基于点柱的二阶多注意力机制3D点云目标检测方法
本发明属于3d纯激光雷达点云目标领域,具体涉及基于点柱的二阶点注意力机制、二阶通道注意力机制、伪图像空间注意力机制三种机制来分别实现目标检测的方法。
背景技术:
1、当前,3d点云目标检测方法在计算机视觉、自动驾驶、机器人和虚拟现实等领域得到越来越多的广泛应用。与二维图像的目标检测相比,激光雷达可以提供更可靠的深度信息,更准确地定位物体并提供形状信息。但由于3d点云无纹理、遮挡截断和反射不均匀,激光雷达点云稀疏且密度变化很大,基于手工特征的传统的3d目标检测方法的精度常常因此受到影响。近些年,随着深层神经网络展现出优异的特征提取能力,可以处理高维数据,基于深度神经网络的3d点云目标检测方法在精度上得到一定程度的提升。尽管如此,由于点云的高度稀疏性和本质上的不规则性等原因,一些类别的检测结果的精度还是有很大的提升空间。
2、如2016年li等人提出了velofcn,将点云转换为前视特征图表示,然后使用现成的探测器。(参考b.li,t.zhang,and t.xia,“velofcn:vehicle detection from 3dlidarusing fully convolutional network,”in robotics,2016.)。2017年qi等人提出了pointnet,pointnet首次将原始点云数据投入到深度神经网络训练的模型。(参考c.r.qi,h.su,k.mo,and l.j.guibas,“pointnet:deep learning on point sets for3dclassification and segmentation,”in cvpr,2017.)。2018年martin simon等人推出了complex-yolo,此模型把点云投影到二维平面,用图像的方法做目标检测,从而加速网络推理。但是投影的方式受到点云的稀疏性的限制,使卷积无法较好的提取特征。(参考m.simon,s.milz,k.amende,and h.-m.gross.“complex-yolo:real-time 3dobjectdetection on point clouds,”arxiv:1803.06199,2018.)。为了缓解前视图重叠导致的遮挡问题,yang等人提出了pixor,将点云栅格化为更紧凑的bev表示,但存在的很明显的缺点就是需要手动提取特征,然而手工设计不仅不能充分利用物体的三维信息,也不利于推广到其他雷达上应用。(参考b.y ang,w.luo,and r.urtasun,“pixor:real-time 3d objectdetection from point clouds,”in cvpr,2018.)。2018年,zhou等人首次提出了一种端到端的可训练网络voxelnet,一种通用的3d检测框架。与之前的大多数工作不同,voxelnet开始学习信息丰富的特征表示,并且可以同时从点云中学习不同的特征表示。然而,3d卷积的缺点是它太耗时,并且面临大量的计算量,导致网络的推理速度慢。(参考y.zhou ando.tuzel,“voxelnet:end-to-end learning for point cloud based 3d objectdetection,”in cvpr,2018.)。接着yan等人提出了second,其通过稀疏卷积运算来减少内存消耗并加快计算速度。(参考y.yan,y.mao,and b.li,“second:sparsely embeddedconvolutional detection,”.in sensors,18(10),2018.)。为了利用标准的2d卷积检测管道提高推理速度,h.lang等人在2019年提出pointpillars将点云编码成垂直列,其本质上是体素的特殊划分。(参考a.h.lang,s.v ora,h.caesar,l.zhou,j.y ang,and o.beijbom,“pointpillars:fast encoders for object detection from point clouds,”in cvpr,2019.)。
3、此外,现有技术论文a.h.lang,s.vora,h.caesar,l.zhou,j.y ang,ando.beijbom,“pointpillars:fast encoders for object detection from pointclouds,”in cvpr,2019.中提出了的方法,该方法的具体实现步骤为:首先对输入的原始点云进行区域的划分,将点云体素化,再转换成稀疏伪图像的形式。每个pillar中随机保留固定数量的点,在这个步骤对pillars中的点的特征维度进行增广操作,从原始4维信息增广到9维,此时激光雷达中的每个点都具有了9维的特征。在骨干网络中,使用2d网络进行特征的学习。主干网络中包含两个子网络:一个自上而下的网络以越来越小的空间分辨率产生特征,以及第二个网络执行上采样和串联自顶向下的功能。最终输出的特征是源自不同步幅相同维度的所有特征的串联。在检测头模块中,选用ssd检测头进行bbox的回归。使用了2d联合截面(iou)将先验盒和地面的真实情况进行匹配。bbox的高度和高程没有用于匹配,这里采用的是2d匹配,高度和高程作为附加的回归目标。虽然pointpillars网络提出了利用pillars对点云体素化提升了速度,然而主干网络下采样过程中通常会丢失输入图像的特征信息,而且体素中的点和点之间具有关联性,孤立的对点云中的点进行处理势必会丢掉一部分有用的几何信息,进而影响检测精度。在主干网络中,分别孤立的对各个通道进行处理忽略了通道与通道之间的关联性,这样就会损失一部分有用信息,降低检测精度。在生成伪图像后,对伪空间中的特征做了相同的处理。由于不是全部伪空间的特征对检测任务具有同样的贡献,与任务相关性越大的区域重要性越大,直接做相同的处理也会降低最后的检测精度,所以迫切需要一种实时精准的3d点云目标检测方法,在速度和精度之间实现一个动态平衡。
技术实现思路
1、有鉴于现有技术的上述缺陷,本发明的目的是提供一种实时精准的3d点云目标检测方法,在速度和精度之间可以实现一个动态平衡,并且分别通过基于点柱的二阶点注意力机制,二阶通道注意力机制,伪图像空间注意力机制三种机制,解决了现有方法无法实时进行更高精度目标检测的问题。
2、本发明解决的技术问题:
3、第一、在特征提取网络步骤中,主干网络下采样过程中通常会丢失输入图像的特征信息,而且体素中的点和点之间具有关联性,孤立的对点云中的点进行处理势必会丢掉一部分有用的几何信息,进而影响检测精度。本发明提出一种基于点柱的二阶点注意力机制,通过将同个体素内的点和点联系起来保留更多的有用信息,这能够以相对较少的推理速度提取更加精细的特征信息。
4、第二、在主干网络中,分别孤立的对各个通道进行处理忽略了通道之间的关联性,这样就会损失一部分有用信息,降低检测精度。本发明提出一种基于点柱的二阶通道注意力机制,将通道和通道之间联系起来,保留更多有用的特征信息,提升其整体的检测精度。
5、第三、在生成伪图像后,对伪空间中的特征做了相同的处理。由于不是全部伪空间的特征对检测任务具有同样的贡献,与任务相关性越大的区域重要性越大,直接做相同的处理也会影响其检测精度。考虑到这些,本发明提出一种基于点柱的伪图像空间注意力机制,依据伪空间中区域对任务的重要性程度对伪空间中每个像素点分配不同的权重,以获得更加精确的检测结果。
6、本发明解决其技术问题所采用的技术方案是:基于点柱的二阶多注意力机制3d点云目标检测方法,该方法包括以下步骤:
7、s1:提出基于点柱的二阶点注意力机制、二阶通道注意力机制、伪图像空间注意力机制三种机制来分别实现目标检测的方法;
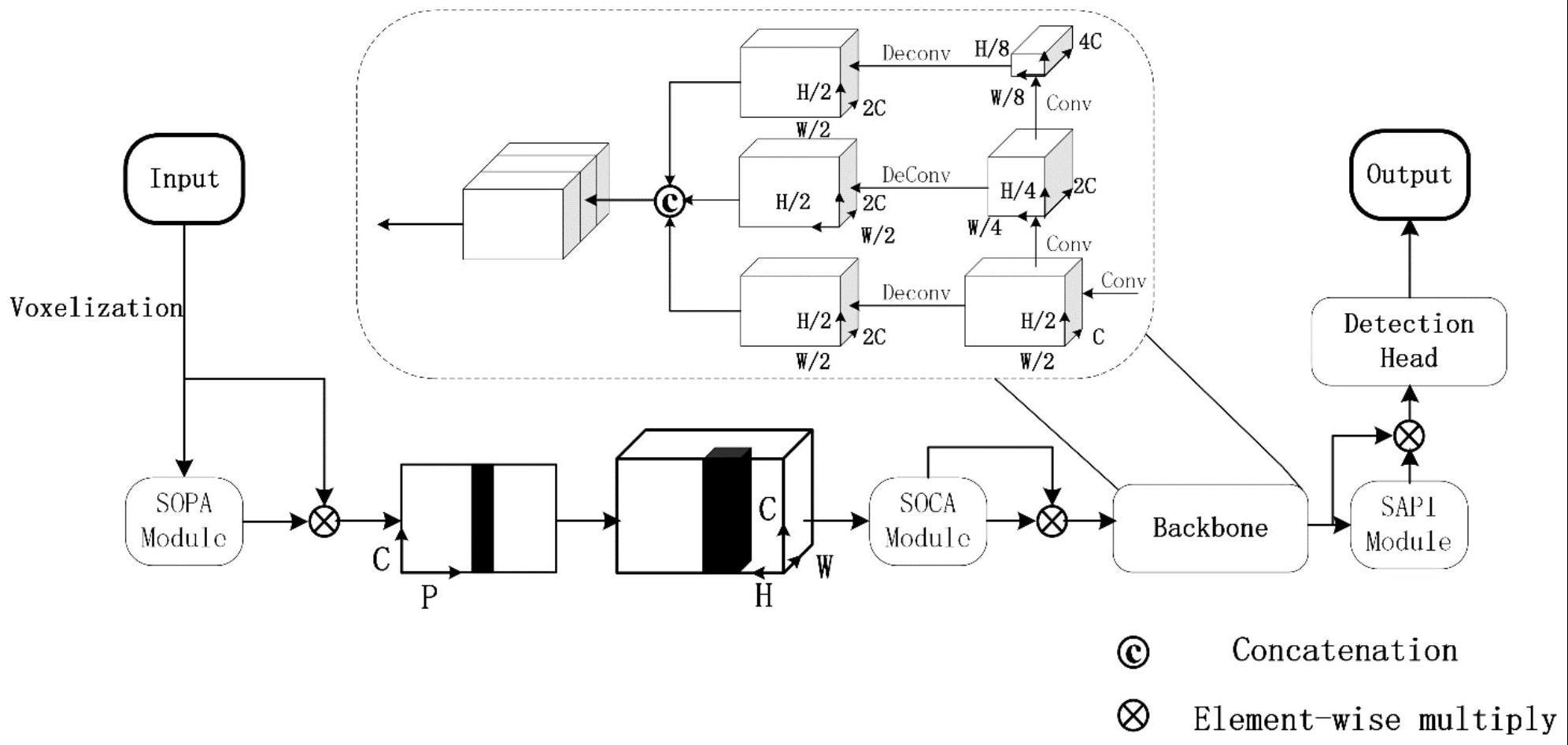
8、s2:基于s1提供一种网络,该网络主要由二阶点注意力机制、点柱特征网络、二阶通道注意力机制、主干网络、伪图像空间注意力机制和ssd检测头组成,该网络也分为二阶注意力模块、二阶点注意力模块和二阶通道注意力模块;
9、s3:将点云体素化,然后对点云进行二阶点注意力机制操作,转换成伪图像的特征;
10、s4:对伪图像的特征进行二阶通道注意力机制操作,输出伪空间的特征;
11、s5:对伪空间的特征进行伪图像空间注意力机制操作,输出得到检测结果;
12、其中,ssd检测头使用主干的特征来预测物体的三维边界盒;二阶注意力模块包含全局最大池化、协方差池化和行卷积;s3中将点特征作为二阶注意力模块的输入的情况下,将获得二阶点注意力机制权重作为输出,该过程为二阶点注意力模块;当通道特征输入到二阶注意力模块时,将获得二阶通道注意力机制权重,该过程为二阶通道注意力模块。
13、在给定的第k个体素中,对于体素中所有的点其中n代表点的数量的最大值、c表示通道的数量,在经过全局最大池化后,得到每个维度上的最大值组成的向量将输入到一层全连接层,其中n×1代表n行1列的向量,得到向量其中t是经过w1全连接层减少之后的点的数量,w1全连接层后面使用relu激活函数,计算得到同一体素中两点之间的协方差矩阵其中在二阶点注意力机制则t为点的数量、在二阶通道注意力机制则t为通道的数量、t×t为维度,对协方差矩阵进行逐行卷积,获得向量然后将向量输入到w2全连接层并使用激活函数sigmoid函数,获得n维注意力向量所述s3中,二阶点注意力机制表示为:
14、s=σ(w2rc(cov(σ(w1(gmp(x))))))
15、式中,cov(·)为计算点的协方差矩阵、rc(·)为行卷积、gmp(·)为全局最大池化、σ为relu激活函数、与为两个不同的全连接层、x为给定的第k个体素中的点
16、二阶通道注意力机制与二阶点注意力机制类似,通道特征经过二阶注意力模块后,输出产生了类似的权重,所述s4中,二阶通道注意力机制表示为:
17、m=σ(w2rc(cov(σ(w1(gmp(y))))))
18、式中,为伪图像的特征,上标h、w为伪图像的高度和宽度。
19、根据伪空间中区域对任务的重要性程度对伪空间中每个像素点分配不同的权重,获得更加精确的检测结果,将伪空间的特征p和信号g作为输入,则最终输出产生的空间注意力权重为s,伪图像空间注意力机制表示为:
20、
21、p和g的关系可以表示为:
22、
23、式中,和为用1×1的卷积来进行线性变换操作,其中为用1×1的卷积对p进行线性变换操作,为用1×1的卷积对g进行线性变换操作。
24、将三维地面真值框参数化为(x,y,z,w,l,h,θ),其中(x,y,z)表示中心位置,(w,l,h)和θ表示边框的大小和方向角,地面真值和锚之间的定位回归残差定义如下:
25、
26、
27、δθ=sin(θgt-θa),
28、式中,gt为地面真值、a为锚箱的参数、(xgt,ygt,zgt)为3d真值框的中心位置坐标,(lgt,wgt,hgt)为3d真值框的长宽高、θgt为3d真值框绕z轴的偏航角、(xa,ya,za)为锚箱的中心位置坐标、(la,wa,ha)为锚箱的长宽高。
29、θa为锚箱绕z轴的偏航角;
30、回归损失表示为:
31、
32、式中,smoothl1为smoothl1损失函数;
33、因为角度定位损失无法区分翻转的框,所以在离散化的方向使用一个softmax分类损失ldir,这使网络能够学习朝向,对于物体分类损失,使用焦点损失:
34、lcls=-a(1-p)rlogp
35、式中,p为正确检测框的概率,r和a为参数设置,最后得到的总损失表示为:
36、
37、式中,npos表示正确检测框的数量,βloc、βcls、βdir为预设值。
38、本发明具有的优点和在益效果:
39、本发明中二阶点注意力机制考虑到体素中的点之间具有关联性,与现有方法中对体素中的点孤立地进行处理相比,可以保留更多有用的几何特征信息,提升了检测的准确性。类似的,本发明中二阶通道注意力机制考虑到通道之间的相关性,进一步提升了检测精度。而本发明中提出的伪图像空间注意力机制考虑到不是全部伪空间的特征对检测任务具有同样的贡献,与任务相关性越大的区域重要性越大,因而对伪空间特征中的每一个像素点都分配不同的权重,进一步提升其特征提取效果。所以基于点柱的三种机制即保证了相对较高的检测速度也保证了提取的准确性。
- 还没有人留言评论。精彩留言会获得点赞!