用于多维对话行动选择的强化学习代理的制作方法
本文中描述的实施例总体上涉及一种用于在对话系统中产生响应的方法和装置。
背景技术:
1、对话系统,例如面向任务的口语对话系统(sds),包括可以连续地与人类进行交互以通过言语的使用来帮助人类实现任务的系统。这些任务可以包括信息搜索、客户支持、电子商务、物理环境控制和人类-机器人交互。
2、对话系统可以包括通过将关于当前的和先前的用户输入(即,用户轮次turn))的信息和系统输出(即,系统轮次)合并到“对话状态”中来跟踪在对话中发生了什么的组件。
3、对话系统的动作选择组件基于对话策略和对话状态从固定的动作集合选择动作。
4、对话内的话语通常具有多于一个的沟通功能。例如:将任务向前移动、给予和引出反馈、以及管理谁有权讲话(即,轮次管理)。具有多于一个的沟通功能的话语被称为多功能话语。iso 24617-2标注标准(annotation standard)被设计为支持多功能话语,并且定义包括多个维度的标注方案,每个维度专用于对话过程的不同的方面。
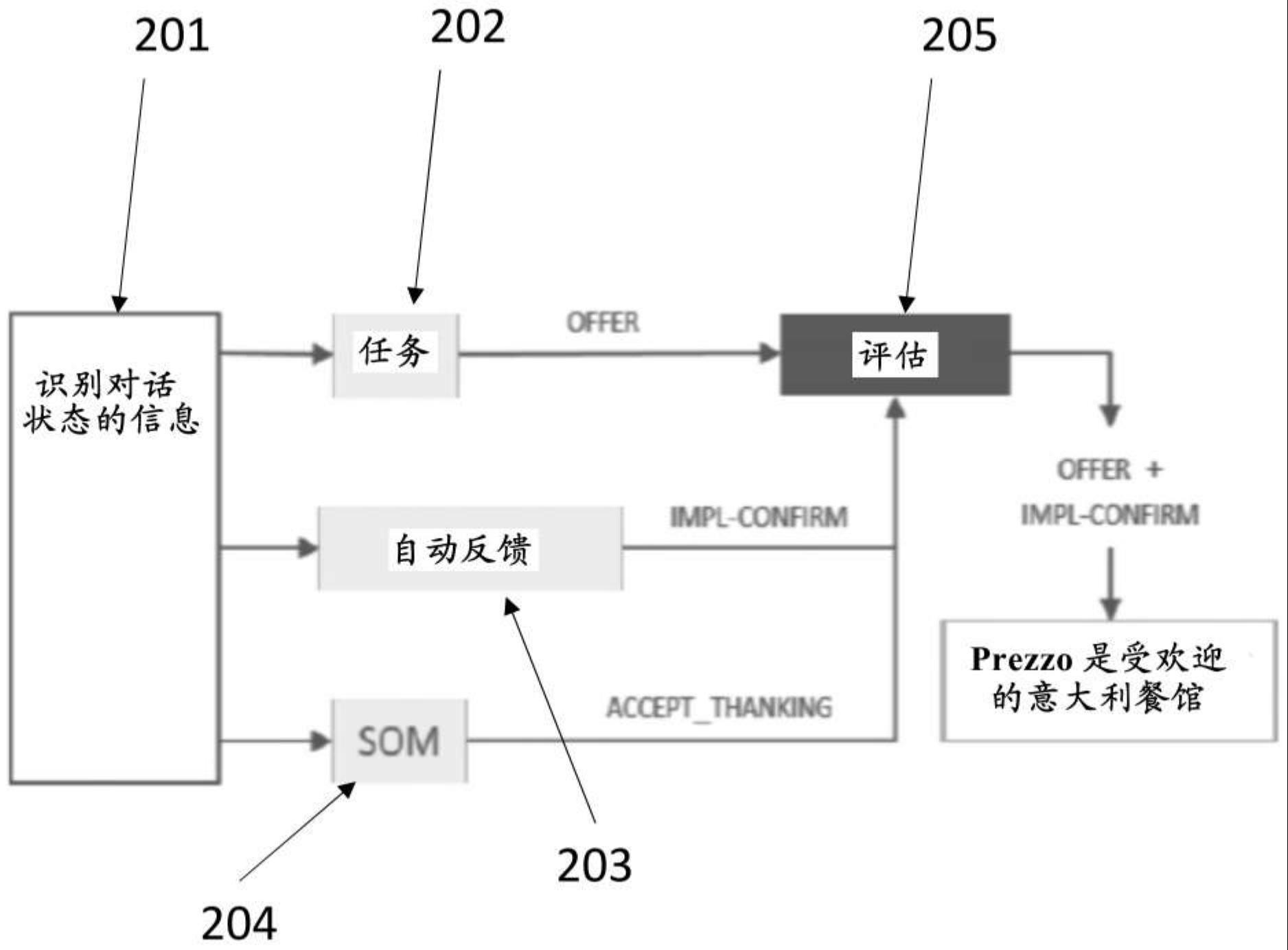
5、通过几个对话策略、而不是一个对话策略来驱动决策过程的多维对话系统已经被开发。该方法反映人类对话行为的多功能性质。在这种情况下,每个对话行动(da)代理具有它自己的具有动作集合的对话策略,并且每个对话行动(da)代理产生至少一个候选对话行动。
6、多功能话语需要来自若干不同维度的对话行动的组合。然而,一些维度不能被认为是充分地独立的。例如,来自不同维度的一些对话行动可能彼此冲突,使得它们中只有一个应被输出。因此,需要评估代理(ea)选择候选对话行动的最终组合。
技术实现思路
1、根据第一方面,提供一种用于在对话系统中产生响应的计算机实现方法,其中所述对话系统用于与用户进行对话。所述方法包括:从用户接收话语;基于所述话语更新对话状态;产生识别所述对话状态的信息;第一对话行动代理使用第一机器学习模型和识别所述对话状态的信息从第一候选动作集合选择第一候选动作,其中所述第一候选动作集合与第一对话维度相关联;第二对话行动代理使用第二机器学习模型和识别所述对话状态的信息从第二候选动作集合选择第二候选动作,其中所述第二候选动作集合与第二对话维度相关联;评估代理使用第三机器学习模型、所述第一候选动作和所述第二候选动作来选择输出动作,其中所述输出动作包括:所述第一候选动作和/或所述第二候选动作的组合;以及基于所述输出动作来产生系统响应。
2、在实施例中,所述对话系统包括用于接收所述话语的麦克风。
3、在实施例中,所述对话系统包括扬声器,所述方法进一步包括经由扬声器输出所述系统响应。
4、在实施例中,所述输出动作包括所述第一候选动作和所述第二候选动作。
5、在实施例中,所述输出动作包括所述第一候选动作或所述第二候选动作。
6、在实施例中,所述输出动作不包括所述第一候选动作和所述第二候选动作,优选地其中所述输出动作指示没有响应将被产生。
7、在实施例中,使用单个相同的奖励信号来独立地训练所述第一机器学习模型、所述第二机器学习模型和所述第三机器学习模型。
8、在实施例中,所述第一机器学习模型实现第一对话策略,所述第二机器学习模型实现第二对话策略,并且所述第三机器学习模型实现第三对话策略。
9、在实施例中,所述自然语言产生器是基于模板的自然语言产生器。
10、在实施例中,所述对话状态包括数据结构,所述数据结构包括在所述系统和所述用户之间的对话期间已经被提及的项。
11、在实施例中,每个对话维度与所述对话过程的不同的方面相关联,并且与用于对所述对话过程的所述方面做出响应的多个动作相关联。
12、在实施例中,对话维度包括根据iso 25617-2标注标准定义的维度。
13、在实施例中,识别所述对话状态的信息是所述对话状态。
14、在实施例中,识别所述对话状态的信息是从所述对话状态提取的特征集合。
15、在实施例中,产生识别所述对话状态的信息包括:产生识别所述对话状态的信息的第一实例;产生识别对话状态的信息的第二实例;并且其中基于识别所述对话状态的信息的第一实例来选择所述第一候选动作;以及基于识别所述对话状态的信息的第二实例来选择所述第二候选动作。
16、在实施例中,识别所述对话状态的信息的第一实例和识别所述对话状态的信息的第二实例包括不同的对话状态特征集合。
17、在实施例中,所述系统响应由自然语言产生器产生。
18、在实施例中,所述系统响应是话语。
19、在实施例中,选择所述输出动作包括:产生值矢量,所述值矢量包括对于所述第一候选动作和/或所述第二候选动作的每个组合的、在给定所述对话状态下与选择相应的组合作为所述系统响应相关联的估计的累积奖励的指示;以及基于所述值矢量来选择所述输出动作。
20、在实施例中,使用通过第一可训练权重集合而被参数化的函数来产生所述值矢量,其中所述函数的输入是识别所述对话状态的信息,所述函数的输出是对于每个组合的估计的累积奖励。
21、在实施例中,所述函数是线性函数。
22、在实施例中,所述第三机器学习模型包括被配置为实现所述线性函数的线性层。
23、在实施例中,使用(人工)神经网络来实现所述线性层。
24、在实施例中,基于所述值矢量来选择所述输出动作包括:将所述值矢量转换为概率分布以产生动作概率矢量;以及基于所述动作概率矢量来选择所述输出动作。
25、在实施例中,通过将softmax函数应用于所述值矢量来将所述值矢量转换为概率分布。
26、在实施例中,所述概率分布是规范化概率分布。
27、在实施例中,将所述值矢量转换为所述概率分布以产生所述动作概率矢量包括:将所述值矢量转换为经转换的动作值矢量,其中所述经转换的动作值矢量包括大于或等于零的值;通过基于预定准则将所述经转换的动作值矢量中的第一动作值设置为等于零来形成掩蔽的经转换的动作值矢量;以及使所述掩蔽的经转换的动作值矢量规范化以形成所述动作概率矢量。
28、在实施例中,所述经转换的动作值矢量仅包含大于或等于零的值。
29、在实施例中,掩蔽概率矢量由掩蔽层形成,所述掩蔽层被配置为采取所述经转换的动作值矢量作为输入,并且提供所述掩蔽概率矢量作为输出。
30、在实施例中,所述预定准则包括以下中的至少一个:无意义的组合的列表,和/或不被下游组件(诸如自然语言产生器)支持的组合的列表。
31、在实施例中,将所述第一动作值设置为等于零使所述第一候选动作和/或所述第二候选动作的组合禁用。
32、在实施例中,所述第一对话维度不同于所述第二对话维度。
33、在实施例中,所述用户是人类用户。
34、在实施例中,所述对话系统包括麦克风,并且从所述用户接收所述话语包括:产生经由所述麦克风接收的人类言语的表示。
35、在实施例中,基于所述话语和所述对话状态的前一个实例来更新所述对话状态。
36、在实施例中,所述对话系统包括扬声器,并且所述方法进一步包括经由所述扬声器输出所述系统响应,以使得所述系统响应可以被所述用户听到。
37、根据第二方面,提供一种用于训练对话系统的计算机实现方法,所述方法包括:根据上述方法产生系统响应;将所述系统响应提供给所述用户;以及使用强化学习来训练所述第一机器学习模型、所述第二机器学习模型和所述第三机器学习模型。
38、在实施例中,所述用户是模拟用户。
39、在实施例中,使用强化学习来训练所述第一机器学习模型、所述第二机器学习模型和所述第三机器学习模型包括:确定累积奖励;以及基于所述累积奖励来训练所述第一机器学习模型、所述第二机器学习模型和所述第三机器学习模型。
40、在实施例中,使用具有线性值函数逼近的monte cario(蒙特卡罗)控制来训练所述第一机器学习模型、所述第二机器学习模型和所述第三机器学习模型。
41、在实施例中,单独地训练所述第一机器学习模型、所述第二机器学习模型和所述第三机器学习模型。
42、在实施例中,所述累积奖励是在提供所述系统响应和完成所述对话之间获得的单个的奖励的总和。
43、在实施例中,所述第一机器学习模型被配置为基于通过第一可训练权重集合而被参数化的第一函数来估计对于所述第一候选输出动作的第一估计累积奖励;并且其中:基于所述累积奖励来训练所述第一机器学习模型包括:确定所述累积奖励和所述第一估计累积奖励之间的差异;以及基于所述差异来更新所述第一可训练权重集合。
44、在实施例中,所述差异是均方误差。
45、在实施例中,更新所述第一可训练权重集合包括:使用梯度下降并且基于所述差异来确定所述第一权重集合中的每个权重的权重变化。
46、在实施例中,更新所述第一可训练权重集合以使所述累积奖励(即,“真实的”累积奖励)和所述第一估计累积奖励之间的差异最小化。
47、在实施例中,所述第三机器学习模型被配置为基于通过第二可训练权重集合而被参数化的第二函数来估计对于所述输出动作的第二估计累积奖励;并且基于所述累积奖励训练所述第三机器学习模型包括:确定所述累积奖励和所述第二估计累积奖励之间的差异;以及基于所述差异来更新所述第二可训练权重集合。
48、在实施例中,所述累积奖励基于奖励的总和,所述奖励的总和包括为提供所述系统响应而产生的第一奖励。
49、在实施例中,所述第一奖励包括第一分量和第二分量的总和,其中所述第一分量提供惩罚以阻拦长对话,所述第二分量提供完成预定义目标的奖励。
50、在实施例中,所述方法进一步包括:响应于提供所述系统响应,接收第二话语;根据用于在对话系统中产生响应的所述方法来产生第二系统响应,其中用于在对话系统中产生响应的所述方法中的话语是所述第二话语,并且通过用于在对话系统中产生响应的所述方法产生的系统响应是所述第二系统响应;基于所述第二系统响应来产生第二奖励;基于所述第一奖励和所述第二奖励的总和来计算所述累积奖励。
51、在实施例中,所述第一奖励和所述第二奖励的总和是折扣总和,以使得所述总和中的第二奖励的值按折扣因子减少。
52、在实施例中,所述对话系统包括被配置为控制以下对话策略的探究量的第一超参数:所述第一机器学习模型实现的第一对话策略、所述第二机器学习模型实现的第二对话策略、以及所述第三机器学习模型实现的第三对话策略,并且其中:所述第一超参数在第一对话期间具有第一值,所述第一对话包括所述话语和所述系统响应,所述方法进一步包括:确定所述第一对话是否完成,并且响应于确定所述第一对话完成:修改所述第一超参数以使得所述第一对话策略、所述第二对话策略和所述第三对话策略在状态-动作空间内的探究量小于所述第一对话期间的探究量;以及用第二对话重新训练所述对话系统。
53、在实施例中,所述第一机器学习模型、所述第二机器学习模型和所述第三机器学习模型每个都包括转换层,所述转换层被配置为将动作值矢量转换为经转换的动作值矢量,其中根据温度超参数来控制所述转换层,并且其中修改所述第一超参数包括减小所述温度超参数的值,以使得它更接近于1。
54、在实施例中,使用独热(one-hot)编码来表示所述第一机器学习模型的输出。
55、在实施例中,所述第一机器学习模型的输出包括第一矢量,其中所述第一矢量包括多个条目,其中每个条目与第一动作集合中的不同的动作相关联,并且其中与所述第一候选动作相关联的条目包括指示所述候选动作已经被所述第一机器学习模型选择的信息,并且所述多个条目中的其他条目包括指示与所述其他条目相关联的候选动作尚未被所述第一机器学习模型选择的信息。
56、根据第三方面,提供一种用于在对话系统中产生响应的装置,其中所述对话系统用于与用户进行对话,所述装置被配置为:从用户接收话语;基于所述话语更新对话状态;产生识别所述对话状态的信息;第一对话行动代理使用第一机器学习模型和识别所述对话状态的信息从第一候选动作集合选择第一候选动作,其中所述第一候选动作集合与第一对话维度相关联;第二对话行动代理使用第二机器学习模型和识别所述对话状态的信息从第二候选动作集合选择第二候选动作,其中所述第二候选动作集合与第二对话维度相关联;评估代理使用第三机器学习模型、所述第一候选动作和所述第二候选动作来选择输出动作,其中所述输出动作包括:所述第一候选动作和/或所述第二候选动作的组合;以及基于所述输出动作来产生系统响应。
57、在实施例中,所述装置在选择所述输出动作时被进一步配置为:产生值矢量,所述值矢量包括对于所述第一候选动作和/或所述第二候选动作的每个组合的、在给定所述对话状态下与选择相应的组合作为所述系统响应相关联的估计的累积奖励的指示;以及基于所述值矢量来选择所述输出动作。
58、在实施例中,所述装置被进一步配置为使用通过第一可训练权重集合而被参数化的函数来产生所述值矢量,其中所述函数的输入是识别所述对话状态的信息,所述函数的输出是对于每个组合的估计的累积奖励。
59、在实施例中,所述函数是线性函数。
60、在实施例中,所述装置在基于所述值矢量来选择所述输出动作时被进一步配置为:将所述值矢量转换为概率分布以产生动作概率矢量;以及基于所述动作概率矢量来选择所述输出动作。
61、在实施例中,所述装置在转换所述值矢量时被进一步配置为:将所述值矢量转换为经转换的动作值矢量,其中所述经转换的动作值矢量包括大于或等于零的值;通过基于预定准则将所述经转换的动作值矢量中的第一动作值设置为等于零来形成掩蔽的经转换的动作值矢量;以及使所述掩蔽的经转换的动作值矢量规范化以形成所述动作概率矢量。
62、在实施例中,所述第一对话维度不同于所述第二对话维度。
63、根据第四方面,提供一种用于训练对话系统的训练系统,所述训练系统包括以上所讨论的用于在所述对话系统中产生响应的装置,所述训练系统被配置为:使用以上所讨论的用于在所述对话系统中产生响应的装置来产生系统响应;将所述系统响应提供给所述用户;以及使用强化学习来训练所述第一机器学习模型、所述第二机器学习模型和所述第三机器学习模型。
64、在实施例中,所述训练系统在使用强化学习来训练所述第一机器学习模型、所述第二机器学习模型和所述第三机器学习模型时被进一步配置为:确定累积奖励;以及基于所述累积奖励来训练所述第一机器学习模型、所述第二机器学习模型和所述第三机器学习模型。
65、在实施例中,所述第一机器学习模型被配置为:基于通过第一可训练权重集合而被参数化的第一函数来估计对于所述第一候选输出动作的第一估计累积奖励;并且其中所述训练系统在基于所述累积奖励来训练所述第一机器学习模型时被进一步配置为:确定所述累积奖励和所述第一估计累积奖励之间的差异;以及基于所述差异来更新所述第一可训练权重集合。
66、在实施例中,所述第三机器学习模型被配置为:基于通过第二可训练权重集合而被参数化的第二函数来估计对于所述输出动作的第二估计累积奖励;并且其中所述训练系统在基于所述累积奖励训练所述第三机器学习模型时被进一步配置为:确定所述累积奖励和所述第二估计累积奖励之间的差异;以及基于所述差异来更新所述第二可训练权重集合。
67、在实施例中,所述累积奖励是基于奖励的总和,所述奖励的总和包括为提供所述系统响应而产生的第一奖励。
68、在实施例中,所述训练系统被进一步配置为:响应于提供所述系统响应,接收第二话语;使用以上所讨论的用于在对话系统中产生响应的所述装置来产生第二系统响应,其中所述装置接收的话语是所述第二话语,并且所述装置产生的系统响应是所述第二系统响应;基于所述第二系统响应来产生第二奖励;基于所述第一奖励和所述第二奖励的总和来计算所述累积奖励。
69、在实施例中,所述对话系统包括被配置为控制以下对话策略的探究量的第一超参数:所述第一机器学习模型实现的第一对话策略、所述第二机器学习模型实现的第二对话策略、以及所述第三机器学习模型实现的第三对话策略,并且其中:所述第一超参数在第一对话期间具有第一值,所述第一对话包括所述话语和所述系统响应,所述训练系统被进一步配置为:确定所述第一对话是否完成,并且响应于确定所述第一对话完成:修改所述第一超参数以使得所述第一对话策略、所述第二对话策略和所述第三对话策略在状态-动作空间内的探究量小于所述第一对话期间的探究量;以及用第二对话重新训练所述对话系统。
70、根据第五方面,提供一种非暂时性计算机可读介质,所述非暂时性计算机可读介质包括适合于供处理器执行的计算机程序指令,所述指令在被所述处理器执行时被配置为使所述处理器执行以上所讨论的方法。
- 还没有人留言评论。精彩留言会获得点赞!