模型训练方法、法律诉讼信息对齐融合方法及其终端设备与流程
1.本技术主要涉及法律和深度学习技术领域,尤其涉及一种模型训练方法、多源异构法律诉讼信息对齐融合方法、终端设备以及计算机可读存储介质。
背景技术:
2.法律诉讼过程复杂多变,律师进行案情研判时,经常需要分析涉及诉讼主体的大量多源异构数据,人工处理数据效率较低。虽然目前已有自然语言处理、知识图谱等智能化技术可有效提高人工处理速度,但已有技术只能处理单一数据源,从单一数据源(例如一份法律文书)中提取诉讼实体信息,无法在多个可能存在不同数据结构的数据源之间(如多个非结构文书数据以及在商业网站上获取的结构化主体关联信息)进行主体信息融合对齐,导致其匹配准确率不高,仍需要大量人工核对和对齐工作,从另一个层面降低了工作效率,无法有效支持进一步的分析决策。因此,现有法律文书智能化分析技术有待改进,亟需智能化的诉讼主体信息对齐与融合方法。
技术实现要素:
3.本技术提供了一种模型训练方法、多源异构法律诉讼信息对齐融合方法、终端设备以及计算机可读存储介质,旨在解决现有技术中,需要法律分析人员人工核对多源异构法律诉讼所涉主体信息,降低工作效率的问题。
4.为解决上述技术问题,本技术提供了一种模型训练方法,所述模型训练方法包括:
5.在若干多源异构数据源内提取诉讼主体及其关联关系,并按照所述诉讼主体及其关联关系构建诉讼主体知识三元组;
6.利用同一诉讼主体对应的诉讼主体知识三元组组成第一知识图谱,利用不同诉讼主体对应的诉讼主体知识三元组组成第二知识图谱,并根据所述第一知识图谱和所述第二知识图谱,组成诉讼主体训练数据集;
7.对所述诉讼主体训练数据集内的知识图谱进行向量化表示;
8.采用双循环方式配对组合第一知识图谱和第二知识图谱,根据知识图谱之间的特征向量训练判断模型,得到用于比较任意诉讼主体相似度,并对判断对相同主体的诉讼主体进行对齐的判断模型。
9.其中,所述在若干多源异构数据源内提取诉讼主体及其关联关系,包括:
10.通过柔性深度学习信息提取方式在所述若干多源异构数据源内提取诉讼主体及其关联关系;
11.其中,所述多源异构数据源包括在不同数据源存储,通过不同数据接口或访问方式提供的结构化数据和非结构化数据。
12.其中,所述柔性深度学习信息提取方式包括:根据所述多源异构数据源的类型,构建适配数据特点的柔性信息提取工具。
13.其中,所述按照所述诉讼主体及其关联关系构建诉讼主体知识三元组,包括:
14.将所述诉讼主体作为所述诉讼主体知识三元组的点;
15.将所述诉讼主体的关联关系作为所述诉讼主体知识三元组的边;
16.利用两个点,以及点与点之间连接的边,构建诉讼主体知识三元组。
17.其中,所述对所述诉讼主体训练数据集内的知识图谱进行向量化表示,包括:
18.获取开源法律诉讼领域文本语料库中的字词预训练向量字典;
19.根据所述诉讼主体训练数据集内的点、边名称语义在所述向量字典中进行检索,获取对点、边语义向量,实现知识图谱向量化表示;
20.采用注意力模型,在所述诉讼主体点上集成图谱点、边语义以及关联拓扑结构特征信息,生成诉讼主体的知识图谱特征向量。
21.其中,所述采用双循环方式配对组合第一知识图谱和第二知识图谱,根据知识图谱之间的特征向量训练判断模型,包括:
22.循环遍历所述诉讼主体训练数据集中的每个诉讼主体的知识图谱;
23.基于当前知识图谱,和当前同一主体其他图谱配对,并且和其他不同诉讼主体知识图谱数据集中的图谱配对,自动为主体相同的图谱和不同的图谱设置标签;
24.在每对匹配的两个知识图谱中,根据所述判断模型预测标签和实际标签的差异更新所述判断模型参数,完成模型训练。
25.其中,所述根据知识图谱之间的特征向量训练判断模型,得到用于比较任意诉讼主体相似度,并对判断对相同主体的诉讼主体进行对齐的判断模型之后,所述模型训练方法包括:
26.获取任意一对知识图谱,其中,所述指示图谱包括一对诉讼主体及其对应的关联关系;
27.利用所述判断模型通过生成当前配对对诉讼主体知识图谱向量并计算相似度;
28.通过阈值判断配对主体是否为同一诉讼主体,将视为相同主体的对齐融合。
29.为解决上述技术问题,本技术提供了一种多源异构法律诉讼信息对齐融合方法,所述信息对齐融合方法包括:
30.获取目标诉讼主体类型;
31.获取所述目标诉讼主体类型对应的主体关联关系信息;
32.基于所述目标诉讼主体类型,及其主体关联关系信息,从若干法律诉讼信息数据源中,形成以所述目标诉讼主体类型为中心点的若干知识图谱;
33.使用预选训练的判断模型对所述若干知识图谱进行匹配,获取所述若干知识图谱两两之间的相似度;
34.将相似度超过预设阈值的多个知识图谱的诉讼主体对齐为同一诉讼主体,实现多源异构法律信息的融合;
35.其中,所述判断模型通过上述的模型训练方法训练得到。
36.为解决上述技术问题,本技术提供了一种终端设备,其中,所述终端设备包括处理器、与所述处理器连接的存储器,其中,所述存储器存储有程序指令;
37.所述处理器用于执行所述存储器存储的程序指令以实现如上述模型训练方法和/或多源异构法律诉讼信息对齐融合方法。
38.为解决上述技术问题,本技术提供了一种计算机可读存储介质,所述存储介质存
储有程序指令,所述程序指令被执行时实现上述模型训练方法和/或多源异构法律诉讼信息对齐融合方法。
39.与现有技术相比,本技术的有益效果是:终端设备在若干多源异构数据源内提取诉讼主体及其关联关系,并按照所述诉讼主体及其关联关系构建诉讼主体知识三元组;利用同一诉讼主体对应的诉讼主体知识三元组组成第一知识图谱,利用不同诉讼主体对应的诉讼主体知识三元组组成第二知识图谱,并根据所述第一知识图谱和所述第二知识图谱,组成诉讼主体训练数据集;对所述诉讼主体训练数据集内的知识图谱进行向量化表示;采用双循环方式配对组合第一知识图谱和第二知识图谱,根据知识图谱之间的特征向量训练判断模型,得到用于比较任意诉讼主体相似度,并对判断对相同主体的诉讼主体进行对齐的判断模型。本技术提出的方法解决已有自动法律信息处理技术无法在多源异构数据内进行主体信息自动比较对齐,导致仍需大量人工核对,大幅降低工作效率,无法有效支持进一步分析决策的问题;通过双循环方式匹配相同和不同主体的知识图谱对,自动生成大量知识图谱配对训练数据,并根据配对信息自动设置是否为相同主体的标签,为图注意力判断模型的训练提供充分数据支撑,减少人工标注需求;从适配多源异构数据中提取诉讼主体及其关联关系;克服已有法律诉讼领域信息提取和自然语言处理方法只能处理单一数据源,难以在多源异构数据源中有效识别诉讼主体信息的问题。
附图说明
40.为了更清楚地说明本发明实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。其中:
41.图1是本技术提供的模型训练方法一实施例的流程示意图;
42.图2是本技术提供的判断模型训练流程的示意图;
43.图3是本技术提供的判断模型训练集一实施例的结构示意图;
44.图4是本技术提供的判断模型注意力机制的工作原理图;
45.图5是本技术提供的多源异构法律诉讼信息对齐融合方法一实施例的流程示意图;
46.图6是本技术提供的终端设备的一实施例的框架示意图;
47.图7是本技术提供的计算机存储介质一实施例的结构示意图。
具体实施方式
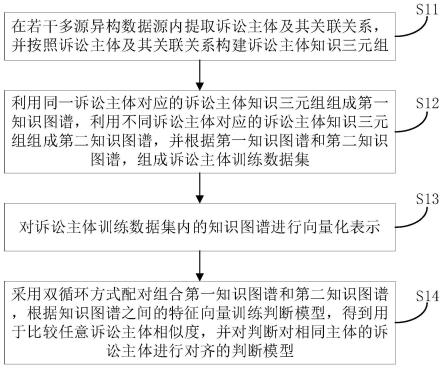
48.下面将结合本技术实施例中的附图,对本技术实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅是本技术的一部分实施例,而不是全部的实施例。基于本技术中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本技术保护的范围。
49.本技术领域技术人员可以理解,除非特意声明,这里使用的单数形式“一”、“一个”、“所述”和“该”也可包括复数形式。应该进一步理解的是,本发明的说明书中使用的措辞“包括”是指存在所述特征、整数、步骤、操作、元件和/或组件,但是并不排除存在或添加
一个或多个其他特征、整数、步骤、操作、元件、组件和/或它们的组。应该理解,当我们称元件被“连接”或“耦接”到另一元件时,它可以直接连接或耦接到其他元件,或者也可以存在中间元件。此外,这里使用的“连接”或“耦接”可以包括无线连接或无线耦接。这里使用的措辞“和/或”包括一个或更多个相关联的列出项的全部或任一单元和全部组合。
50.本技术领域技术人员可以理解,除非另外定义,这里使用的所有术语(包括技术术语和科学术语),具有与本发明所属领域中的普通技术人员的一般理解相同的意义。还应该理解的是,诸如通用字典中定义的那些术语,应该被理解为具有与现有技术的上下文中的意义一致的意义,并且除非像这里一样被特定定义,否则不会用理想化或过于正式的含义来解释。
51.律师进行案情研判需要分析大量多源异构数据中描述的诉讼主体是否为同一主体,已有自动化法律信息分析技术只能处理单一数据源,无法在多源异构数据内进行主体信息自动比较对齐,仍需要大量人工核对工作,降低研判工作效率。因此,现有法律文书智能化分析技术有待改进,亟需智能化的诉讼主体信息对齐与融合方法。
52.针对现有技术的上述缺陷,本技术提供一种多源异构法律诉讼信息对齐融合方法,以及其中使用到的判断模型的模型训练方法。本技术可解决已有自动化法律信息处理技术无法在多源异构数据内进行主体信息自动比较,导致仍需大量人工核对,大幅降低工作效率,无法有效支持进一步分析决策的问题。
53.具体请参阅图1和图2,图1是本技术提供的模型训练方法一实施例的流程示意图,图2是本技术提供的判断模型训练流程的示意图。
54.如图1所示,本实施例的模型训练方法具体包括以下步骤:
55.步骤s11:在若干多源异构数据源内提取诉讼主体及其关联关系,并按照诉讼主体及其关联关系构建诉讼主体知识三元组。
56.具体地,本实例中的诉讼主体包含自然人和各类型单位,其中,单位包含国有企业、私营企业、事业单位、非盈利组织等各类型参与社会经济活动的单位实体。人和人之间的关系包括亲属关系、朋友关系、职权关系等。人和单位之间的关系包括股权关系、任职关系、财务关系(如借贷关系、抵质押关系等)。对于属性关系,与人相关的属性关系包括地址(如居住地址、办公地址等)、日期(如出生日期等)、性别、年龄等;与单位相关属性关系包括法人、类别(如国有企业、民营企业、事业单位等)、地址(如曾所在地和现所在地等)、日期(如注册日期、增资日期、上市日期等)。
57.终端设备可以通过柔性深度学习信息提取方式在若干多源异构数据源内提取诉讼主体及其关联关系;其中,多源异构数据源包括在不同数据源存储,通过不同数据接口或访问方式提供的结构化数据和非结构化数据。
58.具体地,多源异构法律诉讼数据的多源性体现在数据存储在不同数据源中,并通过不同接口提供访问方式,例如本地计算机文档、开源网站(如法律文书网等)、商业网站(例如企查查、爱企查等)、社交媒体等。多源异构法律诉讼数据的异构型,在于数据包括数据结构,如结构化表格类数据(如企业信息表格)以及非结构化数据,如法律文书、网站公告和社交媒体留言等。将多源异构数据输入柔性信息提取模型中,提取诉讼主体和主体关系,将从不同数据源内提取到的诉讼主体和关系自动匹配,分别生成若干知识三元组。
59.在一种实现方式中,诉讼主体及其关联关系由柔性信息提取工具提取,信息提取
工具包含正则表达式、逻辑规则和深度学习模型,可针对所述法律诉讼数据特性进行调节。
60.具体地,本技术根据多源异构数据的结构化程度和语义表达规范性,将多源异构数据分为表格类规范化数据以及非表格类不规范数据。本技术的终端设备可以自动判断输入数据的规范性,包括使用启发式逻辑规则基于输入数据的超文本标记判断数据形式,然后将输入对应的提取方法进行主体信息提取。
61.其中,表格类规范化数据。例如企查查等公开的诉讼主体基本信息,具有标准化的表头-表值数据结构。本实例通过结合逻辑规则和正则表达式的方式提取诉讼主体信息。例如,正则表达式可以基于当前表格位置的文本信息特征判断该文本是否属于表头(例如“公司名称”或表值“某科技有限公司”)。逻辑规则通过“如果-那么”的形式,基于文本长度、主谓宾位置和顺序等特征,对表值文本进行清洗和关键信息提取。
62.非表格不规范数据包括但不限于:网络公告、社交媒体留言以及各类法律文本,如判决书、裁定书等。非表格不规范数据虽然存在一定的标准句式,但不存在规范结构,且由于人工撰写呈现较大随机性和差异性。本实例使用双向长短时记忆网络集成条件随机场的深度学习模型(bi-lstm-crf)实现非结构法律诉讼数据的主体信息提取。
63.bi-lstm-crf模型的输入是法律诉讼文本句子,输出是输入句子中包含的表达法律诉讼主体及其关联关系的字词。例如“某公司”、“某人名”等表达诉讼主体,“某地址”、“某电话”等表达主体属性,“就职”、“朋友”、“父母”、“抵押”、“质押”等表达主体关系。
64.bi-lstm-crf模型需要基于人工标注样本进行训练。人工标注样本与模型输出样本形式相似,包括人工使用“开头-中间-结束-其他”(bieo)原则在法律诉讼文本句子中标注的诉讼主体及其关联的准确标签(如把所有的具体公司名都使用统一“公司”标签标注)。模型训练,包括将原始文本输入模型,将模型输出结果与人工标注真实样本对比,通过交叉熵损失、反向传播以及梯度下降方法更新模型参数。训练完成的bi-lstm-crf深度学习模型,可接收法律诉讼文本,自动提取表达诉讼主体和关系的字词。
65.进一步地,终端设备将bi-lstm-crf深度学习模型提取到的主体和关系以“点(头实体)-边-点(尾实体)”三元组的形式构成以若干以不同诉讼主体为中心的知识图谱。其中,三元组中的头实体表示诉讼主体,尾实体表示另一诉讼主体或当前诉讼主体的属性,三元组的边表示主体之间或主体与属性之间的关系。本实例针对表格类数据和非表格类数据,分别设计逻辑推理规则建立所述诉讼主体知识三元组数据。对于表格类规范化数据,逻辑规则集基于表格的设计分布将表头和表值进行关联匹配;对于非表格类不规范数据,逻辑规则集基于数据中提取到的表达诉讼主体及其关联的字词位置进行关联匹配。
66.举例说明,输入数据为结构化表格时,逻辑推理规则可遍历表格所有行列,如果当前表头的右侧一格为表值,而该表值的右侧再次出现表头,那么该表值与前一表头匹配。输入数据为非结构文本时,如果bi-lstm-crf深度学习模型提取到“公司”和“地址”标签,则假定其文字部分指代的具体公司和地址之间存在“主体-属性”关系。
67.步骤s12:利用同一诉讼主体对应的诉讼主体知识三元组组成第一知识图谱,利用不同诉讼主体对应的诉讼主体知识三元组组成第二知识图谱,并根据第一知识图谱和第二知识图谱,组成诉讼主体训练数据集。
68.具体地,为实现多源异构数据内诉讼主体的对齐融合,本技术训练了判断模型。判断模型使用多个诉讼主体的知识图谱数据集所组成的训练集训练。知识图谱数据集包括不
同数据源中描述相同诉讼主体的知识三元组形成的该主体知识图谱数据集。对知识图谱进行向量化表示,包括使用预训练字词向量和图注意力模型(gat)在诉讼主体中心点上集成图谱特征信息。双循环方式配对组合,包括相同主体的知识图谱集合,即第一知识图谱,和不同主体的知识图谱集合,即第二知识图谱中通过循环遍历采样知识图谱配对,根据已知配对信息分别自动设置当前配对主体是否为相同主体的标签,根据配对标签通过softmarginloss损失训练判断模型。
69.具体地,终端设备构建某一诉讼主体知识图谱数据集,包括通过人工交叉比对,识别不同数据源中提取到的描述相同主体的三元组,每一数据源中所述三元组自动形成以同一诉讼主体为中心的知识图谱。换言之,相同诉讼主体根据数据源不同存在多个以其为中心的知识图谱,共同形成该主体的知识图谱数据集。
70.另外,终端设备构建判断模型训练集,包括将数据集构建方法应用于建立多个不同诉讼主体的知识图谱数据集,形成判断模型训练集。如图3所示,图3是本技术提供的判断模型训练集一实施例的结构示意图。训练集包括若干不同诉讼主体知识图谱集合,每个知识图谱集合内包括若干表示该主体自不同数据源中提取的知识图谱,每个知识图谱包括若干三元组。知识图谱数据集和训练集可以使用neo4j图谱数据库工具保存和可视化展示。
71.步骤s13:对诉讼主体训练数据集内的知识图谱进行向量化表示。
72.具体地,终端设备使用预训练字词向量初始化每个诉讼主体知识图谱内点、边语义信息,实现点和边向量化表示;使用图注意力模型在诉讼主体中心点上集成当前知识图谱的点、边语义信息特征和拓扑结构信息特征,生成知识图谱特征向量。
73.具体地,终端设备从开源数据集获取法律诉讼领域预训练字词向量字典,其中每个字词对应一个50-300维的语义数值向量。根据主体知识图谱内的点、边名称语义在开源字词向量集合中进行检索,获取其名称对应预训练向量,对知识图谱内所有点、边的名称进行初始向量化,表达其语义特征信息。
74.终端设备遍历每个主体知识图谱中每个点,采集与当前点直接关联的点与边形成多个三元组c
i,j,p
=(hi,r
p
,hj)。其中,hi和hj为对应点的语义向量,r
p
为对应边的语义向量。然后,将每一主体知识图谱对应的若干三元组输入图注意力模型,生成可同时表达该图谱点、边语义和拓扑结构特征的向量。
75.请参阅图4,图4是本技术提供的判断模型注意力机制的工作原理图。如图4所示,图注意力模型(gat)包括两个可训练参数矩阵w1和w2,拼接操作模块concat,非线性激活函数模块relu。所述知识图谱三元组输入图注意力模型后,会先经过可训练参数矩阵w1和w2,得到各三元组对应的绝对权重值,即图4中的beta值;然后各三元组分别对应的绝对权重值再输入softmax模块,得到各三元组分别对应的相对权重值,即图4中的alpha值。将各三元组与其对应的绝对权重值和相对权重值关联保存在列表ai中。经过k次迭代后(k是图谱更新次数,一般不大于3次),通过对各三元组向量加权求和(公式1),生成代表当前诉讼主体点的图谱特征向量:
76.hk=∑nα
,j,pci,j,p
77.步骤s14:采用双循环方式配对组合第一知识图谱和第二知识图谱,根据知识图谱之间的特征向量训练判断模型,得到用于比较任意诉讼主体相似度,并对判断对相同主体的诉讼主体进行对齐的判断模型。
78.具体地,终端设备采用双循环配对生成知识图谱配对,包括遍历判断模型训练集每个诉讼主体的知识图谱数据集,一方面在每个集合内部训练通过两两组合的方式遍历集合,形成同一诉讼主体的多个知识图谱配对;另一方面在不同主体的知识图谱数据集合之间进行跨集合遍历采样和两两组合配对,形成不同诉讼主体的多个知识图谱配对。由于遍历过程已知当前配对的主体是否为同一主体,可自动对当前配对设置标签y,其中,为同一主体的配对标签设置为1,为不同主体的配对标签设置为-1。
79.终端设备将诉讼主体知识图谱的配对特征向量以及标签信息输入到判断模型中,使用softmarginloss损失函数控制模型参数梯度下降和更新,实现判断模型训练。
80.具体地,终端设备遍历诉讼主体知识图谱配对,按步骤s13对每一配对的对应两个知识图谱分别生成其图谱特征向量。将两个特征向量做内积,生成代表向量相似度的实数s,代表当前配对主体是同一主体的可能性。
81.终端设备使用softmarginloss损失函数,输入s和当前配对的正确标签信息y,计算判断模型预测结果和真实标签差异作为模型损失值。
82.由于模型损失值反映当前基于图注意力的判断模型对相同和不同主体知识图谱特征向量识别的偏差,因此,基于损失值,使用反向传播和随机梯度下降(sgd)技术,对判断模型参数进行更新,可以收敛判断模型预测结果真实标签之间的差距。
83.在判断模型训练过程中,终端设备将相同和不同主体知识图谱配对数据分别按预设比例(如7:2:1)划分为训练集、验证集以及测试集,再将两部分训练、验证和测试数据分别混合,保证所述训练、验证和测试数据中相同和不同主体知识图谱数据比例一致。首先使用训练集数据更新图注意力判断模型参数,并使用验证集调整优化模型超参数(如梯度下降学习率、gat迭代次数k等),最后使用测试集评估质量预测模型的表现。当所述判断模型在测试集上的预测表现达到阈值,如对于两个诉讼主体是否为相同主体的判断准确率大于95%,表示模型参数已经迭代更新完毕,即得到目标判断模型。
84.在训练得到目标判断模型之后,训练后的判断模型可输入配对的诉讼主体知识图谱,将判断为相同主体的诉讼主体对齐融合。
85.具体地,针对新输入的法律诉讼主体,从不同数据源中使用步骤s11自动提取主体知识三元组,构成描述该主体的知识图谱,使用步骤s13所述配对方法将知识图谱配对后输入图注意力判断模型,判断模型输入当前诉讼主体相似度s。根据具体法律诉讼需求确定特征向量相似度阈值s’,将大于s’的配对主体视为同一诉讼主体进行对齐融合。
86.请继续参阅图5,图5是本技术提供的多源异构法律诉讼信息对齐融合方法一实施例的流程示意图。
87.如图5所示,本实施例的多源异构法律诉讼信息对齐融合方法具体包括以下步骤:
88.步骤s21:获取目标诉讼主体类型。
89.步骤s22:获取目标诉讼主体类型对应的主体关联关系信息。
90.步骤s23:基于目标诉讼主体类型,及其主体关联关系信息,从若干法律诉讼信息数据源中,形成以目标诉讼主体类型为中心点的若干知识图谱。
91.步骤s24:使用预选训练的判断模型对若干知识图谱进行匹配,获取若干知识图谱两两之间的相似度。
92.步骤s25:将相似度超过预设阈值的多个知识图谱的诉讼主体对齐为同一诉讼主
体,实现多源异构法律信息的融合。
93.其中,本技术实施例中的判断模型可以通过图1所示的模型训练方法训练得到,其训练过程在此不再赘述。
94.在本技术提供的模型训练方法以及多源异构法律诉讼信息对齐融合方法通过柔性深度学习信息提取可从适配多源异构数据中提取诉讼主体及其关联关系;克服已有法律诉讼领域信息提取和自然语言处理方法只能处理单一数据源,难以在多源异构数据源中有效识别诉讼主体信息的问题;图谱数据格式可有效融合点、边语义信息以及主体与属性之间拓扑特征,基于特征向量快速判断诉讼主体相似性,克服已有法律诉讼主体对齐过程依赖人工,效率低,无法支持进一步法律分析研判的问题;通过双循环方式匹配相同和不同主体的知识图谱对,自动生成大量知识图谱配对训练数据,并根据配对信息自动设置是否为相同主体的标签,为图注意力判断模型的训练提供充分数据支撑,减少人工标注需求。
95.为实现上述实施例中的模型训练方法以及多源异构法律诉讼信息对齐融合方法,本技术还提供另一种终端设备300,具体请参见图6,本技术实施例的终端设备300包括处理器31、存储器32、输入输出设备33以及总线34。
96.该处理器31、存储器32、输入输出设备33分别与总线34相连,该存储器32中存储有程序数据,处理器31用于执行程序数据以实现上述实施例所述的模型训练方法以及多源异构法律诉讼信息对齐融合方法。
97.在本技术实施例中,处理器31还可以称为cpu(central processing unit,中央处理单元)。处理器31可能是一种集成电压控制系统芯片,具有信号的处理能力。处理器31还可以是通用处理器、数字信号处理器(dsp,digital signal process)、专用集成电压控制系统(asic,application specific integrated circuit)、现场可编程门阵列(fpga,field programmable gate array)或者其它可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件。通用处理器可以是微处理器或者该处理器31也可以是任何常规的处理器等。
98.本技术还提供一种计算机存储介质,请继续参阅图7,图7是本技术提供的计算机存储介质一实施例的结构示意图,该计算机存储介质400中存储有程序数据41,该程序数据41在被处理器执行时,用以实现上述实施例的模型训练方法以及多源异构法律诉讼信息对齐融合方法。
99.本技术的实施例以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。基于这样的理解,本技术的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的全部或部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)或处理器(processor)执行本技术各个实施方式所述方法的全部或部分步骤。而前述的存储介质包括:u盘、移动硬盘、只读存储器(rom,read-only memory)、随机存取存储器(ram,random access memory)、磁碟或者光盘等各种可以存储程序代码的介质。
100.以上所述仅为本技术的实施方式,并非因此限制本技术的专利范围,方式利用本技术说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本技术的专利保护范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1