一种基于RISC-V指令集的多矩阵节点总线拓扑结构及其工作方法
一种基于risc-v指令集的多矩阵节点总线拓扑结构及其工作方法
技术领域
1.本发明涉及一种基于risc-v指令集的多矩阵节点总线拓扑结构及其工作方法,属于集成电路处理器层次结构设计技术领域。
背景技术:
2.多年来,随着芯片设计技术的提升和应用范围的广泛,risc-v展示出越来越多传统的arm和x86架构所不具备的完全开源、架构简单等优势。如今risc-v已经被广泛应用,但由于risc-v官方只提供了tilelink总线协议,目前的市场兼容性并不好。
3.与此同时,soc的系统总线也得到越来越多样化,传统的系统总线已经不再满足日新月异的soc设计,由于各种cpu的内核总线接口不一致,会产生使用较低性能的处理器来驱动复杂的soc,造成soc性能和core性能的不匹配,引起种种问题,为解决这种问题往往会提升内核的数量,用更多的核来驱动整个soc,但这种方法在核和各种核簇组成的复杂片上网络中,会涉及到极为复杂的一致性检测;除此之外,也可以通过修改核内的总线接口,来提升并行总线通道的数量,但这种方法在core ip的提供方提供的是硬ip或者固ip的情况下,会无法修改总线接口。
技术实现要素:
4.针对现有技术的不足,本发明提供了一种基于risc-v指令集的多矩阵节点总线拓扑结构,解决risc-v在中高端处理器上的总线协议兼容问题;
5.本发明还提供了上述硬件架构的工作方法;
6.本发明利用基于risc-v的指令集内核;本发明由三种矩阵节点组成,分别是高速总线矩阵节点(high speed bus matrix node)、缓速总线矩阵节点(medium speed bus matrix node)和低速总线矩阵节点(low speed bus matrix node),每个矩阵节点可通过总线通道不同的宽度,不同的工作频率或者不同的工作电压,来控制功耗形成效率差;
7.术语解释:
8.1、dmap:direct memory access for peripherals,一种工作在低速节点的dma,除了能执行正常的dma的功能外(即3种通路,存储器到外设,外设到存储器,存储器到存储器),还能执行由外设到外设的数据转换。
9.2、主端:两个设备进行数据交互,发出指令的一端。
10.3、从端:两个设备进行数据交互,接收指令的一端。
11.4、dma:direct memory access,在各个节点都能工作的用于搬运数据的核外单元。
12.5、core:能在msmn和hsmn中工作的运算单元,节点中处理数据的核心单元。
13.6、matrix:由主端和从端交互而成的通信矩阵,每一个能访问主端和从端相交点称为内部节点。
14.7、flash:闪存,在本发明中可配置为nor flash或者nand flash,一种非易失性存储单元。
15.8、sram:静态随机存储器,一种易失性存储单元。
16.9、low speed bus:低速总线,一般用于连接外设。
17.10、bridge:不同速度的总线之间必须通过bridge来连接,用于分配和片选地址。
18.本发明的技术方案为:
19.一种基于risc-v指令集的多矩阵节点总线拓扑结构,包括一个高速总线矩阵节点、多个缓速总线矩阵节点及多个低速总线矩阵节点;
20.每个矩阵节点通过总线通道不同的宽度、不同的工作频率或者不同的工作电压,来控制功耗形成效率差,同时,保持正确的节点通信方向。
21.根据本发明优选的,低速总线矩阵节点中,dmap和其它缓速总线矩阵节点或高速总线矩阵节点作为低速总线矩阵节点的主端,此外,高速总线矩阵节点来的控制信号需要通过一个bridge到达低速总线矩阵节点;低速总线矩阵节点和小于128kb的sram作为低速总线矩阵节点的从端;容量较小的sram配置自己独立工作电压域,在关闭低速总线矩阵节点的电压域后,仍能保持正常的工作,存储外设到其中的数据。
22.根据本发明优选的,缓速总线矩阵节点中,dma、可配置的核和高速总线矩阵节点发出的控制信号作为缓速总线矩阵节点的主端;高速总线矩阵节点来的控制信号需要通过一个bridge到达缓速总线矩阵节点;外设作为缓速总线矩阵节点的从端。
23.根据本发明优选的,高速总线矩阵节点中,一个高性能的核、dma、以及其它可配置的加速器作为高速总线矩阵节点的主设备;在缓速总线矩阵节点在有独立核而无flash存放bootloader的情况下,在高速总线矩阵节点的从端配置用于存放缓速总线矩阵节点的启动程序,在soc工作之后,通过高性能的核的程序来控制dma,将缓速总线矩阵节点的启动程序搬运到缓速总线矩阵节点的sram或者其它的存储单元中。
24.根据本发明优选的,整个soc整体分为三种电压域,分别为主域、备份域和模拟电压域,其中,每个矩阵节点都工作在一个主域,通过不同的power gating来独立工作,或者,所有矩阵节点工作在不同的主域中,由电压制造频率差,使相同类型的矩阵节点有不同的工作频率满足低功耗的多样性。
25.根据本发明优选的,高速总线矩阵节点与缓速总线矩阵节点之间的bridge中添加单向指令滤波器。
26.根据本发明优选的,高速总线矩阵节点与每一个缓速总线矩阵节点、每一个低速总线矩阵节点进行数据通信,在搬运指令时遵循指令滤波的原则;
27.高速总线矩阵节点作为缓速总线矩阵节点、低速总线矩阵节点的主端;
28.缓速总线矩阵节点中,同级的缓速总线矩阵节点相连,保证不同的缓速总线矩阵节点有主频差,以工作频率较高的缓速总线矩阵节点作为两个缓速总线矩阵节点的主端,工作频率较低的缓速总线矩阵节点作为两个缓速总线矩阵节点的从端;
29.缓速总线矩阵节点在和高速总线矩阵节点连接时,缓速总线矩阵节点作为从端;在缓速总线矩阵节点和低速总线矩阵节点相连时,在与同频及更低频的低速总线矩阵节点交互时,缓速总线矩阵节点作为主端;
30.低速总线矩阵节点中,在低速总线矩阵节点和同频或者更高频的缓速总线矩阵节
点相连时,低速总线矩阵节点作为同频或者更高频的缓速总线矩阵节点的从端;在低速总线矩阵节点和高速总线矩阵节点相连时,较高频的矩阵节点作为主端,较低频的矩阵节点作为从端。
31.根据本发明优选的,缓速总线矩阵节点中,由高速总线矩阵节点发出的控制信号,两个dma、一个core的三组总线作为matrix的主端,flash、sram、low speed bus、bridge作为matrix的从端,其中每一个主端都配置相应从端的访问权限,在无节点访问的通道上,两组或者多组通道同步进行。
32.上述基于risc-v指令集的多矩阵节点总线拓扑结构的工作方法,包括步骤如下:
33.每个矩阵节点独立工作在不同的电压域下,每个矩阵节点是指高速总线矩阵节点、缓速总线矩阵节点及低速总线矩阵节点中的任一节点;
34.最开始,对于带有flash的各个矩阵节点,将flash中的bootloader读取出来,对于没有flash的矩阵节点,带有flash的矩阵节点将其中的数据通过dma或者core搬运到没有flash的矩阵节点;在各个矩阵节点都工作之后,交互的数据也通过dma或者core搬运到有flash的矩阵节点当中;
35.各个矩阵节点电压关断前,需要通过算法延迟几个周期之后,等待矩阵节点中的数据处理完成后,再通过电压开关关断此电压域;对于能将数据搬运到其他矩阵节点执行的,将数据搬运到其他节点后,再通过电压开关关断此电压域。
36.本发明的有益效果为:
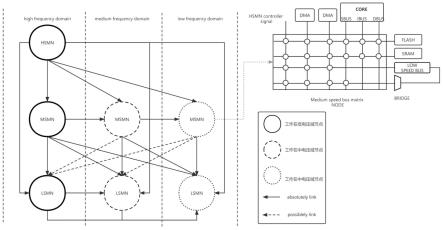
37.1、本发明通过设计三种矩阵节点,以满足不同情况下的功耗性能比,由于每个矩阵节点都可以独立工作,仅最大化的根据当前的性能需要来决定当前的功耗需要,是一种典型的用面积换取功耗的设计方式。
38.2、本发明通过设计多级的工作电压模式,以满足同一种矩阵节点在不同电压或者不同工作频率的工作模式,让同级的矩阵节点也能够相互连接,保持正常的通信和工作状态。
39.3、本发明设计了每种矩阵节点的内部节点,根据矩阵节点内部的不同通路来决定,访问权限,同时提供了在极低功耗模式下的dmap工作模式,在没有core的节点也能进行外设的数据交互。
40.4、本法明设计了两种保证数据一致性不需要二级cache的设计方法,一种是通过指令滤波来保证每个矩阵节点的输入指令能被矩阵节点的核执行并识别,另一种方法是通过给每个矩阵节点设立独立的存储空间,并提供跨节点的内存保护。
41.5、本发明通过将以上的几点结合,设计了一种全新的总线拓扑结构,这种拓扑结构由上述的三种节点组成,节点(除hsmn以外)最多可工作在三个不同的电压域,由此构成最多七个数据节点,数据节点的关系分为absolutely link和possible link,absolutely link是一定能访问的节点关系,possible link是不建议作为possible link的起始端作为主端的节点关系。
附图说明
42.图1是本发明提出的基于risc-v指令集的多矩阵节点总线拓扑结构及其工作方法和节点之间的连接关系以及节点的种类划分示意图;
43.图2是本发明利用总线拓扑结构设计的五节点三核soc的示意图。
具体实施方式
44.下面结合说明书附图和实施例对本发明作进一步限定,但不限于此。
45.实施例1
46.一种基于risc-v指令集的多矩阵节点总线拓扑结构,包括一个高速总线矩阵节点、多个缓速总线矩阵节点及多个低速总线矩阵节点;
47.每个矩阵节点通过总线通道不同的宽度、不同的工作频率或者不同的工作电压,这一部分通过电压控制器或者分频器来实现,来控制功耗形成效率差,同时,保持正确的节点通信方向。
48.实施例2
49.根据实施例1所述的一种基于risc-v指令集的多矩阵节点总线拓扑结构,其区别在于:
50.低速总线矩阵节点中,dmap和其它缓速总线矩阵节点或高速总线矩阵节点作为低速总线矩阵节点的主端,此外,高速总线矩阵节点来的控制信号需要通过一个bridge到达低速总线矩阵节点;低速总线矩阵节点和小于128kb的sram作为低速总线矩阵节点的从端;容量较小的sram配置自己独立工作电压域,在关闭低速总线矩阵节点的电压域后,仍能保持正常的工作,存储外设到其中的数据。
51.缓速总线矩阵节点中,dma、可配置的核和高速总线矩阵节点发出的控制信号作为缓速总线矩阵节点的主端;高速总线矩阵节点来的控制信号需要通过一个bridge到达缓速总线矩阵节点;外设例如常见的flash,sram等作为缓速总线矩阵节点的从端。
52.高速总线矩阵节点中,一个高性能的核、dma、以及其它可配置的加速器作为高速总线矩阵节点的主设备;在缓速总线矩阵节点在有独立核而无flash存放bootloader的情况下,在高速总线矩阵节点的从端配置用于存放缓速总线矩阵节点的启动程序,在soc工作之后,通过高性能的核的程序来控制dma,将缓速总线矩阵节点的启动程序搬运到缓速总线矩阵节点的sram或者其它的存储单元中。一般一个系统中只有唯一的高速总线矩阵节点,并且高速总线矩阵节点使用的数据通道要多于缓速矩阵节点和低速矩阵节点。
53.实施例3
54.根据实施例1或2所述的一种基于risc-v指令集的多矩阵节点总线拓扑结构,其区别在于:
55.电压控制单元和电压域的划分,整个soc整体分为三种电压域,分别为主域、备份域和模拟电压域,其中,每个矩阵节点都工作在一个主域,通过不同的power gating来独立工作,或者,所有矩阵节点工作在不同的主域中,由电压制造频率差,使相同类型的矩阵节点有不同的工作频率满足低功耗的多样性。其中,adc,dac等模拟电路工作在模拟电压域,一些部分外设工作在备份域,备份域可以不通过没有power gating来控制。
56.不同矩阵节点的数据一致性相关问题:由于整个系统有可能存在多核并存的情况,所以是有可能造成数据冲突的可能性,在系统的设计中没有采用多级cache来解决数据一致性的冲突,主要原因是由于可能存在多种工作电压的情况下,cache会涉及到极为复杂的跨时钟域信号处理和cache一致性检测;但为解决系统中可能存在潜在的数据冲突,本发
明采用如下方法:
57.通过单向risc-v指令滤波,由于在msmn中可以配置单独的core而不配置存储相应bootloader的flash,所以需要将hsmn中的启动程序通过dma搬运到msmn当中,但是由于两个节点的指令集不一定兼容,所以容易将原应该被hsmn执行,msmn中却无法识别的指令错误搬运到msmn的存储器当中,为解决这种问题,由于msmn和hsmn之间的通信必须通过一组bridge,所以,高速总线矩阵节点与缓速总线矩阵节点之间的bridge中添加单向指令滤波器。如果程序操作错误将无法执行的指令通过bridge发送到msmn当中将会保持原数据不动,并且发出短暂的中断指令,以此指令的下一地址作为此中断信号的中断向量。
58.高速总线矩阵节点与每一个缓速总线矩阵节点、每一个低速总线矩阵节点进行数据通信,在搬运指令时遵循指令滤波的原则;
59.高速总线矩阵节点作为缓速总线矩阵节点、低速总线矩阵节点的主端;
60.缓速总线矩阵节点中,同级的缓速总线矩阵节点相连,保证不同的缓速总线矩阵节点有一定的主频差(通过电压和频率调节单元来分配),以工作频率较高的缓速总线矩阵节点作为两个缓速总线矩阵节点的主端,工作频率较低的缓速总线矩阵节点作为两个缓速总线矩阵节点的从端;
61.缓速总线矩阵节点在和高速总线矩阵节点连接时,缓速总线矩阵节点作为从端;在缓速总线矩阵节点和低速总线矩阵节点相连时,在与同频及更低频的低速总线矩阵节点交互时,缓速总线矩阵节点作为主端;在和高频lsmn相连时,需要对lsmn做降频或者降压处理,否则容易引起数据冲突;
62.低速总线矩阵节点中,在低速总线矩阵节点和同频或者更高频的缓速总线矩阵节点相连时,低速总线矩阵节点作为同频或者更高频的缓速总线矩阵节点的从端;在低速总线矩阵节点和高速总线矩阵节点相连时,较高频的矩阵节点作为主端,较低频的矩阵节点作为从端。延续这种设计方法不易产生数据冲突,并且不但能保持低功耗的各种情况下的控制,还能延续设计的合理性。
63.在每一个矩阵节点中,都有着几组内部节点,每一个内部节点代表主端能否方位对应节点的从端,缓速总线矩阵节点中,由高速总线矩阵节点发出的控制信号,两个dma(dma1、dma2)、一个core的三组总线作为matrix的主端,flash、sram、low speed bus、bridge作为matrix的从端,其中每一个主端都配置相应从端的访问权限,在无节点访问的通道上,两组或者多组通道同步进行。如dma1在访问flash的同时,没有内部节点冲突的dma2也可以访问sram但不能访问flash。
64.三种矩阵节点每一个矩阵节点都有自己的独立的存储空间,高速总线矩阵节点和缓速总线矩阵节点都独自执行自己单独的启动程序,但是soc允许跨节点的数据交互,高速总线矩阵节点和缓速总线矩阵节点的dma只搬运存储器到存储器的传输类型,只有矩阵内部的节点不被占用才能搬运数据,在矩阵节点被占用时,需等待节点占用时间结束,或者通过中断程序强行中断矩阵内部节点。
65.图1是提出的基于risc-v指令集的多矩阵节点总线拓扑结构及其工作方法和节点之间的连接关系以及节点的种类划分示意图;图1列举了7种矩阵节点,其中由上到下代表矩阵节点种类的不同,有左到右代表工作的电压范围不同,电压或者频率范围由实线和虚线划分,矩阵节点种类由图1中的名称划分,矩阵节点之间的箭头代表主端和从端的连接方
向,连线的实线代表可以访问的矩阵节点,虚线代表访问前需要做降频或者降压处理才能访问的矩阵节点,图1中的电路为矩阵节点放大后真实的电路架构。
66.实施例4
67.实施例1-3任一所述的基于risc-v指令集的多矩阵节点总线拓扑结构的工作方法,包括步骤如下:
68.每个矩阵节点独立工作在不同的电压域下,每个矩阵节点是指高速总线矩阵节点、缓速总线矩阵节点及低速总线矩阵节点中的任一节点;
69.最开始,对于带有flash的各个矩阵节点,将flash中的bootloader读取出来,对于没有flash的矩阵节点,带有flash的矩阵节点将其中的数据通过dma或者core搬运到没有flash的矩阵节点;在各个矩阵节点都工作之后,交互的数据也通过dma或者core搬运到有flash的矩阵节点当中;
70.由于每个矩阵节点可以独立关断,各个矩阵节点电压关断前,需要通过算法延迟几个周期之后,等待矩阵节点中的数据处理完成后,再通过电压开关关断此电压域;对于能将数据搬运到其他矩阵节点执行的,将数据搬运到其他节点后,再通过电压开关关断此电压域。比如,将缓速总线矩阵节点中的数据搬运到高速总线矩阵节点中,此时内部的电压域分批关闭,先将缓存中的指令和数据搬运到sram或者flash中,然后关闭缓速总线矩阵节点中core的电压,在可执行的指令传输到高速总线矩阵节点之后,再关闭存储的电压。
71.实施例5
72.根据实施例4所述的基于risc-v指令集的多矩阵节点总线拓扑结构的工作方法,其区别在于:
73.为便于说明,图2是利用总线拓扑结构设计的五节点三核soc的示意图;其中,一个工作在高频域高速总线矩阵节点,两个分别工作在中、高频域的缓速总线矩阵节点以及两个分别工作在中、高频的低速总线矩阵节点;将图2的所有矩阵节点重新命名,高速总线矩阵节点命名为节点1,两个分别工作在高、中频域的缓速总线矩阵节点命名为节点2和节点3,即图2上方的三个矩阵由左到右依次为节点1、节点2、节点3,最后两个工作在高、中频域的低速总线矩阵节点命名为节点4和节点5,即图2下方的两个从左到右依次为节点4、节点5;
74.再简单介绍一下各个节点的组成,其中节点1由一个性能较高的核和11通道以上的dma作为节点1的主端,两个flash(及flash的控制器),一个sram和通向其中一个缓速总线矩阵节点和一个低速总线矩阵节点的bridge(另一个缓速总线矩阵节点当中有自己的flash,在整体soc的设计上就没有设计这条通路,否则连线太长有可能引起时序违例),两个缓速总线矩阵节点基本相同,都是由一个高节点的访问信号,两个7或5通道的dma和一个core作为节点的主端,从端设计到存储单元和连接外设的低速总线,两个低速总线矩阵节点也基本相同,但在低速总线矩阵节点的从端没有放置存储单元,只有两组连接外设的低速中线。
75.一组完整的全节点共同工作模式下,各个节点的工作方式;
76.节点1和节点3同时将存放在各自矩阵中flash的指令搬运到核中的指令耦合存储单元或者cache当中,在节点1的核收到将另一个flash的数据搬运到节点2的指令后,对同节点的dma发出命令;
77.由于此时不存在内部节点冲突,dma将另一个flash的数据搬运到节点2中的存储单元(在这种节点跨频传输的方式中,由于写速率高于读速率,所以在节点2的双端口存储器中写操作不占用访问节点),与此同时节点1和节点3仍正常执行各自的指令,其中节点3收到去访问节点5数据的指令,节点2收到去依次访问节点4和节点5同一外设的指令,在这种情况下在节点5可能会出现多主访问的情况引起仲裁;
78.节点2访问节点4由于不存在仲裁情况所以可以正常访问,节点5由于节点2、节点3同时访问,所以引起仲裁,这里的仲裁算法采用正常的轮询仲裁,轮询的起始由高频域开始轮询,所以由节点2优先访问节点5;
79.节点1的dma由于仍在将指令搬运到节点2当中,在搬运过程通过risc-v指令滤波发现一条节点2执行不了的指令,此时将节点1的搬运程序中断(由dma发出,将中断向量定在此条指令的下一条,由于这种指令错误是偶然发生所以可以通过中断进行程序终止),与此同时节点2在执行指令,访问节点3当中的数据,访问结束后程序结束;
80.上述主要描述了在这种5节点的拓扑结构里,所有的节点连接方式,跨频域dma工作方式和节点占用,内部节点的多主仲裁,指令滤波引起的程序中断。
81.描述各个节点在功耗不同的情况下独立或者部分节点组联合工作的工作模式;
82.以在所有节点同时工作为开始,由于性能需求下降不需要高速总线矩阵节点的高功耗模式进行工作,所以通过power gating关闭高速总线矩阵节点,在关断前先关断flash的读通道,然后将当前寄存器中的数据保存到always on cell中,两个缓速总线矩阵节点和两个低速总线矩阵节点仍在正常工作,此时,缓速总线矩阵节点的core和dma都可以正常访问其他节点,高速总线矩阵节点的pdma;
83.随着性能需求的进一步降低,依次关闭两个缓速总线矩阵节点的power gating,使整个系统依次进入单核和无核的工作模式,在单核模式下的关断顺序和高速总线矩阵节点的关断顺序一致,程序依旧保存到各个单元即可;
84.在进入到无核模式下,由于dmap无法识别指令,需要在缓速总线矩阵节点关断前将外设存储空间的搬运指令发送到两个低速总线矩阵节点中,在两个低速总线矩阵节点收到搬运指令后,就能在core休眠状态下通过dmap运行搬运不同外设的数据,由于图2中的节点4、节点5无存储单元,固在缓速总线矩阵节点和高速总线矩阵节点都关闭后,节点4、节点5的dmap只能进行外设和外设的传输方式;
85.最后,在最低功耗的模式下,只有节点5仍在工作,它可以执行节点2发送到节点4的访问节点5数据的未完成指令,也可以执行节点2或节点3访问节点5的未完成指令,此时dmap可由节点2、节点3节点的核在关断前进行驱动,也可在无核模式下由外设中断发起。
86.以上实例描述了各个节点在低功耗模式下的单独或者组合工作模式,这种工作模式也是多矩阵节点总线拓扑结构的性能优势之一,结合以上两个实例能够看出这种矩阵节点拓扑结构,能在不需要考虑一致性协议的情况下完成多核的协同工作和功耗模式较多的可控性选择,同时插入risc-v指令滤波器和独立的节点存储单元,最大化的适应各种risc-v内核的多种接口选择。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1