练以提取训练数据中的固有模式,如果输入图像是真实的,而不是一些随机向量,则特征映射往往会收到更高的激活值。因此可以采用activation loss来约束生成数据:
[0076][0077]
其中‖
·
‖1是传统的l1范数,将教师模型提取的特征表示为它对应于全连接层之前的输出;
[0078]
③
生成图像信息熵损失函数:为了简化深度神经网络的训练过程,每个类别中的训练示例数通常是平衡的,本发明使用信息熵损失来衡量生成图像的类别平衡,当loss最小时,生成器生成的每个类别的图片的概率大致相等;给定概率向量p=(p1,p2,
…
,pk),测量p的混淆程度的信息熵计算为h
info
(p)的值表示p拥有的信息量,当所有变量都等于时,信息量将取最大值;给定一组输出向量其中每类生成图像的频率分布为因此,生成图像的信息熵损失定义为
[0079][0080]
当损失取最小值时,向量中的每个元素都将等于即生成器g可以以大致相同的概率生成每个类别的图像;因此,最小化生成图像的信息熵可以得到一组平衡的合成图像;
[0081]
因此,适用于生成器的总体损失函数为:
[0082]
l
total
=l
oh
+αla+βl
ie
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(4)
[0083]
通过设置上述三个损失函数训练生成器,使其生成教师模型(鉴别器)判断不出真假的伪验证码;
[0084]
步骤5、初始化一个学生模型,本发明使用了resnet-18网络模型,使用步骤4中生成器生成的伪验证码作为训练集,加上教师模型的蒸馏损失来共同训练学生模型具体操作如下:
[0085]
s1:将步骤4中生成的伪验证码作为学生模型的训练集,用教师模型在引入温度参数t后的softmax输出作为软标签,学生模型在与教师模型相同温度t条件下的softmax输出和教师模型中得到的软标签的交叉熵作为loss函数的第一部分l
soft
,具体形式如下:
[0086][0087]
其中指教师模型在温度t的条件下softmax输出在第i类上的值。指学生模型在温度t的条件下softmax输出在第i类上的值。
[0088]
s2:学生模型在不引入温度参数t的条件下的softmax输出和ground truth的交叉熵损失函数就是loss函数的第二部分l
hard
,公式如下:
[0089][0090]
其中,ci指在第i类上的ground truth值,ci∈{0,1},正标签取1,负标签取0;
[0091]
综上,教师模型与学生模型蒸馏损失函数包括两部分:
[0092]
①
l
soft
:学生模型软化后的softmax输出值(t取2)与教师模型生成的软标签之间的损失(kl散度);
[0093]
②
l
hard
:学生模型不引入温度参数t的softmax输出值与真实标签的之间的损失(交叉熵);
[0094]
使用软标签是为了更好的让模型学习数据的分布,知识蒸馏的方式不是传统的多个模型求均值,而是采用软硬标签加权结合的交叉熵损失函数来训练小型模型;总体加权函数形式如下:
[0095]
loss=α*l
soft
+(1-α)*l
hard
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(7)
[0096]
本发明所述教师模型的蒸馏损失:对于一般的分类问题如图片分类,输入一张图片后,经过神经网络各种非线性变换,在网络最后的softmax层之前,会得到这张图片属于各个类别的大小数值zi,某个类别的zi数值越大,则模型认为输入图片属于这个类别的可能性就越大,logits就是汇总了网络内部各种信息之后,得出的属于各个类别的汇总分值zi,但是logits不是概率值,因此神经网络使用softmax层来实现logits向probabilities的转换;原始的softmax函数:
[0097][0098]
但是直接使用softmax层的输出值作为软标签,这又会带来一个问题:当softmax输出的概率分布熵相对较小时,负标签的值都很接近0,对损失函数的贡献非常小,小到可以忽略不计;因此“温度”这个变量就派上了用场;下述公式是加了温度这个变量之后的softmax函数:
[0099][0100]
其中qi是每个类别输出的概率,zi是每个类别输出的logits,t就是温度。当温度t=1时,这就是标准的softmax公式。t越高,softmax的output probability distribution越趋于平滑,其分布的熵越大,负标签携带的信息会被相对地放大,模型训练将更加关注负标签;
[0101]
步骤6、将步骤1.2中得到的真实验证码预处理之后放入训练好的学生模型识别;将步骤1爬取到的验证码先进行图像预处理,处理完之后放入训练好的学生模型中进行预测分类即可。
[0102]
如下为采用本发明方法的具体实施例:
[0103]
步骤1、构建验证码数据集:
[0104]
1.1)利用python的captcha库生成程序验证码作为训练集,部分训练集如下:
[0105][0106]
1.2)从知网网站上爬取了500张真实验证码打好标签作为测试集,部分测试集如下:
[0107][0108]
步骤2、图像预处理,将步骤1.1得到的程序验证码图片去除可能会造成识别干扰的信息;
[0109]
2.1)统一尺寸,灰度化处理;
[0110]
统一尺寸可以通过等比例扩大或缩小至长边达到预设值后,对短边两侧同时使用白色填充的方法进行扩大或缩小,灰度化;
[0111]
2.2)利用条件生成对抗网络的方法对验证码图片去除背景干扰信息并拉伸字符间距:
[0112]
cgan的训练过程和gan的训练过程相同,依次固定生成式模型来优化判别式模型,固定判别式模型来优化生成式模型,其优化问题可视为一个带条件概率的最小最大值问题,其整体目标函数采用如下公式所示:
[0113][0114]
本实施例采用条件生成对抗网络的方法对验证码图片去除背景干扰信息并拉伸字符间距,其中去除背景干扰信息网络定义为rbnet,拉伸字符间距网络定义为csnet,这两个网络都使用程序验证码作为样本进行训练;
[0115]
2.2.1)训练rbnet时,其约束条件为含有干扰信息的验证码,监督标签为无干扰信息的验证码,生成式模型在约束条件的约束下生成无干扰信息的验证码;
[0116]
2.2.2)csnet则是以字符粘连的验证码作为约束条件,以不含粘连字符的验证码作为监督标签,通过生成式模型来生成字符间距较大的验证码;
[0117]
2.3)对处理后的图像进行二值化处理,即将图像由灰度模式转化至黑白模式,选择二值化的阈值为200;在二值化处理后的图片中提取单个字符,利用opencv中的最小外接矩形函数来提取,对提取后的字符图片要有一定要求,如图片的大小要超过100,否则可能会得到其他不想要的图片;
[0118]
步骤3、构建教师模型并使用预处理后的程序验证码训练;
[0119]
本实施例教师模型采用resnet-34网络模型;教师模型所用的训练数据来自python的captcha库生成的程序验证码预处理之后的单个字符图片,为了提高机器学习的效率,需要构建队列模式来减少机器读取数据的等待时间;tensorflow提供了tfrecord格
式文件,结合队列模式能够方便数据的读取操作;将处理好的验证码图片转换成tfrecord格式文件;将每1000张图片制作成一个tfrecord文件,图片的像素矩阵和图片的标签都做成了二进制的数据流,存入tfrecord文件中;采用线程来管理队列,每20步输出一次loss值,每100步输出一次准确率,每20000步保存一次模型,batchsize设为2,按照整个流程训练了14万步停止;
[0120]
步骤4、构建生成器并训练;
[0121]
本实施例将预训练好的教师模型作为鉴别器,引入三个新的损失函数来构造一个生成器,使其与鉴别器对抗生成训练样本,下面是训练生成器的三个损失函数:
[0122]
①
one-hot loss:在图像分类任务中,对于真实的数据,网络的输出往往接近一个one-hot向量,其中,在分类正确类别上的输出接近1,其它类别的输出接近0;因此,如果生成器生成的图片接近真实数据,那么它在教师网络上的输出应该同样接近于一个one-hot向量;采用如下公式:
[0123][0124]
公式中:h
cross
表示交叉熵损失函数,用于衡量教师模型的输出与预测标签的差异;n表示最终输出图片的数量;
[0125]
将生成器与教师模型分别表示为g和n
t
,给定一组随机向量{z1,z2,
…
,zn},将这些向量生成的图像输入到教师模型n
t
中,得到教师模型n
t
的输出预测标签是中的最大值;其中,如果生成器g生成的图像与教师模型的训练数据具有相同的分布,则它们也应该具有与训练数据类似的输出;
[0126]
②
激活损失函数:除了深度神经网络预测的类标签外,卷积层提取的中间特征也是输入图像的重要表示。卷积滤波器提取的特征也包含有价值的输入图像信息;由于教师模型中的过滤器已被训练以提取训练数据中的固有模式,如果输入图像是真实的,而不是一些随机向量,则特征映射往往会收到更高的激活值;因此可以采用activation loss来约束生成数据:
[0127][0128]
其中‖
·
‖1是传统的l1范数,将教师模型提取的特征表示为它对应于全连接层之前的输出。
[0129]
③
生成图像信息熵损失函数:为了简化深度神经网络的训练过程,每个类别中的训练示例数通常是平衡的,本实施例使用信息熵损失来衡量生成图像的类别平衡,当loss最小时,生成器生成的每个类别的图片的概率大致相等;给定概率向量p=(p1,p2,
…
,pk),测量p的混淆程度的信息熵计算为h
info
(p)的值表示p拥有的信息量,当所有变量都等于时,信息量将取最大值。给定一组输出向量其中每类生成图像的频率分布为因此,生成图像的信息熵损失定义为
[0130][0131]
当损失取最小值时,向量中的每个元素都将等于即生成器g可以以大致相同的概率生成每个类别的图像。因此,最小化生成图像的信息熵可以得到一组平衡的合成图像。
[0132]
因此,适用于生成器的总体损失函数为:
[0133]
l
total
=l
oh
+αla+βl
ie
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(4)
[0134]
通过设置上述三个损失函数训练生成器,使其生成教师模型(鉴别器)判断不出真假的伪验证码。
[0135]
步骤5、初始化一个学生模型,本实施例使用了resnet-18网络模型,使用步骤4中生成器生成的伪验证码作为训练集,加上教师模型的蒸馏损失来共同训练学生模型具体操作如下:
[0136]
s1:将步骤4中生成的伪验证码作为学生模型的训练集,用教师模型在引入温度参数t后的softmax输出作为软标签,学生模型在与教师模型相同温度t条件下的softmax输出和教师模型中得到的软标签的交叉熵作为loss函数的第一部分l
soft
,具体形式如下:
[0137][0138]
其中指教师模型在温度t的条件下softmax输出在第i类上的值,指学生模型在温度t的条件下softmax输出在第i类上的值;
[0139]
s2:学生模型在不引入温度参数t的条件下的softmax输出和ground truth的交叉熵损失函数就是loss函数的第二部分l
hard
,公式如下:
[0140][0141]
其中,ci指在第i类上的ground truth值,ci∈{0,1},正标签取1,负标签取0;
[0142]
综上,教师模型与学生模型蒸馏损失函数包括两部分:
[0143]
①
l
soft
:学生模型软化后的softmax输出值(t=2)与教师模型生成的软标签之间的损失(kl散度);
[0144]
②
l
hard
:学生模型不引入温度参数t(t=1)的softmax输出值与真实标签的之间的损失(交叉熵);
[0145]
总体加权函数形式如下:
[0146]
loss=0.1*l
hard
+0.9*l
soft
[0147]
步骤6、将步骤1.2中得到的知网验证码先进行图像预处理,再放入训练好的学生模型resnet-18中识别即可。
[0148]
本发明利用知识蒸馏实现模型压缩,一方面压缩了模型,另一方面增强了模型的泛化能力,同时构建生成器生成的大量伪验证码,代替了真实验证码来训练学生模型,解决了真实验证码难以大量获取以及打标签所耗费成本大的问题。
[0149]
本发明使用教师模型预测的软标签来辅助硬标签训练学生模型的方式之所以有效,是因为softmax层的输出,除了正例之外,负标签也带有教师模型归纳推理的大量信息,比如某些负标签对应的概率远远大于其他负标签,则代表教师模型在推理时认为该样本与
该负标签有一定的相似性;而在传统的训练过程中,所有负标签都被统一对待;也就是说,知识蒸馏的训练方式使得每个样本给学生模型带来的信息量大于传统的训练方式。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1