一种基于深度学习的活跃IPV6地址预测方法
一种基于深度学习的活跃ipv6地址预测方法
技术领域
1.本发明属于神经网络和ipv6地址预测技术领域,尤其是涉及一种基于深度学习的活跃ipv6地址预测方法。
背景技术:
2.ipv6已成为支撑未来工业互联网、物联网发展的基础,大规模ipv6网络部署不断涌现。ipv6庞大的地址空间
1.,为用户行为追踪溯源、网络精细管控提供了可能。研究人员通过探索全球ipv6地址,来提升对下一代互联网进行大范围评估的能力。随着网络和硬件的快速发展,以及zmap和masscan等扫描工具的出现,已经实现对全球ipv4地址空间的探索。然而ipv6拥有更大地址空间,传统的扫描方法难以胜任。因此如何实现全球ipv6地址扫描,是研究人员面临的一个挑战。
3.目前关于ipv6地址扫描的研究,第一点是挖掘已知ipv6地址的结构特征,分析潜在分布规律,推断聚类区域。第二点是设计地址生成算法,预测网络中可能出现的ipv6地址。随后将预测地址作为扫描的目标,来达到ipv6地址扫描的目的。
4.由于ipv6完全由字符组成,缺少语义信息,序列关系无法预测活跃ipv6地址。虽然已经设计出各种复杂的算法,但ipv6网络以下性质导致这些算法仍然面临挑战:
5.(1)ipv6寻址模式
6.网络管理员可以自由选择ipv6地址分配方案,实现地址中接口标识符(iid)多种分配模式。客户端可以使用无状态地址自动配置,从而产生伪随机或eui-64iid。而服务器和路由器分配地址,通常是根据管理员的习惯或采用dhcpv6方式。根据rfc 7136中的要求,这些模式是不透明的,导致算法推断困难。
7.(2)ipv6别名
8.已有的经验表明,大规模的别名地址是未来ipv6扫描中必须解决的问题,因为这些地址无条件地响应查询,不受设备唯一性约束。已有的算法仍需学习别名地址,导致消耗大量算力来生成低质量的地址。
技术实现要素:
9.针对上述问题,本发明提出利用语言模型和目标生成算法,来实现对潜在的活跃ipv6地址进行预测。本发明基于深度学习的方法,首先通过词向量空间映射,构建具有一定语义关系的ipv6向量空间;随后利用图神经网络构建语言模型,来估计词序列的概率分布,推断活跃地址的组成。
10.本发明的技术方案为:
11.一种基于深度学习的活跃ipv6地址预测方法,包括以下步骤:
12.s1、构建ipv6地址词序列,具体为:通过地址词来表示十六进制的ipv6地址的每一个nybble,定义ipv6地址中第i个nybble的值为vi,定义索引i为si,i为正整数且1≤i≤32,则将第i个地址词表示为visi,从而对每一个位置的nybble值在地址词中均单独赋予语义,
将整个ipv6地址的每一位nybble值转化为地址词,则构成一条ipv6地址的词序列;
13.s2、采用s1的方法对获取的所有ipv6地址集进行处理,根据获得的所有词序列构成词汇表,基于词汇表进行训练数据的构建,具体为:从一条词序列中选择一个地址词visi作为输入词,将visi前后的地址词作为背景词从而生成训练样本,选择背景词的范围是以visi作为中心并且窗口大小为5,即采用v
i-2si-2
、v
i-1si-1
、v
i+1si+1
、v
i+2si+2
作为背景词vi±nsi±n,获得的训练样本对为(visi,v
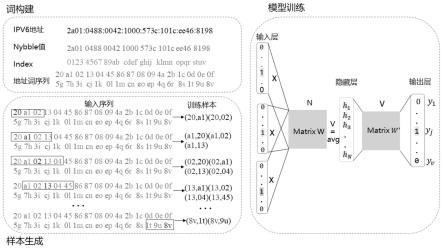
i-2si-2
)(visi,v
i-1si-1
)(visi,v
i+1si+1
)(visi,v
i+2si+2
),并且当作为背景词的地址词不存在时,对应的组合为空;对词汇表中的所有词序列进行训练数据的构建从而获得训练数据集;
14.s3、采用word2vec算法,将visi作为输入,背景词vi±nsi±n作为期望输出进行训练,并输出词向量;具体的:对每一个训练样本对(visi,vi±nsi±n),输入visi进入一个二层神经网络,输出s1中得到的词汇表中每个词的概率,再将背景词作为标签,采用logsoftmax损失函数进行训练,二层神经网络的隐藏层的参数矩阵的每一行ui与词汇表的每个词visi具有一一对应关系,待算法收敛后,将隐藏层的参数矩阵作为ipv6地址词的词向量编码矩阵输出,词向量编码矩阵记为u;
15.s4、采用gpt算法进行训练,将真实ipv6地址数据集的每条样本16位前缀按照s1的方式构成地址词序列{visi}作为输入,再采用s3中得到词向量矩阵u对输入种子集进行词向量编码,得到输入地址词向量序列{ui},剩下的16位后缀以同样的方式得到目标地址词向量序列{ui'},将{ui}输入gpt网络预测{ui'}以提升gpt网络的ipv6地址词预测能力;
16.s5、生成新的地址:将s4中得到的{ui}输入收敛的gpt网络中,根据余弦相似度生成采样概率分布,通过核心采样解码策略,将gpt网络输出的词与输入的词重新组合,生成一个新的地址,从而完成活跃ipv6地址的预测。
17.本发明的有益效果为:与其他目标生成方法相比,本发明生成的地址拥有更好的多样性,以及更高的活跃率。
附图说明
18.图1是ipv6地址样本示意图。
19.图2是add2vec的整体结构示意图。
20.图3是gpt-ipv6的整体结构示意图。
21.图4是greedy search与nucleus sampling生成地址词概率对比图。
22.图5是不同softmax温度t的地址预测结果示意图。
具体实施方式
23.下面结合附图来对本发明进行详细描述。
24.ipv6协议标准提出至今,ipv6的地址架构及其格式还在不断演进,新的分配方式也在不断涌现。rfc4291定义了基本的地址架构,ipv6地址由128位二进制数字组成,包括全局网络标识符、子网前缀和一个接口标识符。如图1所示,地址分为8组,每组包含4个十六进制数字,用冒号隔开。每个十六进制数字被称为一个nybble,ipv6地址通常使用::来代替连续的零值组,并省略每组中的第一个零值。
25.然而,ipv6地址并不是简单地由无意义的数字组成。ipv6有许多不同的寻址方案,
接口标识符语义不透明,管理员可以选择使用各种标准来自定义地址类型。此外,一些ipv6具有slaac地址格式,64位的iid通常根据eui-64标准嵌入mac地址,或者完全使用伪随机。参考图1中的样本地址,按照复杂程度递增,这些地址是:(1)一个具有固定iid值的地址(::3);(2)一个在低64位有结构化数值的地址(一个以:a区分的子网);(3)一个具有eui-64的slaac地址,基于ethernet-mac的id(ff:fe标志);(4)一个带有伪随机的slaac隐私地址。
26.由于ipv6地址语义不透明,还存在多种寻址方案,很难有效地进行模型训练。为了实现高效的地址生成算法,合理挖掘地址组合的语义信息尤为关键,于是通过构建地址词序列来生成ipv6语义。通过学习地址词序列模型的上下文,生成具有语义辨识度的地址向量,随后通过语言建模推测活跃地址。
27.本发明设计了基于深度学习的活跃地址生成算法6lmns,包括add2vec和gpt-ipv6两种机制。add2vec将整个活动地址空间映射到语义向量空间,序列相似的地址在同一簇中。gpt-ipv6将学习语义向量来实现ipv6语言建模,综合考虑多个地址序列之间的关系,通过核心采样top p解码生成与地址集具有语义相似性的序列。
28.add2vec是基于word2vec思想来实现的,word2vec是word embedding的方法之一,它是2013年由谷歌mikolov提出的一套新的词嵌入方法。构建有效的语义信息,首先需要先将ipv6地址赋予新的语义。如图2所示,首先创建地址词来表示十六进制地址的每一个nybble。地址中第i个nybble的值为vi,其中v∈{0,1,...,f}。索引i被定义为si,其中s∈{0,1,...,v}。新表示法中第i个地址词由nybble值和索引值组成,为visi(例如,第11个nybble值4被表示为地址词4a)。词汇表即为所有通过ipv6地址集建立的地址词序列,目的是要区分不同索引的nybble值,相同的nybble值在地址中的位置不同可能具有不同的语义性。
29.在确定了地址词后,按照mikolov等人的选词过程,选择输入词和它的上下文来生成训练样本。如图2所示,对输入序列进行选词操作,当序列中的某个词被选为输入词后,输入词上下文的词被选为建立训练样本的背景词,窗口大小为5。
30.由于不能将词输入神经网络,因此每个地址词都表示为one-hot向量,这个向量的长度等于词汇表的大小,神经网络输入和输出神经元的数量等于词汇量。将词输入神经网络,尝试预测上下文词的概率,输出层使用一个softmax分类器,表示一个特定的词出现在特定语境中的概率。经过训练,最后的隐藏层结果是输入词的向量表示。在本发明中,add2vec在隐藏层中使用了100个神经元。
31.通过语言训练模型gpt-ipv6,并运用地址向量来实现ipv6地址的生成。gpt的整体结构如图3所示,它使用transformer抽取器,特征抽取能力要强于rnn。同时在transformer的基础上进行了改进,只保留了mask multi-head attention。gpt在进行自注意力计算的时候,屏蔽了来自当前计算位置右边所有单词的信息,只采用单词的上文来进行预测。
32.语言模型通过将联合概率按如下分解来计算序列t
0:l
的概率分布,其中l是序列长度:
[0033][0034]
对条件概率建模,训练一个gpt网络来处理地址词序列t
0:i-1
。gpt-ipv6的结构如图3所示,输入词由地址集中的地址转换而来,序列前16个地址词的向量,由预先训练的add2vec决定,被输入到模型中,用于预测后16个词。gpt训练过程分为两个部分,无监
督预训练语言模型和有监督的下游任务fine-tuning。
[0035]
给定地址集u={u1,...,un},使用标准语言模型目标(language modeling objective)来最大化以下似然函数:
[0036][0037]
根据we和w
p
来计算模型的输入
[0038]
h0=uwe+w
p
[0039]
将输入传进decoder模块:
[0040][0041]
将最终输出的hn传入softmax进行计算,得到对应的标签概率分布:
[0042][0043]
其中,u=(u-k
,...,u-1
)是地址词向量,θ是模型参数,n是网络层数,we是地址词嵌入矩阵(embedding matrix),w
p
是位置嵌入矩阵。
[0044]
经过预训练后,采用有监督的目标任务对模型参数微调。假设一个有标签的地址集c,假设每一条数据为一个地址词序列x1,...,xm以及相应的标签y,通过之前预训练的模型获得输出向量h
l
m,再送入线性输出层,来预测标签y:
[0045][0046]
wy为预测输出是的参数,损失函数为:
[0047][0048]
最后,将两阶段的目标函数通过超参λ相加,训练整个模型:
[0049]
l3(c)=l2(c)+λ*l1(c)
[0050]
为了完成向量空间中的地址生成任务,希望生成的词向量y
pred
与目标词向量y
true
具有较高的语义相似度。因此,本发明提出的6lmns模型使用余弦距离作为损失函数l:
[0051][0052]
l=1-cos(θ)
[0053]
传统语言模型直接对单次单词概率建模,与之不同的是,6lmns是预测词向量以保留向量空间的语义信息。由于训练样本是具有语义关系的地址向量,通过add2vec模型获得,因此通过使用最小化余弦距离函数,可使获得的预测目标,与地址集具有相似上下文结构。这种方法旨在选择向量空间中最接近的地址词,这有助于发现活跃ipv6地址集。
[0054]
在每个epoch生成地址词向量后,计算预测得到的词向量,以及词汇表中包含当前索引的每个词向量的余弦相似度。使用softmax函数将余弦相似度cos(θ)转换为单词采样概率p(i):
[0055][0056]
其中c是词汇表中具有当前索引的单词数。为了获得较高活跃率的地址,采用核心
采样(top-p sampling)这一随机解码策略,是对贪心策略的一种改进。在top-p采样中,核心思想是根据概率分布动态的决定采样的词空间,给定i时刻的概率分布:p(x|x
1:i-1
),它是i时刻每个词的选取概率,经过softmax计算得到的归一化概率。取概率和大于固定阈值p的词语作为top-p的采样空间v
(p)
:
[0057][0058]
令p'=∑
x∈v(k)
p(x|x
1:i-1
),然后对采样的概率重新归一化:
[0059][0060]
这种策略可以保证选择最大概率的词,他们的累积概率密度大于预设的阈值p。
[0061]
为了验证本发明的有效性,对本发明的方法与传统技术方法进行测试对比:
[0062]
测试结果如图4所示,可以发现,top p sampling生成的地址每一个地址词的概率基本都大于传统greedy search,因此本发明生成的地址总的活跃率将优于传统greedy search。
[0063]
在6lmns模型中,softmax温度是一个关键参数,可以控制模型生成的地址质量。在选择高温t时,模型更倾向于随机采样,生成的地址拥有更好的多样性。6lmns采用改进后的核心采样top p,在保持低温t的情况下,生成的地址更接近原始地址集。图5显示了不同温度t对应的地址生成结果,温度的升高促使生成的地址更加多样化。通过测试不同t值的生成性能,当t=0.01时,模型生成的地址拥有更高的活跃率r
hit
和有效生成率r
gen
。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1