一种基于FlinkSQL的SQL一致性状态恢复装置的制作方法
一种基于flinksql的sql一致性状态恢复装置
技术领域
1.本发明涉及支付,金融领域,特别涉及一种基于flinksql的sql一致性状态恢复装置。
背景技术:
2.在流计算场景中,数据没有边界源源不断的流入的,每条数据流入都可能会触发计算,比如在进行count或sum这些操作,选择每次触发计算将所有流入的历史数据重新计算,如果遇到网络中断,对应的上次计算结果就会丢失,在节点恢复时,是需要将所有历史数据重新计算一遍的,这样比较消耗计算资源。flink实时计算中采用了分布式快照的设计方案解决了运行计算任务的过程中见计算结果存储问题。在整个任务运行的过程中,中间存在着多个临时状态,比如说某些数据正在执行一个operator,但是只处理了一半数据,另外一般还没来得及处理,这也是一个状态。需要一种机制去保存记录执行过程中的中间状态,这种机制就是状态管理机制。
3.flink是可以通过设置计算函数节点的hash值来确保整个计算拓扑的一致性,来保障任务恢复的时候,函数节点能够从正确的位置获取到该函数的中间存储。但是当我们使用flinksql开发作业的时候,无法为flink作业设置计算函数的hash值,以及在多个sql任务同时运行在一个flinkjob中时,以及在多个sql作业有增删的时候,flinksql作业在失败恢复的时候不能够从指定的hash获取计算函数的中间状态。在这样的背景下,我们希望通过设计为不同sql的计算拓扑生成唯一的计算hash值,多个sql的hash相互隔离,来实现flinksql作业能够同时运行,以及任务之间的变更仍然能够保证新、老的sql任务能够获取到计算中间状态,保证计算的一致性。
技术实现要素:
4.本发明要解决的技术问题是克服现有技术的缺陷,提供一种基于flinksql的sql一致性状态恢复装置,通过对flinksql作业的计算拓扑,为sql的计算拓扑生成唯一设置计算函数hash值,固化整个计算拓扑的计算中间状态数据存储。来实现flinksql同时运行多个sql,sql的变更,删除,新增之间的分布式状态互不影响,来保证实时计算的数据一致性状态恢复。
5.本发明提供了如下的技术方案:
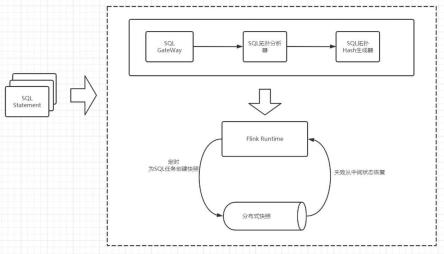
6.本发明提供一种基于flinksql的sql一致性状态恢复装置,该装置包含sql任务提交客户端,sqlgateway、sql拓扑分析器、sql拓扑hash生成器,flinkruntime计算引擎,主要流程如下所示:
7.(1)sql客户端提交多个sql任务到sqlgateway;
8.(2)sqlgateway对每条sql调用sql拓扑分析器,生成对应的flink计算拓扑;
9.(3)生成的计算拓扑交给sql拓扑hash生成器,为该拓扑生成唯一的hash值;
10.(4)sqlgateway把任务提交运行,在运行时的flink程序定期进行状态存储到外部
分布式存储系统中;
11.(5)在flinkruntime遇到异常进行容错恢复的时候,从分布式快照中加载对应的状态快照,然后根据计算的拓扑唯一hash值,进行获取状态,恢复计算结果。
12.与现有技术相比,本发明的有益效果如下:
13.现有的flinksql作业时不支持多个sql任务修改,从计算中间状态恢复也会出现脏数据。未变更的sql任务,也会出现恢复状态异常的情况。flinksql只推荐通过分开运行sql任务的方式,提交到不同的flinksql作业中来保障sql的修改隔离。但是这样会造成数据的消费冗余,计算节点资源浪费;本发明通过sql计算拓扑一致性hash值算法来固定计算拓扑的分布式状态,增强flinksql的任务隔离性,提升资源的利用率。
附图说明
14.附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例一起用于解释本发明,并不构成对本发明的限制。在附图中:
15.图1是本发明的整体架构图;
16.图2是本发明的任务恢复流程示意图;
17.图3是本发明的sql拓扑分析器,根据sql的语法树生成对应的计算拓扑,转换成flink的基础函数示意图;
18.图4是图3中计算拓扑生成了固定的、唯一的计算拓扑hash值示意图。
具体实施方式
19.以下结合附图对本发明的优选实施例进行说明,应当理解,此处所描述的优选实施例仅用于说明和解释本发明,并不用于限定本发明。其中附图中相同的标号全部指的是相同的部件。
20.实施例1
21.如图1-4,本发明提供一种基于flinksql的sql一致性状态恢复装置,该装置组件包括:sql任务网关,sql拓扑分析器,sql拓扑hash生成器。
22.1、sql任务网关接手用户提交的sql,提交给sql拓扑分析器为每一个sql生成对应的计算拓扑;
23.2、为整个sql计算拓扑的计算函数生成唯一hash值;
24.3、flinksql作业在新增sql任务时候,为新sql生成唯一拓扑hash,从指定的状态存储进行恢复作业计算。
25.该装置中的sql任务提交客户端,sqlgateway、sql拓扑分析器、sql拓扑hash生成器,flinkruntime计算引擎主要流程如下所示:
26.(1)sql客户端提交多个sql任务到sqlgateway;
27.(2)sqlgateway对每条sql调用sql拓扑分析器,生成对应的flink计算拓扑;
28.(3)生成的计算拓扑交给sql拓扑hash生成器,为该拓扑生成唯一的hash值;
29.(4)sqlgateway把任务提交运行,在运行时的flink程序定期进行状态存储到外部分布式存储系统中;
30.(5)在flinkruntime遇到异常进行容错恢复的时候,从分布式快照中加载对应的
状态快照,然后根据计算的拓扑唯一hash值,进行获取状态,恢复计算结果;
31.在flink中仅仅提供了基础算子的分布式快照功能,用户需要在编写flinkapi的程序中,手动设置对应的hash值,才能够让整个作业恢复。但是flink程序目前不支持flinksql任务的hash值的设定,并且在任务恢复的过程中会存在数据状态错乱的问题,流程如图2。
32.sql拓扑分析器,根据sql的语法树生成对应的计算拓扑,转换成flink的基础函数如图3。
33.在平台中sql代表了计算任务,即使相同的sql在不同的提交时间,也代表不同的计算任务,也有不同的计算状态,也就是我们需要在恢复的时候为它们生成不同的hash值。在此,我们引入sql_id。单个sql解析出来多个计算函数,并且计算拓扑是一个有向无环图的结构,我们给每一个计算函数引入了深度deep。因此我们为sql的分布式计算函数拓扑生成固定的hash值算法如下:
34.sql_hash=定长sql_id+md5(sql)
35.计算函数hash=sql_hash+deep+type
36.注:
37.1、sql_id是任务的唯一标识
38.2、md5(sql)是对sql取md5值
39.3、deep计算函数节点的深度
40.4、type计算函数的类型
41.由上述公式,我们为图3的计算拓扑生成了固定的、唯一的计算拓扑hash值,简要示例如下图4;
42.flink计算引擎在运行时,可以通过我们设定的计算函数hash值确定固定的分布式状态存储,从而保证计算状态恢复的一致性。
43.进一步的,本发明中包括以下特征:
44.1.sql计算拓扑函数计算状态一致性hash算法;
45.2.flinksql从指定的hash获取对应的计算函数状态保证数据一致性。
46.最后应说明的是:以上所述仅为本发明的优选实施例而已,并不用于限制本发明,尽管参照前述实施例对本发明进行了详细的说明,对于本领域的技术人员来说,其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1