一种基于语义分割的药物不良事件关系抽取方法
1.本发明涉及医学文本数据挖掘技术领域,具体涉及一种基于语义分割的药物不良事件关系抽取方法。
背景技术:
2.药物不良事件(adverse drug event,ade)是指药物治疗过程中出现的不良临床事件,它不一定与该药有因果关系。导致药物不良事件的原因主要有两个,一个是药品质量问题,另一个是用药错误。药物不良事件严重危害了患者的身体健康,并为整个医疗系统和社会带来巨大的经济损失。据统计,由于药物不良事件导致的紧急出诊率占总出诊率的28%,并且由于药物不良事件的重要性及其危害性,目前己受到生命科学、生物学以及综合医学等各个领域的科研工作者们的广泛关注。另外,尽管药物发现的最终目标是开发用于特定疾病治疗的化学药品,但是,认识到化学药品及其导致的不良药物反应的对应关系,对于提高化学安全性和毒性研究,以及促进新的药物化合物筛选方法至关重要。
3.经过研究工作者的长期探索,基于文本挖掘的药物不良事件研究技术己从早期的基于模板和规则的方法逐步发展成为以数据为导向的传统基于机器学习的方法,并在理论和实际研究中都取得了重大突破。此外,随着深度学习方法的兴起与发展,基于神经网络的深度学习框架也为文本挖掘方法提供了新的思路。由于神经网络模型能够通过大规模数据训练,自动地从原始数据中学习到数据内部特征,因此在语音和图像识别领域己经取得了突破性进展,在自然语言处理领域也表现出巨大的潜力。因此,基于深度学习的文本挖掘方法将成为未来研究发展的趋势。而利用基于深度学习的文本挖掘方法对药物不良事件进行研究,对促进生物医学相关研究的发展具有重大的价值和推动作用。
4.本技术的发明人经过研究发现,由于药物不良事件的特殊定义,从自然语言文本中识别出所有药物和不良事件提及并抽取出药物及其对应的不良事件关系具有以下问题:(1)随着生物医学领域药物研发进程的加快,在上市前的临床试验中,由于试验条件的限制,很多药物的不良事件很难被发现并列在不良事件报告中;此外,由于一些药物不良事件在用药一段时间后才会出现,或者在特定的人群中出现,因此很多潜在不良事件无法被现有词典或数据库覆盖,仅依靠词典和规则方法很难找到这些潜在的药物不良事件提及;(2)同一个病征提及在不同语境下既可能是药物不良事件也可能是适应症,因此对药物不良事件提及的识别更加依赖于对上下文语义关系的理解,从而对具体的药物不良事件加以区分;(3)针对同一个药物不良事件没有统一的命名方式,同一种疾病可能有多种表达方式,此类问题会导致提及名称稀疏,在有限的标注语料集中难以得到充分学习,难以识别;(4)在一些自然语言文本中,经常用非医学术语表示药物不良事件,这种非医学术语经常与前后文的普通单词或者形容词相连来表示一个药物不良事件提及,因此难以判断药物不良事件提及的边界,从而造成识别不准确。
技术实现要素:
5.针对现有药物及其对应不良事件关系抽取存在的技术问题,本发明提供一种基于语义分割的药物不良事件关系抽取方法,该方法通过使用特殊符号在药物提及前后进行标记,并用悬浮标记将不良事件提及标注拼接在文本后面,以更好地识别药物和不良事件提及的边界;同时引入u形语义分割网络融合局部上下文信息来捕获药物不良事件之间的全局相互依赖性,从而能更精确的找到关键信息;另外运用一种平衡的softmax方法来处理不平衡关系分布,避免不相关提及三元组对对模型造成的影响,从而更精准的抽取出医学文本中的药物不良事件关系。
6.为了解决上述技术问题,本发明采用了如下的技术方案:
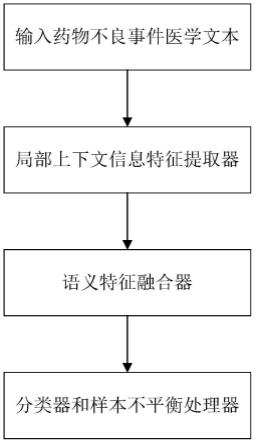
7.一种基于语义分割的药物不良事件关系抽取方法,包括以下步骤:
8.s1、药物不良事件关系抽取模型搭建:
9.药物不良事件关系抽取模型用于将医学文本中的药物及其造成的不良事件抽取出来,模型结构包括局部上下文信息特征提取器、语义特征融合器、分类器和样本不平衡处理器;其中,
10.所述局部上下文信息特征提取器用于从医学文本的输入中提取不同提及的局部上下文特征,具体包括:给定一个包含n个文本标记的药物不良事件文档首先在药物提及开头和结尾插入固定标记《s》和《/s》来标记药物提及位置,然后将对应的候选不良事件提及采用悬浮标记《o》和《/o》方式拼接在文本后面,其中《o》和《/o》与对应的不良事件提及为同一位置编码,接着将文本标记和插入的悬浮标记的组合序列提供给bert预训练模型,以获得药物提及标记局部上下文表示es和不良事件提及标记局部上下文表示eo,将es和eo拼接在一起作为对应药物提及与不良事件提及对嵌入表示其中m表示样本中药物提及与不良事件提及组成的最大提及对数,最后利用bert预训练模型获得注意力表示其中a是bert预训练模型最后一个encoder层中注意力头的平均值,利用来自bert预训练模型的注意力矩阵a以及仿射变换来获得药物和不良事件的提及对关系矩阵:
[0011][0012]
其中,是hadamard积,w1是可学习的参数矩阵,h为药物提及与不良事件提及对嵌入表示,as表示药物提及es对文档所有标记的注意力,通过平均药物提及最后一个encoder层中注意力头的平均值获得,ao表示不良事件提及eo对文档所有标记的注意力,通过平均不良事件提及最后一个encoder层中注意力头的平均值获得,f(s,o)表示药物和不良事件的提及对(es,eo)关系矩阵;
[0013]
所述语义特征融合器用于将局部上下文信息通过编码模块和u形语义分割网络来融合提及的全局依赖,具体包括:先将包含局部上下文信息的提及对关系矩阵f∈rm×m×d作为d通道图像,再结合一个编码模块,然后利用u形语义分割网络获取丰富的全局特征,u形语义分割网络包含顺序设置的全局特征提取块、两个带有跳跃连接的上采样块和特征输出层,从而获得局部上下文及全局依赖信息矩阵:
[0014]
y=u(w2f)
[0015]
其中,y∈rm×m×d'表示局部上下文及全局依赖信息矩阵,u∈rm×m×d'表示u形语义分割网络,w2是可学习的权重矩阵,以降低f的维数,且d'远小于d,w2f表示编码模块;
[0016]
所述分类器用于通过局部上下文及全局依赖信息矩阵和提及平滑嵌入表示来对药物不良事件关系进行预测,具体包括:先利用文挡中不同位置的提及局部上下文嵌入m,再利用最大池化的平滑版本获得同一个提及平滑嵌入表示ei:
[0017][0018]
其中,ei表示提及ei的平滑嵌入表示,表示文档中药物或不良事件提及ei总共出现的次数;
[0019]
在分别获得药物和不良事件平滑嵌入表示es和eo与局部上下文及全局依赖信息矩阵y后,分类器先利用前馈神经网络将es、eo、y映射到隐藏表示z,然后通过双线性函数获得关系概率,具体过程如下:
[0020]zs
=tanh(w
ses
+y
s,o
)
[0021]zo
=tanh(w
oeo
+y
s,o
)
[0022]
p(r|es,eo)=σ(zswrzo+br)
[0023]
其中,zs是药物隐藏表示,zo是不良事件隐藏表示,p是关系概率,y
s,o
是矩阵y中的药物和不良事件的提及对(es,eo)的局部上下文及全局依赖信息表示,tanh为非线性激活函数,σ为双线性函数,ws、wo、wr、br是可学习的参数矩阵;
[0024]
所述样本不平衡处理器用于通过引入一种平衡的softmax方法进行训练,并引入一个额外的类别0来处理样本集中类别不平衡问题,希望目标类别的分数都大于阈值t0,非目标类别的分数都小于阈值t0:
[0025][0026]
其中,l表示目标损失函数,log表示以e为底的对数,e表示常数,ti表示第i个正标签的概率,tj表示第j个负标签的概率,ωpos表示药物及其对应的不良事件提及关系即正标签,ωneg表示药物及其非对应的不良事件提及关系即负标签;
[0027]
s2、数据预处理,具体采用以下方法进行提及统一化处理:
[0028]
先将医学文本中的提及进行去停顿词处理,然后再进行正则化匹配,将正则化匹配度高于90%的提及归为同一个提及;
[0029]
s3、模型训练与参数优化:使用处理后的数据对抽取模型进行训练,设计目标优化函数优化网络参数,产生最优抽取模型,具体包括以下步骤:
[0030]
s31、将数据集按7:2:1比例划分为训练集、验证集和测试集;
[0031]
s32、采用平衡的softmax分类交叉熵损失函数作为优化目标,目标函数采用与步骤s1样本不平衡处理器中计算目标损失函数l相同的公式来实现;
[0032]
s33、采用随机梯度下降算法优化目标函数,运用误差反向传播更新网络模型参
数;
[0033]
s4、药物不良事件关系抽取:
[0034]
s41、将待抽取医学文本数据预处理,获得标准化后的样本数据,并将药物及其非对应的不良事件提及关系对类别定义为0;
[0035]
s42、对于一个医学样本及其包含的所有药物提及和不良事件提及,构成一条训练样本,在所有药物提及的前后直接插入《s》和《/s》两个固定标记,将不良事件提及用《o》和《/o》表示的悬浮标记的方式拼接在文本后面;
[0036]
s43、将样本送进bert预训练模型中,对于每一对药物和不良事件提及标记对,分别将药物提及标记局部上下文表示和不良事件提及标记局部上下文表示拼接在一起,作为对应药物提及与不良事件提及对嵌入表示;
[0037]
s44、在获得样本所有包含局部上下文信息的药物提及与不良事件提及对嵌入表示后,与bert预训练模型的注意力层做仿射变换来获得药物和不良事件的提及对关系矩阵;
[0038]
s45、将包含局部上下文信息的提及对关系矩阵结合一个编码模块,再利用u形语义分割网络获取丰富的全局特征,从而输出所有局部上下文及全局依赖信息矩阵;
[0039]
s46、获得药物和不良事件平滑嵌入表示,利用前馈神经网络将药物和不良事件平滑嵌入表示与局部上下文及全局依赖信息矩阵映射到隐藏表示,然后通过双线性函数获得关系概率即关系得分;
[0040]
s47、引入softmax方法计算正样本关系和负样本关系的得分,让正样本关系的得分都大于0。
[0041]
进一步,所述步骤s1语义特征融合器利用的u形语义分割网络中,全局特征提取块包括三个卷积模块和两个最大池化层,第一最大池化层位于第一卷积模块之后,第二最大池化层位于第二卷积模块之后,每个卷积模块包括两个卷积层,特征提取块中的通道数加倍;两个上采样块均包括顺序设置的反卷积层和两个卷积层,第一上采样块位于第三卷积模块之后,第二上采样块位于第一上采样块之后,每个上采样块中的通道数减半;第二上采样块中的反卷积层输出结果与第一卷积模块中的第二卷积层输出结果跳跃连接,第一上采样块中的反卷积层输出结果与第二卷积模块中的第二卷积层输出结果跳跃连接。
[0042]
进一步,所述每个卷积模块中两个卷积层的卷积核大小为3
×
3、步长为1,两个最大池化层的卷积核大小为2
×
2、步长为2,两个上采样块中反卷积层的卷积核大小为2
×
2、步长为2,两个卷积层的卷积核大小为3
×
3、步长为1,特征输出层的卷积核大小为1
×
1、步长为1。
[0043]
进一步,所述步骤s1样本不平衡处理器中,将阈值t0设为0,则计算目标损失函数l的公式简化如下:
[0044][0045]
与现有技术相比,本发明提供的基于语义分割的药物不良事件关系抽取方法具有以下有益效果:
[0046]
1、本发明在获取嵌入表示时,利用了悬浮标记表示,能更加有效的区分不同提及
嵌入表示,可显著提高预测准确率。
[0047]
2、利用了u形语义分割网络来捕获三元组(药物、不良事件、药物不良事件关系)之间的全局相互依赖关系,使抽取模型可以更加有效的处理提及对之间距离过长,无法找到关键信息的问题。
[0048]
3、引入了一个编码模块来捕获局部提及的上下文信息,并通过融合全局相互依赖关系,使抽取模型对全局语义有更充分地理解,从而能更好的区分具体的药物不良事件。
[0049]
4、利用一种平衡的softmax方法来处理关系分布不平衡问题,避免抽取模型出现“欠采样”的情况,从而提高关系分类的准确率。
附图说明
[0050]
图1是本发明提供的药物不良事件关系抽取系统流程示意图。
[0051]
图2是本发明提供的悬浮标记跨度示意图。
[0052]
图3是本发明提供的提及对关系矩阵示意图。
[0053]
图4是本发明提供的药物不良事件关系抽取网络结构示意图。
[0054]
图5是本发明提供的u形语义分割网络结构示意图。
具体实施方式
[0055]
为了使本发明实现的技术手段、创作特征、达成目的与功效易于明白了解,下面结合具体图示,进一步阐述本发明。
[0056]
请参考图1至图5所示,本发明提供一种基于语义分割的药物不良事件关系抽取方法,包括以下步骤:
[0057]
s1、药物不良事件关系抽取模型搭建:
[0058]
药物不良事件关系抽取模型用于将医学文本中的药物及其造成的不良事件抽取出来,模型结构包括局部上下文信息特征提取器、语义特征融合器、分类器和样本不平衡处理器;其中,
[0059]
所述局部上下文信息特征提取器用于从医学文本的输入中提取不同提及的局部上下文特征,具体包括:受益于悬浮标记的并行性,可以灵活地将一系列相关提及打包到一个训练实例中,给定一个包含n个文本标记(用于标注出文本中哪些字符属于普通字符,没有含义的,哪些字符属于药物或不良事件提及的字符)的药物不良事件文档如图2所示首先在药物提及开头和结尾插入固定标记《s》和《/s》来标记药物提及位置,然后将对应的候选不良事件提及采用悬浮标记《o》和《/o》方式拼接在文本后面,即将对应的不良事件提及用《o》和《/o》标记置于文本后面,其中《o》和《/o》与对应的不良事件提及为同一位置编码,即采用相同的位置编码来表示《o》和《/o》与对应的不良事件提及,接着将文本标记和插入的悬浮标记的组合序列提供给bert预训练模型,以获得药物提及标记局部上下文表示es和不良事件提及标记局部上下文表示eo,将es和eo拼接在一起作为对应药物提及与不良事件提及对嵌入表示其中m表示样本中药物提及与不良事件提及组成的最大提及对数,最后利用bert预训练模型获得注意力表示其中a是
bert预训练模型最后一个encoder层中注意力头的平均值,利用来自bert预训练模型的注意力矩阵a以及仿射变换来获得药物和不良事件的提及对关系矩阵:
[0060][0061]
其中,是hadamard积,w1是可学习的参数矩阵,h为药物提及与不良事件提及对嵌入表示,as表示药物提及es对文档所有标记的注意力,通过平均药物提及最后一个encoder层中注意力头的平均值获得,ao表示不良事件提及eo对文档所有标记的注意力,通过平均不良事件提及最后一个encoder层中注意力头的平均值获得,f(s,o)表示药物和不良事件的提及对(es,eo)关系矩阵,具体如图2所示;
[0062]
所述语义特征融合器用于将局部上下文信息通过编码模块和u形语义分割网络(见下表1)来融合提及的全局依赖,具体包括:先将包含局部上下文信息的提及对关系矩阵f∈rm×m×d作为d通道图像,即将文档级关系预测公式化为f中的像素掩码,为此利用u形语义分割网络获取丰富的全局特征,u形语义分割网络包含顺序设置的全局特征提取块(序号1~8)、两个带有跳跃连接的上采样块(序号9~14)和特征输出层(序号15);作为具体方式,全局特征提取块包括三个卷积模块和两个最大池化层,第一最大池化层位于第一卷积模块之后,第二最大池化层位于第二卷积模块之后,每个卷积模块包括两个卷积层,每个卷积模块中两个卷积层的卷积核大小为3
×
3、步长为1,两个最大池化层的卷积核大小为2
×
2、步长为2,特征提取块中的通道数加倍,具体第一卷积模块和第一最大池化层的通道数为64,第二卷积模块和第二最大池化层的通道数为128,第三卷积模块的通道数为256,提及对关系矩阵中的分割区域是指提及对之间关系的出现,u形语义分割网络可以促进感受野中提及对之间的信息交换,类似于隐式推理,具体来说,特征提取块可以扩大当前提及对嵌入f的感受野,从而为表示学习提供丰富的全局信息;两个上采样块均包括顺序设置的一个反卷积层和两个卷积层,第一上采样块位于第三卷积模块之后,第二上采样块位于第一上采样块之后,两个上采样块中反卷积层的卷积核大小为2
×
2、步长为2,两个卷积层的卷积核大小为3
×
3、步长为1,每个上采样块中的通道数减半,可以将聚合信息分布到每个像素,具体第一个上采样块中的通道数为128,,第二个上采样块中的通道数为64;第二上采样块中的反卷积层(序号12)输出结果与第一卷积模块中的第二卷积层(序号2)输出结果跳跃连接,第一上采样块中的反卷积层(序号9)输出结果与第二卷积模块中的第二卷积层(序号5)跳跃连接,由此以最后一个上采样块为例,它的特征不仅有来自第一个卷积模块的输出(同尺度特征),也有来自第一个上采样块的输出(大尺度特征),因而实现有效的将多尺度特征融合在了一起;特征输出层的卷积核大小为1
×
1、步长为1,且通道数为1。具体所述u形语义分割网络模型参数见下表1。
[0063]
表1全局依赖网络模型结构超参数表
[0064][0065][0066]
然后结合一个编码模块和u形语义分割网络来获得局部上下文及全局依赖信息矩阵y:
[0067]
y=u(w2f)
[0068]
其中,y∈rm×m×
d'
表示局部上下文及全局依赖信息矩阵,u∈rm×m×
d'
表示u形语义分割网络,w2是可学习的权重矩阵,以降低f的维数,且d'远小于d,w2f表示编码模块;
[0069]
所述分类器用于通过局部上下文及全局依赖信息矩阵和提及平滑嵌入表示来对药物不良事件关系进行预测,具体包括:同一个提及可能在文档中多次出现,因此先利用文挡中不同位置的提及局部上下文嵌入m,再利用最大池化的平滑版本获得同一个提及平滑嵌入表示ei:
[0070][0071]
其中,ei表示提及ei的平滑嵌入表示,表示文档中药物或不良事件提及ei总共出现的次数;
[0072]
在分别获得药物和不良事件平滑嵌入表示es和eo与局部上下文及全局依赖信息矩阵y后,分类器先利用前馈神经网络将es、eo、y映射到隐藏表示z,然后通过双线性函数获得关系概率,具体过程如下:
[0073]zs
=tanh(w
ses
+y
s,o
)
[0074]zo
=tanh(w
oeo
+y
s,o
)
[0075]
p(r|es,eo)=σ(zswrzo+br)
[0076]
其中,zs是药物隐藏表示,zo是不良事件隐藏表示,p是关系概率,y
s,o
是矩阵y中的
药物和不良事件的提及对(es,eo)的局部上下文及全局依赖信息表示,tanh为非线性激活函数主要用来做非线性变换,σ为双线性函数用来输出预测结果的概率值,ws、wo、wr、br是可学习的参数矩阵;
[0077]
所述样本不平衡处理器用于通过引入一种平衡的softmax方法进行训练,并引入一个额外的类别0来处理样本集中类别不平衡问题,希望目标类别的分数都大于阈值t0,非目标类别的分数都小于阈值t0:
[0078][0079]
其中,l表示目标损失函数,log表示以e为底的对数,e表示常数,ti表示第i个正标签的概率,tj表示第j个负标签的概率,ωpos表示药物及其对应的不良事件提及关系即正标签,ωneg表示药物及其非对应的不良事件提及关系即负标签;
[0080]
作为具体实施方式,为简化起见,将阈值t0设为0,则计算目标损失函数l的公式简化如下:
[0081][0082]
s2、数据预处理:医学文本中存在着同一个提及不同写法的情况,有的提及仅为首字母,有的提及为字母的缩写等情况,因而需要进行实体的提及名字统一化处理,具体采用以下方法进行提及统一化处理:
[0083]
先将医学文本中的提及进行去停顿词处理,然后再进行正则化匹配,将正则化匹配度高于90%的提及归为同一个提及。
[0084]
s3、模型训练与参数优化:使用处理后的数据对模型进行训练,设计目标优化函数优化网络参数,产生最优抽取模型,具体包括以下步骤:
[0085]
s31、将数据集按7:2:1比例划分为训练集、验证集和测试集;作为具体实施方式,本技术的发明人共获取了505个医学文档数据;
[0086]
s32、采用分类交叉熵损失函数作为优化目标,目标函数具体采用与步骤s1样本不平衡处理器中计算目标损失函数l相同的公式来实现,即目标函数如下:
[0087][0088]
s33、采用现有的随机梯度下降算法优化目标函数,运用误差反向传播更新网络模型参数。
[0089]
s4、药物不良事件关系抽取:
[0090]
s41、将待抽取医学文本数据预处理,获得标准化后的样本数据(参见数据预处理步骤),并将药物及其非对应的不良事件提及关系对类别定义为0;
[0091]
s42、对于一个医学样本及其包含的所有药物提及和不良事件提及,构成一条训练样本,其中药物提及采用固定标记,也就是在所有药物提及的前后直接插入《s》和《/s》两个固定标记,将不良事件提及用《o》和《/o》表示的悬浮标记的方式拼接在文本后面;
[0092]
s43、将样本送进bert预训练模型中,对于每一对药物和不良事件提及标记对,分别将药物提及标记局部上下文表示和不良事件提及标记局部上下文表示拼接在一起,即分别将药物提及标记的表征和不良事件提及标记的表征拼接在一起,作为对应药物提及与不良事件提及对嵌入表示或表征;
[0093]
s44、在获得样本所有包含局部上下文信息的药物提及与不良事件提及对嵌入表示或表征后,与bert预训练模型的注意力层做仿射变换来获得药物和不良事件的提及对关系矩阵;
[0094]
s45、将包含局部上下文信息的提及对关系矩阵结合一个编码模块,再利用u形语义分割网络获取丰富的全局特征,从而输出所有局部上下文及全局依赖信息矩阵;
[0095]
s46、获得药物和不良事件平滑嵌入表示,利用前馈神经网络将药物和不良事件平滑嵌入表示与局部上下文及全局依赖信息矩阵映射到隐藏表示,然后通过双线性函数获得关系概率即关系得分;
[0096]
s47、引入softmax方法计算正样本关系和负样本关系的得分,让正样本关系的得分都大于0。
[0097]
与现有技术相比,本发明提供的基于语义分割的药物不良事件关系抽取方法具有以下有益效果:
[0098]
1、本发明在获取嵌入表示时,利用了悬浮标记表示,能更加有效的区分不同提及嵌入表示,可显著提高预测准确率。
[0099]
2、利用了u形语义分割网络来捕获三元组(药物、不良事件、药物不良事件关系)之间的全局相互依赖关系,使抽取模型可以更加有效的处理提及对之间距离过长,无法找到关键信息的问题。
[0100]
3、引入了一个编码模块来捕获局部提及的上下文信息,并通过融合全局相互依赖关系,使抽取模型对全局语义有更充分地理解,从而能更好的区分具体的药物不良事件。
[0101]
4、利用一种平衡的softmax方法来处理关系分布不平衡问题,避免抽取模型出现“欠采样”的情况,从而提高关系分类的准确率。
[0102]
最后说明的是,以上实施例仅用以说明本发明的技术方案而非限制,尽管参照较佳实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改或者等同替换,而不脱离本发明技术方案的宗旨和范围,其均应涵盖在本发明的权利要求范围当中。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1