茶树种植区域提取方法及系统与流程
1.本技术涉及数据识别技术领域,特别是涉及一种茶树种植区域提取方法及系统。
背景技术:
2.茶树是我国重要的经济树种之一,茶树的种植面积和茶叶的产量常年位居世界第一,近年来我国茶园面积和产量也出现大幅增长的现象。茶树的扩张种植能够促进区域的经济发展,但是单一的树种会降低生态系统的生物多样性,加速水土流失、土壤酸化等生态环境问题。目前,茶园面积仅有统计数据,且多为茶农自主上报统计,具有很大的不确定性,且很难在空间上获取茶园种植区域。传统的获取空间分布的方法需要测绘人员挨家挨户使用专业测绘仪器测量、核对,需要投入大量的人力和物力,时间周期长,而且成本高,因此茶园种植区的数据很难获取或缺失。
3.传统的茶树种植区域提取方法一般使用基于遥感数据的二分类法。这种方法一般将茶树种植区域提取转化为二分类问题,这里采用遥感影像的特征分级方法,将遥感影像的色调或颜色纳入初级特征,将遥感影像的大小,形状和纹理特征纳入二级特征。基于遥感数据的二分类法具体是先采集遥感影像,再提取遥感影像的二级特征输入至二分类器中,输出分类结果。
4.传统的基于遥感数据的二分类法有如下问题:1)分类精度差,偏离实际情况。由于二分类法只能单纯的区分正样本(茶树种植区域)和负样本(非茶树种植区域),而正样本(非茶树种植区域)实际上样本组成非常复杂,正样本中包含很多与茶树特征十分相似的果园、林地等,不可避免的造成正样本数量高于实际值的现象,导致提取到的茶树种植区域的面积大于实际茶树种植区域的面积。
5.2)遥感影像特征选取单一。在利用遥感影像方面,基于遥感数据的二分类法计算或使用的是二级特征,没有使用更适用于茶树种植提取的更高级别的遥感图像特征,例如植被指数的纹理特征、植被指数的时序变化特征等。
6.3)此外,没有考虑茶树的地理环境和茶树生长特性的影响,例如某省茶树多种植于丘陵山地,平原地区也有少量分布。
技术实现要素:
7.基于此,有必要针对传统茶树种植区域提取方法分类精度差,遥感影像特征选取单一且没有考虑茶树的地理环境和茶树生长特性的影响的问题,提供一种茶树种植区域提取方法及系统。
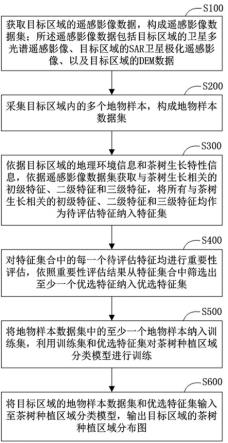
8.本技术提供一种茶树种植区域提取方法,所述茶树种植区域提取方法包括:获取目标区域的遥感影像数据,构成遥感影像数据集;所述遥感影像数据包括目标区域的卫星多光谱遥感影像、目标区域的sar卫星极化遥感影像、以及目标区域的dem数据;采集目标区域内的多个地物样本,构成地物样本数据集;
依据目标区域的地理环境信息和茶树生长特性信息,依据遥感影像数据集获取与茶树生长相关的初级特征、二级特征和三级特征,将所有与茶树生长相关的初级特征、二级特征和三级特征均作为待评估特征纳入特征集;对特征集合中的每一个待评估特征均进行重要性评估,依照重要性评估结果从特征集合中筛选出至少一个优选特征纳入优选特征集;将地物样本数据集中的至少一个地物样本纳入训练集,利用训练集和优选特征集对茶树种植区域分类模型进行训练;将目标区域的地物样本数据集和优选特征集输入至茶树种植区域分类模型,输出目标区域的茶树种植区域分布图。
9.本技术还提供一种茶树种植区域提取系统,包括:服务器,用于执行如前述内容提及的茶树种植区域提取方法;卫星多光谱遥感影像数据库,与所述服务器通信连接,用于存储卫星多光谱遥感影像;sar卫星极化遥感影像数据库,与所述服务器通信连接,用于存储sar卫星极化遥感影像;dem数据库,与所述服务器通信连接,用于存储dem数据。
10.本技术涉及一种茶树种植区域提取方法及系统,通过引入卫星多光谱遥感影像、sar卫星极化遥感影像和dem数据三种不同的遥感数据源,增加了遥感数据的多样性,通过同时获取与茶树生长相关的初级特征、二级特征和三级特征,构建了多层级遥感特征集,此外在获取特征时引入了目标区域的地理环境信息和茶树生长特性信息,充分考虑了茶树在生长过程中的生长环境,生长特性等重要因素,使得最终茶树种植区域分类模型的分类结果精度大大提升,更符合茶树的实际生长情况。
附图说明
11.图1为本技术一实施例提供的茶树种植区域提取方法的流程示意图。
12.图2为本技术一实施例提供的茶树种植区域提取系统的结构示意图。
13.图3为本发明一实施例提供的茶树种植区域提取方法中目标区域示意图。
14.图4为本发明一实施例提供的茶树种植区域提取方法中茶树种植区域地物样本分布示意图。
15.图5为本发明一实施例提供的茶树种植区域提取方法中重要性排名前四的遥感特征示意图。
16.图6为本发明一实施例提供的茶树种植区域提取方法中目标区域的茶树种植区域分布图。
17.附图标记:100-服务器;200-卫星多光谱遥感影像数据库;300-sar卫星极化遥感影像;400-dem数据库。
具体实施方式
18.为了使本技术的目的.技术方案及优点更加清楚明白,以下结合附图及实施例,对
本技术进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本技术,并不用于限定本技术。
19.一方面,本技术提供一种茶树种植区域提取方法。需要说明的是,本技术提供的茶树种植区域提取方法应用于大到市县,小到乡镇村,甚至是一个具体尺寸土地的茶树种植区域提取工作中。
20.此外,本技术提供的茶树种植区域提取方法不限制其执行主体。可选地,本技术提供的茶树种植区域提取方法的执行主体可以为一种茶树种植区域提取系统。具体地,本技术提供的茶树种植区域提取方法的执行主体可以为所述茶树种植区域提取系统中的服务器。
21.在本技术的一实施例中,所述茶树种植区域提取方法包括:s100,获取目标区域的遥感影像数据,构成遥感影像数据集。所述遥感影像数据包括目标区域的卫星多光谱遥感影像、目标区域的sar卫星极化遥感影像、以及目标区域的dem数据。
22.具体地,在s100之前,所述茶树种植区域提取方法还包括:选取目标区域。
23.目标区域可以大到市县,小到乡镇村,甚至是一个具体尺寸土地。
24.如图3所示,图3示出的就是z省q市k县的行政区示意图。星星所示的位置为县政府所在地。图3左下角为比例尺。
25.步骤s100中,卫星多光谱遥感影像可以采用哨兵2号卫星采集的多光谱遥感影像,其具有多个波长,是由哨兵2号卫星搭载相机拍摄得到,选择覆盖目标区域影像的云量小于20%。
26.sar卫星极化遥感影像可以采用哨兵1号采集的卫星sar极化影像,也具有多个波长,其来源是由哨兵1号卫星发射雷达波至地面的目标区域,反射回哨兵1号卫星。哨兵1号卫星自带极化功能,极化方式为vv+vh双极化方式,vv为垂直单极化方式,vh为垂直水平双极化方式。
27.dem数据则可以采用srtm-dem-v3数据,即使用srtm数据库的v3精度的dem数据。
28.srtm英文全称为shuttle radar topography mission,中文名称为航天飞机雷达地形测绘任务。dem的英文全称为digital elevation model,中文名称为数字高程模型。v3精度即30米精度。
29.s200,采集目标区域内的多个地物样本,构成地物样本数据集。
30.具体地,地物样本的采集方式多种多样。可选地,可以采用高精度图室内采样与野外实地采样方法结合的方式采集目标区域内的多个地物样本,作为室内地物样本。
31.室内采样使用计算机软件对目标区域在目标时间的历史高精度地图上采集所需要的目标地物类型的地物样本。野外实地采样采用移动设备(例如手机)在目标区域内实地采集地物样本,作为实地地物样本。
32.无论是室内地物样本还是实地地物样本,都需要覆盖整个目标区域。
33.在获得室内地物样本和实地地物样本后,依据实地地物样本检查并纠正室内地物样本,最终形成地物样本数据集。
34.采集目标区域内的多个地物样本后,还可以生成茶树种植区域地物样本分布示意
图,如图4所示。
35.s300,依据目标区域的地理环境信息和茶树生长特性信息,依据遥感影像数据集获取与茶树生长相关的初级特征、二级特征和三级特征,将所有与茶树生长相关的初级特征、二级特征和三级特征均作为待评估特征纳入特征集。
36.具体地,与茶树生长相关的初级特征依据遥感影像数据集得到。二级特征和三级特征由初级特征计算而来,并不能依据遥感影像数据集直接得到。二级特征和三级特征首先需要经过选取,选取的过程依据目标区域的地理环境信息和茶树生长特性信息。在选取好合适的二级特征和三级特征后,再通过初级特征计算得到。
37.二级特征和三级特征可以包括与茶树垄状种植相关的纹理特征,与茶树季节变化相关的特征,与海拔和雷达极化相关的特征等等,充分考虑了目标区域的地理环境信息和茶树生长特性信息。
38.s400,对特征集合中的每一个待评估特征均进行重要性评估,依照重要性评估结果从特征集合中筛选出至少一个优选特征纳入优选特征集。
39.具体地,为了提供重要性评估效率,可以采取人工智能方法进行评估。例如,创建并训练机器学习模型或深度学习模型,使得机器学习模型或深度学习模型具有对一级特征、二级特征和三级特征进行重要性评估的能力,从而在一级特征、二级特征和三级特征的总量较大时,大大重要性评估的效率。
40.s500,将地物样本数据集中的至少一个地物样本纳入训练集,利用训练集和优选特征集对茶树种植区域分类模型进行训练。
41.具体地,本步骤中,创建一个茶树种植区域分类模型,所述茶树种植区域分类模型为深度学习模型。将在s100中采集的所有地物样本中的一部分样本做为训练数据,对茶树种植区域分类模型进行训练,同时在训练的过程中还同步加入优选特征集,从而使得茶树种植区域分类模型具有以下能力:在输入待测区域的遥感图像的特征集后,可以自动将地物样本进行分类,辨别哪些地物样本是茶树,哪些地物样本不是茶树,并将茶树样本注在遥感特征图像的不同位置。
42.s600,将目标区域的地物样本数据集和优选特征集输入至茶树种植区域分类模型,输出目标区域的茶树种植区域分布图。
43.具体地,目标区域的茶树种植区域分布图如图6所示。茶树种植区域分布图中,可以看出茶树种植区域在目标区域的分布情况。
44.本实施例中,通过引入卫星多光谱遥感影像、sar卫星极化遥感影像和dem数据三种不同的遥感数据源,增加了遥感数据的多样性,通过同时获取与茶树生长相关的初级特征、二级特征和三级特征,构建了多层级遥感特征集,此外在获取特征时引入了目标区域的地理环境信息和茶树生长特性信息,充分考虑了茶树在生长过程中的生长环境,生长特性等重要因素,使得最终茶树种植区域分类模型的分类结果精度大大提升,更符合茶树的实际生长情况。
45.在本技术的一实施例中,当采集目标区域内的多个地物样本,构成地物样本数据集时,控制目标区域内地物样本的地物类别大于或等于6类,控制目标区域内每平方公里内采集的地物样本数量大于或等于5个。
46.具体地,控制目标区域内每平方公里内采集的地物样本数量大于或等于5个的目
的是为了控制所有地物样本均匀覆盖整个目标区域。
47.在本技术的一实施例中,在所述s100之后,所述茶树种植区域提取方法还包括:s110,对目标区域的遥感影像数据进行预处理。
48.具体地,对目标区域的卫星多光谱遥感影像进行预处理包括辐射定标、去云去雾、大气校正、几何校正、正射校正、镶嵌和裁剪中的一种或多种。
49.对目标区域的sar卫星极化遥感影像进行预处理包括标定轨道参数、边界噪音去除、去除热噪声、辐射定标、地形校正、镶嵌和裁剪中的一种或多种。
50.对目标区域的dem数据进行预处理包括镶嵌、裁剪和调整空间分辨率的操作。dem数据采用srtm-dem-v3数据,即精度为30米精度,而卫星多光谱遥感影像和sar卫星极化遥感影像都是10米精度,精度即空间分辨率,那么需要将srtm-dem-v3数据调整为10米精度的dem数据。
51.三种遥感数据都涉及到了镶嵌,这是因为在目标时间采集的遥感数据不一定完整,即产生缺失,此时需要在目标时间的临近时间再次采集一次遥感数据,镶嵌到在目标时间采集的遥感数据中,这样目标区域的遥感数据方可采集完整。
52.三种遥感数据都涉及到了裁剪,和镶嵌同理,在目标时间采集的遥感数据可能覆盖面积过大,超出了目标区域的原有面积,此时就需要对遥感数据进行裁剪。
53.此外,在s200之后,还可以包括:s210,对目标区域内的多个地物样本进行预处理。
54.对目标区域内的多个地物样本进行预处理包括样本错误成分核查、样本纯净度计算、样本提纯、样本空间分布均匀化和样本数量分布均衡化中的一种或多种。
55.在本技术的一实施例中,所述s300包括:s310,依据遥感影像数据集获取与茶树生长相关的初级特征。
56.具体地,获取到的与茶树生长相关的初级特征可以如表1所示。
57.表1-与茶树生长相关的初级特征表
如表1所示,包括12个波段的哨兵2号卫星多光谱遥感影像,3个波段的哨兵1号sar极化遥感影像,以及1个波段的srtm-dem-v3数据。
58.s320,依据目标区域的地理环境信息和茶树生长特性信息,以及与茶树生长相关的初级特征,计算与茶树生长相关的二级特征。
59.具体地,二级特征是先选取后计算的。在选取二级特征时引入了目标区域的地理环境信息和茶树生长特性信息。
60.s330,依据目标区域的地理环境信息和茶树生长特性信息,以及与茶树生长相关的二级特征,计算与茶树生长相关的三级特征。
61.具体地,三级特征是先选取后计算的。在选取三级特征时引入了目标区域的地理环境信息和茶树生长特性信息。与茶树生长相关的二级特征和三级特征可以如表2所示。我们把二级特征和三级特征统称为高级特征。
62.表2-与茶树生长相关的高级特征表
如图表2所示,表2列出了三类二级特征和两类三级特征。
63.表2中各个特征都是使用英文简称来表示,具体释义请参见表3和表4。
64.表3-表2中的英文简称解释表表4-表2中glcm的18个特征分量的介绍表
表2中的glcm(b8)、glcm(vv)、glcm(vh)和glcm(ndti)均各自具有18个特征分量。
65.本实施例中,在获取二级特征和三级特征时引入了目标区域的地理环境信息和茶树生长特性信息,充分考虑了茶树在生长过程中的生长环境,生长特性等重要因素,使得最终茶树种植区域分类模型的分类结果精度大大提升,更符合茶树的实际生长情况。
66.在本技术的一实施例中,所述s320包括:s321,分析目标区域的地理环境信息和茶树生长特性信息,依据分析结果获取12月的近红外光反射率、12月的红色光反射率、5月的近红外光反射率和5月的红色光反射率。所述近红外光反射率和所述红色光反射率均为与茶树生长相关的初级特征。
67.s322,依据公式1分别计算12月的ndvi值和5月的ndvi值。所述ndvi值为二级特征。
68.ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
公式1。
69.其中,ndvi为ndvi值,band8为近红外光反射率,band4为红色光反射率。
70.具体地,本实施例具体列出了在获取二级特征时引入目标区域的地理环境信息和茶树生长特性信息的实施例。
71.茶树作为常绿作物,虽然全年均呈现绿色,但是其绿度在全年是随着季节变化和修剪与否密切相关的,有一定的周期性规律,这也是茶树与其他常绿乔木的区别之处。通过获取目标区域的地理环境信息知晓了目标区域归属于长江中下游区域。这个地理位置的江南茶区每年都会在春茶采摘后进行一次定型修剪,时间一般为4月下旬至5月上旬,修剪后
ndvi值(即归一化差异植被指数,此处只解释一次,后续不再解释,查表2和表3可以直接得到)会降低。修剪后的茶树随着营养积累与生殖生长,经过多次生长与休止期,茶树的冠层在冬季冬眠之前达到绿度最高的时期,那么此时ndvi值最高。
72.因此本实施例分别采集了12月的ndvi值和5月的ndvi值,着重考虑了茶树修剪之后与冬眠之前两个时期的ndvi值植被特征及其变化,充分考虑了茶树在生长过程中的生长环境,生长特性等重要因素,使得后续计算的三级特征也兼顾这些要素。
73.在本技术的一实施例中,所述s330包括:s331,分析目标区域的地理环境信息和茶树生长特性信息,依据分析结果采用公式2计算ndvi_dvi值。所述ndvi_dvi值为三级特征。
74.ndvi_dvi=ndvi(12)-ndvi(5)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
公式2。
75.其中,ndvi_dvi为ndvi_dvi值,ndvi(12)为12月的ndvi值,ndvi(5)为5月的ndvi值。
76.具体地,上述实施例已经提及到过,三级特征是依据二级特征计算而来,那么承接上述s321至s322的实施例,本实施例,将12月的ndvi值和5月的ndvi值做差值,得到三级特征ndvi_dvi值,因此在更深层次的植被指数的差值充分体现了茶树生长过程中茶树植株绿度变化之一重要的时序信息,使得后续的茶树种植区域提取过程更符合实际情况。
77.在本技术的一实施例中,所述s320还包括:s323,分析目标区域的地理环境信息和茶树生长特性信息,依据分析结果获取短波红外1反射率和短波红外2反射率。短波红外1反射率即表1中的band11,短波红外2反射率即表1中的band12,均为与茶树生长相关的初级特征。
78.s322,依据公式4计算ndti值。所述ndti值为二级特征。
79.ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
公式4。
80.其中,ndti为ndti值, 为短波红外光1反射率, 为短波红外光2反射率。
81.在本技术的一实施例中,所述s330还包括:s332,分析目标区域的地理环境信息和茶树生长特性信息,依据分析结果和上述公式4得到的ndti计算glcm的18个特征分量,glcm的18个特征分量如表4所示。所述glcm为三级特征。
82.具体地,由于当前绝大部分茶树均是人工按照垄状种植,山地地区和丘陵地区沿垂直于山脊或山谷的方向成片分布,种植于山地地区和丘陵地区的茶树的垄的形状一般为平行的不闭合的曲线形状。而部分种植于平原耕地上的茶树的垄形结构一般呈现平行的短直线形状。此外,还有部分茶树种植在整个小丘陵上,茶树的垄的形状呈现闭合的环状结构,与等高线分布形状极为相似,均具有十分明显且区别于其他地物的纹理特征信息。具体表现为二级特征和三级特征的纹理特征部分。
83.在本技术的一实施例中,在所述s400之前,所述茶树种植区域提取方法还包括:s350,依据公式3对特征集合中的每一个待评估特征进行归一化处理;
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
公式3;其中,k为待评估特征的波段序号,i为行序号,j为列序号,为波段序号为k的待评估特征的第i行第j列像素的像素值,为波段序号为k的待评估特征的所有像素的平均像素值,为波段序号为k的待评估特征的所有像素的像素值标准差,为波段序号为k的待评估特征的第i行第j列像素的像素值归一化后的值。
84.具体地,本技术提取的波长较多,特征较多,本实施例的归一化的目的是避免各个特征的数量级差异导致出现误差。
85.在本技术的一实施例中,所述s400包括:s410,采用随机森林平均精确度下降算法对特征集合中的每一个待评估特征进行重要性评估,得到每一个待评估特征的重要性指数。
86.具体地,所述s410包括如下步骤:s411a,创建一个遥感特征分布模型。将地物样本数据集中的所有地物样本标注在目标区域的特征集上,生成遥感特征图像(图中未显示),将这张遥感特征图像作为标准图像c,每一个地物样本被标注后生成一个标签。
87.s411b,将特征集和所有标签作为训练数据输入至遥感特征分布模型,对遥感特征分布模型进行训练,使得遥感特征分布模型具有自动在特征集上标注的功能。
88.s411c,将特征集和所有标签输入至训练后的遥感特征分布模型,运行训练后的遥感特征分布模型,获取训练后的遥感特征分布模型输出的初始预测图像c’。
89.s411d,将初始预测图像c’和标准图像c进行比对,计算标注正确的标签数量,依据公式5计算初始预测正确率。
90.ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
公式5。
91.其中, 为初始预测正确率, 为初始预测图像c’和标准图像c进行比对后标注正确的标签数量,为原始标签总数量(即标准图像c中标签总数量)。
92.s412a,在特征集中,随机抽出一个待评估特征置入待评估特征队列的随机一个位置,以改变待评估特征的排列顺序,将改变待评估特征的排列顺序的特征集合和所有标签输入至训练后的遥感特征分布模型,运行训练后的遥感特征分布模型,获取训练后的遥感特征分布模型输出的第一预测图像c1’。
93.s412b,将第一预测图像c1’和标准图像c进行比对,计算标注正确的标签数量,依据公式6计算第一预测正确率。
94.ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
公式6。
95.其中, 为第一预测正确率,为第一预测图像c1’和标准图像c进行比对后标注正确的标签数量, 为原始标签总数量。
96.s412c,在特征集中,再抽出s412a中同一个待评估特征置入待评估特征队列的随机一个位置,但是需要注意的是随机位置不可以是此待评估特征处于待评估特征队列的初始位置和s412a放置的位置,避免重复,这样又改变了一次待评估特征的排列顺序,将改变待评估特征的排列顺序的特征集输入至训练后的遥感特征分布模型,运行训练后的遥感特征分布模型,获取训练后的遥感特征分布模型输出的第二预测图像c2’。
97.s412d,将第二预测图像c2’和标准图像c进行比对,计算标注正确的标签数量,依据公式7计算第二预测正确率。
98.ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
公式7。
99.其中, 为第二预测正确率, 为第二预测图像c2’和标准图像c进行比对后标注正确的标签数量, 为原始标签总数量。
100.s413,那么通过第二次抽出待评估特征改变待评估特征的排列顺序后,此待评估特征预测正确率的精度就可以通过公式8计算。
101.ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
公式8。
102.其中,j为与待评估特征对应的预测正确率的精度, 为第二预测正确率, 为第一预测正确率, 为初始预测正确率。
103.s414,那么我们后续继续依照上述的原理继续对其余每个待评估特征进行抽出并置入待评估特征队列的随机位置,改变待评估特征的排列顺序,计算预测正确率,进行再次抽出待评估特征置入待评估特征队列另一随机位置,改变待评估特征的排列顺序,计算预测正确率,从而计算此待评估特征预测正确率的精度,重复直至将所有待评估特征均计算出预测正确率的精度j。
104.正确率的精度即正确率的变化率,体现了抽出一个待评估特征后改变待评估特征的排列顺序后,预测结果的正确率的波动情况。预测正确率的精度越高,代表这个待评估特征的抽出对预测结果的正确率的波动越大,那么代表这个待评估特征的重要性就越高。因此,采用随机森林平均精确度下降算法评估各个待评估特征的重要性,实际上就是得出各个待评估特征对应的预测正确率的精度,我们将预测正确率的精度作为重要性指数。
105.s420,将重要性指数按从大到小的顺序进行排序。
106.具体地,预测正确率的精度越高,重要性指数越高,代表重要性越高。
107.s430,选取重要性指数前n%对应的待评估特征作为优选特征。
108.具体地,例如,n可以取大于等于20且小于等于40的数值范围中的一个数字。可选地,n为40。
109.s440,创建优选特征集,将所有优选特征纳入所述优选特征集。
110.具体地,例如我们通过s430选取了前40%的优选特征,其中重要性指数前六的待评估特征为二级特征ndvi_re2(归一化差异红边2植被指数,见表2和表3),二级特征glcm(vv)-savg(依据一级特征vv计算的glcm纹理特征的savg波段,见表2),一级特征band2(蓝色光反射率,见表1),一级特征elevation(地面高程,见表1),三级特征ndvi_dvi(见表2),一级特征band12(短波红外光2反射率,见表1)。那么我们将前40%的优选特征作为优选特征纳入所述优选特征集。
111.可选地,我们可以生成重要性排名前四的遥感特征示意图,如图5所示。图5包括a,b,c,d四张图,图5中的a对应二级特征ndvi_re2,图5中的b对应二级特征glcm(vv)-savg,图5中的c对应一级特征band2,图5中的d对应一级特征elevation。图5中的a中的左下角的图示为比例尺。图5中的a中的右上角的图示为指北方向标,图5中的a中的右下角的渐变条的含义是:颜色越浅,代表特征值越大。颜色越深,代表特征值越小。渐变条的最浅色端代表特征值的最大值,渐变条的最深色端代表特征值的最小值。图5中的b的图示,图5中的c的图示和图5中的d的图示和图5中的a的图示相同,此处不再赘述。
112.在本技术的一实施例中,所述s500包括:s510,将地物样本数据集内占地物样本总量x%的地物样本纳入训练集。
113.s520,利用训练集和优选特征集对茶树种植区域分类模型进行训练。
114.s530,将地物样本数据集内占地物样本总量y%的地物样本纳入验证集。
115.s540,将验证集输入至茶树种植区域分类模型,运行茶树种植区域分类模型得出分类结果。所述分类结果包括目标区域内归属于茶树地物类别的地物样本数量,以及归属于非茶树地物类别的地物样本数量。
116.s550,将分类结果和验证集的茶树分类实际情况进行比对,得到茶树分类精度。
117.s560,判断茶树分类精度是否大于或等于预设茶树分类精度。
118.s570,若茶树分类精度大于或等于预设茶树分类精度,则执行后续将目标区域的地物样本数据集和优选特征集输入至茶树种植区域分类模型,输出目标区域的茶树种植区域分布图的步骤。
119.s580,若茶树分类精度小于预设茶树分类精度,则将地物样本数据集内占地物样本总量z%的地物样本纳入测试集。x,y和z的和为100,且x大于y且x大于z。
120.s590,将测试集输入茶树种植区域分类模型,利用测试集对预设茶树分类精度进行调整,返回所述将验证集输入至茶树种植区域分类模型,运行茶树种植区域分类模型得出分类结果的步骤。
121.具体地,本实施例是将地物样本数据集内占地物样本总量按x:y:z的比例分配,x%作为训练集,y%作为验证集,z%作为测试集,三个不同的集合来分别完成不同的功能。
122.x:y:z可以为6:2:2,即x=60,y=20,z=20。x:y:z也可以为8:1:1,即x=80,y=10,z=10。x:y:z也可以为7:3:1,即x=70,y=30,z=10。训练集占比是最高的,x大于y且x大于z,可选地,x还要大于或等于60%,这样的目的是避免训练出来的茶树种植区域分类模型的泛化能力特别弱,避免茶树种植区域分类模型无法用于非训练集的预测与分类。
123.训练集用于训练茶树种植区域分类模型。验证集用于验证茶树种植区域分类模型的分类结果是否正确,从而可以计算出茶树种植区域分类模型的分类精度,若茶树分类精
度大于或等于预设茶树分类精度,则茶树种植区域分类模型是合格的,可以执行后续步骤投入使用。若茶树分类精度小于预设茶树分类精度,则茶树种植区域分类模型是不合格的,需要使用测试集去调整预设茶树分类精度的值。预设茶树分类精度可以为95%。
124.s540至s550通过验证集对茶树种植区域分类模型的分类结果进行评价的过程中,使用了混淆矩阵的原理,例如,目标区域的茶树分布的正确状态参见验证集的实际分布状态,例如实际为50个茶树地物样本,50个非茶树地物样本。而样验证集输入至茶树种植区域分类模型,运行茶树种植区域分类模型,茶树种植区域分类模型输出的分类结果是45个茶树地物样本,55个非茶树地物样本。
125.将原来的50个茶树地物样本中的30个茶树地物样本成功分类出来,但是20个茶树地物样本错认为非茶树地物样本。
126.此外茶树种植区域分类模型输出的分类结果是将原来的50个非茶树地物样本中的35个认定为非茶树地物样本,其中的15个认定为茶树样本。
127.那么茶树分类精度就是30除以50乘以100%为60%。
128.在本技术的一实施例中,还可以计算下整体分类精度,计算整体分类精度的结果就是[(30+35)]/100=75%。
[0129]
在本技术的一实施例中,s560中,若整体分类精度大于等于预设整体分类精度阈值且茶树分类精度高于预设茶树分类精度,才执行s570,否则执行s580。
[0130]
可选地,预设茶树分类精度为95%,预设整体分类精度为90%。
[0131]
测试集用于调整预设茶树分类精度的值,找到一个适合茶树种植区域分类模型当前分类精度(换言之是符合茶树种植区域分类模型的分类能力的预设茶树分类精度)。
[0132]
s600中,将目标区域的地物样本数据集和优选特征集输入至茶树种植区域分类模型,茶树种植区域分类模型可以输出(0,1)二值图像,1表示茶树,0表示非茶树,得到最终精确的茶树提取结果,可以具象化为目标区域的茶树种植区域分布图输出,如图6所示。
[0133]
另一方面,本技术提供一种茶树种植区域提取系统。
[0134]
如图2所示,在本技术的一实施例中,所述茶树种植区域提取系统包括服务器100、卫星多光谱遥感影像数据库200、sar卫星极化遥感影像300和dem数据库400。
[0135]
所述服务器100用于执行如前述任意一个实施例所提及的茶树种植区域提取方法。所述卫星多光谱遥感影像数据库200与所述服务器100通信连接。所述卫星多光谱遥感影像数据库200用于存储卫星多光谱遥感影像。
[0136]
sar卫星极化遥感影像数据库300与所述服务器100通信连接。sar卫星极化遥感影像数据库300用于存储sar卫星极化遥感影像。
[0137]
所述dem数据库400与所述服务器100通信连接。所述dem数据库400用于存储dem数据。
[0138]
具体地,为了行文简洁,本实施例中提及的服务器100、卫星多光谱遥感影像数据库、sar卫星极化遥感影像和dem数据库仅在本实施例中进行标号,前述茶树种植区域提取方法中出现相同名称的设备或数据库不进行标号。
[0139]
以上所述实施例的各技术特征可以进行任意的组合,各方法步骤也并不做执行顺序的限制,为使描述简洁,未对上述实施例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。
[0140]
以上所述实施例仅表达了本技术的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对本技术专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本技术构思的前提下,还可以做出若干变形和改进,这些都属于本技术的保护范围。因此,本技术的保护范围应以所附权利要求为准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1