一种定站不定线定制公交多层次站点设计方法与流程
1.本发明涉及一种定站不定线定制公交多层次站点设计方法,属于大数据信息挖掘与公共交通系统设计的交叉应用领域。
背景技术:
2.随着城市的发展壮大,居民生活节奏加快,生活水平显著提高,人们对出行的便利性、舒适性、快速性的要求不断提高。定制公交以互联网技术为依托,以乘客需求为导向,根据实际的乘客出行需求分布及出行时间要求进行车辆行驶路径的规划,相比于传统公交,能够更好地满足乘客个性化的出行需求,提升乘客出行体验,提高出行效率,并能够有效吸纳私家车出行需求,减少机动车出行量,缓解交通拥堵和空气污染。
3.定制公交系统为乘客提供了更有效的防疫安全空间,避免与其他非同程出行者的不必要近距离接触,大大降低了交叉感染的风险,用户出行轨迹可溯源、便于追踪等优势使得其在后疫情时代的公共交通出行中发挥了巨大的作用。定站不定线是定制公交系统中一种常见的运营模式,公交车辆在一定区域内为出行者提供出行服务,设有固定站点,但线路灵活。乘客在手机app端的站点库中选择上车、下车站点和出行时间,系统根据实际需求派车并实时规划最优线路。目前该模式已经在北京、西安等城市得到广泛应用。
4.如何选取站点位置,使得系统能够服务和吸纳更多的出行者和出行需求,是决定定站不定线定制公交系统高效运营的一个关键环节。站点的合理布设,能够有效减少乘客步行距离,长期保持较高的上座率,增加定制公交出行系统的服务水平和盈利能力。因此,探索一种科学的定站不定线定制公交站点设计方法具有较强的现实意义。
5.目前现有技术中,马小磊等人公开了基于网约车数据的定制公交站点选址方法(cn 109583611 a),基于网约车订单数据提取出行od,补充了乘客出行需求收集方式,将网约车数据简化为区域间流动与区域内流动的概念,从而提高站点选址的精度。存在以下缺陷:无法将定制公交服务设计参数作为站点划分的控制变量(如步行距离),采用的聚类算法易受离群点和噪声点的影响;采用的聚类算法参数k依据经验值确定,算法易产生过于庞大的聚类簇和交通小区,不能保证乘客步行距离在一定范围之内。
6.张改等人公开了一种基于手机信令数据的定制公交站点布局方法(cn112150796 a),针对一天产生的手机信令数据,识别出枢纽站到发人口及出行 od,采用dbscan聚类算法确定合乘站点位置。存在以下缺陷:需求数据的起终点位置并不精确;采用的聚类算法易产生较大的聚类簇,进而导致需求密度大的区域站点反而较为稀疏的问题。
7.现有方法或发明的缺陷:
8.1)目前无公开的直接适用于定站不定线定制公交系统的站点设计方法;
9.2)无法充分考虑定制公交系统服务设计参数;
10.3)需求簇对应的站点数量计算缺乏科学性,采用的算法无法综合考虑站点服务半径限制和需求密度的分布,易产生过大的需求簇,进而导致站点过于稀疏且乘客步行距离过大的实际问题。
技术实现要素:
11.基于上述定制公交站点选址方法的缺陷和不足,本发明构建了一种定站不定线定制公交多层次站点设计方法,该方法能够充分考虑出行系统设计参数,创新性的提出了一种多层次站点设计方法,能够综合考虑站点服务半径限制和需求密度的分布,克服传统聚类方法易产生过大需求簇和站点过于稀疏的问题。提出的站点设计方法提高了定站不定线的动态定制公交站点设计的科学性,该方法在不同城市具有普遍适用性。
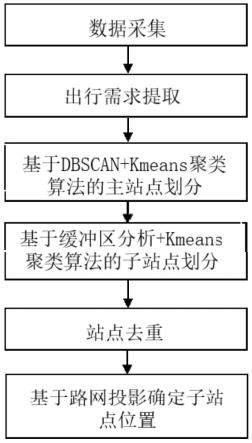
12.为了实现上述目的,本发明采用如下技术方案:
13.一种定站不定线定制公交多层次站点设计方法,步骤如下:
14.第一步:数据采集:采集潜在需求数据,如网约车平台订单数据、公交ic 卡数据等,出行大数据中必须包含或推算的字段包括出行起点位置、出行终点位置和出发时刻时间戳;提取目标区域矢量地理数据作为地图数据集;
15.第二步:出行需求提取:提取或计算出行(订单)需求信息,包括出行起、终点坐标、出发时间等;
16.第三步:主站点划分:
17.s1:出行需求起、终点空间聚类:基于需求的起、终点经、维度坐标,采取基于密度的噪声应用空间聚类算法(dbscan),以设计站点服务半径r和最小上座率对应的需求数量minpts为参数,进行空间聚类,生成需求的起点簇和终点簇;
18.s2:计算主站点空间坐标:采用k-means聚类算法以每个聚类簇中需求的起、终点为样本,设定聚类数量k为1,聚类得到需求簇,计算得到的各聚类簇的质心坐标即为主站点坐标;
19.第四步:子站点划分:
20.s1:基于缓冲区分析计算各主站点服务区:为需求簇中需求起点、终点生成圆形缓冲区作为需求缓冲区,半径设定为站点服务半径r,并将相同簇中的需求缓冲区进行融合,得到各主站点服务区域;
21.s2:计算子站点数量:计算各主站点服务区面积a,并基于以下公式计算需要划分的子站点数量q:
[0022][0023]
s3:子站点需求再聚类:采用k-means聚类算法以每个聚类簇中需求的起、终点为样本,设定聚类数量为q,聚类得到各主站点的子需求簇,并求得子站点需求簇的质心;
[0024]
第五步,站点去重:
[0025]
s1:分析需求起点和终点分别生成的上、下车子站点位置的空间分布;计算各个上车子站点与各个下车子站点的距离,将站点间距小于最大服务半径r的站点标识为待调整站点;
[0026]
s2:采用基于需求权重的中心坐标计算方法将待调整站点进行合并:
[0027]
第六步:计算子站点位置:将去重后生成的子站点投影至路网,获得实际站点位置坐标。
[0028]
优选的,第三步中采用的基于密度的噪声应用空间聚类(dbscan)是一种无监督机器学习聚类算法,可以聚类任意形状的簇,对异常值不敏感,并且不需要预先设定集群的数量。
[0029]
优选的,第四步中需求缓冲区的融合,是将同一需求簇的需求产生的缓冲区要素中,相交的缓冲区要素融合成一个缓冲区面要素的过程。
[0030]
优选的,第四步中聚类簇缓冲区分析能够在考虑步行距离约束的前提下计算站点服务区面积,并最终计算出各聚类簇需要进一步划分的子站点数量q作为下一步kmeans聚类的输入参数,弥补了传统算法中根据设计者经验主观确定子站点数量的缺陷。
[0031]
优选的,第五步采用基于权重的站点坐标计算方法合并过近的站点,假设两站点坐标c1(x1,y1)和c2(x2,y2),两站点权重分别为α1和α2,合并后的聚类中心坐标为:
[0032][0033]
优选的,第五步采用的基于权重的站点坐标计算方法合并过近的站点,站点权重由各站点服务的需求数量确定。
[0034]
本发明的有益效果:
[0035]
与现有技术相比,本发明公开提供的定站不定线定制公交多层次站点设计方法,具有以下优点:
[0036]
(1)本发明提出的站点设计流程和算法能够将定制公交系统服务参数作为站点设计的控制参数,可操作性和科学性有所增强,公交公司可以根据乘客满意度反馈和运营状况对站点设计算法参数进行调整,以提升服务质量;
[0037]
(2)本发明提出的多层次站点聚类算法基于需求密度聚类,并且能够在算法全流程中考虑站点服务半径的限制,通过多次聚类完成多层次站点的设计。具体通过缓冲区分析确定聚类簇内站点数量,并对第一步聚类产生的较大聚类簇进行二次划分,能够有效避免现有技术中易产生较大聚类簇进而导致站点稀疏、乘客步行距离远的问题。
附图说明
[0038]
图1为本发明提供的定站不定线公交多层次站点设计方法实施流程图;
[0039]
图2为本发明实施例中提供的数据中需求起点分布图;
[0040]
图3为本发明实施例中提供的数据中需求终点分布图;
[0041]
图4为本发明实施例中提供的上车主站点位置计算结果图;
[0042]
图5为本发明实施例中提供的下车主站点位置计算结果图;
[0043]
图6位本发明提供的站点设计方法中的缓冲区分析原理图;
[0044]
图7为本发明实施例中提供的上车子站点位置计算结果图;
[0045]
图8为本发明实施例中提供的下车子站点位置计算结果图;
[0046]
图9为本发明实施例中提供的主、子站点路网位置计算结果图。
具体实施方式
[0047]
以下结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,所描述的实施例仅是本发明一部分实施例,并非全部实施例。基于本发明中的实施
例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0048]
参见图1,本发明实施例公开了一种定站不定线定制公交多层次站点设计方法,具体包括以下步骤:
[0049]
第一步,采集潜在需求数据,本实施例采用某工作日早高峰时段网约车订数据作为本实施例的潜在需求数据样本集;采集城市矢量地图和路网数据作为地图数据集。
[0050]
第二步,出行需求提取:提取或计算订单中出行需求信息,包括出行起、终点坐标、出发时间,空间坐标系统一为wgs 1984,需求起点、终点分布分别如图2和图3所示。
[0051]
第三步,主站点设计:
[0052]
s1:出行需求起、终点空间聚类:基于需求的起、终点经、纬度坐标,采取基于密度的噪声应用空间聚类算法(dbscan),以设计站点服务半径r和最小类簇需求数量minpts为参数,进行空间聚类,生成需求的起点簇和终点簇。其中服务半径r依据乘客步行距离设定为300米,最小需求数量minpt基于最小上座率对应的需求数量设定,本实施例选用18座公交车型,最小上座率本实施例设定为50%,因此设定参数minpts=18
×
50%=9。
[0053]
s2:计算主站点坐标:采用k-means聚类算法以每个聚类簇中需求的起、终点为样本,设定聚类数量k为1,计算得到的各聚类簇的质心坐标即为主站点坐标。得到的上、下车主站点空间分布分别如图4和图5所示,共生成32个上车主站点和31个下车主站点。
[0054]
第四步,子站点划分:
[0055]
s1:基于缓冲区分析计算各主站点服务区:先将各站点进行投影,投影坐标系设定为wgs 1984 web mercator auxiliary;为各主站点聚类簇中需求起点、终点生成圆形缓冲区,半径设定为站点服务半径r=300米,并将相同簇中的需求缓冲区进行融合(融合原理示意图见图6所示),得到的融合后的缓冲区面积即为各上、下车主站点的服务区域。
[0056]
s2:计算子站点数量:计算各主站点服务区域的面积a,并基于以下公式确定各主站点需求簇需要划分的子站点数量q:
[0057][0058]
其中,本实施例选取最小服务半径r为300米;π为圆周率,本实施例取 3.14;
[0059]
s3:子站点需求再聚类:采用k-means聚类算法,分别以每个需求聚类簇中的需求点为样本,设定聚类数量为k=q,聚类得到各主站点的q个子需求簇,并计算各个子需求簇的聚类中心坐标。本实施例计算得到子需求簇的聚类中心位置如图7和8所示,其中,图7为需求起点子需求簇的中心位置,图8为需求终点子需求簇的中心位置。生成的各需求簇的中心点位置即为上、下车备选站点位置,共生成153个上车子站点和154个下车子站点。
[0060]
第五步,站点去重:
[0061]
s1:分析需求起点和终点分别生成的上、下车子站点位置的空间分布,计算各个上车子站点与各个下车子站点的距离,将站点间距小于最大服务半径r=300 米的站点标识为待调整站点;
[0062]
s2:采用基于需求权重的中心坐标计算方法将待调整站点进行合并:
[0063]
假设两聚类中心点坐标c1(x1,y1)和c2(x2,y2),两聚类中心权重分别为α1和α2,合并后的聚类中心点坐标为:
[0064][0065]
其中,聚类中心权重按照各站点服务的需求数量确定,如c1站点服务10个上车需求,则该站点权重α1=10;站点c2服务7个下车需求,则该站点权重α2=7。本实施例中共有76对上、下车子站点相距小于最小服务半径r,合并后共得到231个子站点。
[0066]
第六步,计算子站点位置:将去重后生成的子站点投影至路网,得到最终定制公交上、下车站点的地理位置。
[0067]
将去重后的各子站点向最近的路段和路网节点进行投影,其中路网包含了主干路、次干路、支路构成的路网。得到的主站点和子站点位置如图9所示,其中五角星所在位置为主站点地理位置,图钉形所在位置为各子站点地理位置。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1