用于文本到代码变换的双贝叶斯编码-解码技术的制作方法
本申请总地涉及自然语言处理,并且更具体地涉及用于文本到代码变换的双贝叶斯编码-解码技术。
背景技术:
1、用于自然语言处理(nlp)的方法和机器学习(ml)框架已在过去十年中呈现显著进步。特别地,深度学习(dl)技术已在诸如含义提取、命名实体识别、问答和机器翻译之类的nlp任务上显示了性能的提高。然而,收到较少关注的自然语言(nl)的一个子域是nl到源代码的变换。
2、编写无错误的源代码是极其困难的任务,对复杂软件系统来说尤其如此。甚至最有经验的程序员和开发者也可能在编写源代码时遇到困难。来自在线论坛的使用的统计信息提供了困难有多么普遍的证据。例如,stack overflow的1600万个用户已张贴了2200万个问题,提供了3200万个回答,并且每天访问站点1100万次(最近的平均值)。通常,用户需要询问其他人或者搜索网络以查找适当的语法或者查找已知代码实现方式的解决方案。
3、搜索像github或stack overflow(及其他)一样的大代码数据库常常非常耗时;因此,使用dl和概率模型来自动化源代码生成正在赢得关注。需要准确且降低计算成本的技术,以便为依赖软件/固件开发的公司提供优势,以缩短其软件和硬件产品的上市时间。
技术实现思路
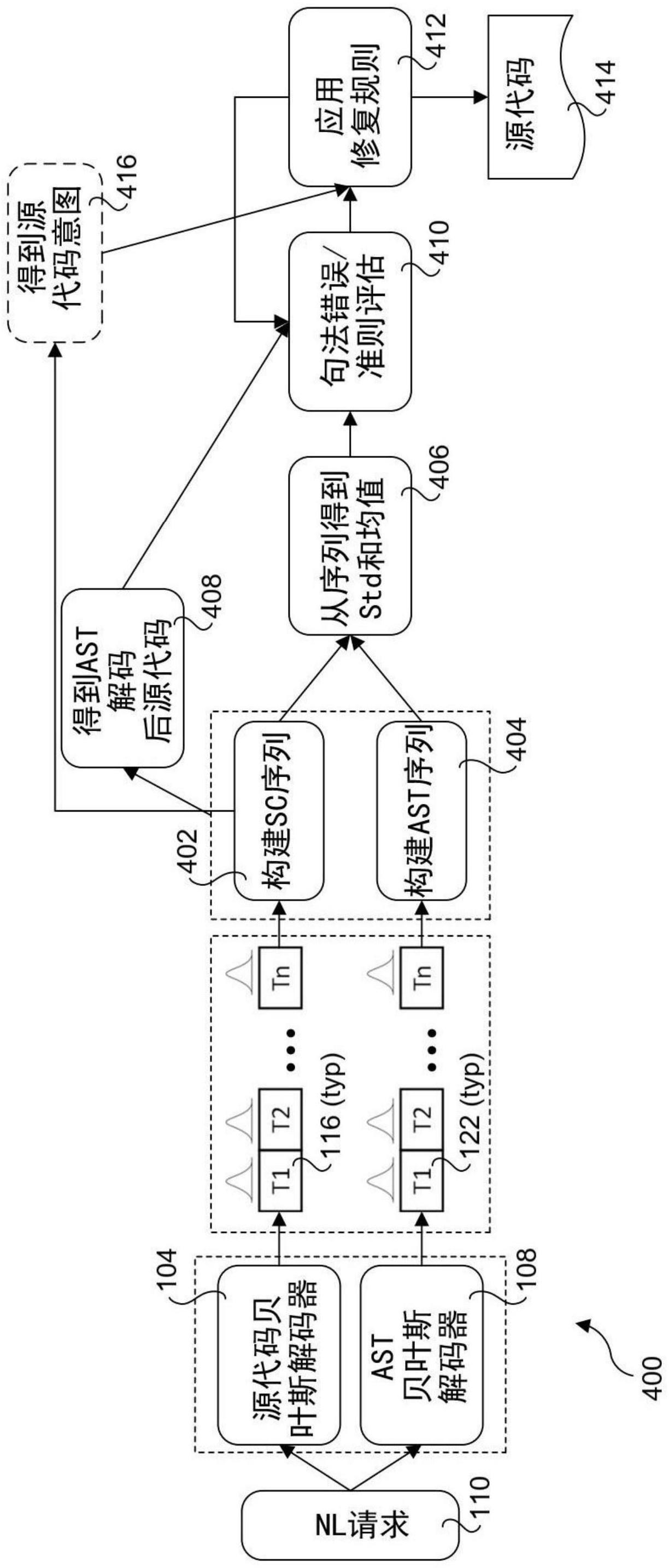
1、根据本申请的一方面,提供了一种用于从自然语言nl输入生成源代码的方法,包括:处理所述nl输入以生成源代码sc词元序列中的sc词元的概率分布pd;处理所述nl输入以生成抽象句法树ast词元序列中的ast词元的pd;标识要修复的一个或多个sc词元;以及对被标识的所述一个或多个sc词元应用一个或多个修复规则,其中用于给定sc词元的修复规则是基于所述sc词元的pd和与所述sc词元相关联的ast词元的pd中的至少一个来选择的。
2、根据本申请的另一方面,提供了一种非暂时性机器可读介质,其上存储有指令,所述指令被配置为在计算系统上的一个或多个处理器上执行以从自然语言(nl)输入生成源代码,其中所述指令的执行使得所述计算系统:处理所述nl输入以生成源代码sc词元序列中的sc词元的概率分布pd;处理所述nl输入以生成抽象句法树ast词元序列中的ast词元的pd;标识要修复的一个或多个sc词元;以及对被标识的所述一个或多个sc词元应用一个或多个修复规则,其中用于给定sc词元的修复规则是基于所述sc词元的pd和与所述sc词元相关联的ast词元的pd中的至少一个来选择的。
3、根据本申请的又一方面,提供了一种计算系统,包括:一个或多个处理器,存储器,所述存储器耦合到所述一个或多个处理器,在所述存储器中存储有指令,所述指令被配置为在所述一个或多个处理器中的至少一个上执行以使得所述系统能够:处理自然语言nl输入以生成源代码sc词元序列中的sc词元的概率分布pd;处理所述nl输入以生成抽象句法树ast词元序列中的ast词元的pd;标识要修复的一个或多个sc词元;以及对被标识的所述一个或多个sc词元应用一个或多个修复规则,其中用于给定sc词元的修复规则是至少部分地基于所述sc词元的pd和与所述sc词元相关联的ast词元的pd中的至少一个来选择的。
技术特征:
1.一种用于从自然语言nl输入生成源代码的方法,包括:
2.根据权利要求1所述的方法,其中标识要修复的sc词元包括:
3.根据权利要求1或2所述的方法,进一步包括:
4.根据权利要求1至3中任一项所述的方法,进一步包括:
5.根据权利要求1至4中任一项所述的方法,进一步包括:
6.根据权利要求1至5中任一项所述的方法,其中sc词元的pd包括与所述sc词元是否匹配的确定性水平相关联的均值和与所述sc词元是否匹配的不确定性水平相关联的标准偏差,其中ast词元的pd包括与所述ast词元是否匹配的确定性水平相关联的均值和与所述ast词元是否匹配的不确定性水平相关联的标准偏差,并且其中对所述修复规则的选择对于sc词元及其相关联的ast词元中的至少一个采用所述确定性水平和所述不确定性水平中的至少一个。
7.根据权利要求1至6中任一项所述的方法,其中所述sc词元的pd由文本到源代码text2code机器学习ml模型生成。
8.根据权利要求7所述的方法,其中所述text2code ml模型包括长短期记忆lstm编码器以及输出解码后sc词元的序列的源代码贝叶斯lstm解码器。
9.根据权利要求1至7中任一项所述的方法,其中所述ast词元的pd由文本到asttext2ast机器学习ml模型生成。
10.根据权利要求9所述的方法,其中所述text2ast ml模型包括长短期记忆lstm编码器以及输出解码后ast词元的序列的ast贝叶斯lstm解码器。
11.一种非暂时性机器可读介质,其上存储有指令,所述指令被配置为在计算系统上的一个或多个处理器上执行以从自然语言nl输入生成源代码,其中所述指令的执行使得所述计算系统:
12.根据权利要求11所述的非暂时性机器可读介质,其中所述指令的一部分包括文本到ast text2ast机器学习ml模型,所述text2ast ml模型包括长短期记忆lstm编码器以及输出解码后ast词元的序列的ast贝叶斯lstm解码器。
13.根据权利要求11或12所述的非暂时性机器可读介质,其中所述指令的一部分包括文本到源代码text2code机器学习ml模型,所述text2code ml模型包括长短期记忆lstm编码器以及输出解码后源代码词元的序列的源代码贝叶斯lstm解码器。
14.根据权利要求11至13中任一项所述的非暂时性机器可读介质,其中sc词元的pd包括与所述sc词元是否匹配的确定性水平相关联的均值和与所述sc词元是否匹配的不确定性水平相关联的标准偏差,其中ast词元的pd包括与所述ast词元是否匹配的确定性水平相关联的均值和与所述ast词元是否匹配的不确定性水平相关联的标准偏差,并且其中对所述修复规则的选择对于sc词元及其相关联的ast词元中的至少一个采用所述确定性水平和所述不确定性水平中的至少一个。
15.根据权利要求11至14中任一项所述的非暂时性机器可读介质,其中所述指令的执行进一步使得所述计算系统:
16.根据权利要求11至15中任一项所述的非暂时性机器可读介质,其中所述指令的执行进一步使得所述计算系统:
17.一种计算系统,包括:
18.根据权利要求17所述的计算系统,其中所述指令的第一部分包括文本到asttext2ast机器学习ml模型,所述text2ast ml模型包括长短期记忆lstm编码器以及输出解码后ast词元的序列的ast贝叶斯lstm解码器,并且其中所述指令的第二部分包括文本到源代码text2code机器学习ml模型,所述text2code ml模型包括长短期记忆lstm编码器以及输出解码后源代码词元的序列的源代码贝叶斯lstm解码器。
19.根据权利要求17或18所述的计算系统,其中sc词元的pd包括与所述sc词元是否匹配的确定性水平相关联的均值和与所述sc词元是否匹配的不确定性水平相关联的标准偏差,其中ast词元的pd包括与所述ast词元是否匹配的确定性水平相关联的均值和与所述ast词元是否匹配的不确定性水平相关联的标准偏差,并且其中对所述修复规则的选择对于sc词元及其相关联的ast词元中的至少一个采用所述确定性水平和所述不确定性水平中的至少一个。
20.根据权利要求17至19中任一项所述的计算系统,其中所述指令的执行使得所述系统能够:
技术总结
本申请涉及用于文本到代码变换的双贝叶斯编码‑解码技术。提供了实现用于文本到代码变换的双贝叶斯编码‑解码的方法、设备和软件。在一个方面中,采用双贝叶斯编码器‑解码器模型的多模态概率源代码模型用于将自然语言(NL)输入(也称为请求)转换成源代码。NL输入被处理以生成源代码(SC)词元序列中的SC词元的概率分布(PD)和抽象句法树(AST)词元序列中的AST词元的PD,其中每个SC词元与相应的AST词元相关联,并且所述SC和AST词元中的每一个具有相应的PD。一个或多个修复规则被应用于被标识为需要修复的一个或多个SC词元,其中考虑到所述SC词元的PD及其关联的AST词元的PD来选择修复规则。
技术研发人员:亚历杭德罗·伊巴拉·冯·博斯特尔,费尔南多·安布里兹·梅萨,大卫·以色列·冈萨雷斯·阿吉雷,沃尔特·亚历杭德罗·马约加·马西亚斯,罗西奥·埃尔南德斯·费边
受保护的技术使用者:英特尔公司
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!