分布式声纹检索方法及系统与流程
1.本发明涉及声纹检索技术领域,特别是涉及一种分布式声纹检索方法及系统。
背景技术:
2.随着网络媒体的飞速发展,大量的语音和视频喷涌出现,声纹检索的用途也越来越广泛。声纹检索就是通过给定的语音,检索返回在数据库中与这段语音来自同一个说话人的一条或多条语音,通过进行声纹检索,可以检测各种侵权行为。
3.传统的声纹检索算法,通常先建立声纹数据库,然后将待检索的声纹与数据库中的声纹进行比对返回对应的检索结果。然而,传统的声纹检索算法不适用于大规模数据的情况,过高的存储开销和计算时间会降低检索的实用性和效率。
技术实现要素:
4.基于此,为了解决上述技术问题,提供一种分布式声纹检索方法及系统,可以提高声纹检索的效率。
5.一种分布式声纹检索方法,所述方法包括:
6.中心服务器基于大规模脱敏录音数据训练声纹编码器,并将所述声纹编码器分发给各个分布式存储端;
7.各个所述分布式存储端构建本地声纹底库,并根据所述声纹底库中的声纹数据构建底库矩阵;
8.所述中心服务器接收声纹查询数据,并根据所述声纹查询数据构建查询矩阵,将所述查询矩阵广播至各个所述分布式存储端;
9.各个所述分布式存储端接收所述查询矩阵,根据所述查询矩阵与所述底库矩阵进行声纹检索计算,得到打分矩阵并发送给所述中心服务器;
10.所述中心服务器根据所述打分矩阵确定与所述声纹查询数据对应的说话人声纹检索结果。
11.在其中一个实施例中,中心服务器基于大规模脱敏录音数据训练声纹编码器,包括:
12.中心服务器接收声纹编码器训练数据,并将所述声纹编码器训练数据划分为第一标签数据和第二标签数据;
13.所述中心服务器通过自监督学习在所述第二标签数据上初始化网络参数,得到基本收敛后的声纹编码器模型;
14.所述中心服务器在所述第一标签数据上进行多分类训练精调网络直至基本收敛后的声纹编码器模型完全收敛,得到声纹编码器;
15.其中,所述第一标签数据为有说话人标记的标签数据,所述第二标签数据为数据来源确定但没有说话人标记的标签数据。
16.在其中一个实施例中,各个所述分布式存储端构建本地声纹底库,包括:
17.各个所述分布式存储端接收同一说话人的若干条录音样本;
18.各个所述分布式存储端通过质量评估函数对每条所述录音样本的声纹编码进行质量评估,并得到评估分数;
19.各个所述分布式存储端利用所述评估分数对每条所述录音样本的声纹编码进行线性加权融合,得到所述说话人的声纹表征;
20.各个所述分布式存储端根据所述声纹表征构建本地声纹底库。
21.在其中一个实施例中,各个所述分布式存储端根据所述声纹底库中的声纹数据构建底库矩阵,包括:
22.各个所述分布式存储端根据所述声纹编码器将所述声纹底库划分为若干个子声纹底库;
23.各个所述分布式存储端根据各个所述子声纹底库构成各个子底库矩阵。
24.在其中一个实施例中,所述中心服务器接收声纹查询数据,并根据所述声纹查询数据构建查询矩阵,包括:
25.所述中心服务器通过所述声纹编码器将待查询录音数据归一化为所述声纹查询数据;
26.所述中心服务器将所述声纹查询数据划分为若干个子声纹查询数据;
27.所述中心服务器根据若干个所述子声纹查询数据构成各个子查询矩阵。
28.在其中一个实施例中,各个所述分布式存储端根据所述查询矩阵与所述底库矩阵进行声纹检索计算,得到打分矩阵,包括:
29.各个所述分布式存储端基于cannon算法利用多处理器并行技术,根据各个所述子底库矩阵、各个所述子查询矩阵计算得到各个子打分矩阵;
30.各个所述分布式存储端将各个所述子查询矩阵与各个所述子打分矩阵进行合并计算,得到所述打分矩阵。
31.在其中一个实施例中,所述中心服务器根据所述打分矩阵确定与所述声纹查询数据对应的说话人声纹检索结果,包括:
32.所述中心服务器收集所述打分矩阵,并从所述打分矩阵中查找最高打分结果,根据所述最高打分结果得到说话人声纹检索结果。
33.一种分布式声纹检索系统,所述系统包括:
34.中心服务器,用于基于大规模脱敏录音数据训练声纹编码器,并将所述声纹编码器分发给各个分布式存储端;
35.各个所述分布式存储端,用于构建本地声纹底库,并根据所述声纹底库中的声纹数据构建底库矩阵;
36.所述中心服务器,还用于接收声纹查询数据,并根据所述声纹查询数据构建查询矩阵,将所述查询矩阵广播至各个所述分布式存储端;
37.各个所述分布式存储端,还用于接收所述查询矩阵,根据所述查询矩阵与所述底库矩阵进行声纹检索计算,得到打分矩阵并发送给所述中心服务器;
38.所述中心服务器,还用于根据所述打分矩阵确定与所述声纹查询数据对应的说话人声纹检索结果。
39.上述分布式声纹检索方法及系统,中心服务器基于大规模脱敏录音数据训练声纹
编码器,并将所述声纹编码器分发给各个分布式存储端;各个所述分布式存储端构建本地声纹底库,并根据所述声纹底库中的声纹数据构建底库矩阵;所述中心服务器接收声纹查询数据,并根据所述声纹查询数据构建查询矩阵,将所述查询矩阵广播至各个所述分布式存储端;各个所述分布式存储端接收所述查询矩阵,根据所述查询矩阵与所述底库矩阵进行声纹检索计算,得到打分矩阵并发送给所述中心服务器;所述中心服务器根据所述打分矩阵确定与所述声纹查询数据对应的说话人声纹检索结果。通过将声纹底库数据采用分布式存储的方式存储在各个存储端中,并通过查询矩阵和打分矩阵进行声纹查询,当存在大规模检索数据时,通过分布式存储端进行辅助声纹查询可以提高声纹检索的效率。
附图说明
40.图1为一个实施例中分布式声纹检索方法的应用环境图以及分布式声纹检索系统的结构图;
41.图2为一个实施例中分布式声纹检索方法的流程示意图。
具体实施方式
42.为了使本技术的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本技术进行进一步详细说明。应当理解,此处描述的具体实施例仅仅用以解释本技术,并不用于限定本技术。
43.可以理解,本技术所使用的术语“第一”、“第二”等可在本文中用于描述标签数据,但这些标签数据不受这些术语限制。这些术语仅用于将第一个标签数据与另一个标签数据区分。举例来说,在不脱离本技术的范围的情况下,可以将第一标签数据称为第二标签数据,且类似地,可将第二标签数据称为第一标签数据。第一标签数据和第二标签数据两者都是标签数据,但其不是同一标签数据。
44.本技术实施例提供的分布式声纹检索方法,可以应用于如图1所示的应用环境中。如图1所示,该应用环境包括中心服务器110、各个分布式存储端120,其中,中心服务器110与各个分布式存储端120之间可以通信。中心服务器110基于大规模脱敏录音数据训练声纹编码器,并将声纹编码器分发给各个分布式存储端120;各个分布式存储端120构建本地声纹底库,并根据声纹底库中的声纹数据构建底库矩阵;中心服务器110接收声纹查询数据,并根据声纹查询数据构建查询矩阵,将查询矩阵广播至各个分布式存储端120;各个分布式存储端120接收查询矩阵,根据查询矩阵与底库矩阵进行声纹检索计算,得到打分矩阵并发送给中心服务器110;中心服务器110根据打分矩阵确定与声纹查询数据对应的说话人声纹检索结果。
45.在一个实施例中,如图2所示,提供了一种分布式声纹检索方法,包括以下步骤:
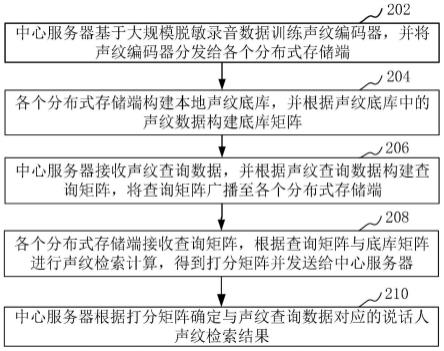
46.步骤202,中心服务器基于大规模脱敏录音数据训练声纹编码器,并将声纹编码器分发给各个分布式存储端。
47.中心服务器可以基于大规模脱敏录音数据基于深度神经网络构建声纹编码器,声纹编码器由声学特征提取器、编码网络、池化层等组成。
48.中心服务器上训练完成声纹编码器后,可以将声纹编码器分发给各个分布式存储端以待后用。
49.步骤204,各个分布式存储端构建本地声纹底库,并根据声纹底库中的声纹数据构建底库矩阵。
50.多数说话人可能录入或者被采集到多条音频,各个分布式存储端可以采用基于线性加权的方式对多条音频进行声纹融合,从而构建成本地声纹底库。
51.步骤206,中心服务器接收声纹查询数据,并根据声纹查询数据构建查询矩阵,将查询矩阵广播至各个分布式存储端。
52.中心服务器接收声纹查询数据,是为了进行声纹检索以查询对应说话人身份。为了减少平均计算时间提高检索效率,将声纹检索过程建模为矩阵乘法并利用矩阵运算并行化技术加速检索过程。中心服务器可以根据声纹查询数据构建查询矩阵,并通过广播的方式将查询矩阵传输至各个分布式存储端。
53.步骤208,各个分布式存储端接收查询矩阵,根据查询矩阵与底库矩阵进行声纹检索计算,得到打分矩阵并发送给中心服务器。
54.步骤210,中心服务器根据打分矩阵确定与声纹查询数据对应的说话人声纹检索结果。
55.在本实施例中,提供的一种分布式声纹检索方法中,中心服务器基于大规模脱敏录音数据训练声纹编码器,并将声纹编码器分发给各个分布式存储端;各个分布式存储端构建本地声纹底库,并根据声纹底库中的声纹数据构建底库矩阵;中心服务器接收声纹查询数据,并根据声纹查询数据构建查询矩阵,将查询矩阵广播至各个分布式存储端;各个分布式存储端接收查询矩阵,根据查询矩阵与底库矩阵进行声纹检索计算,得到打分矩阵并发送给中心服务器;中心服务器根据打分矩阵确定与声纹查询数据对应的说话人声纹检索结果。通过将声纹底库数据采用分布式存储的方式存储在各个存储端中,并通过查询矩阵和打分矩阵进行声纹查询,当存在大规模检索数据时,通过分布式存储端进行辅助声纹查询可以提高声纹检索的效率。
56.在一个实施例中,提供的一种分布式声纹检索方法还可以包括训练声纹编码器的过程,具体过程包括:中心服务器接收声纹编码器训练数据,并将声纹编码器训练数据划分为第一标签数据和第二标签数据;中心服务器通过自监督学习在第二标签数据上初始化网络参数,得到基本收敛后的声纹编码器模型;中心服务器在第一标签数据上进行多分类训练精调网络直至基本收敛后的声纹编码器模型完全收敛,得到声纹编码器;其中,第一标签数据为有说话人标记的标签数据,第二标签数据为数据来源确定但没有说话人标记的标签数据。
57.中心服务器可以基于大规模脱敏录音数据基于深度神经网络构建声纹编码器。具体的,构建声纹编码器的过程可以是一个两阶段的模型训练过程。其中,在声纹编码器训练阶段,中心服务器可以将训练数据划分为两类,第一标签数据和第二标签数据,第一标签数据是有说话人记号的强标签数据,例如身份证或电话号码;第二标签数据是只知道数据来源而没有说话人标记的弱标签数据,例如知道其来自某个运营商或者知道他来自某个地区,但不知道说话人具体的身份信息或电话号码。
58.为了提高样本丰富性并充分利用两类数据,中心服务器可以通过自监督学习在弱标签数据集上初始化网络参数,例如将时空关联性强的录音数据认为是正样本对而来自不同数据源的2条录音认为是负样本对开展度量学习;等到模型基本收敛后,中心服务器改在
强标签数据集上进行多分类训练精调网络直至完全收敛,从而得到声纹编码器。
59.在一个实施例中,提供的一种分布式声纹检索方法还可以包括各个分布式存储端构建本地声纹底库的过程,具体过程包括:各个分布式存储端接收同一说话人的若干条录音样本;各个分布式存储端通过质量评估函数对每条录音样本的声纹编码进行质量评估,并得到评估分数;各个分布式存储端利用评估分数对每条录音样本的声纹编码进行线性加权融合,得到说话人的声纹表征;各个分布式存储端根据声纹表征构建本地声纹底库。
60.各个分布式存储端可以基于线性加权的说话人多录音样本声纹融合,从而进行制作和维护声纹底库。在本实施例中,各个分布式存储端可以接收同一说话人的若干条录音样本,对于拥有多条录音样本的说话人i,各个分布式存储端可以使用一质量评估函数f对每条样本的声纹编码e
it
进行质量评估得到一评估分数w
t
=f(e
it
),利用该质量评估分数对每条样本的声纹编码进行线性加权融合得到该说话人的声纹表征:进而构建本地声纹底库。
61.在一个实施例中,提供的一种分布式声纹检索方法还可以包括构建底库矩阵的过程,具体过程包括:各个分布式存储端根据声纹编码器将声纹底库划分为若干个子声纹底库;各个分布式存储端根据各个子声纹底库构成各个子底库矩阵。
62.对于声纹底库中的数据,各个分布式存储端可以将声纹底库划分为若干个小批次的子声纹底库{1,2,...,k},每个小批次的子声纹底库构成一个n*e的小批次子底库矩阵bk,其中,n表示该小批次的底库说话人数据,e是声纹编码维度,需要保证n≤e且n尽量接近e。
63.在一个实施例中,提供的一种分布式声纹检索方法还可以包括构建查询矩阵的过程,具体过程包括:中心服务器通过声纹编码器将待查询录音数据归一化为声纹查询数据;中心服务器将声纹查询数据划分为若干个子声纹查询数据;中心服务器根据若干个子声纹查询数据构成各个子查询矩阵。
64.声纹底库说话人相互之间具有无关性,每条查询数据之间也具有无关性,对于一个批次的查询,中心服务器可以通过声纹编码器将待查询录音数据归一化为声纹查询数据,然后将该批次的声纹查询数据划分为多个小批次查询数据,即子声纹查询数据{1,2,...,j},每个小批次查询数据可以构成一个m*e的小批次查询矩阵,即子查询矩阵qj。其中,m表示该小批次的录音数目,e是声纹编码维度,需要保证m≤e且m尽量接近e。
65.在一个实施例中,提供的一种分布式声纹检索方法还可以包括得到打分矩阵的过程,具体过程包括:各个分布式存储端基于cannon算法利用多处理器并行技术,根据各个子底库矩阵、各个子查询矩阵计算得到各个子打分矩阵;各个分布式存储端将各个子查询矩阵与各个子打分矩阵进行合并计算,得到打分矩阵。
66.在本实施例中,各个分布式存储端可以基于cannon算法利用多处理器并行技术快速求解矩阵乘法r
jk
=q
jbkt
,其中,r
jk
为小批次打分矩阵,即子打分矩阵。各个分布式存储端可以对所有底库批次合并r
jk
得到rj,再对所有查询批次合并rj得到r,即为该批次的打分矩阵r。
67.在一个实施例中,提供的一种分布式声纹检索方法还可以包括确定检索结果的过程,具体过程包括:中心服务器收集打分矩阵,并从打分矩阵中查找最高打分结果,根据最
高打分结果得到说话人声纹检索结果。
68.对于每个查询u,打分矩阵r中对应行的最大响应所对应的底库说话人v
*
即为检索结果:v
*
=argmaxv(r
uv
)。
69.在一个实施例中,在各个分布式存储端下进行说话人声纹检索时,考虑到生物特征信息的用户隐私性,声纹底库数据采用分布式存储的方式存储在采集方设备上,并通过查询矩阵和打分矩阵通信实现分布式脱敏声纹检索。各分布式存储端基于底库声纹编码数据构建底库矩阵,查询时中心服务器首先基于查询数据构建查询矩阵,然后向各存储方广播查询矩阵。各个分布式存储端基于查询矩阵和底库矩阵进行声纹检索计算对应的打分矩阵,并将打分矩阵返回给中心服务器。中心服务器收集所有打分矩阵并根据最高打分结果确定说话人身份。
70.应该理解的是,虽然上述流程图中的各个步骤按照箭头的指示依次显示,但是这些步骤并不是必然按照箭头指示的顺序依次执行。除非本文中有明确的说明,这些步骤的执行并没有严格的顺序限制,这些步骤可以以其它的顺序执行。而且,上述流程图中的至少一部分步骤可以包括多个子步骤或者多个阶段,这些子步骤或者阶段并不必然是在同一时刻执行完成,而是可以在不同的时刻执行,这些子步骤或者阶段的执行顺序也不必然是依次进行,而是可以与其它步骤或者其它步骤的子步骤或者阶段的至少一部分轮流或者交替地执行。
71.在一个实施例中,如图1所示,提供了一种分布式声纹检索系统,包括:中心服务器110、各个分布式存储端120,即,在本实施例中,提供的一种分布式声纹检索系统可以包括部署在中心服务器110的主系统和部署在各个分布式存储端120侧的分系统,其中:
72.中心服务器110,用于基于大规模脱敏录音数据训练声纹编码器,并将声纹编码器分发给各个分布式存储端120;
73.各个分布式存储端120,用于构建本地声纹底库,并根据声纹底库中的声纹数据构建底库矩阵;即,在各个分布式存储端120处,通过分系统构建本地声纹底库;
74.中心服务器110,还用于接收声纹查询数据,并根据声纹查询数据构建查询矩阵,将查询矩阵广播至各个分布式存储端120;
75.各个分布式存储端120,还用于接收查询矩阵,根据查询矩阵与底库矩阵进行声纹检索计算,得到打分矩阵并发送给中心服务器110;
76.中心服务器110,还用于根据打分矩阵确定与声纹查询数据对应的说话人声纹检索结果。
77.使用者通过中心服务器110的主系统对给定录音数据进行声纹检索以查询其对应说话人身份。由于声纹底库数据采用分布式存储的方式存储在各个分布式存储端120上以保护用户的生物特征隐私,故通过主从节点间的查询数据和打分结果通信实现分布式声纹检索。
78.在一个实施例中,中心服务器110还用于接收声纹编码器训练数据,并将声纹编码器训练数据划分为第一标签数据和第二标签数据;通过自监督学习在第二标签数据上初始化网络参数,得到基本收敛后的声纹编码器模型;在第一标签数据上进行多分类训练精调网络直至基本收敛后的声纹编码器模型完全收敛,得到声纹编码器;其中,第一标签数据为有说话人标记的标签数据,第二标签数据为数据来源确定但没有说话人标记的标签数据。
79.在一个实施例中,各个分布式存储端120,还用于接收同一说话人的若干条录音样本;通过质量评估函数对每条录音样本的声纹编码进行质量评估,并得到评估分数;利用评估分数对每条录音样本的声纹编码进行线性加权融合,得到说话人的声纹表征;根据声纹表征构建本地声纹底库。
80.在一个实施例中,各个分布式存储端120,还用于根据声纹编码器将声纹底库划分为若干个子声纹底库;根据各个子声纹底库构成各个子底库矩阵。
81.在一个实施例中,中心服务器110还用于通过声纹编码器将待查询录音数据归一化为声纹查询数据;将声纹查询数据划分为若干个子声纹查询数据;根据若干个子声纹查询数据构成各个子查询矩阵。
82.在一个实施例中,各个分布式存储端120,还用于基于cannon算法利用多处理器并行技术,根据各个子底库矩阵、各个子查询矩阵计算得到各个子打分矩阵;将各个子查询矩阵与各个子打分矩阵进行合并计算,得到打分矩阵。
83.在一个实施例中,中心服务器110还用于收集打分矩阵,并从打分矩阵中查找最高打分结果,根据最高打分结果得到说话人声纹检索结果。
84.以上实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。
85.以上所述实施例仅表达了本技术的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本技术构思的前提下,还可以做出若干变形和改进,这些都属于本技术的保护范围。因此,本技术专利的保护范围应以所附权利要求为准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1