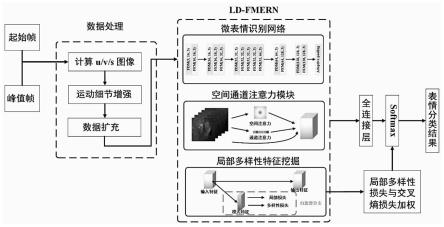
一种基于局部多样性驱动深度网络的面部微表情识别方法
1.本发明属于情感识别技术领域。
背景技术:
2.区别于面部宏表情,面部微表情是一种自发的肌肉运动幅度小、动作持续时间短(一般标准为少于500ms)、局部肌肉动作的面部表情动作。面部微表情是人们对面部表情有意识或无意识抑制的结果,是人们真实情绪的泄露。当人们试图隐藏情绪时,无法控制的微表情会揭露人们的真实情感。由于微表情的客观性,因此微表情的识别对心理和临床诊断、讯问和公共安全等领域具有广泛的应用。
3.与宏表情识别相似,微表情识别可以分为图像预处理、特征提取和表情分类识别。对微表情识别的有效性影响最大的是从图像序列中提取相关特征。传统方法基于手工特征如光流,使用支持向量机和随机森林等传统分类模型,根据提取的运动属性进行面部微表情识别。
4.近期,很多研究提出了定制的深度神经网络(dnn),以学习的方式提取微表情相关特征。一些研究人员从受试者的面部图像中提取特征,尤其是峰值帧。然而,即使是微表情序列的峰值帧也运动强度低的问题。因此,一些研究人员将计算出的运动属性输入dnn,以挖掘微表情相关特征。与峰值帧相比,这些运动属性对微弱肌肉运动更敏感。因此,从运动属性自动提取的特征更适合用来识别微表情。尽管研究人员成功地将运动属性输入到定制的dnn中,但仍存在一些问题。首先,因为微表情数据的收集过程非常昂贵,所以所有的微表情数据库规模都很小。因此,即使使用随机裁剪或翻转输入图像进行数据增强,dnn也很容易过拟合。此外,严格意义上光流的计算是从相邻两帧计算的,然而微表情流的计算是从受试者的起始帧和峰值帧计算的。因此,从表情流中计算出的运动属性可能会遇到一些干扰因素,如轻微的面部抖动和光照变化。其次,即使从增强的运动属性中也很难提取出与运动相关的特征。以前的研究中大多采用宏表情识别使用的网络,忽略了宏表情识别和微表情识别之间的差异。具体来说,面部微表情往往是由低强度的肌肉运动引起的,它存在于局部但多样的面部区域。
技术实现要素:
5.发明目的:为了解决上述现有技术存在的问题,本发明提供了一种基于局部多样性驱动深度网络的面部微表情识别方法。
6.技术方案:本发明提供了一种基于局部多样性驱动深度网络的面部微表情识别方法,该方法具体包括如下步骤:
7.步骤1:对样本数据进行预处理,所述预处理包括:计算数据集中原始图像的原始表情流图像,对计算得到的原始表情流图像进行运动细节增强,最后对运动细节增强后的表情流图像进行扩充;
8.步骤2:建立局部多样性的面部微表情识别网络,从扩充后的表情流图像中提取微
表情相关的特征;
9.步骤3:采用softmax分类器对步骤2中的特征进行分类。
10.进一步的,所述步骤1中的预处理具体为:
11.步骤1.1:将数据集中的原始图像的尺寸进行调整,然后提取微表情的起始帧与峰值帧之间的面部肌肉运动属性,得到微表情的起始帧和峰值帧之间的表情流:
12.i
t
(x,y)=i
t+a
(x+u
t
(x,y)δt,y+v
t
(x,y)δt)
13.其中,t表示起始帧,i
t
(x,y)表示起始帧中坐标为(x,y)的像素点的光强度,a表示起始帧与峰值帧之间的间隔时间,u
t
(x,y)和v
t
(x,y)分别表示表情流的水平和垂直分量,i
t+a
(x+u
t
(x,y)δt,y+v
t
(x,y)δt)表示峰值帧中坐标为(x+u
t
(x,y)δt,y+v
t
(x,y)δt)像素点的光强度;
14.步骤1.2:基于u
t
(x,y)和v
t
(x,y)计算应变分量s:其中u=[u(x,y),v(x,y)]
t
,t表示转置,表示求导;根据u
t
(x,y),v
t
(x,y)和s得到原始表情流图像;
[0015]
步骤1.3:对数据集中的原始的起始帧与峰值帧进行下采样,并根据步骤1.1和步骤1.2计算下采样后的起始帧与峰值帧之间表情流图像;并将该表情流图像上采样到原始表情流图像的尺寸,得到与微表情无关的运动的模糊表情流图像;
[0016]
步骤1.4:将原始表情流图像按像素减去模糊表情流图像,得到与微表情相关的细节表情流图像;并将该细节表情流图像按像素加入到原始表情流图像中,得到运动细节增强的表情流图像;
[0017]
步骤1.5:调节运动细节增强的表情流图像的水平分量和垂直分量的权重,并计算相应的应变分量,从而对运动细节增强的表情流图像的数量进行扩充。
[0018]
进一步的,所述局部多样性的面部微表情识别网络包括第一~第五特征降采样模块,第一~第九特征增强模块,第一自适应池化层以及全连接层;所述第一特征降采样模块,第一特征增强模块,第二特征降采样模块,第二特征增强模块,第三特征增强模块,第三特征降采样模块,第四~第七特征增强模块,第四特征降采样模块,第八特征增强模块,第五特征降采样模块,第九特征增强模块,第一自适应池化层以及全连接层依次连接。
[0019]
进一步的,所述第一~第五特征降采样模块结构相同均包括依次连接的第一卷积层,第一批处理归一化层,最大池化层以及第一p-relu激活函数层。
[0020]
进一步的,所述特征增强模块用于对微表情相关特征进行增强,第一~第九特征增强模块结构相同均包括依次连接的第二卷积层,第二批处理归一化层,第三卷积层,第三批处理归一化层,第二p-relu激活函层,空间通道注意力模块以及局部多样性特征挖掘模块。
[0021]
进一步的,对于输入特征x,所述空间通道注意力模块输出相应的特征进一步的,对于输入特征x,所述空间通道注意力模块输出相应的特征sa(
·
)表示空间注意力模块,ca(
·
)表示通道注意力模块;
[0022]
所述空间注意力模块包括第四、第五卷积层和sigmoid函数激活;第四、第五卷积层将输入尺寸为c
×h×
w的特征,转化为1
×h×
w的空间注意力地图,其中c表示通道数,h为高度,w为宽度,sigmoid函数激活将空间注意力地图与输入特征逐元素相乘,得到c
×h×
w大小的输出特征;
[0023]
所述通道注意力模块包括第二自适应池化层,多层感知器和softmax激活函数;所
述第二自适应池化层将输入尺寸为c
×h×
w的特征转化为c维向量,并将c维向量输入至多层感知器,得到通道注意力地图,softmax激活函数层将通道注意力地图与输入特征逐元素相乘,得到c
×h×
w大小的输出特征。
[0024]
进一步的,所述局部多样性特征挖掘模块包括第六卷积层,用于将输入特征转化为模式特征,在局部多样性特征挖掘模块中设置局部多样性损失函数l
l-d
,实现局部多样性特征的挖掘,l
l-d
的表达式为:
[0025][0026]
其中,σ2为所有通道间方差,λ为常数,n为模式特征的通道数,fi为模式特征的第i个通道,l
lc
的表达式为:其中τ为常数,θ(fi)表示第i个通道的激活区域。
[0027]
进一步的,对局部多样性的面部微表情识别网络和softmax分类器进行训练时,损失函数为:
[0028][0029]
其中,ω(epoch)为随历元变换的权重,为所有局部多样性损失l
l-d
的均值,l
ce
为交叉熵损失函数,其中k为样本数,pk表示真实的概率分布,qk表示预测的概率分布。
[0030]
有益效果:
[0031]
(1)考虑到面部轻微抖动、光照变化等复杂因素,本发明对采集得到的微表情图像进行预处理,从而去除与微表情无关的动态,并增强微表情相关运动细节。针对微表情数据库规模有限的问题,提出了一种基于人脸u/v/s图像的数据增强策略。从而提高微表情运动特征提取的准确率。
[0032]
(2)考虑到微表情运动强度低,表情发生区域小而多样,本发明提出了一种局部多样性的面部微表情识别网络(ld-fmern)。引入空间通道注意力模块来细化提取的特征。提出了一种局部多样性特征挖掘策略,使网络聚焦于小而多样的面部区域,从中找到微表情相关的线索。
[0033]
(3)利用softmax分类不同微表情,采用交叉熵加局部多样性损失的自适应损失函数约束,以促使ld-fmern在不同阶段集中于不同的面部区域,提高微表情识别的准确性。
附图说明
[0034]
图1为本发明的方法流程图;
[0035]
图2为本发明的预处理流程图;
[0036]
图3为ld-fmern网络的结构图,其中图(a)为ld-fmern网络的整体结构图,图(b)为fdm模块的结构图,图(c)为fem模块的结构图;
[0037]
图4为空间通道注意力模块结构图;
[0038]
图5为局部多样性挖掘模块结构图。
具体实施方式
[0039]
构成本发明的一部分的附图用来提供对本发明的进一步理解,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。
[0040]
如图1所示,本发明提出的人脸面部微表情识别方法,包括图像预处理模块与局部多样性的面部微表情识别网络(local-diverse facial-micro-expression recognition network,ld-fmern),后者包括特征降采样模块(feature down-sampling modules,fdms)和特征增强模块(feature enhancement modules,fems)。本发明可以同时完成微表情图像的特征提取与分类。本发明对输入的微表情图像进行预处理,包括表情流计算、运动细节增强以及数据样本扩充。特征提取阶段使用通道空间注意力和局部多样性挖掘策略获取更准确的微表情特征。softmax求解时,采用交叉熵加局部多样性损失的自适应损失函数约束,提高微表情识别的准确性。
[0041]
本发明的具体操作步骤:
[0042]
1)进行数据预处理,计算表情流,增强运动细节和扩充样本
[0043]
(1):表情流u/v/s计算
[0044]
将数据集中原始图像调整大小到148*148(单位:像素)。采用tv-l1算法计算表情流,从而提取微表情起始帧与峰值帧之间的面部肌肉运动属性。与连续帧之间定义的光流不同,考虑到微表情持续时间短,在起始帧和峰值帧之间定义的表情流如下:i
t
(x,y)=i
t+a
(x+u
t
(x,y)δt,y+v
t
(x,y)δt),其中i
t
为起始帧光强度,(x,y)表示像素的位置,i
t
(x,y)表示起始帧中坐标为(x,y)的像素点的光强度,t表示起始帧,a表示起始帧与峰值帧的间隔时间,i
t+a
为峰值帧光强度,u
t
(x,y)和v
t
(x,y)分别表示表情流的水平和垂直分量(即u/v图像)。基于一阶的u和v,计算二阶的应变分量s(即s图像),定义如下式中u=[u(x,y),v(x,y)]
t
,表示求导,t表示转置。
[0045]
采用tv-l1算法(一种成熟的光流计算方法)求解方程计算得到u/v,进而得到s;
[0046]
根据u
t
(x,y),v
t
(x,y)和s得到原始表情流图像(也即u/v/s图像)。
[0047]
(2):运动细节增强
[0048]
图2给出了运动细节增强算法示意图。
[0049]
按照步骤(1)从初始起始帧和峰值帧生成原始u/v/s图像。将原始起始帧和峰值帧下采样到64*64(单位:像素),按照步骤(1)计算相应的表情流u/v/s图像,将得到的表情流图像上采样到原始尺寸,得到一个可能只包含与微表情无关的运动的模糊的表情流图像。使用原始表情流图像按像素减去模糊表情流图像,得到与微表情相关的细节表情流图像。将计算得到的细节表情流图像按像素加入到原始的表情流图像中,生成运动细节增强的表情流图像。
[0050]
(3):数据样本扩充
[0051]
由于目前微表情基准数据库中的样本量无法满足要求,而微表情样本采集成本很高,因此本发明对运动细节增强的表情流图像进行了数据扩充。调节表情流水平分量u和垂直v的权重,并计算得到相应的应变分量s。u分量的权重以0.1的步长从0.1增加到1.9,而v分量的权重以0.1的步长从1.9减少到0.1。使用该方法,u/v/s图像的数量可以扩展到19倍。生成的u/v/s图像仍然反映与微表情相关的运动,但对u/v分量的关注程度有所不同。
[0052]
2)搭建一个局部多样性的面部微表情识别网络自动提取有效特征
[0053]
如图3中的(a)所述,本实施例给出了局部多样性的面部微表情识别网络的结构图,包括表情流图像输入,五个特征降采样模块(feature down-sampling modules,fdms)和九个特征增强模块(feature enhancement modules,fems),最后一个fem模块后接自适应池化层,将2维特征地图转化为1维特征向量,输出送入全连接层fc。
[0054]
如图3中的(b)所示,特征降采样模块(fdm)对特征图进行下采样,避免过拟合,降低计算复杂度。它包含一个卷积层(conv),一个批处理归一化层(batch normalization)以加速收敛,一个最大池化(max-pooling)层用于对输入的特征图进行下采样,一个p-relu层作为激活函数。初始特征降采样模块输入通道为3,输出通道16,卷积核大小3。
[0055]
如图3中的(c)所示,特征增强模块(fem)对微表情相关特征进行增强。它由两个卷积层(conv)组成,每个卷积层后面跟着一个批处理归一化层(batch normalization)。第二个批处理归一化层的输出被输入p-relu激活层。激活的输出被依次输入一个空间通道注意力模块(spatial-channel modulator)和一个局部多样性特征挖掘模块(local-diverse feature mining)。初始特征增强模块输入通道为16,输出通道16,卷积核大小3。
[0056]
如图4所示,为特征增强模块中空间通道注意力模块结构图。
[0057]
特征增强模块中空间通道注意力模块采用并行计算结构,对于输入特征x,输出特征其中sa(
·
)表示空间注意力模块,ca(
·
)表示通道注意力模块。空间注意力模块包含两个卷积层,将输入尺寸为c
×h×
w的特征(c为通道数,h为特征图高度,w为特征图宽度)转化为1
×h×
w的空间注意力地图,经sigmoid函数激活后,将得到的空间注意力地图与输入特征逐元素相乘,得到c
×h×
w大小的输出特征。通道注意力模块包含一个自适应池化层,将输入尺寸为c
×h×
w的特征转化为c维向量,再经过一个多层感知机(multi-layer perceptron,mlp),本实施中采用3层感知器,每层神经元个数分别为c、c/4、c,得到大小为c的通道注意力地图。经softmax函数后,将得到的通道注意力地图与输入特征逐元素相乘,得到c
×h×
w大小的输出特征。
[0058]
如图5所示,为特征增强模块中局部多样性特征挖掘模块结构图。
[0059]
特征增强模块中局部多样性挖掘模块包含一个卷积层将c
×h×
w大小的输入特征转化为c/4
×h×
w的模式特征。通过引入额外的损失函数l
lc
,将局部约束以自监督的方式应用到模式特征的每个通道,其中n为通道数,τ为尝试,本实施中τ为0.15,用于控制激活区域与整个特征图之间的比例。θσfi)表示第i个通道的激活区域,fi为模式特征的第i个通道。通过计算所有通道间方差σ2来引入多样性约束。通过优化局部多样性损失l
l-d
实现局部多样性特征挖掘,实现局部多样性特征挖掘,λ为常数,本实施中λ设为0.1。
[0060]
3)利用softmax进行表情分类
[0061]
softmax函数以概率的形式展现多类别分类问题的分类结果,对于给定输入x:softmax函数以概率的形式展现多类别分类问题的分类结果,对于给定输入x:其中,输入x与输出y均为n维向量,输出向量的每个值在[0,1]范围内。
[0062]
在深度网络中,softmax函数中的值可用n个神经元来表示,对给定的输入x,每种
类别分类的概率y可表示为其中,p(y=n|x)表示输入x属于第n类的概率。
[0063]
对于softmax函数的求解,本发明采用交叉熵加局部多样性损失的自适应损失函数l
adap
作为损失函数,定义如下:其中l
ce
为交叉熵损失函数,ω(epoch)为随历元变化的权重,表示所有特征增强模块计算出的局部多样性损失l
l-d
的均值。交叉熵损失函数其中k为样本数,pk表示真实的概率分布,qk表示预测的概率分布。ω(epoch)初始值为0.1。本实施例采用基于梯度下降优化的反推算法进行最小化,从而得到网络输出。
[0064]
以上所述对本发明进行了简单说明,并不受上述工作范围限值,只要采取本发明思路和工作方法进行简单修改运用到其他设备,或在不改变本发明主要构思原理下做出改进和润饰的等行为,均在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1