一种基于大数据分析的运营平台管理系统的制作方法
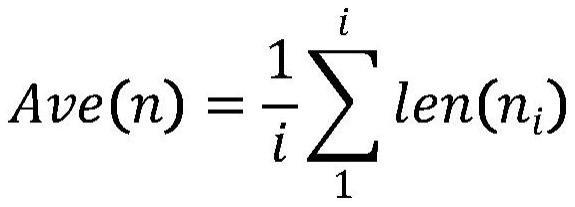
本发明涉及大数据,具体为一种基于大数据分析的运营平台管理系统。
背景技术:
1、大数据时代的到来,使得各行各业都开始重视对大数据的挖掘。大数据隐藏着巨大的商业价值,且近年来井喷式发展,相对于数据的增长速度,人们对于大数据的分析能力确无法满足要求,出现数据存量很大,却仍然信息匮乏的局面。传统的数据集成方法无法处理异构数据带来的数据语义冲突,导致集成精度降低,且随着数据量的增大,这种语义冲突会不断扩大,严重影响数据集成效率;传统的数据挖掘会受到单机性能影响,挖掘深度取决于服务器的算力,在处理海量数据时效率变低,因此,设计集成精度高和挖掘效率高的一种基于大数据分析的运营平台管理系统是很有必要的。
技术实现思路
1、本发明的目的在于提供一种基于大数据分析的运营平台管理系统,以解决上述背景技术中提出的问题。
2、为了解决上述技术问题,本发明提供如下技术方案:一种基于大数据分析的运营平台管理系统,包括数据集成模块、数据挖掘模块,所述数据集成模块用于对异构数据进行专项化集成,所述数据挖掘模块用于实现数据并行挖掘。
3、根据上述技术方案,所述数据集成模块包括异构数据筛选模块、局部特征提取模块、全局特征库创建模块、特征映射模块,所述异构数据筛选模块用于对数据集成过程中的异构数据进行筛选,所述局部特征提取模块用于对待处理的异构数据进行局部特征提取,所述全局特征库创建模块用于将提取出的局部特征映射为全局特征并保存到库中,所述特征映射模块用于创建局部特征到全局特征的映射规则,所述异构数据筛选模块与局部特征提取模块、全局特征库创建模块、特征映射模块形成闭环连接。
4、根据上述技术方案,所述数据挖掘模块包括分类训练模块、关联聚类模块、预测规则制定模块、结果评估模块、可视化操作模块,所述分类训练模块用于根据数据的不同特征进行分类训练,所述关联聚类模块用于将存在关联性的特征通过聚合的方式形成数据簇,所述预测规则制定模块通过对训练数据集进行分析,制定预测规则对未知的数据集进行特征预测,所述结果评估模块用于对数据挖掘的结果进行评估,筛选出重要性高的数据,所述可视化操作模块用于实现与数据拥有者的可视化展示操作。将数据的不同特征划分为不同的类,这些类可以根据训练数据集进行创建,通过发现不同数据对象之间存在的依赖关系,确定关联规则,并通过关联聚类将一个类中数据的功能特征提炼出来作为特征描述。
5、根据上述技术方案,所述数据集成模块的运行方法包括以下步骤:
6、步骤a:对数据源进行筛选,筛选出具有异构特征的异构数据;由于存在大量的异构数据,所以要进行筛选,作为异构数据源;
7、步骤b:进行异构数据的局部特征提取;
8、步骤c:根据局部特征创建全局特征库;
9、步骤d:建立特征映射规则,将局部特征映射到全局特征库中。
10、根据上述技术方案,所述步骤a中,对异构数据的筛选方法为:
11、步骤s1:进行初步筛选,具体筛选方法为根据数据的表面结构差异进行初步筛选;表面结构差异包括数据的物理存储差异、操作系统的差异、数据格式差异;
12、步骤s2:进行进一步筛选,具体筛选方法为追溯数据来源,并判断其逻辑模型,根据逻辑模型进行筛选;数据在不同的业务逻辑中进行存储和维护,即使是相同的数据也会出现逻辑表现上的异构,对其进行溯源后可以追溯到原始应用场景,从而进行逻辑异构筛选;
13、步骤s3:根据筛选结果进行分类,具体为将出现异构特征的数据进行筛选。
14、根据上述技术方案,所述步骤b中,异构数据的局部特征提取方法为:
15、建立特征树,在特征树中遍历异构数据源的所有数据;
16、将遍历过程中出现的数据特征按数据量大小排列到特征树中;
17、将特征树中数据量最大的特征作为一段数据的代表特征;
18、对提取完局部特征的数据进行模拟操作,记录操作完成的最少编辑次数ni;操作过程为将某段数据经过字符替换、插入或删除转变为另外一个相同特征的数据,并记录下需要的最少编辑操作次数;
19、获取操作步骤,将最少编辑次数根据距离转换算法转换成距离值len(ni)。编辑次数无法在系统内参与计算,转换为距离值更方便参与计算,距离转换算法可以根据具体的操作步骤将编辑的次数转换为距离值,便于计算并为后续的全局映射做准备,具体的转换规则为规定每个操作的步数,该步数与操作产生的字符变化程度有关,并成正比关系。
20、根据上述技术方案,所述步骤d中,特征映射规则的建立方法为:
21、步骤a:遍历特征树中所有的局部特征,并进行距离值计算,建立距离值数列{len(n1)、len(n2)……len(ni)};
22、步骤b:计算特征树中已存的特征距离均值ave(n),其中:
23、
24、其中i为特征树中的局部特征数量,且i≥1;
25、步骤c:将计算出的特征距离均值ave(n)作为映射对比幅度;特征距离均值ave(n)反映了异构数据集群的平均特征,作为映射对比幅度可以保证特征映射过程的上下限可控;
26、步骤d:建立方差运行算法,并在映射对比幅度确定的基础上再次遍历特征树中所有数据,生成结果;方差运行算法的结果显示数据特征距离值与平均值的差异,确定筛选规则后对数据的存入进行筛选;
27、步骤e:对方差算法生成的结果进行数值限定,将低于映射对比幅度的数据存入全局特征库中,将高于映射对比幅度的数据保留在特征树中进入下一个周期的集成。低于映射对比幅度的数据为特征距离值低于平均值的数据,这些数据的特征复杂度更低,出现误判的几率更小,可以直接筛选出并存入全局特征库中,高于映射对比幅度的数据特征复杂度更高,继续留在特征树中与下一轮的数据进行新一轮的集成筛选。
28、根据上述技术方案,所述数据集成模块中,数据映射进全局特征库后,将占比最多的特征距离值作为主特征,并进行分类筛选,其中分类筛选依据为人工制定和大数据集成过程中提取出的数据特征。
29、根据上述技术方案,所述据挖掘模块中,包括对预测规则的制定方法,具体为:
30、将特征类型相同的数据进行关联聚类,生成带有特征值的数据簇,其中特征值为一串数据簇中所有数据的特征距离平均值;
31、将带有特征值的数据簇与数据集成过程中生成的特征树进行数据比对,筛选出特征值相同的数据并标记。在数据集成过程中,特征树上存留的数据与生成的带有特征值的数据簇会存在冲突,相同的特征值会出现不同语义之间产生的冲突,需要筛选出来,减少预测过程中的冗余操作和语义冲突带来的算力浪费。
32、与现有技术相比,本发明所达到的有益效果是:本发明,通过设置有特征映射模块,在数据集成过程中,由于传统的数据集成方法难以克服异构数据产生的语义缺陷,因此提取出异构数据的局部特征后,通过创建局部特征到全局特征的映射规则,完成全局特征库的创建,再回头进行异构数据的特征比对,实现异构数据的集成;通过设置有分类训练模块,将数据的不同特征划分为不同的类,这些类可以根据训练数据集进行创建,通过发现不同数据对象之间存在的依赖关系,确定关联规则,并通过关联聚类将一个类中数据的功能特征提炼出来作为特征描述。
- 还没有人留言评论。精彩留言会获得点赞!