一种数据召回方法、装置、电子设备及存储介质与流程
本公开实施例涉及数据处理领域,尤其涉及一种数据召回方法、装置、电子设备及存储介质。
背景技术:
1、由于应用软件平台每日的内容及评论量可达数亿量级,海量线上数据为现有的召回模型带来了极大的挑战,这导致了召回耗时过长,时间成本不可接受。此外,由于目前召回模型的标注数据有限且存在数据不均衡的情况,导致召回模型的准确率得不到保证。
技术实现思路
1、本公开实施例提供了一种数据召回方法、装置、电子设备及存储介质,不仅能够提高召回效率,还可以提高召回的准确率。
2、第一方面,本公开实施例提供了一种数据召回方法,包括:
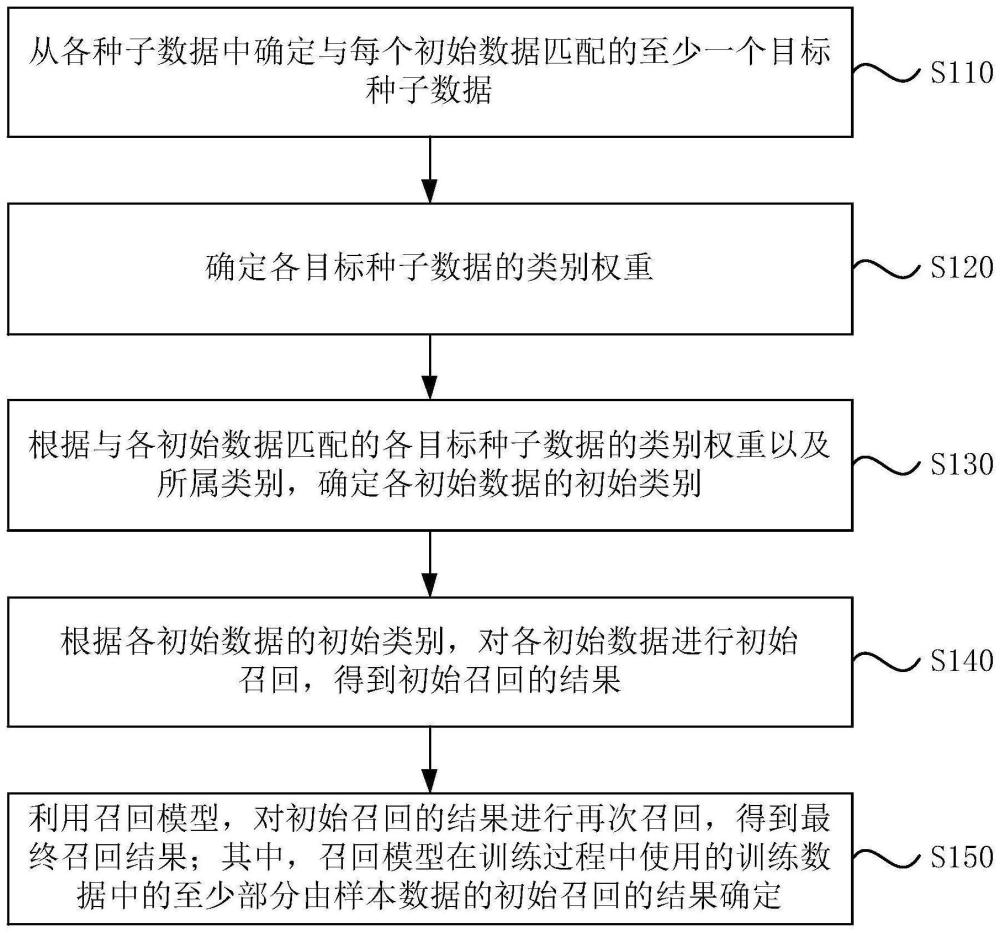
3、从各种子数据中确定与每个初始数据匹配的至少一个目标种子数据;
4、确定所述各目标种子数据的类别权重;
5、根据与各所述初始数据匹配的各目标种子数据的类别权重以及所属类别,确定各所述初始数据的初始类别;
6、根据所述各初始数据的初始类别,对所述各初始数据进行初始召回,得到初始召回的结果;
7、利用召回模型,对所述初始召回的结果进行再次召回,得到最终召回结果;其中,所述召回模型在训练过程中使用的训练数据中的至少部分由样本数据的初始召回的结果确定。
8、第二方面,本公开实施例还提供了一种数据召回装置,包括:
9、目标种子匹配模块,用于从各种子数据中确定与每个初始数据匹配的至少一个目标种子数据;
10、种子权重确定模块,用于确定所述各目标种子数据的类别权重;
11、初始类别确定模块,用于根据与各所述初始数据匹配的各目标种子数据的类别权重以及所属类别,确定各所述初始数据的初始类别;
12、第一召回模块,用于根据所述各初始数据的初始类别,对所述各初始数据进行初始召回,得到初始召回的结果;
13、第二召回模块,用于利用召回模型,对所述初始召回的结果进行再次召回,得到最终召回结果;其中,所述召回模型在训练过程中使用的训练数据中的至少部分由样本数据的初始召回的结果确定。
14、第三方面,本公开实施例还提供了一种电子设备,所述电子设备包括:
15、一个或多个处理器;
16、存储装置,用于存储一个或多个程序,
17、当所述一个或多个程序被所述一个或多个处理器执行,使得所述一个或多个处理器实现如本公开实施例任一所述的数据召回方法。
18、第四方面,本公开实施例还提供了一种包含计算机可执行指令的存储介质,所述计算机可执行指令在由计算机处理器执行时用于执行如本公开实施例任一所述的数据召回方法。
19、本公开实施例的技术方案中,从各种子数据中确定与每个初始数据匹配的至少一个目标种子数据;确定各目标种子数据的类别权重;根据与各初始数据匹配的各目标种子数据的类别权重以及所属类别,确定各初始数据的初始类别;根据各初始数据的初始类别,对各初始数据进行初始召回,得到初始召回的结果;利用召回模型,对初始召回的结果进行再次召回,得到最终召回结果;其中,召回模型在训练过程中使用的训练数据中的至少部分由样本数据的初始召回的结果确定。
20、通过先基于种子数据进行快速地初始召回,可减少召回模型的数据处理量,能够提高召回效率。此外,在初始召回过程中通过设置目标种子数据的权重,能够均衡召回类别。从而,不仅在召回模型训练过程中,通过根据样本数据的初始召回结果,确定召回模型的至少部分训练数据,可提高召回模型的准确率,以及有利于增加训练数据量;而且在实际的初始数据召回过程中,通过进行类别均衡的初始召回,也有助于提高召回准确率。
技术特征:
1.一种数据召回方法,其特征在于,包括:
2.根据权利要求1所述的方法,其特征在于,所述各种子数据,包括:属于召回类别的正例种子数据,以及属于非召回类别的负例种子数据。
3.根据权利要求1所述的方法,其特征在于,所述从各种子数据中确定与每个初始数据匹配的至少一个目标种子数据,包括:
4.根据权利要求1所述的方法,其特征在于,所述确定所述各目标种子数据的类别权重,包括:
5.根据权利要求1所述的方法,其特征在于,所述根据与各所述初始数据匹配的各目标种子数据的类别权重以及所属类别,确定各所述初始数据的初始类别,包括:
6.根据权利要求1所述的方法,其特征在于,所述根据所述各初始数据的初始类别,对所述各初始数据进行初始召回,包括:
7.根据权利要求1-6中任一所述的方法,其特征在于,所述初始数据,包括:基于目标平台的预设时间段全量的评论数据得到的初筛文本数据。
8.根据权利要求3所述的方法,其特征在于,所述初始数据为初筛文本数据时,所述第一特征向量的确定步骤,包括:
9.根据权利要求8所述的方法,其特征在于,在所述将所述各初筛文本数据进行切词处理之前,还包括:
10.一种数据召回装置,其特征在于,包括:
11.一种电子设备,其特征在于,所述电子设备包括:
12.一种包含计算机可执行指令的存储介质,所述计算机可执行指令在由计算机处理器执行时用于执行如权利要求1-9中任一所述的数据召回方法。
技术总结
本公开实施例公开了一种数据召回方法、装置、电子设备及存储介质,其中该方法包括:从各种子数据中确定与每个初始数据匹配的至少一个目标种子数据;确定所述各目标种子数据的类别权重;根据与各所述初始数据匹配的各目标种子数据的类别权重以及所属类别,确定各所述初始数据的初始类别;根据所述各初始数据的初始类别,对所述各初始数据进行初始召回,得到初始召回的结果;利用召回模型,对所述初始召回的结果进行再次召回,得到最终召回结果;其中,所述召回模型在训练过程中使用的训练数据中的至少部分由样本数据的初始召回的结果确定。不仅能够提高召回效率,还可以提高召回的准确率。
技术研发人员:余晏,陈泽晗,祝航程,马国俊
受保护的技术使用者:北京字跳网络技术有限公司
技术研发日:
技术公布日:2024/3/24
- 还没有人留言评论。精彩留言会获得点赞!