基于FPGA实现的运动活动识别模型的模型训练方法及其设备
基于fpga实现的运动活动识别模型的模型训练方法及其设备
技术领域
1.本技术主要涉及神经网络技术领域,尤其涉及一种基于fpga实现的运动活动识别模型的模型训练方法、终端设备以及计算机可读存储介质。
背景技术:
2.人体日常运动行为与人的健康指标、能量平衡有着密切联系例如可以通过对跑步,走路等运动行为的监测计算出个人的能量消耗,这在个人的健康运动以及身体能量平衡等方面具有积极的意义。另外,通过对人体异常运动行为(如跌倒等)的识别可以有效的对出现危险状况的个人进行及时救助。但这些工作的前提是需要研究出一种面向用户的实时的,便携的小型化的设备来支撑例如神经网络特征提取,分类器等算法的技术实现。
3.智能手机的日益普及和广泛接受,加上大量的嵌入式传感器,为采用手机作为数据采集手段开辟了一条道路。通过采集加速度计、陀螺仪等移动传感器的传输信号,可以根据人体的运动加速度和角旋转速度进行人体运动分析。除了数据获取,边缘智能(edgeai)的最新进展引入了开发自给式人工智能设备的另一个有趣的视角。edgeai在智能手机上使用预先训练的模型以低延迟实时提供按需预测,而不是依赖于训练模型的云部署。这样的进步提供了引人注目的生态系统来建模人类活动识别(har),以便随着时间的推移快速而准确地对个人的活动模式进行个性化。然后可以将其整合到用于视频监控、患者康复、娱乐和智能家居的系统的开发管道中。
4.fpga作为边缘计算的一种形式在信号处理中已经得到了广泛的应用,其作为一种半定制电路,克服了在专用集成电路(asic)领域中定制电路不可编程的缺点,同时庞大数量的逻辑单元也使得可编程器件灵活性更好、应用领域更广。基于这些特点国内外很多研究者深入探索利用fpga高效、低功耗等优点提高运动信号处理算法的实时性和能效性。
5.人类活动识别(har)有几个重要的应用程序,包括医疗监控、安全和监视、辅助生活、智能家居以及视频搜索和索引。尽管最近在这一领域取得了进展,但仍然存在重大挑战,需要非常高的精确度才能有效地应用到实际应用中,从老年护理到显微外科设备。深度学习模型可以实现最高的精确度,但这些模型不容易部署在资源非常有限的手持或可穿戴设备中。
6.目前在人体运动行为识别领域已经诞生了很多性能优异的深度学习算法模型,例如cnn以及gnn,但是这些模型都具有较高的层数以及模型复杂度,计算量大使得中间层产生的输出和权重参数量激增,这样也就带来了对硬件需求高,很难完成实时处理以及便携性差等问题,虽然前辈做了人体运动行为识别硬件化的研究,但是部分利用verilog,vhdl硬件描述语言进行开发,其具有开发周期长、成本高、难度大以及调试困难等缺点。且有技术利用vivado hls完成了神经网络模型的fpga实现,但只限于硬件的加速化研究,并没有通过实际应用背景来具体化设计。
技术实现要素:
7.本技术提供了一种基于fpga实现的运动活动识别模型的模型训练方法、终端设备以及计算机可读存储介质。
8.为解决上述技术问题,本技术提供了一种基于fpga实现的运动活动识别模型的模型训练方法,所述模型训练方法包括:
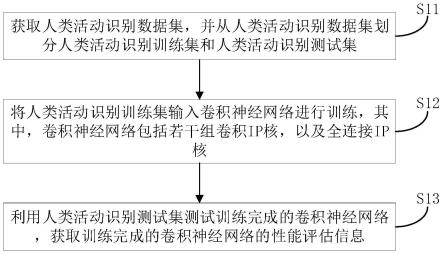
9.获取人类活动识别数据集,并从所述人类活动识别数据集划分人类活动识别训练集和人类活动识别测试集;
10.将所述人类活动识别训练集输入卷积神经网络进行训练,其中,所述卷积神经网络包括若干组卷积ip核,以及全连接ip核;
11.利用所述人类活动识别测试集测试训练完成的卷积神经网络,获取所述训练完成的卷积神经网络的性能评估信息。
12.其中,所述卷积ip核包括卷积层、归一化层以及激活函数。
13.其中,所述卷积ip核的详细运算过程如下:
[0014][0015]
其中,每个输出矩阵的大小是n-m+l,其中,中的l表示第l个卷积层,i表示第i个卷积输出矩阵的某个值,j表示对应的输出矩阵的编号,从左往右依次表示为0到n,n表示卷积输出矩阵的个数。f表示非线性激活函数。
[0016]
其中,所述归一化层的详细运算过程如下:
[0017][0018]
其中,μ为一个batch内的均值,σ2为一个batch内的标准差,ε为一个预设常数,γ和β均为一个可学习的参数,在训练过程中,和其他卷积核的参数一样,通过梯度下降来学习。
[0019]
其中,所述全连接ip核设置于所述卷积神经网络的输出端,用于实现所述卷积神经网络最终的分类输出。
[0020]
其中,所述将所述人类活动识别训练集输入卷积神经网络进行训练之后,所述模型训练方法还包括:
[0021]
将所述训练完成的卷积神经网络的权值参数和偏置参数保存为预设文件格式,并存入初始化的存储卡,输入到测试平台进行测试。
[0022]
其中,所述利用所述人类活动识别测试集测试训练完成的卷积神经网络,获取所述训练完成的卷积神经网络的性能评估信息,包括:
[0023]
将所述人类活动识别测试集传输到所述测试平台,以使所述测试平台按照所述人类活动识别测试集对所述存储卡中的权值参数和偏置参数组成的卷积神经网络进行测试;
[0024]
获取所述测试平台上的卷积神经网络返回的分类结果;
[0025]
基于所述分类结果计算所述卷积神经网络的性能评估信息。
[0026]
其中,所述性能评估信息的类型包括平均准确率、查全率、查准率以及f1值中的一种或多种指标类型。
[0027]
为解决上述技术问题,本技术提供了一种终端设备,其中,所述终端设备包括处理器、与所述处理器连接的存储器,其中,所述存储器存储有程序指令;
[0028]
所述处理器用于执行所述存储器存储的程序指令以实现如上述基于fpga实现的运动活动识别模型的模型训练方法。
[0029]
为解决上述技术问题,本技术提供了一种计算机可读存储介质,所述存储介质存储有程序指令,所述程序指令被执行时实现上述基于fpga实现的运动活动识别模型的模型训练方法。
[0030]
与现有技术相比,本技术的有益效果是:终端设备获取人类活动识别数据集,并从所述人类活动识别数据集划分人类活动识别训练集和人类活动识别测试集;将所述人类活动识别训练集输入卷积神经网络进行训练,其中,所述卷积神经网络包括若干组卷积ip核,以及全连接ip核;利用所述人类活动识别测试集测试训练完成的卷积神经网络,获取所述训练完成的卷积神经网络的性能评估信息。本技术通过以fpga作为硬件平台,鉴于fpga在深度学习加速方面的可行性,研究人体行为识别模型的fpga实现;在基于uci-har的人体运动识别上,搭建了一个具有bn融合结构的卷积神经网络用于硬件实现,减少了内存的消耗,并取得非常好的分类结果。
附图说明
[0031]
为了更清楚地说明本发明实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。其中:
[0032]
图1是本技术提供的基于fpga实现的运动活动识别模型的模型训练方法一实施例的流程示意图;
[0033]
图2是本技术提供的软硬件协同设计的设计方案总体框架示意图;
[0034]
图3是本技术提供的基于fpga实现的运动活动识别模型的模型训练方法的整体流程示意图;
[0035]
图4是本技术提供的卷积神经网络一实施例的框架示意图;
[0036]
图5是本技术提供的vivado hls设计流程的示意图;
[0037]
图6是本技术提供的卷积层ip核一实施例的框架示意图;
[0038]
图7是本技术提供的全连接层ip核一实施例的框架示意图;
[0039]
图8是本技术提供的pc端训练测试结果以及vitis下通过串口返回的测试结果的示意图;
[0040]
图9是本技术提供的终端设备的一实施例的框架示意图;
[0041]
图10是本技术提供的计算机存储介质一实施例的结构示意图。
具体实施方式
[0042]
下面将结合本技术实施例中的附图,对本技术实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅是本技术的一部分实施例,而不是全部的实施例。基于本技术中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他
实施例,都属于本技术保护的范围。
[0043]
本技术领域技术人员可以理解,除非特意声明,这里使用的单数形式“一”、“一个”、“所述”和“该”也可包括复数形式。应该进一步理解的是,本发明的说明书中使用的措辞“包括”是指存在所述特征、整数、步骤、操作、元件和/或组件,但是并不排除存在或添加一个或多个其他特征、整数、步骤、操作、元件、组件和/或它们的组。应该理解,当本技术称元件被“连接”或“耦接”到另一元件时,它可以直接连接或耦接到其他元件,或者也可以存在中间元件。此外,这里使用的“连接”或“耦接”可以包括无线连接或无线耦接。这里使用的措辞“和/或”包括一个或更多个相关联的列出项的全部或任一单元和全部组合。
[0044]
本技术领域技术人员可以理解,除非另外定义,这里使用的所有术语(包括技术术语和科学术语),具有与本发明所属领域中的普通技术人员的一般理解相同的意义。还应该理解的是,诸如通用字典中定义的那些术语,应该被理解为具有与现有技术的上下文中的意义一致的意义,并且除非像这里一样被特定定义,否则不会用理想化或过于正式的含义来解释。
[0045]
针对上述现有技术的问题,本文提出了一种高泛化性的卷积神经网络结构,借助vivado高层次综合(hls)等设计工具,通过例如并行化以及数组分割等优化指令来实现硬件加速,以fpga作为硬件平台,鉴于fpga在深度学习加速方面的可行性,研究人体运动行为识别算法模型的fpga实现。
[0046]
本技术以fpga(现场可编程逻辑门阵列,field programmable gate array)作为硬件平台,鉴于fpga在深度学习加速方面的可行性,提出了一种卷积神经网络模型来研究人体运动行为识别的fpga实现。系统采用软硬件协同设计的方法,通过uci-har数据集对步行、上楼、下楼、静坐、站立、平躺六类动作进行分类验证,可用于判别对象的活动状态。其技术范畴主要包括了信号处理、深度学习以及fpga设计,是一个基于信号的机器学习分类以及硬件化加速问题。
[0047]
具体请参阅图1至图3,图1是本技术提供的基于fpga实现的运动活动识别模型的模型训练方法一实施例的流程示意图,图2是本技术提供的软硬件协同设计的设计方案总体框架示意图,图3是本技术提供的基于fpga实现的运动活动识别模型的模型训练方法的整体流程示意图。
[0048]
如图1所示,本实施例的基于fpga实现的运动活动识别模型的模型训练方法具体包括以下步骤:
[0049]
步骤s11:获取人类活动识别数据集,并从人类活动识别数据集划分人类活动识别训练集和人类活动识别测试集。
[0050]
在本技术实施例中,终端设备,即图2中的pc端获取uci-har人类活动识别数据集作为模型训练的源数据。其中,uci-har人类活动识别数据集是以智能手机采集的传感器数据为基础的活动识别,创建于2012年,实验团队来自意大利热那亚大学。
[0051]
uci-har人类活动识别数据集是从30名年龄在19岁到48岁之间的志愿者身上收集的,这些志愿者将智能手机绑在腰间,进行6项标准活动中的一项,通过开发的手机软件记录运动数据。同时记录每个执行活动的志愿者的视频,后期根据这些视频和传感器数据进行手动标记所属运动类别,类似剪辑视频中的音画同步。使用其嵌入式加速度计和陀螺仪,本技术以50hz的恒定速率捕获了3轴线性加速度和3轴角速度。实验已被录像以手动标记数
据。执行的六项活动分别为:walking(行走)、walking upstairs(向上走)、walking downstairs(向下走)、sitting(坐)、standing(站)、laying(睡)。
[0052]
终端设备还可以对原始的uci-har人类活动识别数据集中的数据进行预处理。
[0053]
在一种具体的实施例中,数据集中传感器信号通过应用噪声滤波器进行预处理,然后在2.56秒和50%重叠的固定宽度滑动窗口中进行采样(128个读数/窗口),从每个窗口通过九维采样数据来构建一个9*128大小的特征图,这些数据被随机分成两组,其中70%被选择用于生成训练数据,30%用作测试数据。
[0054]
步骤s12:将人类活动识别训练集输入卷积神经网络进行训练,其中,卷积神经网络包括若干组卷积ip核,以及全连接ip核。
[0055]
在本技术实施例中,将训练集放入卷积神经网络结构中进行训练,本发明所采用的卷积神经网络结构如图4所示,图4是本技术提供的卷积神经网络一实施例的框架示意图。
[0056]
如图4所示,本技术的卷积神经网络由若干组卷积ip核,以及全连接ip核,其中,每一组卷积ip核包括卷积层、归一化层以及激活函数,而全连接ip核则设置于卷积神经网络的输出端,用于实现所述卷积神经网络最终的分类输出。
[0057]
具体地,在卷积神经网络中批归一化(batch normalization,bn)因其可以加速神经网络训练、使网络训练更稳定,而且还有一定的正则化效果,所以得到了非常广泛的应用,训练过程中bn层的运算如下:
[0058][0059]
其中,μ为一个batch内的均值,σ2为一个batch内的标准差,ε为一个预设常数,例如0.001,γ和β均为一个可学习的参数,在训练过程中,和其他卷积核的参数一样,通过梯度下降来学习。
[0060]
在python训练时候,在卷积层后面直接加bn层,但是,训练完成后进入硬件设计阶段,bn层一般是可以完全融合到前面的卷积层的,而且丝毫不影响性能,在本技术的实施例中只需要将网络中bn层去掉,读取原来的卷积层权重和偏置,以及bn层的四个参数(均值μ,方差σ2,γ,β),将其融合为一个conv+bn+relu的结构(通过vivado hls将其设计为conv2d用户ip核)。
[0061]
最终将python环境下训练得到的卷积神经网络模型结构中卷积层中的权值参数(w)和偏置参数(b)保存为bin文件并存入初始化后的sd卡中。
[0062]
在一种具体实施例中,终端设备可以利用vivado hls完成上述算法ip核设计。
[0063]
如图5所示,图5是本技术提供的vivado hls设计流程的示意图。在图5中,vivado hls的设计流程首先是编译、执行(模拟)和调试c算法;可选地使用用户优化指令,将c算法合成到rtl(寄存器转换级电路,register transfer level)实现中;综合生成全面的报告,并对设计进行分析;联合仿真验证rtl实现;并最终将rtl实施打包成多种ip格式。
[0064]
下面分别介绍本技术中需要设计的两种算法ip核的设计:
[0065]
1)conv2d卷积ip核
[0066]
对卷积层的算法设计最终生成的用户ip核如图6所示,其中,图6是本技术提供的卷积层ip核一实施例的框架示意图。
[0067]
卷积层作为cnn中最重要的一层,通过卷积运算对图像的隐藏特征信息进行提取,相比于传统神经网络,cnn使用了稀疏交互和权值共享两大核心思想。源于对生物视觉细胞局部感受野的理解,卷积神经网络采用局部过滤器,进行卷积过程,即取输入项的局部子矩阵与局部过滤器进行内积运算,输出结果作为卷积输出矩阵的对应维数的值,详细运算过程如下式所示:
[0068][0069]
其中,每个输出矩阵的大小是n-m+l,其中,中的l表示第l个卷积层,i表示第i个卷积输出矩阵的某个值,j表示对应的输出矩阵的编号,从左往右依次表示为0到n,n表示卷积输出矩阵的个数。f表示非线性激活函数。在本技术实施例中,非线性激活函数可以采用relu函数。
[0070]
2)fc全连接ip核
[0071]
对全连接层的算法设计最终生成的用户ip核如图7所示,其中,图7是本技术提供的全连接层ip核一实施例的框架示意图。
[0072]
全连接运算是特殊的卷积运算,全连接层的每一个结点都与上一层的所有结点相连,用来把前边提取到的特征综合起来。由于其全相连的特性,一般全连接层的参数也是最多的,因此为了减少参数,硬件实现中本技术尽量保证神经网络模型中拥有较少的全连接操作,全连接层只用于最终的分类输出。
[0073]
步骤s13:利用人类活动识别测试集测试训练完成的卷积神经网络,获取训练完成的卷积神经网络的性能评估信息。
[0074]
在本技术实施例中,模型训练完成后,通过测试集中的心拍数据对模型分类性能进行验证,实验结果显示卷积神经网络模型在训练集上的平均准确率为99.92%,在测试集上的平均准确率为96.27%。
[0075]
在上述描述中,具体介绍了运动行为识别系统的硬件实现。本系统基于zynq-7020平台的arm+fpga硬件结构,采用软硬件协同仿真的设计方法来实现常见人体行为动作的六分类算法。硬件部分首先通过vivado hls 2019.2工具设计实现卷积神经网络卷积层及全连接层ip核,通过vivado 2019.2工具建立块设计(block design)配置连接ip核搭建硬件平台,通过vitis软硬件协同设计在fpga开发板上实现运动行为识别系统,最后对算法的fpga设计和实现做了测试和分析。
[0076]
此系统总体分为pc端和fpga venes2平台(zynq-7020核心板的zynq芯片型号为xc7z020clg400-2,pl逻辑单元达85k,bram存储资源为4.9mbit)两个部分,pc端一方面是用作与fpga平台进行串口数据传输,其次需要将pc端训练好的卷积神经网络权值参数导入fpga平台;fpga平台的ps部分主要负责控制驱动各个接口,pl部分则负责卷积神经网络模型的运算加速。最终将计算结果通过串口返回给pc端进行显示,而设计方案的总体框图如图2所示。
[0077]
本技术arm+fpga的硬件结构即发挥了fpga逻辑控制对大量数据进行高速处理的优势,又结合了arm软件编程灵活的特点,其主要流程图如图3所示。
[0078]
具体地,pc端通过uart串口将人类活动识别测试集传输到fpga平台,然后将存储
有训练完成的卷积神经网络的权值参数和偏置参数sd卡插入fpga平台。fpga平台下载程序,加载卷积神经网络开始对人类活动识别测试集进行测试,以获取测试结果,即卷积神经网络的分类结果。fpga平台通过串口将测试结果返回给pc端,由pc端进行卷积神经网络的性能评估。
[0079]
在本技术实施例中,在算法的性能评估方面,除了平均准确率外,还选择了查全率(recall)、查准率(precision)、f1值(f1-score)这三个指标。对于数据集中的每个活动类别,将模型的预测与基本事实标签进行比较,以计算真阳性(tp)、真阴性(tn)、假阳性(fp)和假阴性(fn)的数量。总体精确度acc等于:
[0080][0081]
并且一个典型类别的查准率(precision)和召回率(recall)可以通过以下公式计算:
[0082][0083][0084]
其中,f1-score是查准率和召回率的平衡组合,其计算公式为:
[0085][0086]
在一种具体实施例中,由本技术提供的模型训练方法训练得到的卷积神经网络的性能评估情况如下表所示:
[0087]
表运动行为识别分类模型性能评估
[0088]
运动行为类型precision[%]recall[%]f1-score[%]walking98.61100.0099.30walking upstairs95.83100.0097.87walking downstairs100.0096.6798.31sitting95.0086.3690.48standing88.1694.3791.16laying100.00100.00100.00
[0089]
在本技术实施例中,终端设备训练了一种基于卷积神经网络的运动行为识别分类模型。将滤波后的uci-har动作识别数据库中的加速度,角速度,陀螺仪这九通道信号调整为9*128大小的特征矩阵,利用运动信号特征矩阵数据训练所提出的卷积神经网络模型,最终模型在测试集上进行验证的平均分类准确率为96.27%。在保证低延迟的条件下,本技术对资源利用方面也进行了优化,以适应给定的fpga。此外,本技术通过选择最符合条件的axi4协议来优化硬件和软件组件之间的通信。因此,本技术将系统的性能较于纯arm软件实现提高明显,并在高效利用有限的硬件资源的同时满足了实时约束。实现了基于fpga的运动行为识别系统。利用生成的高性能算法模块ip核,通过软硬件协同仿真设计,最终在xilinx zynq-7020开发平台上实现了分类准确率高、运算速度快、功耗低的运动行为识别系统。
[0090]
小型嵌入式处理器的性能由于成本、功耗和尺寸而受到限制,硬件加速通常会提高这些片上系统(soc)的性能,因此,当今的soc(例如xilinx zynqs)将arm处理器与fpga结合在一个芯片上。这结合了这两个领域的优点:系统的某些部分(例如操作系统)可以更好地在软件中执行,而与性能相关,并行度高的任务则更好地在硬件中实现。本文借助vivado高层次综合(hls)等设计工具,可以从c和c++代码进行硬件综合,尽管这些条件可以快速实现硬件加速,但必须进行设计优化以满足资源和性能限制;再者使用vivado hls开发避免了使用verilog或vhdl硬件描述语言进行开发,会具有开发周期长、成本高、难度大以及调试困难等缺点,本技术的主要有益效果如下:
[0091]
1.在基于uci-har的人体运动识别上,搭建了一个具有bn融合结构的卷积神经网络用于硬件实现,减少了内存的消耗,并取得非常好的分类结果。
[0092]
2.以fpga作为硬件平台,鉴于fpga在深度学习加速方面的可行性,研究人体行为识别模型的fpga实现。
[0093]
3.在保证低延迟的条件下,本技术对资源利用方面也进行了优化,以适应给定的fpga。此外,本技术通过选择最符合条件的协议来优化硬件和软件组件之间的通信。因此,本技术将系统的性能较于纯arm软件实现大幅提高,并在高效利用有限的硬件资源的同时满足了实时约束。最终,本技术实现了将硬件ip核集成到了一个复杂的嵌入式系统中。
[0094]
本技术采取了来自uci的uci-har对算法进行验证,uci数据集是一个常用的机器学习标准测试数据集,是加州大学欧文分校(university of californiairvine)提出的用于机器学习的数据库。机器学习算法的测试大多采用的便是uci数据集,其重要之处在于“标准”二字,新编的机器学习程序可以采用uci数据集来进行测试,类似的机器学习算法也可以一较高下。
[0095]
具体的pc端训练测试结果以及vitis下通过串口返回的测试结果如图8所示,虽然会因为硬件的定点量化从而损失一些准确度百分比,但不会影响整体系统性能。
[0096]
为实现上述实施例中的基于fpga实现的运动活动识别模型的模型训练方法,本技术还提供另一种终端设备300,具体请参见图9,本技术实施例的终端设备300包括处理器31、存储器32、输入输出设备33以及总线34。
[0097]
该处理器31、存储器32、输入输出设备33分别与总线34相连,该存储器32中存储有程序数据,处理器31用于执行程序数据以实现上述实施例所述的基于fpga实现的运动活动识别模型的模型训练方法。
[0098]
在本技术实施例中,处理器31还可以称为cpu(central processing unit,中央处理单元)。处理器31可能是一种集成电压控制系统芯片,具有信号的处理能力。处理器31还可以是通用处理器、数字信号处理器(dsp,digital signal process)、专用集成电压控制系统(asic,application specific integrated circuit)、现场可编程门阵列(fpga,field programmable gate array)或者其它可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件。通用处理器可以是微处理器或者该处理器31也可以是任何常规的处理器等。
[0099]
本技术还提供一种计算机存储介质,请继续参阅图10,图10是本技术提供的计算机存储介质一实施例的结构示意图,该计算机存储介质400中存储有程序数据41,该程序数据41在被处理器执行时,用以实现上述实施例的基于fpga实现的运动活动识别模型的模型
训练方法。
[0100]
本技术的实施例以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。基于这样的理解,本技术的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的全部或部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)或处理器(processor)执行本技术各个实施方式所述方法的全部或部分步骤。而前述的存储介质包括:u盘、移动硬盘、只读存储器(rom,read-only memory)、随机存取存储器(ram,random access memory)、磁碟或者光盘等各种可以存储程序代码的介质。
[0101]
以上所述仅为本技术的实施方式,并非因此限制本技术的专利范围,方式利用本技术说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本技术的专利保护范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1