端到端的关系三元组抽取方法、装置、设备和介质与流程
本发明涉及到语义识别领域,具体而言,涉及到一种端到端的关系三元组抽取方法、装置、设备和介质。
背景技术:
1、关系三元组抽取定义为实体-关系联合抽取,是信息抽取领域中的一个经典任务,旨在从文本中抽取出结构化的关系三元组。关系三元组包括头实体-关系-尾实体。其中实体的定义是对客观个体的抽象,一个人、一部电影、一个地点都可以看作是一个实体,关系是实体与实体之间关系的抽象。
2、当前关系三元组的抽取方法存在两种。第一类为利用流水线式模型进行抽取,这种模型会使用一个序列标注模型识别文本中的实体;然后使用一个分类器对前面识别出来的实体进行两两之间关系的分类。这种做法会导致三个问题:1、类别分布不均衡问题;2、多三元组重叠问题;3、存在误差传递,即实体识别的误差会传递给关系分类。第二类是利用联合模型进行抽取,这种模型一般将实体识别模块和实体关系分类模块整合到一个模型内,让两者共享底层特征,并联合二者的损失值进行训练。这种方法相较于流水线式模型可以较好的解决类别分布不均衡以及多元三元组重叠的问题,但是因为实体和关系的预测还是存在相互依赖,还是存在一定的误差传递。
技术实现思路
1、本发明的主要目的为提供一种端到端的关系三元组抽取方法、装置、设备和介质,旨在解决关系三元组抽取时存在误差传递的技术问题。
2、本发明公开了以下技术方案:
3、一种端到端的关系三元组抽取方法,包括:
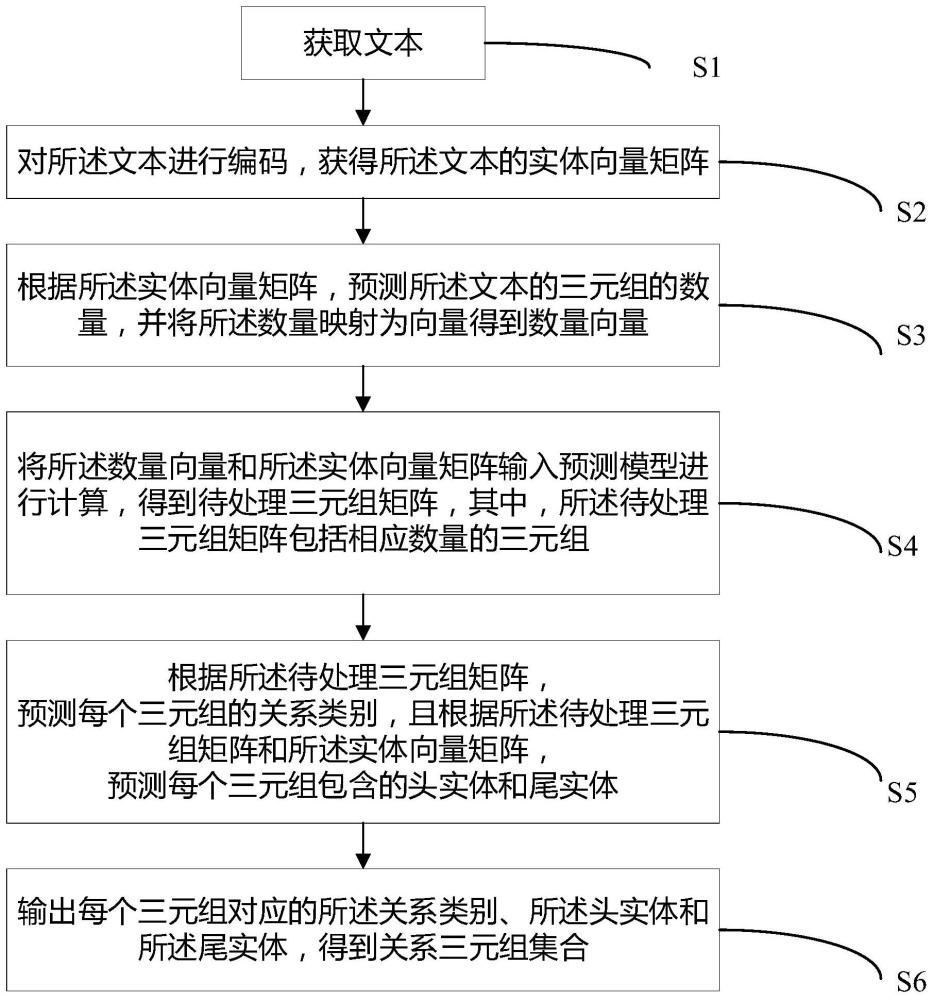
4、获取文本;
5、对所述文本进行编码,获得所述文本的实体向量矩阵;
6、根据所述实体向量矩阵,预测所述文本的三元组的数量,并将所述数量映射为向量得到数量向量;
7、将所述数量向量和所述实体向量矩阵输入预测模型进行计算,得到待处理三元组矩阵,其中,所述待处理三元组矩阵包括相应数量的三元组;
8、根据所述待处理三元组矩阵,预测每个三元组的关系类别,且根据所述待处理三元组矩阵和所述实体向量矩阵,预测每个三元组包含的头实体和尾实体;
9、输出每个三元组对应的所述关系类别、所述头实体和所述尾实体,得到关系三元组集合。
10、进一步地,所述根据所述待处理三元组矩阵和所述实体向量矩阵,预测每个三元组包含的头实体和尾实体的步骤,包括:
11、根据所述待处理三元组矩阵和所述实体向量矩阵,预测每个三元组包含的初始头实体和初始尾实体;
12、统计训练集中所有实体的长度数据;
13、对所述长度数据进行排序,并按照从大到小的顺序筛选出指定数量的长度数据;
14、统计所述指定数量的长度数据中的众数和最小值;
15、根据所述众数和所述最小值,形成实体长度限制区间;
16、根据所述实体长度限制区间,对所述初始头实体和所述初始尾实体进行截断,得到所述头实体和所述尾实体。
17、进一步地,所述预测模型由三层transformer模型组成,所述将所述数量向量和所述实体向量矩阵输入预测模型进行计算,得到待处理三元组矩阵的步骤,包括:
18、将所述数量向量和所述实体向量矩阵输入第一层所述transformer模型进行计算,得到第一结果;
19、将所述第一结果和所述实体向量矩阵输入第二层所述transformer模型进行计算,得到第二结果;
20、将所述第二结果和所述实体向量矩阵输入第三层所述transformer模型进行计算,得到待处理三元组矩阵。
21、进一步地,所述transformer模型包括多头自注意力机制层、多头互注意力机制层、ffn全连接层;所述将所述数量向量和所述实体向量矩阵输入第一层所述transformer模型进行计算,得到第一结果的步骤,包括:
22、将所述数量向量输入所述多头自注意力机制层进行计算,得到多头自注意力机制层结果;
23、将所述多头自注意力机制层结果和所述实体向量矩阵输入所述多头互注意力机制层进行计算,得到多头互注意力机制层结果;
24、将所述多头互注意力机制层结果输入所述ffn全连接层进行计算,得到第一结果。
25、进一步地,所述根据所述待处理三元组矩阵,预测每个三元组的关系类别的步骤,包括:
26、将所述待处理三元组矩阵代入下列公式进行计算,得到每个三元组的关系类别:
27、pr=softmax(wrd)
28、其中:pr为所述三元组的关系类别,wr为可训练的权重参数,d为所述待处理三元组矩阵。
29、进一步地,所述根据所述待处理三元组矩阵和所述实体向量矩阵,预测每个三元组包含的头实体和尾实体的步骤,包括:
30、将所述待处理三元组矩阵和所述实体向量矩阵代入下列公式中,得到三元组包含的头实体的起始位置和终止位置:
31、
32、
33、
34、其中:d为所述待处理三元组矩阵,e为所述实体向量矩阵,v1、w1、w2、v2、w3、w4均为可训练的权重参数,为头实体的起始位置,为头实体的终止位置,sstart为中间计算值;
35、将所述待处理三元组矩阵和所述实体向量矩阵代入下列公式中,得到三元组包含的尾实体的起始位置和终止位置:
36、
37、
38、
39、其中:v3、w5、w6、v4、w7、w8均为可训练的权重参数,为尾实体的起始位置,为尾实体的终止位置,ostart为中间计算值。
40、进一步地,所述对所述文本进行编码,获得所述文本的实体向量矩阵,包括:
41、使用ernie 2.0 base对所述文本进行编码。
42、本发明还提供一种端到端的关系三元组抽取装置,包括:
43、获取模块,用于获取文本;
44、实体向量矩阵生成模块,用于对所述文本进行编码,获得所述文本的实体向量矩阵;
45、三元组的数量向量生成模块,用于根据所述实体向量矩阵,预测所述文本的三元组的数量,并将所述数量映射为向量得到数量向量;
46、待处理三元组矩阵生成模块,用于将所述数量向量和所述实体向量矩阵输入预测模型进行计算,得到待处理三元组矩阵,其中,所述待处理三元组矩阵包括相应数量的三元组;
47、关系类别和头实体、尾实体生成模块,用于根据所述待处理三元组矩阵,预测每个三元组的关系类别,且根据所述待处理三元组矩阵和所述实体向量矩阵,预测每个三元组包含的头实体和尾实体;
48、关系三元组集合生成模块,用于输出每个三元组对应的所述关系类别、所述头实体和所述尾实体,得到关系三元组集合。
49、本技术还提供一种计算机设备,包括存储器和处理器,所述存储器存储有计算机程序,所述处理器执行所述计算机程序时实现上述任一项所述方法的步骤。
50、本技术还提供一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现上述任一项所述的方法的步骤。
51、有益效果:
52、在本发明中,将实体抽取和关系类别预测看成一个三元组整体,然后通过基于端到端的编码解码方式将三元组整体解码生成出来。本发明首先通过使用编码端来进行文本的向量表示;然后预测输入文本的三元组的数量,该数量和该文本的向量将作为端到端模型解码端的输入;最后通过非自回归的解码方式生成关系三元组集合。本发明将实体抽取和关系类别预测作为两个独立并行的步骤,不依赖对方的输出结果,解决了误差传递的问题,实体抽取的误差不会传递给关系分类,关系分类的误差不会传递给实体抽取,并且本发明的方案在时间和空间损耗上更小,能够取得准确性和时空间复杂度上的折中效果。
- 还没有人留言评论。精彩留言会获得点赞!