一种自适应解决分布式系统中小文件的方案的制作方法
本发明涉及大数据实时计算领域,特别涉及一种自适应解决分布式系统中小文件的方案。
背景技术:
1、structured streaming是业界具有低处理时延、高吞吐量的分布式实时计算框架。目前业务中常见一种应用场景是structured streaming消费kafka 消息中间件的数据,经过etl清洗后将结果数据存储在hdfs文件系统中,其处理模型如图1所示:
2、kafka partitions==structured streaming parallelism,一个spark task实例读取一个kafka分区数据。基于structured streaming的微批处理模式,在time1,streaming batch1中的task1、task2、task3将结果分别写入到hdfs分布式存储系统file0-1、file0-2、file0-3中;同理,在time2 streaming batch2中三个task分别将结果写入到文件file 1-1、file1-2、 file1-3中,以此类推。在此计算模式下,随着时间的推移,对于设置较大并行度(较多task个数)、较小批处理时间(batch interval较小)的structuredstreaming应用将会产生大量的小文件(hdfs数据块默认大小是128m,文件大小为kb一般定义为小文件)。而大量的小文件将会导致hdfs namenode内存溢出,影响集群稳定性。
3、在实际的业务处理中,常见的解决方案是增大structured streaming batchinterval,也就是降低写入hdfs文件系统的频率,但缺点是数据时效性降低。
技术实现思路
1、本发明要解决的技术问题是克服现有技术的缺陷,提供一种自适应解决分布式系统中小文件的方案,减少structured streaming产生过多的小文件对hdfs文件系统的影响,同时提高数据时效性。
2、本发明提供了如下的技术方案:
3、本发明提供一种自适应解决分布式系统中小文件的方案,具体包括以下步骤:
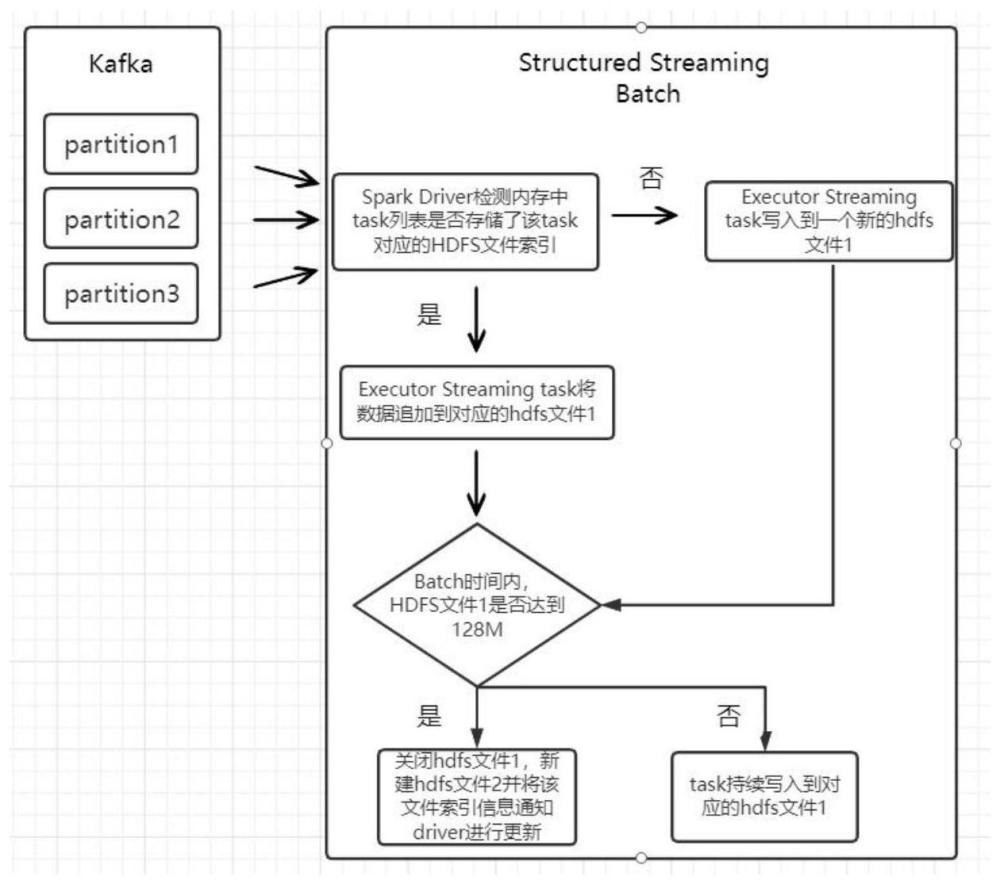
4、(1)structured streaming driver检测内存中task列表是否存储了该 task对应的hdfs文件索引;
5、(2)若是,则driver通知executor中的task将本批次内该task处理的数据追加到对应的文件中;否则executor中的task新建一个hdfs文件并将后续数据写入;
6、(3)在structured streaming batch时间段内,task周期性判断文件是否达到128m;若是,则关闭当前hdfs文件1并新建hdfs文件2并将该文件索引信息通知driver进行更新;batch时间结束,每个streaming task关闭对应的hdfs文件,并等待下一个批次的driver调度运行。
7、与现有技术相比,本发明的有益效果如下:
8、本发明减少了structured streaming产生过多的小文件对hdfs文件系统的影响,同时提高数据时效性。
技术特征:
1.一种自适应解决分布式系统中小文件的方案,其特征在于,具体包括以下步骤:
技术总结
本发明公开了一种自适应解决分布式系统中小文件的方案,具体包括以下步骤:(1)Structured Streaming Driver检测内存中task列表是否存储了该task对应的HDFS文件索引;(2)若是,则driver通知Executor中的task将本批次内该task处理的数据追加到对应的文件中;否则Executor中的task新建一个hdfs文件并将后续数据写入;(3)在Structured StreamingBatch时间段内,task周期性判断文件是否达到128M;若是,则关闭当前hdfs文件1并新建hdfs文件2并将该文件索引信息通知driver进行更新;Batch时间结束,每个Streaming task关闭对应的hdfs文件,并等待下一个批次的driver调度运行。本发明减少了Structured Streaming产生过多的小文件对HDFS文件系统的影响,同时提高数据时效性。
技术研发人员:请求不公布姓名,请求不公布姓名,请求不公布姓名
受保护的技术使用者:天翼电子商务有限公司
技术研发日:
技术公布日:2024/3/11
- 还没有人留言评论。精彩留言会获得点赞!