一种语音驱动的人脸动画生成方法及系统
1.本发明属于人工智能虚拟人脸应用技术领域,尤其涉及一种语音驱动的人脸动画生成方法及系统。
背景技术:
2.语音驱动人脸动画生成旨在根据输入的语音信息和人脸形象生成具有流畅、自然、唇音同步的人脸动画。它在虚拟主播、虚拟客服、在线教育、电影特效、游戏娱乐等众多领域都有着广阔的应用前景。一个高质量、高真实感、唇音同步的人脸动画可以很好地增强使用者的认同感与体验感。
3.近年来,随着深度学习技术的不断发展,各种卷积神经网络、对抗生成网络等模型被提出并得到广泛应用,使得人脸动画生成技术开始有了新的研究方向,采用学习机制使训练后的人脸模型具有良好的口型表现效果。
4.当前技术手段主要归纳为两种,即基于中间特征的人脸动画生成以及端到端的语音同步人脸动画生成。
5.(1)基于中间特征的人脸动画生成由音频特征得到唇部关键点,将其作为中间特征指导人脸图像,以获得唇音同步的人脸动画。suwajanakorn等人(2017)利用深度学习方法从语音中获取唇部运动信息作为中间特征,再利用传统计算机视觉处理方法合成面部纹理并生成人脸动画。他们的方法虽然能够生成同步较强的人脸动画,但是合成的唇部纹理边缘区域存在模糊、遮挡情况,图像帧质量也有待提高。此外,该方法针对特定对象开展研究,模型对目标对象不具备泛化能力。kumar等人(2017)在suwajanakorn等人研究工作的基础上,提出了一种obamanet模型。它利用预测得到的唇部运动信息对人脸图像进行遮罩处理,再通过图像转换模型pix2pix将遮罩图像转换为人脸动画图像帧。虽然该方法使用可训练的神经网络模块代替传统的计算机视觉办法,能够在一定程度上提高人脸动画的生成效率,但是生成的人脸图像唇部边缘仍然较为模糊,对目标对象泛化能力也十分有限。
6.(2)端到端的语音同步人脸动画生成则直接将音频特征和人脸图像输入到同一神经网络模块中进行训练来生成人脸动画。vougioukas等人(2018)使用生成对抗网络建立从音频到人脸动画的映射。他们提出的生成对抗网络模型包括一个生成器和三个判别器。其中,生成器为编解码器,用于接收音频和人脸图像作为输入,生成人脸动画图像帧;判别器由帧判别器、序列判别器和同步判别器组成,用于指导人脸面部重建、图像帧间流畅以及唇音同步。虽然该方法能够得到唇音同步性较好的人脸动画,也具有一定的泛化能力,但是仅使用一张人脸图像生成人脸动画,人物仍缺乏自然的口型运动,真实感不足。vougioukas等人(2020)后续在动画中添加了人物眨眼动作,但仅凭借眨眼这一项面部运动仍不足以体现人脸动画的真实感。chung等人(2016)曾提出了唇音同步判别网络syncnet。它通过判断音频和人脸图像在某个共同参数空间下的相似性,计算该共同空间参数下音频特征与人脸图像特征的交叉熵损失以反映唇音同步效果。针对vougioukas等人(2018)生成的人脸动画中人物缺乏自然面部运动的不足之处,prajwal等人在chung等人研究工作的基础上,进一步
提出了基于生成对抗网络的lipgan(2019)及其改进模型wav2lip(2020)。不同于vougioukas等人使用单张人脸图像,wav2lip模型接收图像帧序列作为输入,在保留原始帧序列人物面部运动信息的同时,通过音频特征指导唇部运动的变化来生成人脸动画。该模型能够生成具有自然头部运动、唇音同步效果良好的人脸动画,但该模型仍存在生成的人脸图像帧不够清晰、图像帧质量有待提高的问题。
7.综述当前语音驱动人脸动画生成技术研究现状,仍存在着唇音同步效果一般、人脸动画图像帧质量有待提高、人脸模型泛化能力较弱、人脸动画中人物缺乏自然的头部运动等主要问题。如何在控制人脸唇型和面部运动的同时保持局部细节,生成具有真实感的唇音同步的人脸依然面临着很大的技术挑战。
技术实现要素:
8.针对现有技术难题,本发明提出一种新的语音驱动的人脸动画生成方案,根据给定音频与人脸形象的图像或视频生成以人物形象为说话主体并且音频同步的人脸动画。生成的人脸动画具有良好表现,满足:(1)良好的唇音同步效果;(2)高质量的人脸动画图像帧;(3)人脸动画生成模型具有泛化能力;(4)生成的人脸动画中人物具有自然头部运动。
9.为了达到这个目的,本发明提供的一种语音驱动的人脸动画生成方法,包括通过以下步骤进行人脸动画自动生成,
10.步骤s1,人脸关键点提取及标准化,其中人脸关键点标准化处理包括以唇部为主要参照,利用眼睛与嘴唇的位置关系,对人脸关键点进行几何位置纠正;
11.步骤s2,从音频特征中预测唇部关键点,包括音频特征提取、数据预处理、唇部关键点预测模型audio2mkp建模与训练,以及唇部关键点预测模型audio2mkp参数优化;所述唇部关键点预测模型audio2mkp是实现从语音到唇部关键点的映射的模型;
12.步骤s3,基于唇部关键点的参照图像生成,包括遮罩图像生成、人脸区域划分、人脸转换生成对抗网络模型ftgan建模与训练,以及人脸转换生成对抗网络模型ftgan参数优化;所述人脸转换生成对抗网络模型ftgan是实现将人脸遮罩图像转换为人脸参照图像的模型;
13.步骤s4,在步骤s3获得的参照图像基础上,并利用步骤s2获得的音频特征来指导人脸动画的生成,包括语音到人脸生成对抗网络a2fgan建模与训练、语音到人脸生成对抗网络a2fgan参数优化,以及人脸动画合成;所述语音到人脸生成对抗网络a2fgan是实现获得唇音同步效果的人脸动画的模型。
14.而且,进行人脸关键点提取时,首先对人脸图像的面部关键部位进行定位,包括眉毛、眼睛、鼻子、嘴唇以及脸部外轮廓,并确定基本的人脸关键点。
15.而且,步骤s2中,基于卷积神经网络实现唇部关键点预测模型audio2mkp,由语音信息获取准确的唇部关键点坐标,实现方式包括以下步骤,
16.1)audio2mkp建模,包括基于卷积神经网络实现唇部关键点预测模型audio2mkp,实现从语音到唇部关键点的映射;所述唇部关键点预测模型audio2mkp包括依次连接的若干卷积层和若干全连接层,部分卷积层中分别添加来自上一个卷积层的残差连接,形成残差块;
17.2)audio2mkp训练,包括接收输入的音频特征,对唇部关键点预测模型audio2mkp
进行训练,并通过反向传播优化模型参数,获得准确的预测唇部关键点。
18.而且,步骤s3中进行遮罩图像生成时,采取唇部区域往外延伸的方式来确定遮罩区域的大小。
19.而且,步骤s3中进行人脸区域划分时,人脸图像按照从高到低重要程度划分为不同区域,包括唇部区域、人脸区域以及背景区域;同时,为每个区域设置权重,唇部区域的权重大于人脸区域,人脸区域的权重大于背景区域。
20.而且,步骤s3中,基于生成对抗网络的架构改进建立人脸转换生成对抗网络模型ftgan,将人脸遮罩图像转换为人脸参照图像,实现方式包括以下步骤,
21.1)ftgan建模,包括基于所述人脸转换生成对抗网络模型ftgan实现将预测唇部关键点得到的遮罩图像转换为人脸参照图像;所述人脸转换生成对抗网络模型ftgan由一个生成器网络和一个判别器网络组成,所述生成器网络接收输入的遮罩图像产生输出人脸参照图像,其中stn模块、人脸编码器模块、cbam模块和人脸编码器模块依次连接;判别器网络中包括帧判别器模块,生成器网络生成的参照图像以及对应的真值图像一起输入到帧判别器模块,计算生成标签与真值标签之间均方误差以评价生成图像优劣;
22.2)ftgan训练,接收输入的遮罩图像,对人脸转换生成对抗网络模型ftgan进行训练,通过反向传播优化模型参数,获得高质量的人脸参照图像。
23.而且,步骤s4中,基于生成对抗网络的架构改进建立提出语音到人脸生成对抗网络a2fgan,以获得人脸动画的唇音同步效果,实现方式包括以下步骤,
24.1)a2fgan建模,包括基于语音到人脸生成对抗网络a2fgan在参照图像基础上利用语音信息指导人脸动画生成;所述语音到人脸生成对抗网络a2fgan包括一个生成器网络和两个判别器网络,所述生成器网络由人脸编、解码器模块、stn模块以及cbam模块组成,两个判别器网络分别由帧判别器模块与唇音同步判别器模块组成;
25.2)a2fgan训练,接收输入的音频特征以及参照图像,对语音到人脸生成对抗网络a2fgan进行训练,通过反向传播优化模型参数,获得唇音同步的人脸动画图像帧。
26.而且,a2fgan的判别器训练时,首先单独训练唇音同步判别器模块,然后根据训练好的唇音同步的人脸动画图像,训练帧判别器模块,最终得到唇音同步且保持真值图像效果的人脸动画图像帧。
27.另一方面,本发明还提供一种语音驱动的人脸动画生成系统,用于实现如上所述的一种语音驱动的人脸动画生成方法。
28.而且,包括处理器和存储器,存储器用于存储程序指令,处理器用于调用存储器中的存储指令执行如上所述的一种语音驱动的人脸动画生成方法。
29.本发明具有如下特点和有益效果:
30.1、为了实现由语音信息获得准确的唇部关键点坐标,提出基于卷积神经网络(cnn)的唇部关键点预测模型audio2mkp。解决早期图像处理方法获取唇部关键点计算工作量大、自动程度不高的问题。同时,相比于基于长短期记忆网络(lstm)的方法,该模型预测的唇部关键点与真值的唇部关键点之间的误差将更小,从而用该模型预测唇部关键点更准确。
31.2、为了提高人脸动画图像帧质量,提出人脸转换生成对抗网络ftgan,将人脸遮罩图像转换为人脸参照图像。考虑到人脸相对于图像大小与位置的不确定性,在ftgan的生成
器中引入stn模块与cbam模块的组合来提高参照图像的生成质量,且不需要增加额外开销;ftgan的判别器则利用多尺度判别器(patchgan)更好地指导生成器输出参照图像。同时,考虑到人脸图像中不同部位所在区域的重要性不同,引入注意力机制模块,设计基于人脸区域划分的图像重建损失函数。因此,所设计的该模型能够最大程度地确保生成高质量的人脸参照图像。
32.3、提出语音到人脸生成对抗网络a2fgan,利用syncnet网络判断唇音同步的优势,在a2fgan的判别器中引入唇音同步判别器。同时,该模型在参照图像基础上利用语音信息指导人脸动画生成,进一步提高人脸动画的唇音同步效果。
33.4、针对人脸形象以单张图像形式给出时容易导致生成的人脸动画中人物缺乏自然的头部运动的问题,利用人脸姿态迁移模型few_shot_vid2vid,提出一种基于中间人脸过渡的解决方案,将中间人物的人脸动画迁移至人物形象上。该方案可保证以单张图像生成的人脸动画中人物具有自然的头部运动,生成具有泛化能力的人脸动画。
34.概括起来,本发明所提出的语音驱动的人脸动画生成方案能够自动生成具有高质量图像帧、良好唇音同步效果、自然头部运动的人脸动画,并且人脸动画生成模型具有泛化能力。它在虚拟主播、虚拟客服、在线教育、电影特效、游戏娱乐等众多领域都有着广阔的应用前景,具有重要的市场价值。
附图说明
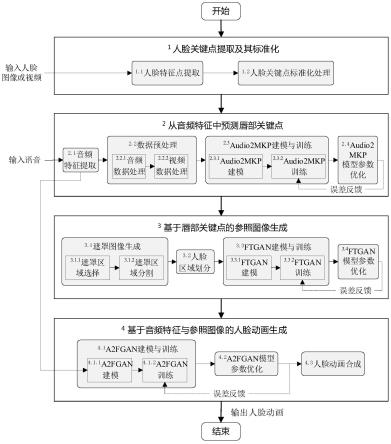
35.图1是本发明实施例的语音驱动的人脸动画生成流程图;
36.图2是本发明实施例的人脸关键点示意图,其中图2(a)部分为人脸关键部位定位示意图,图2(b)部分为人脸关键点示意图;
37.图3是本发明实施例的唇部关键点预测模型audio2mkp;
38.图4是本发明实施例的几种不合适的遮罩区域处理方式示意图,其中图4(a)部分为覆盖整个人脸图像下半区域示意图,图4(b)部分为覆盖人脸下半区域示意图,图4(c)部分为仅覆盖唇部区域示意图;
39.图5是本发明实施例的预测唇部关键点存在误差示意图,其中图5(a)部分为原始图像的遮罩区域示意图,图5(b)部分为真实与预测存在误差示意图;
40.图6是本发明实施例的遮罩区域选择示意图,其中图6(a)部分为原始图像示意图,图6(b)部分为遮罩区域选择示意图;
41.图7是本发明实施例的遮罩区域分割处理示意图,其中图7(a)部分为原始图像示意图,图7(b)部分为分割后的遮罩区域示意图;
42.图8是本发明实施例的人脸区域划分示意图;
43.图9是本发明实施例的人脸转换生成对抗网络ftgan;
44.图10是本发明实施例的stn模块网络结构;
45.图11是本发明实施例的cbam模块的网络结构;
46.图12是本发明实施例的语音到人脸生成对抗网络a2fgan;
47.图13是本发明实施例的唇音同步判别网络。
具体实施方式
48.以下结合附图和实施例对本发明技术方案进行具体地描述。
49.本发明根据给定音频与人脸图像或视频生成以该人脸形象为说话主体并且与音频同步的人脸动画,包括人脸关键点提取及其标准化、从音频特征中预测唇部关键点、基于唇部关键点的参照图像生成、基于音频特征与参照图像的人脸动画生成。本发明提供一套完整的人脸动画制作步骤,生成的人脸动画满足:(1)良好的唇音同步效果;(2)高质量的人脸动画图像帧;(3)人脸动画生成模型具有泛化能力;(4)生成的人脸动画中人物具有自然头部运动。
50.如图1所示,本发明实施例提供的语音驱动的人脸动画生成方法,包括步骤如下:步骤1人脸关键点提取及其标准化
51.人脸特征点提取是人脸动画生成的基础,这些特征点位置的准确性将直接影响到后续步骤唇部区域处理以及人脸动画生成的效果。本步骤根据输入的人脸图像或视频对人脸关键点进行提取,并对它们进行标准化处理,实施例中进一步提出具体涉及步骤1.1和步骤1.2。
52.步骤1.1人脸关键点提取
53.后续对唇部关键点预测模型进行训练需要获取与音频对应的唇部关键点数据。因此,首先对人脸图像的面部关键部位进行定位,包括眉毛、眼睛、鼻子、嘴唇以及脸部外轮廓,并确定人脸基本关键点。参见图2所示提取的人脸关键点示意图。具体实施时可以使用一些人脸识别工具,例如人脸识别开源库dlib等,对图2(a)所示人脸图像的人脸关键部位进行定位,提取68个人脸关键点,其中唇部关键点为20个(如图2b所示)。人脸的第1个关键点一般为脸部外轮廓的左上方的点。如图2(b)所示依次对各个关键点进行编号,得到唇部的第一个关键点为编号49。
54.步骤1.2人脸关键点标准化处理
55.在人脸图像帧中人脸相对于整个图像的位置、大小和旋转角度不一样。因此,对步骤1.1所获得的人脸关键点进行标准化处理。以唇部为主要参照,利用眼睛与嘴唇的位置关系,对人脸关键点进行几何位置纠正,消除人脸在整个图像中发生倾斜角度偏差的影响,以确保人脸位置的不变形。
56.步骤2从音频特征中预测唇部关键点
57.本步骤根据输入的原始语音,从中提取语音的音频特征,数据预处理后将其向量化表示,并通过建立唇部关键点预测模型并训练,由音频特征准确地预测唇部关键点坐标。实施例中进一步提出具体涉及步骤2.1~步骤2.4。
58.步骤2.1音频特征提取
59.从原始语音中提取语音的音频特征。具体实施时,可利用一些语音识别系统来提取音频特征,如deepspeech等。deepspeech是一个开源的、基于深度学习框架、可实现端到端的自动语音识别功能的语音识别系统。本发明实施例优选采用deepspeech语音识别系统,对输入语音进行快速傅里叶变换,将时域信号转化为频域信号;同时,在时域和频域所组成的二维空间上获得每个音频片段的特征向量;再对获取的特征向量进行加窗处理得到音频特征。提取的音频特征为29维。在本发明实施例中将利用deepspeech提取的音频特征定义为dsaudio_features以便后续表述。
60.需要说明的是,当前深度学习技术已经可以做到从原始音频中自动地提取音频特征。因此,本发明实施例优选提取dsaudio_features音频特征来代替提取传统的mfcc特征参数。
61.步骤2.2数据预处理
62.数据预处理分别对音频数据和视频数据进行处理,实施例中进一步提出具体涉及步骤2.2.1和步骤2.2.2。
63.步骤2.2.1音频数据处理
64.具体实施时,可以利用多媒体视频处理工具,例如ffmpeg等,对原始语音进行预处理,将它们统一转换为采样率为16,000hz的单声道语音数据。本发明进一步提出,在获取dsaudio_features音频特征的基础上,增加1个音频特征的维度以符合后期卷积神经网络的卷积层运算对数据格式的要求。经过数据预处理后,每秒语音数据可表示为1个音频特征向量,优选建议的统一格式为(音频帧数,维度,加窗处理的窗口大小,音频特征向量大小),例如(n,1,16,29),其中n为音频帧数。
65.步骤2.2.2视频数据处理
66.具体实施时,可以利用多媒体视频处理工具,例如ffmpeg等,以25帧/秒的速率提取人脸图像帧。在步骤1提取人脸关键点的基础上,使用主成分分析(principal component analysis,pca)方法,对每帧人脸图像的20个唇部关键点进行降维处理,用一定数量的pca主成分来表示20个唇部关键点。经过数据预处理后,每秒视频数据可表示为1个唇部关键点特征向量,统一格式为(视频帧数,pca主成分数),例如(25,8)。
67.步骤2.3唇部关键点预测模型audio2mkp建模与训练
68.本发明实施例提出构建基于卷积神经网络的唇部关键点预测模型(audio to mouth key points,audio2mkp),实现从语音到唇部关键点的映射。它接收输入的dsaudio_features音频特征,结合后续步骤2.4对audio2mkp模型进行反复训练,最终获得预测准确的唇部关键点。它涉及步骤2.3.1和步骤2.3.2。
69.步骤2.3.1audio2mkp建模
70.早期图像处理方法获取唇部关键点计算工作量大、自动程度不高;而基于长短期记忆网络(long short-term memory,lstm)的方法获得的唇部关键点精度不高。卷积神经网络(cnn)是一种专门用来处理具有类似网格结构数据的神经网络,它能够捕获图像的局部性质,在图像识别中具有良好表现。本发明基于cnn来设计audio2mkp模型。
71.audio2mkp模型的网络结构如图3所示,包括依次连接的若干卷积层和若干全连接层,部分卷积层中分别添加来自上一个卷积层的残差连接,形成残差块。
72.实施例中优选包含12个卷积层(conv,依次记为conv-1至conv-12)以及2个全连接层(linear,依次记为linear-1、linear-2)来学习dsaudio_features音频特征到唇部关键点的映射。
73.在该模型中,卷积层使用大小统一的3
×3×
3卷积核,每个卷积层包含向量卷积运算,并且音频特征的特征图在进入下一个卷积层之前使用relu函数进行激活。该函数由式(2)进行定义。
74.relu(x)=max(0,x)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(2)
75.其中,x为音频特征的特征图。
76.部分卷积层(如图中conv-2、conv-3、conv-5、conv-6、conv-8、conv-9、conv-12)中分别添加来自上一个卷积层的残差连接,形成残差块(参见图3中点划线箭头所形成的7个残差块),以减少随着网络深度的增加出现训练错误的问题。每个残差块将输入与经过卷积层的输出相加之后再进行激活。以conv-1与conv-2之间的连接为例。将conv-2的输入(即conv-1经过激活的输出)直接与conv-2卷积结果加在一起,然后再激活。其他类似情况同理。每一个形状为(1,16,29)的音频特征向量经过12个卷积层处理后得到形状为(256,1,1)的特征图,进一步通过重塑(reshape)对该特征图进行降维处理得到一维的包含256个特征值的列向量。
77.卷积层通过reshape连接到全连接层。全连接层1(linear-1)提取包含64个特征值的列向量,进行正则化(batchnorm)操作,通过全连接层2(linear-2)得到表示唇部关键点的8个特征值。再经过pca复原以及逆向标准化操作可得到预测的20个唇部关键点坐标。这里,pca复原时可调用python中的sklearn.inverse_transform()方法对数据进行复原。逆向标准化将pca复原后的二维矩阵乘以标准化处理时记录的二范数,再加上唇部中心坐标,可得到逆标准化之后的唇部关键点坐标。
78.步骤2.3.2audio2mkp训练
79.如图3所示,将dsaudio_features音频特征输入audio2mkp模型中,结合步骤2.4对audio2mkp模型进行训练,得到预测的唇部关键点特征向量表示。
80.步骤2.4audio2mkp模型参数优化
81.计算预测的唇部关键点特征表示与真值的唇部关键点特征表示之间的均方根误差(root mean square error,rmse),以评估预测的唇部关键点的准确度,表示为loss
rmse
,由式(1)进行计算。
[0082][0083]
其中,n表示唇部关键点的个数,yi、分别表示第i帧人脸图像对应的真值唇部关键点坐标以及预测得到的唇部关键点坐标。
[0084]
步骤2.3的模型训练是一个反复的过程,由步骤2.4计算误差,并通过反向传播来更新模型参数,最后获得训练良好的audio2mkp模型。
[0085]
步骤3基于唇部关键点的参照图像生成
[0086]
本步骤利用步骤2获取的预测唇部关键点对人脸图像的唇部区域进行处理生成遮罩图像,并通过建立人脸转换生成对抗网络模型并训练,获得高质量的人脸参照图像。实施例中进一步提出具体涉及步骤3.1~步骤3.4。
[0087]
步骤3.1遮罩图像生成
[0088]
以预测的唇部关键点为基准,在人脸图像中选择合适的区域进行遮罩处理以掩盖人脸原始唇部,然后根据预测唇部关键点勾画出唇部轮廓形成遮罩图像。本发明中将选定的图像局部或全部进行遮盖来控制图像处理的区域,用以覆盖的特定图像定义为遮罩图像。对人脸图像遮罩处理效果将直接影响到步骤3.3的ftgan模型的表现。它涉及步骤3.1.1和步骤3.1.2。
[0089]
步骤3.1.1遮罩区域选择
[0090]
生成遮罩图像将为下一步ftgan模型训练以及参照图像生成做准备。它需要选择一个合适的遮罩区域。如果遮罩区域偏大,模型关注度被分散,则不利于唇部区域的重建;如果遮罩区域偏小,当预测唇部关键点与真值唇部关键点之间出现误差时,会导致生成的参照图像失真。图4给出了几种不合适的遮罩区域处理方式。
[0091]
图4(a)为遮罩区域覆盖整个人脸图像下半区域。该方式简单地对整个图像下半区域进行遮罩处理,会丢失许多人物的面部细节,并不能帮助模型学习到遮罩区域到人脸的映射。图4(b)为遮罩区域覆盖人脸下半区域。该方式会丢失下巴等人脸下半区域的面部细节。图4(c)为遮罩区域仅覆盖唇部区域。虽然这种方式可以最大程度地保留人脸面部细节,但由于模型训练预测的唇部关键点会存在一定的误差,将直接影响参照图像的真实性。
[0092]
图5所示预测唇部关键点存在误差示意图。图5(a)和图5(b)中,浅灰色点连线所围成部分为给定人脸的真实唇部区域,深灰色点连线所围成部分为根据音频对给定人脸进行预测得到的唇部区域。如果预测唇部关键点有误差,那么根据预测得到的唇部区域对图像进行遮罩处理时将无法完全覆盖原人脸图像的唇部区域,即黑色遮罩区域以外的浅灰色连线部分。
[0093]
因此,选择遮罩区域时,优选建议考虑以下两个原则:
[0094]
(1)遮罩区域尽可能少地覆盖给定人脸图像除唇部区域以外的面部区域;
[0095]
(2)遮罩区域能包容一定程度的预测唇部关键点产生的误差。
[0096]
本发明采取唇部区域往外延伸的方式来确定遮罩区域的大小。如图6所示,对图6(a)所示原始图像,以唇部关键点所在矩形区域为基准,往其宽度方向左右各延伸唇部区域宽度,并往高度方向上下各延伸唇部区域高度。同时,以唇部的第一个关键点(即图2(b)中编号为49的特征点)为基准,对预测唇部关键点进行移位对齐,以进一步降低由于预测唇部关键点误差所带来的影响,得到如图6(b)所示的遮罩区域。
[0097]
具体实施时,优选建议的方式为,可通过步骤1.1使用dlib工具提取人脸图像的20个唇部关键点,将这些关键点围成唇部区域,并形成一个矩形区域,再以该区域为中心往外延伸倍,形成一个遮罩区域。
[0098]
步骤3.1.2遮罩区域分割
[0099]
尽管步骤3.1.1选择了合适的遮罩区域,但遮罩区域内部有不同组成部分。为了后续使模型对这些不同组成部分进行训练,对选定的遮罩区域进行分割,将其划分为嘴唇、舌头、牙齿以及其它。然后,分别对分割后的组成部分进行填充处理,得到遮罩图像。图7所示遮罩区域分割处理示意图。图7(b)为对图7(a)所示原始图像进行遮罩区域分割处理以后的结果,图中对圆点用实线围成的区域代表嘴唇,白色填充区域代表牙齿和舌头,黑色区域则代表遮罩区域其余部分。
[0100]
步骤3.2人脸区域划分
[0101]
人脸图像转换时,需要为参照图像保留非遮罩区域,也就是将该区域的像素值一一映射到生成的参照图像中,并将遮罩区域还原为真实的人脸唇部区域。
[0102]
一般根据图像中人脸部分来评价生成图像质量的优劣。图像中人脸区域,特别是唇部区域相对于背景区域更为重要。因此,将人脸图像按照从高到低重要程度划分为如图8所示的不同区域,包括唇部区域、人脸区域以及背景区域。同时,为每个区域设置权重,唇部区域的权重大于人脸区域,人脸区域的权重大于背景区域。
[0103]
图8中,实线框、划线点框和虚线框分别代表背景区域、人脸区域和唇部区域。实施例中实线框覆盖整个人脸图像;划线点框由68个人脸关键点围成的矩形区域,包括五官在内的整个头部信息;虚线框为20个唇部关键点围成的矩形区域。实线框包含划线点框,划线点框包含虚线框。这里并不是将整个图像划分为几个独立的区域,而是使划分区域具有一定的包含关系。
[0104]
在后续步骤3.4计算背景区域图像重建损失时,式(5)中λ3·
loss
mae
(x
bg
,g(z)
bg
)会以权重λ3计算一遍人脸区域和唇部区域的图像重建损失。同样地,在后续步骤3.4计算人脸区域图像重建损失时,式(5)中λ4·
loss
mae
(xf,g(z)f)会以权重λ4计算一遍唇部区域的图像重建损失。也就是,以这种方式进行人脸图像处理时,人脸区域和唇部区域会多次加入图像重建损失计算过程。恰好这两个区域是模型更加关注的区域,本质上来说这也是一种对人脸区域和唇部区域权重分配的方法。所以采用这种包含关系来划分人脸图像能够很好地适应tfgan模型的人脸图像转换。
[0105]
划线点框区域实际上是根据68个人脸关键点信息进行绘制的,包括人脸中五官以及面部轮廓的位置信息。基于以下考虑,本发明划线点框所代表的人脸区域并不包含整张人脸。这是因为,(1)头部区域为一个不规则形状,不方便用于步骤3.4计算人脸区域的图像重建损失;(2)人脸区域并不是模型最为关注区域,头部其余部分作为背景区域处理也能够很好地适用于人脸图像转换任务。
[0106]
虚线框所代表的唇部区域实际上就是遮罩区域,即以唇部区域为中心往宽和高两个方向分别延伸倍。虚线框所在区域为模型最为关注的区域,生成的参照图像的质量很大程度上取决于该区域的准确度,包括唇部是否准确、牙齿和舌头区域的细节、边界是否平滑等。
[0107]
步骤3.3人脸转换生成对抗网络ftgan建模与训练
[0108]
构建人脸转换生成对抗网络(face transformation generative adversarial network,ftgan)。结合后续步骤3.4对ftgan模型进行训练,将预测唇部关键点得到的遮罩图像转换为高质量的人脸参照图像。本发明将参照图像定义为将遮罩图像还原为具有真实人脸形象的图像。它涉及步骤3.3.1和步骤3.3.2。
[0109]
步骤3.3.1ftgan建模
[0110]
生成对抗网络(generative adversarial network,gan)(2014)作为一种无监督深度学习模型,它可以通过生成器(generator,g)和判别器(discriminator,d)的互相博弈学习来获得好的输出结果。生成器生成能够骗过判别器的图像,通过对抗学习,判别器变得更强,能够更好地分辨图像的真假。本发明对gan内部架构进行改造来设计ftgan模型。
[0111]
如图9所示,ftgan模型由一个生成器网络和一个判别器网络组成。考虑到人脸相对于图像大小与位置的不确定性,本发明在设计生成器网络结构时,提出在传统生成器中引入stn模块(spatial transformer network,空间转换器模块)(2015)与cbam模块
(convolutional block attention module,卷积块注意力模块)(2018),并通过stn与cbam两者的组合来提高参照图像的生成质量。stn与cbma作为轻量级通用模块,将它们集成到网络中基本不需要增加额外计算开销而能够有效提升模型的表现力。而在设计判别器网络结构时,采用多尺度判别器(patch-based generative adversarial network,patchgan)网络架构(2017)。不同于传统判别器网络仅输出一个评价值,patchgan多维地评价生成图像,可以更好地指导生成器输出人脸的参照图像。
[0112]
1、生成器网络结构
[0113]
生成器网络由人脸编、解码器模块、stn模块以及cbam模块组成,它接收输入的遮罩图像产生输出人脸参照图像,从输入到输出,stn模块、人脸编码器模块、cbam模块和人脸编码器模块依次连接。编、解码器模块利用人脸编码器在编码过程中提取遮罩图像的特征图表示,并在解码过程中恢复图像信息。由于人脸在图像帧中的大小与位置往往不确定,利用stn模块可以消除人脸图像转换时这种情况。cbam模块在模型进行卷积操作过程中关注那些对任务影响较大的中间通道。
[0114]
编、解码器模块。编解码器由下采样卷积层、残差连接块以及上采样卷积层组成。下采样卷积层提取特征并对特征进行降维;残差连接块包括直接映射部分和残差部分,解决梯度消失和网络退化的问题;上采样卷积层用于特征解码恢复图像。
[0115]
stn模块。stn网络结构如图10所示。它由本地化网络、网格生成器和采样器三个部分组成。输入遮罩图像经过本地化网络的一系列仿射变换得到仿射变换参数θ,然后输入网络生成器;网格生成器根据θ进行空间数据变换得到tθ(g),然后输入采样器;输入遮罩图像同时也输入采样器,由采样器进行乘以结合后输出特征图u1,它处理输出坐标为小数时无法索引到对应的像素点的情况。stn模块将输入和输出进行仿射变换得到二者之间的映射关系,利用网络反向传播优化参数来获得数据在空间位置上的最优值。
[0116]
cbam模块。cbam网络结构如图11所示,由通道注意力模块(channel attention module,cam)和空间注意力模块(spatial attention module,sam)组成。其中,cam利用全局最大池化和平均池化的输出与共享模块多层感知器实现通道注意力机制;sam则利用全局最大池化和平均池化将通道特征进行汇聚实现空间注意力机制。输入特征u2输入通道注意力模块cam,通道注意力模块cam的输出和输入特征u2进行乘以结合后所得中间结果输入空间注意力模块sam,空间注意力模块sam的输出和中间结果进行乘以结合后得到精炼特征u3。这样cbam通过注意力机制获得局部精炼后的特征u3。
[0117]
其中乘以结合,是指对特征图的元素级进行相乘运算。
[0118]
2、判别器网络结构
[0119]
判别器网络结构中主要包括帧判别器模块。优选地,帧判别器采用patchgan的网络结构。patchgan是具有全卷积网络的生成对抗网络的判别器。将输入的真值图像切成n
×
n矩阵x,切分后每个图像块patch送入patchgan判别器中进行判别,矩阵中每个x
ij
代表图像中某坐标为(i,j)的区域的评价值(真或假)。将x
ij
求均值后得到判别器最终输出,该值对生成器生成的图像进行评价。一般gan判别器将输入映射成一个实数,仅输出一个评价值(真或假)。与gan判别器不同,patchgan为全卷积形式,可以多维度地对生成图像进行评价,指导生成器在生成图像过程中关注到更多细节。
[0120]
步骤3.3.2ftgan训练
[0121]
在对ftgan模型进行训练时,如图9所示,将遮罩图像输入生成器层的stn模块,遮罩图像经过仿射变换得到特征图u1。将u1输入人脸编码器,经过下采样卷积层与残差卷积块得到特征图u2。将u2输入cbam模块,经过cbam模块中cam与sam的共同作用得到特征图u3。将u3输入人脸解码器,经过上采样卷积层得到初步参照图像。
[0122]
在此基础上,进一步将生成器层生成的参照图像以及对应的真值图像一起输入到帧判别器网络,计算生成标签与真值标签之间均方误差以评价生成图像优劣。结合步骤3.4,通过反向传播更新模型参数,对ftgan模型进行反复训练,以得到训练效果良好的参照图像。这里,真值图像是指能反映真实反映原始图像特征的数字化表示图像。
[0123]
步骤3.4ftgan模型参数优化
[0124]
使用基于人脸区域划分的图像重建损失函数计算参照图像的图像重建损失,将参照图像与对应的真值图像输入到帧判别器中计算二者之间的误差,通过反向传播来更新模型参数。
[0125]
ftgan模型的损失函数loss
total
由一般gan的损失函数loss
gan
与图像重建损失函数loss
rec
两部分构成,由式(3)进行计算,即
[0126]
loss
total
=λ1·
loss
gan
+λ2·
loss
rec
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(3)
[0127]
其中,λ1与λ2分别代表gan损失与图像重建损失的权重。
[0128]
loss
gan
与loss
rec
分别由式(4)与式(5)进行计算,即
[0129]
loss
gan
=loss
mse
(d(x),d(g(z))
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(4)
[0130]
loss
rec
=λ3·
loss
mae
(x
bg
,g(z)
bg
)+λ4·
loss
mae
(xf,g(z)f)+λ5·
loss
mae
(xm,g(z)m)
ꢀꢀ
(5)
[0131]
其中,x与z分别表示真值图像与噪声图像,g(z)则表示生成图像,x
bg
、xf与xm分别表示人脸划分后的图像背景区域、人脸区域、唇部区域,g(z)
bg
表示生成图像g(z)的背景区域,g(z)f表示生成图像g(z)的人脸区域,g(z)m表示生成图像g(z)的唇部区域;λ3、λ4和λ5分别表示背景区域、人脸区域、唇部区域的损失权重。设置损失函数计算的权重时,可遵循以下原则,即确保模型对唇部区域的权重大于人脸区域,且人脸区域的权重大于背景区域。
[0132]
loss
mse
与loss
mae
分别表示最小均方误差与最小绝对值误差,由式(6)与式(7)进行计算,即。
[0133][0134][0135]
式中,n1和n2分别表示判别器评价的维数以及图像的像素点个数。
[0136]
损失函数使用均方误差计算生成对抗损失,使用绝对值误差计算图像重建损失,并对这两部分赋予不同的权重。
[0137]
步骤3.3的模型训练是一个反复的过程,由步骤3.4计算误差,并通过反向传播来更新模型参数,最后获得训练良好的ftgan模型。
[0138]
步骤4基于音频特征与参照图像的人脸动画生成
[0139]
本步骤在步骤3获得的参照图像基础上,并再次利用步骤2获得的音频特征来指导人脸动画的生成。为了获得人脸动画的唇音同步效果,建立语音到人脸生成对抗网络模型并训练,进行人脸动画合成,获得最终人脸动画。实施例中进一步提出具体涉及步骤4.1和
步骤4.2。
[0140]
步骤4.1语音到人脸生成对抗网络a2fgan建模与训练
[0141]
建立语音到人脸生成对抗网络(audio-to-face generative adversarial network,a2fgan),它接收dsaudio_features音频特征以及参照图像作为输入,结合后续步骤4.2,对a2fgan模型进行训练,获得人脸动画图像帧。它涉及步骤4.1.1和步骤4.1.2。
[0142]
步骤4.1.1a2fgan建模
[0143]
本发明实施例的优选方案为,利用gan架构来设计a2fgan模型。但与传统gan架构不同,如图12所示,它包含一个生成器网络和两个判别器网络。在设计生成器网络时,同样地引入stn模块与cbam模块的组合来提高图像的生成质量。在设计判别器网络时,构建基于patchgan网络结构的帧判别器;同时,为了判断音频与视频是否同步,进一步利用syncnet(2016)判断唇音同步的优势,在判别器中设计一个基于syncnet的唇音同步判别器。
[0144]
1、生成器网络结构
[0145]
生成器网络由人脸编、解码器模块、stn模块以及cbam模块组成。
[0146]
编码器模块包含一个人脸编码器和一个dsaudio_features音频编码器。人脸编码器与步骤3.3.1的ftgan模型中的人脸编码器具有相同任务目标,即提取输入图像的特征图及其编码表示。dsaudio_features音频编码器提取dsaudio_features音频特征的特征图及其编码表示,由带有残差连接的卷积层构成。人脸解码器与ftgan模型中的人脸解码器结构类似。所不同的是,a2fgan模型中的人脸解码器需要对两个编码器所提取的特征图进行拼接后再进行解码。
[0147]
将参照图像输入stn模块,参照图像经过仿射变换得到特征图u1;将u1输入人脸编码器,得到特征图u2。然后将dsaudio_features音频特征输入dsaudio_features音频编码器,得到特征图u3。再将u2、u3进行拼接后输入cbam模块,得到特征图u4。将u4输入人脸解码器,得到人脸动画图像帧。
[0148]
2、判别器网络结构
[0149]
两个判别器网络分别由帧判别器模块与唇音同步判别器模块组成。
[0150]
帧判别器模块。它采用与ftgan模型中的patchgan判别器相同的结构。
[0151]
唇音同步判别器模块。基于syncnet的唇音同步判别网络如图13所示,它判断音频特征和人脸图像特征在共同参数空间下的相似性,以此评价生成的人脸动画图像帧与对应的音频帧之间的同步效果。考虑到人脸相对于整个图像的位置与大小的不确定性以及音频特征与唇部运动对应的实际应用,对syncnet模型进行适应性修改。不使用人脸图像的下半区域作为输入,而使用人脸图像数据上以唇部坐标为中心、唇部遮罩区域作为输入来计算共同参数空间下音频帧与图像帧的相似性。这样,该区域能够覆盖唇部区域,并且能够利用在此维度上预先训练好的模型参数进行迁移。
[0152]
在该网络中,如图13所示,采用两个卷积神经网络cnn1和cnn2分别提取具有相同长度的音频帧与人脸图像帧的特征信息。通过权重共享模块对这两个信息设置共享权重,将具有不同模态的音频帧与图像帧的特征信息转化到同一参数空间。然后,通过损失函数计算余弦相似度标签向量与真值标签向量之间的差值。
[0153]
步骤4.1.2a2fgan训练
[0154]
在对a2fgan模型进行训练时,如图12所示,首先,将参照图像输入stn模块,参照图
像经过仿射变换得到特征图u1。将u1输入人脸编码器,经过下采样卷积层与残差卷积块得到特征图u2。然后将dsaudio_features音频特征输入dsaudio_features音频编码器,经过带有残差连接的卷积层得到特征图u3。再将u2、u3进行拼接后输入cbam模块,经过cbam模块中cam模块与sam模块得到特征图u4。将u4输入人脸解码器,经过上采样卷积层得到初步人脸动画图像帧。
[0155]
然后进行判别器训练。本发明优选提出,将唇音同步判别器与帧判别器分开进行训练,即先单独地训练唇音同步判别器,然后再对帧判别器进行训练。
[0156]
1、唇音同步判别器训练
[0157]
先训练用唇音同步判别器进行唇音同步训练,即判断人物说话口型和声音是否同步。如果同步,则模型被训练好;否则有误差,则反复训练。
[0158]
在对唇音同步判别器进行训练时,如图12所示,将生成器层生成的人脸动画图像帧与对应的真值音频输入唇音同步判别器,经过cnn1、cnn2以及权重共享模块得到人脸图像帧与音频帧在共同参数空间下的特征表示。使用余弦相似度计算共同参数空间下人脸图像帧与音频帧的特征表示之间的相似性,得到二者之间的余弦相似度标签向量。余弦相似度由式(8)进行计算,即
[0159][0160]
其中,n表示图像帧与音频帧在共同参数空间下的维度,ai与vi分别表示音频帧与图像帧序列在共同参数空间中的第i个维度上的特征值。
[0161]
2、帧判别器训练
[0162]
训练帧判别器时,要用到训练唇音同步判别器时已训练好的同步的人脸动画图像帧;这时虽然已经做到了唇音同步,但与真值图像还是会有差别,所以还要继续进行训练,直至完全达到真值图像的效果。
[0163]
将已唇音同步的人脸动画图像帧与对应的真值图像输入到帧判别器,计算生成标签与真值标签之间均方误差以评价生成图像优劣。结合步骤4.2,通过反向传播更新模型参数,对a2fgan模型进行反复训练,以得到唇音同步且保持真值图像效果的人脸动画图像帧。
[0164]
步骤4.2a2fgan模型参数优化
[0165]
a2fgan模型的损失函数loss
total
由三部分构成,即帧判别器的生成对抗损失loss
gan
、唇音同步判别器的唇音同步损失loss
sync
以及人脸图像的重建损失loss
rec
,计算公式如式(9)所示。
[0166]
loss
total
=λ1·
loss
gan
+λ2·
loss
sync
+λ3·
loss
rec
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(9)
[0167]
其中,λ1、λ2与λ3表示各部分损失的权重。
[0168]
loss
gan
与loss
rec
的计算同ftgan模型,利用式(4)与式(5)分别进行计算。
[0169]
计算余弦相似度标签向量与真值标签向量的二值交叉熵损失得到loss
sync
,它通过公式(10)进行计算。
[0170]
loss
sync
=loss
bce
(cosine_similarity(d
sync
(audio,g(x))),y)
ꢀꢀꢀꢀꢀꢀ
(10)
[0171]
其中,audio表示真值图像对应的音频,g(x)表示生成器根据参照图像生成的图
像,d
sync
表示基于syncnet模型构建的唇音同步判别器,d
sync
(audio,g(x))返回audio与g(x)在同一参数空间上的表示,cosine_similarity()函数计算二者之间的余弦相似度,计算公式为式(8),y表示唇音同步对应的真值标签向量。loss
bce
由如式(11)进行计算,即
[0172][0173]
其中,n表示标签向量的维度,yi与pi分别表示第i个维度中对应的真值标签与余弦相似度标签。
[0174]
步骤4.1的模型训练是一个反复的过程,由步骤4.2计算误差,并通过反向传播来更新模型参数,最后获得训练良好的a2fgan模型。
[0175]
步骤4.3人脸动画合成
[0176]
输入的人脸形象一般有两种形式,即人脸视频和人脸图像。对于前者,即给定人脸图像帧序列,视频中的人脸图像已经具有自然的头部运动;而对于后者,还需要对图像进行一定的处理以生成具有自然头部运动的人脸动画。因此,在人脸动画合成时,针对以下两种不同情形分别进行处理。
[0177]
1、当人脸形象以视频形式给出时
[0178]
由于视频中的人脸图像已经具有自然的头部运动,因此可根据训练好的a2fgan模型直接生成人脸动画。
[0179]
2、当人脸形象以单张图像形式给出时
[0180]
当人脸形象是以单张图像的形式给出时,为保证语音驱动单张人脸图像生成的人脸动画中人脸具有自然的头部运动,给定语音、单张目标人脸图像,选取一个标准的中间人脸形象图像帧序列,基于给定的音频与中间人脸形象图像帧序列生成与音频同步的中间人脸动画。再利用few_shot_vid2vid模型(2019)构建人脸姿态迁移模型,将中间人脸动画迁移到给定的单张人脸图像上,生成并输出人脸动画。这里,few_shot_vid2vid模型是一种基于gan的条件式视频合成网络,它利用少量目标图像可以合成同样的真人运动视频,并具有场景泛化能力,因此适合进行人脸迁移并生成人脸动画视频。
[0181]
缩略词注释表
[0182]
表:缩略词注释表
[0183][0184][0185]
具体实施时,本发明技术方案提出的方法可由本领域技术人员采用计算机软件技术实现自动运行流程,实现方法的系统装置例如存储本发明技术方案相应计算机程序的计算机可读存储介质以及包括运行相应计算机程序的计算机设备,也应当在本发明的保护范围内。
[0186]
在一些可能的实施例中,提供一种语音驱动的人脸动画生成系统,包括处理器和存储器,存储器用于存储程序指令,处理器用于调用存储器中的存储指令执行如上所述的一种语音驱动的人脸动画生成方法。
[0187]
在一些可能的实施例中,提供一种语音驱动的人脸动画生成系统,包括可读存储介质,所述可读存储介质上存储有计算机程序,所述计算机程序执行时,实现如上所述的一种语音驱动的人脸动画生成方法。
[0188]
本文中所描述的具体实施例仅仅是对本发明精神作举例说明。本发明所属技术领域的技术人员可以对所描述的具体实施例做各种各样的修改或补充或采用类似的方式替代,但并不会偏离本发明的精神或者超越所附权利要求书所定义的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1