机器学习装置、机器学习方法以及推论装置与流程
这里描述的实施例总体上涉及机器学习装置、机器学习方法以及推论装置。
背景技术:
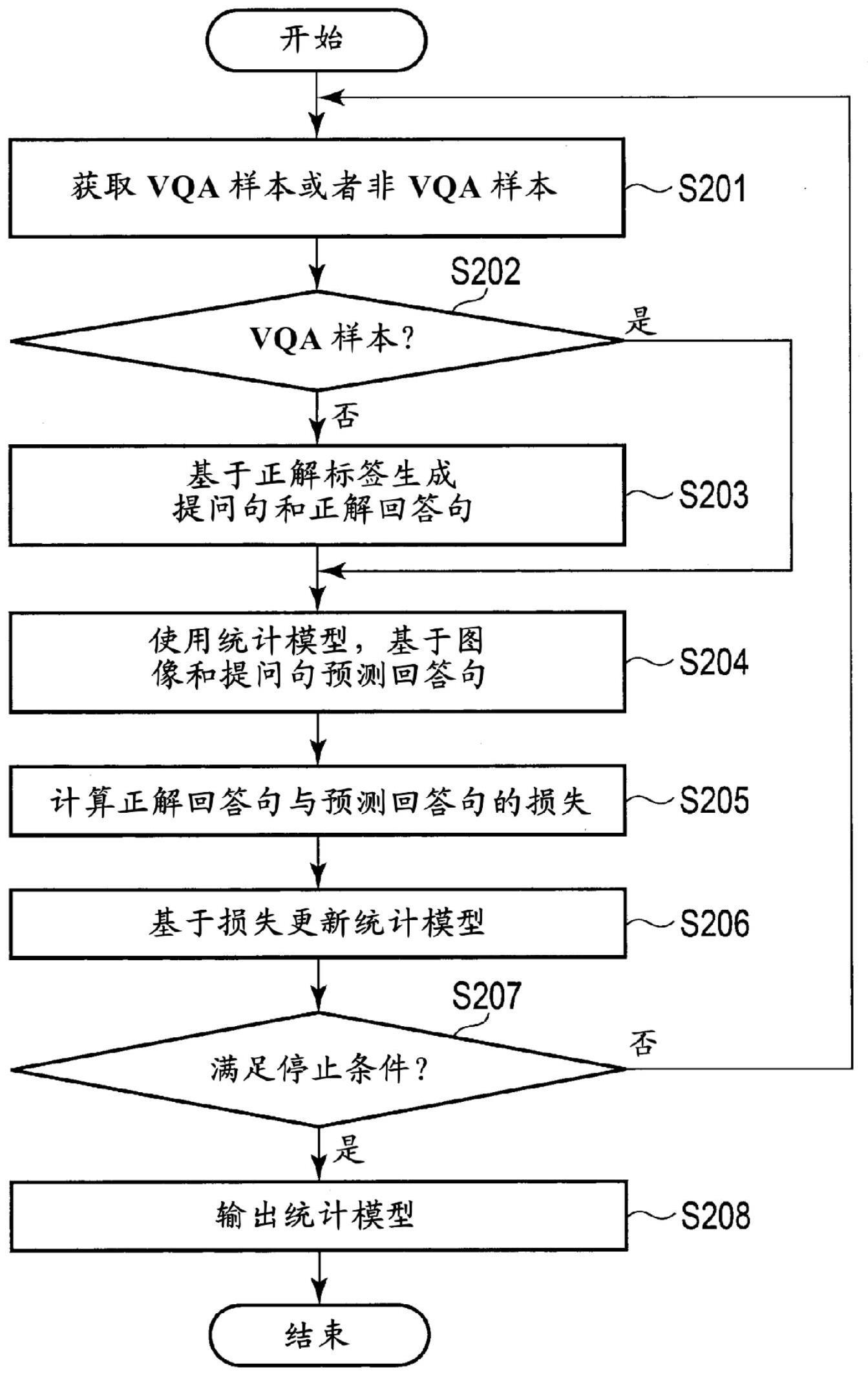
1、在机器学习的领域中,已知有输入图像和与该图像相关的文本形式的提问,输出针对该提问的文本形式的回答的任务。该任务被称为vqa(visual question answering,视觉问答)。vqa任务的统计模型基于作为图像、提问以及回答的组合(元组:taple)而被提供的学习数据集进行训练。在图像和与该图像相关的提问的组合中考虑庞大的变化,因此在被称为vqav2的vqa的学习数据集中,通过对几万个图像准备几十万个提问来确保变化。例如,当想要生成能够与固有的动植物、交通工具对应的统计模型时,需要准备与这些固有的对象物相关的图像和与这些图像相关的所有变化的提问和回答。如此,为了以多样的变化来准备由图像、提问以及回答的组合构成的学习数据集,需要庞大的成本。为了抑制成本,即使利用变化少的学习数据集训练统计模型,也无法生成精度良好的统计模型。期望能够以低成本生成高精度的统计模型的高效的学习。
技术实现思路
1、本发明要解决的课题是提供能够高效地学习vqa任务的统计模型的机器学习装置、机器学习方法以及推论装置。
技术特征:
1.一种机器学习装置,具备:
2.根据权利要求1所述的机器学习装置,其中,
3.根据权利要求2所述的机器学习装置,其中,
4.根据权利要求3所述的机器学习装置,其中,
5.根据权利要求1所述的机器学习装置,其中,
6.根据权利要求1所述的机器学习装置,其中,
7.根据权利要求1所述的机器学习装置,其中,
8.根据权利要求7所述的机器学习装置,其中,
9.根据权利要求1所述的机器学习装置,其中,
10.一种机器学习方法,包括:
11.一种推论装置,具备:
12.根据权利要求11所述的推论装置,其中,
13.根据权利要求11所述的推论装置,其中,
技术总结
提供一种机器学习装置、机器学习方法以及推论装置,能够高效地学习VQA任务的统计模型。机器学习装置包括处理电路。处理电路基于非VQA格式的样本,生成与VQA任务相关的VQA格式的学习样本。所述VQA格式的所述学习样本具有对象、与该对象相关的提问句以及针对该提问句的回答句的组合作为要素,所述非VQA格式的所述样本具有对象和与该对象相关联的标签的组合作为要素。处理电路基于所生成的所述VQA格式的所述学习样本训练所述VQA任务的统计模型。
技术研发人员:三岛直,Q·V·范,细矢悠介,藤村浩司
受保护的技术使用者:株式会社东芝
技术研发日:
技术公布日:2024/1/14
- 还没有人留言评论。精彩留言会获得点赞!