一种基于机器学习模型算法的搜索排序方法与流程
1.本发明涉及机器学习技术领域,特别涉及一种基于机器学习模型算法的搜索排序方法。
背景技术:
2.除了传统的通用搜索引擎google、baidu、bing,大部分互联网垂直产品如电商、音乐、应用市场、短视频等也都需要搜索功能来满足用户的需求查询,相较于推荐系统的被动式需求满足,用户在使用搜索时会通过组织query来主动表达诉求,为此用户的搜索意图相对比较明确。但即便意图相对明确,要做好搜索引擎也是很有挑战的,需要考虑的点及涉及的技术无论在深度还是广度上都有一定难度。尤其对于电子商城来说,搜索占据了流量入口的80%,做好搜索系统尤其重要。一个基本的搜索系统大体可以分为离线挖掘和在线检索两部分,其中包含的重要模块主要有:item内容理解、query理解、检索召回、排序模块等,而现有的电商网站通常会构建自己的搜索系统,提高用户的搜索体验,但是针对搜索结果的排序方式时常会存在着用户的问题反馈。如何提供一种技术方案,可以为用户提高搜索结果的排序体验,是当前需要解决的技术问题。
技术实现要素:
3.本发明的目的旨在至少解决所述技术缺陷之一。
4.为此,本发明的目的在于提出一种基于机器学习模型算法的搜索排序方法,以解决背景技术中所提到的问题,克服现有技术中存在的不足。
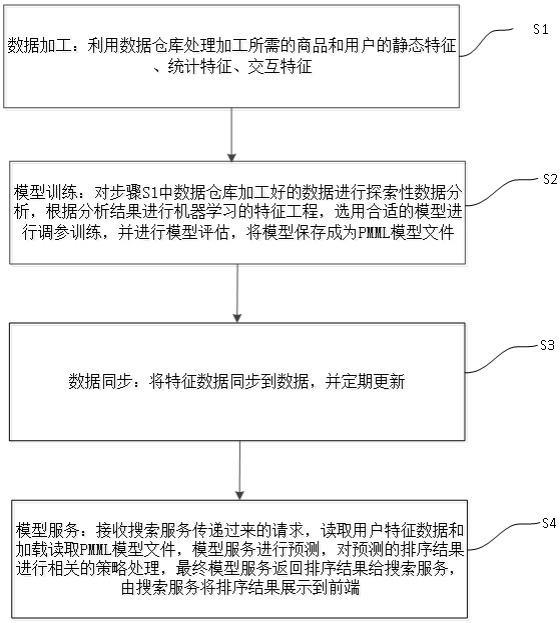
5.为了实现上述目的,本发明的实施例提供一种基于机器学习模型算法的搜索排序方法,包括:步骤s1,数据加工:利用数据仓库处理加工所需的商品和用户的静态特征、统计特征、交互特征;步骤s2,模型训练:对步骤s1中数据仓库加工好的数据进行探索性数据分析,根据分析结果进行机器学习的特征工程,选用合适的模型进行调参训练,并进行模型评估,将模型保存成为pmml模型文件;步骤s3,数据同步:将特征数据同步到数据,并定期更新;步骤s4,模型服务:接收搜索服务传递过来的请求,读取用户特征数据和加载读取pmml模型文件,模型服务进行预测,对预测的排序结果进行相关的策略处理,最终模型服务返回排序结果给搜索服务,由搜索服务将排序结果展示到前端。
6.由上述任一方案优选的是,在所述步骤s2中,采用离线指标进行模型评估,其中,所述离线指标包括:auc值、召回率和准确率。
7.由上述任一方案优选的是,在所述步骤s1中,采用hive 数据仓库分层提取数据,包括ods层、dim层、dwd层、dwi层、dws层和app层,所述数据仓库采用维度建模,将数据分主题抽象为维度表和事实表,使用事实表关联维度表,维度表之间互不关联;
其中,ods层是业务数据存储层,dim层是数仓维度表所在层,dwd层是数仓事实表所在层,dwi层是数据仓库轻度汇总层,dwi层数据来源于dim和dwd层,dws层是数据仓库汇总层;dws层数据来源于dwi层,app层是数据应用层。
8.由上述任一方案优选的是,所述数据仓库的模型为星型模型。
9.由上述任一方案优选的是,在所述步骤s2中,步骤s21,读取数据:使用jdbc方式连接hive,从hive数据仓库app层读取所需训练表数据并处理成dataframe类型。
10.步骤s22,即数据探索性分析eda,首先查看搜索排序数据的大小和行列数量,验证读取数据准确有效,查看各个特征的中值、均值、唯一值数量、每列特征的频度和特征间的相关性,根据查看结果在特征工程中对每列数据进行不同的处理;步骤s23,特征工程:删除单一值过多的特征,删除缺失值大于70%的特征。把object类型的数据值数量小于5的进行onehotencoder,大于5的使用labelencoder,将价格,数量相关的多个特征进行离散化处理;使用selectfrommodel进行特征选择,使得最终入模特征在100以内;步骤s24,模型训练:采用lr模型、xgboost模型或者xgboost+lr混合模型,进行模型训练,比较3个模型的得分,最终选用xgboost模型作为最终的训练模型,使用交叉验证,网格搜索方式进行超参数选择;步骤s25,模型评估:将数据集划分成训练集和测试集,采用训练集训练模型,采用测试集计算离线二分类评估指标;步骤s26,模型保存:将特征工程和模型统一成pipeline形式,保存为pmml文件,pmml文件跨环境使用模型,以供模型服务在java环境调用模型。
11.由上述任一方案优选的是,在所述步骤s23中,缺失值的处理方式包括对有实际含义的缺失值不进行处理,对于缺失值较少的列直接对缺失值进行删除;对较多的缺失值采用均值、中值、众数和插值方法进行填充;其中,异常值的处理方式包括对异常值进行替换填充,根据数据正常上下限,对超范围异常值进行删除。
12.由上述任一方案优选的是,在所述步骤s23中,特征选择方法包括以下三种:filter、wrapper和embedded。
13.由上述任一方案优选的是,在所述步骤s25中,auc值为0.68,召回率为0.66,准确率为0.7。
14.由上述任一方案优选的是,在所述步骤s4中,步骤s41,接收搜索服务请求:即前端发出请求到搜索服务,搜索服务使用elasticsearch全文搜索引擎进行搜索数据的召回,然后调用搜索排序模型服务进行排序,模型服务负责接收搜索服务请求;步骤s42,读取特征数据:根据搜索服务传递的参数,从postgresql数据库中读取所需特征数据;步骤s43,加载pmml模型文件:用第三方jpmml库将已经训练好的pmml模型文件加载到内存中;步骤s44,模型预测:用加载好的模型文件和统一格式的入参数据进行预测,并将预测结果进行排序,并打印日志;将预测的排序结果缓存到redis,并保留预设时长以减少
用户重复搜索时的压力;步骤s45,策略处理,包括:商品补全、配送区匹配、搜索关键词高亮、关联平台标签的商品数据不参与排序。
15.步骤s46,返回结果:将最终处理后的结果返回给搜索服务,由搜索服务统一返回给前端进行展示。
16.由上述任一方案优选的是,在所述步骤s42中,将分开读取的特征表合并成统一格式的模型入参数据。
17.根据本发明实施例的基于机器学习模型算法的搜索排序方法,通过用户和商品的静态属性,用户和商品统计属性,用户和商品的交互行为等数据,作为搜索结果的排序依据,对搜索结果进行排序,本发明为每个用户的搜索结果提供了个性化的排序,达到千人千面的效果,减少了用户重复搜索的次数,提高了用户的搜索结果排序体验。
18.本发明附加的方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到。
附图说明
19.本发明的上述和/或附加的方面和优点从结合下面附图对实施例的描述中将变得明显和容易理解,其中:图1为根据本发明实施例的基于机器学习模型算法的搜索排序方法的流程图;图2为根据本发明实施例的数据加工模块的流程架构图;图3为根据本发明实施例的模型训练模块的流程架构图;图4为根据本发明实施例的模型服务模块的流程架构图。
具体实施方式
20.下面详细描述本发明的实施例,所述实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,旨在用于解释本发明,而不能理解为对本发明的限制。
21.如图1所示,本发明实施例的基于机器学习模型算法的搜索排序方法,包括如下步骤:步骤s1,数据加工:利用数据仓库处理加工所需的商品和用户的静态特征、统计特征、交互特征。
22.具体的,利用数据仓库处理加工所需的商品和用户的静态特征、统计特征、交互特征。如图2所示,使用hive数据仓库分层提取数据,其中,hive底层存储使用hdfs,资源调度使用yarn,流程调度使用dolphinscheduler,hive 数据仓库分层提取数据,包括ods层,dim层,dwd层,dwi层,dws层,app层,数据仓库采用维度建模,将数据分主题抽象为维度表和事实表。本发明的数据仓库采用的数据模型是星型模型,使用事实表关联维度表,维度表之间互不关联。其中ods层是业务数据存储层,dim层是数仓维度表所在层,dwd层是数仓事实表所在层,dwi层是数据仓库轻度汇总层,dwi层数据来源于dim和dwd层,dws层是数据仓库汇总层。dws层数据来源于dwi层,app层是数据应用层。为方案中提供的训练表与预测表就在该层。
23.具体作用如下:ods层:业务数据存储层。从线上业务数据库中通过数据同步工具sqoop抽取数据,从神策日志数仓通过神策提供的数据导出方式导出数据,并使用hive命令导入到我们的数仓中。针对不同的表的加载策略包括增量加载,全量加载,增加和变化加载和单次加载。通过各种方式导入的数据存储在ods层,不做修改。
24.dim层:数仓维度表所在层。本发明所用到的维度表包括时间维度表,地区维度表,配送区维度表,用户维度表(包含研究所属性字段),商品维度表,商家维度表。dim层数据全部来自于ods层,除根据维度重新划分数据,对多来源的维度数据进行统一外,dim层的工作还包括对重复,空值,脏数据,超范围数据进行数据清洗。
25.dwd层:数仓事实表所在层,也称为数仓明细层。事实表由与维度表相关联的外键和数值型的度量值组成。本发明所用到事实表包括登录事实表,加购事实表,收藏事实表,订单事实表,订单详情事实表,商品点击事实表,搜索点击事实表。其中登录事实表,商品点击事实表,搜索点击事实表属于事务型事实表,加购事实表,收藏事实表属于周期型事实表,订单事实表属于累计型事实表,针对不同类型的事实表,采用不同的分区加载策略。dwd层数据也全部来源于ods层,dwd层的工作也是对多来源的事实表数据进行统一,并对空值,异常值数据进行清洗。
26.dwi层:数据仓库轻度汇总层,dwi层数据来源于dim和dwd层。是根据维度对事实表的度量值进行统一的轻度汇总,本发明中dwi层是按天汇总。轻度汇总的目的是为了其他重复的复杂汇总进行提前的计算,以空间换时间,提高计算效率。本发明中的轻度汇总表包括会员主题表,商家主题表,商品主题表。
27.dws层:数据仓库汇总层。dws层数据来源于dwi层,是对dwi层主题表的进一步汇总。dws主题表汇总基本用于即时查询,所以该层主题表分区保存两个即可。汇总层的特点是数据表会相对比较少,一张表会涵盖比较多的业务内容。dws层的主题表包括会员主题表,商家主题表,商品主题表。
28.app层:数据应用层,为数据仓库的后续应用,包括报表,推荐系统,搜索排序系统等提供最终版的数据表以供接口使用,是数据仓库的最终产出数据所在层。该层数据一般会通过数据导入工具sqoop直接导入到关系型数据库中供接口查询使用。
29.其涉及到相关表包括地区相关表,会员相关表,商品相关表,商家相关表,登录行为表,点击行为表,搜索点击行为表,订单提交行为表等。其涉及的相关字段如下:
表1 会员相关字段表
表2 商品相关字段表
表3 商家相关字段表表4 用户行为相关字段表步骤s2,模型训练:对步骤s1中数据仓库加工好的数据进行探索性数据分析,根据分析结果进行机器学习的特征工程,选用合适的模型进行调参训练,并进行模型评估,将模型保存成为pmml模型文件。选用合适的模型进行调参训练,使用auc值,召回率和准确率等离线指标进行模型评估,把模型保存成为pmml模型文件,如图3所示。
30.步骤s21,读取数据:使用jdbc方式连接hive,从hive数据仓库app层读取所需训练数据并处理成dataframe类型。根据后续分析结果删除无用特征。
31.步骤s22,eda:即探索性数据分析,首先查看搜索排序数据的大小,行列数量,验证读取数据准确有效。然后理解114个特征的业务含义,查看各个特征的中值,均值,唯一值数
量,每列特征的频度,特征间的相关性等,根据查看结果在特征工程中对每列数据进行不同的处理。查看label正负比为1:10,数据样本在均衡范围内,无需进行采样处理。还需查看每列数据类型,本训练数据共有int,float,object三种不同的数据类型,需要在特征工程种对object类型数据进行数值化。
32.步骤s23,特征工程:删除单一值过多的特征,删除缺失值大于70%的特征。把object类型的数据值数量小于5的进行onehotencoder,大于5的使用labelencoder,将价格,数量相关的多个特征进行离散化处理;使用selectfrommodel进行特征选择,使得最终入模特征在100以内。
33.对于其他有缺失值的特征采用众数填充,也可根据需求使用中位数,平均数或者插值法进行填充。把object类型的数据值数量小于5的进行onehotencoder,大于5的使用labelencoder,数值化的目的一是为了使不接受objec类型的模型接收数据,二是更好的挖掘数据中的信息。将价格,数量相关的多个特征进行离散化处理,使用等频分箱,离散化处理的目的也是使模型得到更多的信息,对线性模型提升较大。
34.使用selectfrommodel进行特征选择,使得最终入模特征为90个。特征工程使得数据符合模型要求,并可以更好的使模型得到有用的信息,提升模型效果。
35.步骤s24,模型训练:采用lr模型、xgboost模型或者xgboost+lr混合模型,进行模型训练,比较3个模型的得分,最终选用xgboost模型作为最终的训练模型,使用交叉验证,网格搜索方式进行超参数选择。
36.本发明中尝试使用逻辑回归模型,xgboost模型,xgboost+lr混合模型,进行模型训练,使用交叉验证,网格搜索方式进行超参数选择。其中,初始超参数使用默认参数或者经验参数周围数值进行搜索,最终确定使用xgboost模型,最佳参数为选取树数量为200棵,树深度为6,学习率为0.3。
37.步骤s25,模型评估:将数据集划分成训练集和测试集,用训练集训练模型,用测试集数据进行模型评价,本发明中使用xgboost模型进行二分类模型预测,离线二分类评估指标,包括混淆矩阵、auc、召回率、精确率、准确率和f1分数。本发明最终离线结果中auc为 0.68,召回率为0.66,准确率为0.7。符合上线要求。如离线效果不理想,需要继续优化,才可上线。
38.步骤s26,模型保存:将特征工程和模型统一成pipeline形式,pipeline 把多个模型&特征工程组合成一个模型。便于上线调用。pipeline和模型对象一样,可以进行训练、预测、评价、超参数搜索、持久化、部署。然后保存为pmml格式(pmml 是一种跨多语言平台的序列化格式,可以用来跨语言环境部署模型),以便于在java环境使得模型文件可以调用。
39.在本发明的实施例中,数据探索性分析主要对缺失值,重复值,异常值进行查看和处理。
40.特征工程中正负样本比均衡,无需进行数据采样。其中缺失值的处理方式包括对有实际含义的缺失值不进行处理,对于缺失值较少的列可以直接对缺失值进行删除,对数据影响不大。对较多的缺失值可以采用均值,中值,众数,插值等方法进行填充。
41.常值的处理方式包括对异常值进行替换填充,根据数据正常上下限,对超范围异常值进行删除。
42.数值化方法包括将有序类别型变量使用labelencode进行编码,对无序类别型变
量使用onehotencode编码,对高基数特征采用onehot+pca,labelencoder+大数,特征哈希,meanencoder等方式进行编码。
43.离散化可以分为连续数据离散化,连续数据二值化,连续数据离散化的方法包括等宽分箱,等频分箱,自定义分箱等。其中无量纲化也称为标准化、归一化 、中心化,其主要作用是:加快速度(梯度和矩阵为核心的算法中,譬如逻辑回归,支持向量机,神经网络),统一量纲,提升精度(在距离类模型,譬如k近邻,k-means聚类中),具体方法包括standardscaler,minmaxscaler,maxabsscaler等。
44.在本发明的实施例中,特征选择方法包括3种类型的方法:1.filter:根据自变量和目标变量的关联来选择变量。包括方差选择法和利用相关性、卡方、互信息等指标进行选择。
45.2.wrapper:利用模型`coef_` 属性 或 `feature_importances_` 属性获得变量重要性,排除特征,一个模型多次迭代。
46.3.embedded:利用模型单独计算出每个特征和label的系数,设置阈值,删除特征。多个模型一次训练。其中方差选择法和单变量特征选择属于filter,递归特征消除属于wrapper,selectfrommodel属于embedded。
47.在本发明的实施例中,模型最终采用xgboost模型,比较适用于本排序场景,通过模型得到的特征重要性进行了无用特征删除。
48.将之前对数据进行处理的特征工程和模型统一打包进pipeline,并将pipeline保存成pmml形式,以供模型服务进行调用。
49.步骤s3,数据同步:将特征数据从数仓同步到线上关系型数据库,并定时更新。
50.优选的,在本步骤中,将特征数据同步到postgresql数据库,并每日更新。
51.步骤s4,模型服务:搜索服务会发送请求给模型服务,模型服务接收搜索服务请求,模型服务读取特征数据。模型服务读取pmml模型文件,模型服务进行预测,模型服务进行相关的策略处理,模型服务返回结果,由搜索服务统一展示到前端,如图4所示。
52.步骤s41,接收搜索服务请求:即前端发出请求到搜索服务,搜索服务统一调度其他服务,首先搜索服务使用elasticsearch进行搜索数据的召回,然后调用搜索排序模型服务进行排序,传递参数为member_id 和 1000个 produce_id列表,模型服务负责接收搜索服务请求。
53.步骤s42,读取特征数据:根据搜索服务传递的参数,从线上数据库中读取所需特征数据,为了满足线上时效性的要求,不提前关联多个预测表,否则会导致预测表过大,查询缓慢,在真正查询时将分开读取的特征表合并成统一格式的模型入参数据。
54.步骤s43,加载pmml模型文件:用第三方jpmml库将已经训练好的pmml模型文件加载到内存中,只在服务启动的时候加载一次,后续使用加载进内存的pmml对象进行预测,不再进行加载。
55.步骤s44,模型预测:用加载好的模型文件和统一格式的入参数据进行预测,并将预测结果进行排序,并打印日志。将预测的排序结果缓存到redis,并保留1个小时以减少用户重复搜索时的压力。将预测结果打印日志以供后续分析。
56.步骤s45,策略处理:为了使经过排序的商品展示到前端,需要进行一些策略处理,包括商品补全,配送区匹配,搜索关键词高亮,关联平台标签的商品数据不参与排序等。
57.步骤s46,返回结果:将最终处理后的结果返回给搜索服务,由搜索服务统一返回给前端进行展示。
58.在本发明的实施例中,搜索服务是商城已经包含的最重要的服务之一,需要对搜索服务进行改造,使其不直接返回elasticsearch搜索结果,而是调用模型服务进行排序后再返回前端。
59.为了满足线上实时性的要求,对数据读取进行了优化,将特征宽表分成了多张表,并删除了其中对预测影响甚微的多列数据,还将排序结果直接缓存到redis,用户在分页查询时直接读取缓存数据即可。
60.pmml跨环境调用模型的本质是通过第三方jpmml库使用java来完成模型算法的调用及预测,使用pmml固定格式传递参数,以达到跨环境调用的目的。
61.搜索排序解决方案作为整个搜索引擎的一部分,其与搜索引擎的关系是位于搜索引擎query理解,elasticsearch结果召回,排序三个大模块的最后一部分,利用搜索召回结果最终返回精确排序。
62.根据本发明实施例的基于机器学习模型算法的搜索排序方法,通过用户和商品的静态属性,用户和商品统计属性,用户和商品的交互行为等数据,作为搜索结果的排序依据,对搜索结果进行排序,本发明为每个用户的搜索结果提供了个性化的排序,达到千人千面的效果,减少了用户重复搜索的次数,提高了用户的搜索结果排序体验。
63.在本说明书的描述中,参考术语“一个实施例”、“一些实施例”、
ꢀ“
示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不一定指的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任何的一个或多个实施例或示例中以合适的方式结合。
64.本领域技术人员不难理解,本发明包括上述说明书的发明内容和具体实施方式部分以及附图所示出的各部分的任意组合,限于篇幅并为使说明书简明而没有将这些组合构成的各方案一一描述。凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
65.尽管上面已经示出和描述了本发明的实施例,可以理解的是,上述实施例是示例性的,不能理解为对本发明的限制,本领域的普通技术人员在不脱离本发明的原理和宗旨的情况下在本发明的范围内可以对上述实施例进行变化、修改、替换和变型。本发明的范围由所附权利要求及其等同限定。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1