一种半结构化访谈与跨模态融合的情绪识别方法及装置
1.本发明涉及计算机人工智能技术领域,特别是涉及一种半结构化访谈与跨模态融合的情绪识别方法及装置。
背景技术:
2.随着社会的快速发展以及人们工作、生活压力的日益增加,抑郁等情绪问题持续高发。抑郁情绪对个人生活以及家庭和社会均存在着较大的危害。当前情绪问题的识别主要基于量表的方法。在实践中具体确定还依赖于心理咨询师通过人工访谈的方式进行评估。
3.常用的量表工具包括自评的健康问卷(patient health questionnaire-9,phq-9)、抑郁情绪状快速评定量表(quick inventory of depressive symptomatology,qids),也包括通常使用的他评量表,如汉密尔顿抑郁量表(hamilton depression scale,hamd)、蒙哥马利抑郁评定量表(montgomery-asberg depression rating scale,madrs)量表。
4.然而,情绪问题具有一系列的视听行为指征。在识别和评估情绪问题的量表中,这些指征往往没有得到充分考虑。综合利用信息技术、人工智能等多样化手段是目前在情绪问题量化评估领域的新趋势,其中包括基于视觉信号(如面部表情、眼动、手势、头部运动)的情绪检测方法,基于语音(如韵律、频谱图、波形)的情绪检测方法、以及基于文本(如稀疏词汇编码)的情绪检测方法。但大多方法主要对单一行为模态,如视觉、语音、文本模态进行建模,且现有的跨模态融合方法无法解决模态内在不对齐以及长时的语义关联性问题,导致识别评估方法效果不佳。
技术实现要素:
5.本发明实施例提供了一种半结构化访谈与跨模态融合的情绪识别方法及装置。所述技术方案如下:一方面,提供了一种半结构化访谈与跨模态融合的情绪识别方法,该方法由电子设备实现,该方法包括:通过采集预设的半结构化主题模拟访谈的结果,获得被测者的音频数据以及视频数据,根据获得的音频数据转化得到文本数据;其中,所述半结构化主题模拟访谈的结果是由被测者完成预设调研问卷测试的结果得到,所述预设调研问卷测试的内容基于情绪问题专家的调研结果生成,所述预设问卷调研测试的内容包括12项访谈主题;所述半结构化主题模拟访谈在移动终端中通过应用程序或小程序实现。
6.通过预设方法分别对所述音频数据、视频数据以及文本数据进行特征提取,分别得到音频特征数据、视频特征数据以及文本特征数据;可选地,所述预设方法分别对所述音频数据、视频数据以及文本数据进行特征提取,分别得到音频特征数据、视频特征数据以及文本特征数据,包括:
通过opensmile对所述音频数据进行特征提取,获得egemaps特征集作为音频特征数据;通过openface对所述视频数据进行特征提取,获得面部运动单元出现的概率和强度作为视频特征数据;通过预训练中文bert模型对所述文本数据进行特征提取,获得结果作为文本特征数据。
7.基于一维时域卷积操作,对所述音频特征数据、视频特征数据以及文本特征数据进行归一化;分别对归一化后的音频特征数据、视频特征数据以及文本特征数据进行携带时域信息的位置编码,得到第一输入特征数据;基于第一特征数据以及crossmodal-transformer跨模态融合模型进行音频模态、视频模态以及文本模态上的语义对齐与信息交换,得到音频模态、视频模态以及文本模态上特征数据相互影响后的第二输入特征数据;可选地,所述音频模态、视频模态以及文本模态上的语义对齐与信息交换,得到音频模态、视频模态以及文本模态上特征数据相互影响后的第二输入特征数据,包括:将每个模态的输入特征数据转换成一组不同的键/值对,通过crossmodal-transformer跨模态融合模型与目标模态特征数据相互作用,获得一组接受目标模态以外的其他模态信息的不同的键/值对,使用接受其他模态信息的不同的键/值对替换目标模态特征数据的键/值对。
8.将第二输入特征数据中的音频模态数据、视频模态数据以及文本模态数据进行串联;基于串联后的第二输入特征数据以及crossmodal-transformer跨模态融合模型的全连接层,得到跨模态融合情绪识别结果,完成对所述被测者情绪的识别和评估。
9.可选地,所述基于串联后的第二输入特征数据以及crossmodal-transformer跨模态融合模型的全连接层,得到跨模态融合情绪识别结果,包括:将串联后的接受其他模态信息的不同的键/值对输入全连接层进行分类,得到情绪识别的分类输出结果,根据所述分类输出结果判断是否存在情绪问题,输出判断结果;对分类输出结果进行回归操作,得到回归输出结果,根据所述回归输出结果评估情绪问题的严重程度,输出情绪问题的严重程度数值。
10.另一方面,提供了一种半结构化访谈与跨模态融合的情绪识别装置,该由电子设备实现,该装置包括:一种半结构化访谈与跨模态融合的情绪识别装置,其特征在于,所述装置包括:获取模块,用于通过采集预设的半结构化主题模拟访谈的结果,获得被测者的音频数据以及视频数据,根据获得的音频数据转化得到文本数据;可选地,所述获取模块,用于:半结构化主题模拟访谈的结果是由被测者完成预设调研问卷测试的结果得到,预设调研问卷基于情绪问题专家的调研结果,其中包括12项访谈主题;半结构化访谈在移动终端中通过应用程序或小程序实现。
11.特征提取模块,用于通过预设方法分别对所述音频数据、视频数据以及文本数据进行特征提取,分别得到音频特征数据、视频特征数据以及文本特征数据;可选地,所述特征提取模块,用于:
音频数据采用opensmile提取egemaps特征集作为音频特征;视频数据采用openface提取面部运动单元出现的概率和强度作为视觉特征;文本数据采用预训练中文bert模型提取文本特征。
12.归一化模块,用于基于一维时域卷积操作,对所述音频特征数据、视频特征数据以及文本特征数据进行归一化;编码模块,用于分别对归一化后的音频特征数据、视频特征数据以及文本特征数据进行携带时域信息的位置编码,得到第一输入特征数据;信息交换模块,用于第一特征数据以及crossmodal-transformer跨模态融合模型进行音频模态、视频模态以及文本模态上的语义对齐与信息交换,得到音频模态、视频模态以及文本模态上特征数据相互影响后的第二输入特征数据;可选地,所述信息交换模块,用于:每个模态的输入特征数据转换成一组不同的键/值对,通过crossmodal-transformer跨模态融合模型与目标模态特征数据相互作用,获得一组接受目标模态以外的其他模态信息的不同的键/值对。
13.串联模块,用于将第二输入特征数据中的音频模态数据、视频模态数据以及文本模态数据进行串联;评估模块,用于基于串联后的第二输入特征数据以及crossmodal-transformer跨模态融合模型的全连接层,得到跨模态融合情绪识别结果,完成对所述被测者情绪的识别和评估。
14.可选地,所述评估模块,用于:将串联后的接受其他模态信息的不同的键/值对输入全连接层进行分类,得到情绪识别方法的分类输出结果,根据分类输出结果判断是否存在情绪问题,输出判断结果;对分类输出结果进行回归操作,得到回归输出结果,根据所述回归输出结果评估情绪问题的严重程度,输出情绪问题的严重程度数值。
15.另一方面,提供了一种电子设备,所述电子设备包括处理器和存储器,所述存储器中存储有至少一条指令,所述至少一条指令由所述处理器加载并执行以实现上述一种半结构化访谈与跨模态融合的情绪识别方法。
16.另一方面,提供了一种计算机可读存储介质,所述存储介质中存储有至少一条指令,所述至少一条指令由处理器加载并执行以实现上述一种半结构化访谈与跨模态融合的情绪识别方法。
17.本发明实施例提供的技术方案带来的有益效果至少包括:本发明提出的方法,在半结构化访谈形式上,本方法具有高生态效度,便于在移动终端规范化进行大范围施测。在算法性能上,本方法基于中文跨模态数据集构建,适用于国内大范围应用,所取得的跨模态情绪识别实验结果与评估实验结果,在多种融合方式多个指标上综合优于现有方法机器学习方法和深度学习方法,有助于实现自动化情绪辅助识别与评估。本方法关注存在强信号或相关性的其他模态中的信息,能够以手动对齐无法轻易揭示的方式捕获远程跨模态关联情况,解决了跨模态融合方法内在不对齐以及长时的语义关联性问题,情绪识别评估方法的效果有显著提升。
附图说明
18.为了更清楚地说明本发明实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
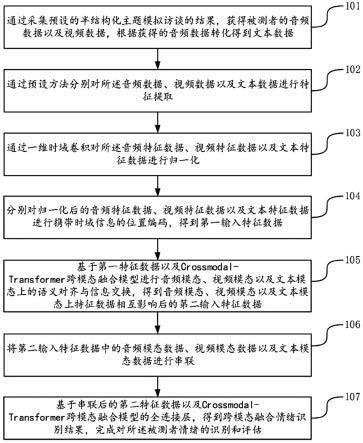
19.图1是本发明实施例提供的一种半结构化访谈与跨模态融合的情绪识别方法流程图;图2是本发明实施例提供的一种半结构化访谈与跨模态融合的情绪识别装置框图;图3是本发明实施例提供的一种半结构化访谈与跨模态融合的情绪识别电子设备的结构示意图。
具体实施方式
20.为使本发明要解决的技术问题、技术方案和优点更加清楚,下面将结合附图及具体实施例进行详细描述。
21.本发明实施例提供了一种半结构化访谈与跨模态融合的情绪识别方法,该方法可以是终端或服务器。如图1所示的一种半结构化访谈与跨模态融合的情绪识别方法流程图,该方法的处理流程可以包括如下的步骤:s101、通过采集预设的半结构化主题模拟访谈的结果,获得被测者的音频数据以及视频数据,根据获得的音频数据转化得到文本数据;其中,半结构化主题模拟访谈的结果是由被测者完成预设调研问卷测试的结果得到,预设调研问卷测试的内容基于情绪问题专家的调研结果生成;半结构化主题模拟访谈在移动终端中通过应用程序或小程序实现。
22.s102、通过预设方法分别对音频数据、视频数据以及文本数据进行特征提取,分别得到音频特征数据、视频特征数据以及文本特征数据;可选地,预设方法分别对音频数据、视频数据以及文本数据进行特征提取,分别得到音频特征数据、视频特征数据以及文本特征数据,包括:通过opensmile对音频数据进行特征提取,获得gemaps特征集作为音频特征数据;通过openface对视频数据进行特征提取,获得面部运动单元出现的概率和强度作为视频特征数据;通过预训练中文bert模型对所述文本数据进行特征提取,获得结果作为文本特征数据。
23.一种可行的实施方式中,opensmile的应用流程:读取命令行选项,并解析配置文件,选择输出特征集为gemaps。注册组件管理器组件和内存数据,然后配置主要步骤的输入/输出文件的字段的名称和尺寸。重复上述步骤数次,有些组件可能依赖于其他组件的配置(例如,组件读取来自另一个组件输出的维度和输出中字段的名称)。所有组件都被成功初始化后,组件管理器启动主执行循环(也可称为滴答循环)。每个组件都有一个tick()方法,该方法实现主要的增量处理功能,并通过其返回值报告处理的状态。
24.当输入结束时,组件管理器通过运行执行循环的最后一次迭代向组件发出输入结
束的信号,并输出gemaps特征集做为音频特征数据。
25.一种可行的实施方式中,openface的应用流程:openface支持静态和动态两种动作单元预测模型。一般而言,在图像检测中默认使用静态模型,在图像序列和视频的检测中使用动态模型。面部动作单元(au)是描述人类面部表情的一种方式,本发明中选择输出运动单元作为模型的输出,并根据运动单元的概率和强度作为视频特征数据。
26.一种可行的实施方式中,预训练中文bert模型的应用流程:bert模型的目标是利用大规模无标注语料训练、获得文本的包含的语义信息,神经网络将文本中各个字或词的一维词向量作为输入,经过一系列的转换后,输出一个一维词向量作为文本的语义表示。bert模型将字向量、文本向量和位置向量的加和作为模型输入。其中,文本向量的取值在模型训练过程中自动学习,用于刻画文本的全局语义信息,并与单字/词的语义信息相融合;位置向量用于区分不同位置的字/词分别附加一个不同的向量。
27.s103、基于一维时域卷积操作,对音频特征数据、视频特征数据以及文本特征数据进行归一化;一种可行的实施方式中,特征数据归一化采用0均值归一化。对于线性模型来说,特征数据归一化是为了使不同的特征处于同样的量级范围内,避免因某些特征所占比重过大,导致预测结果失真。对于梯度下降优化的算法,特征数据归一化会避免特征空间的不规则化,大大减少模型输出结果收敛需要的迭代次数。0均值归一化将原始数据均映射到均值为0,标准差为1的分布上。具体来说,假设原始特征的均值为μ、标准差为σ,具体公式如下:s104、分别对归一化后的音频特征数据、视频特征数据以及文本特征数据进行携带时域信息的位置编码,得到第一输入特征数据;一种可行的实施方式中,跨模态融合模型机制中没有包含位置信息,所以构建一个跟输入维度一样的矩阵,具体公式如下:其中,pe是与输入维度相同的二维矩阵,行表示词语,列表示词向量;pos表示词语在语句中的位置;d
model
表示词向量的维度;i表示词向量的位置。再将pe矩阵中的奇数位置元素添加cos变量,偶数位置元素添加sin变量,完成位置编码的引入。
28.s105、通过第一特征数据以及crossmodal-transformer跨模态融合模型进行音频模态、视频模态以及文本模态上的语义对齐与信息交换,得到音频模态、视频模态以及文本模态上特征数据相互影响后的第二输入特征数据;可选地,通过第一特征数据以及crossmodal-transformer跨模态融合模型进行音频模态、视频模态以及文本模态上的语义对齐与信息交换,得到音频模态、视频模态以及文本模态上特征数据相互影响后的第二输入特征数据,包括;
将每个模态的输入特征数据转换成一组不同的键/值对,通过crossmodal-transformer跨模态融合模型与目标模态特征数据相互作用,获得一组接受目标模态以外的其他模态信息的不同的键/值对,使用接受其他模态信息的不同的键/值对替换目标模态特征数据的键/值对。
29.一种可行的实施方式中,基于crossmodal-transformer跨模态融合模型中的跨模注意力模块设计跨模transformer模块,使一个模态从其他模态接受信息。以下用模态vision(v)到模态language(l)为例:每个跨模态transformer都由跨模注意力块组成,跨模态transformer计算前馈(feed-forwardly)如下:其中,为以为参数的位置前馈子层;是i层中从模态v到模态l的multi-head版的跨模注意力;ln代表层标准化操作(layer normalization),ln是在每一层对单个样本的所有神经元节点进行规范化。
30.根据以上流程连接所有跨模transformers的输出,得到根据以上流程连接所有跨模transformers的输出,得到例如。
31.s106、将第二输入特征数据中的音频模态数据、视频模态数据以及文本模态数据进行串联;s107、基于串联后的第二输入特征数据以及crossmodal-transformer跨模态融合模型的全连接层,得到跨模态融合情绪识别结果,完成对被测者情绪的识别和评估。
32.可选地,基于串联后的第二输入特征数据以及crossmodal-transformer跨模态融合模型的全连接层,得到跨模态融合情绪识别结果,包括:将串联后的接受其他模态信息的不同的键/值对输入全连接层进行分类,得到情绪识别的分类输出结果,根据分类输出结果判断是否存在情绪问题,输出判断结果;对分类输出结果进行回归操作,得到回归输出结果,根据所述回归输出结果评估情绪问题的严重程度,输出情绪问题的严重程度数值。
33.一种可行的实施方式中,全连接层整合前层网络提取的特征信息,并将特征信息映射到样本标记空间。全连接层会把卷积输出的二维特征图(featuremap)转化成一个一维的向量。全连接层对前层输出的特征进行加权求和,并把结果输入到激活函数,最终完成目标的分类。加权求和计算公式如下:其中,wi是全连接层中的权重系数,xi是上一层第i个神经元的值,bi是全连接层的
偏置量。
34.本发明提出的方法,在半结构化访谈形式上,本方法具有高生态效度,便于在移动终端规范化进行大范围施测。在算法性能上,本方法基于中文跨模态数据集构建,适用于国内大范围应用,所取得的跨模态情绪识别实验结果与评估实验结果,在多种融合方式多个指标上综合优于现有方法机器学习方法和深度学习方法,有助于实现自动化情绪辅助识别与评估。本方法关注存在强信号或相关性的其他模态中的信息,能够以手动对齐无法轻易揭示的方式捕获远程跨模态关联情况,解决了跨模态融合方法内在不对齐以及长时的语义关联性问题,情绪识别评估方法的效果有显著提升。
35.图2是根据一示例性实例示出的一种半结构化访谈与跨模态融合的情绪识别装置框图。参照图2,该装置包括:获取模块210,用于通过采集预设的半结构化主题模拟访谈的结果,获得被测者的音频数据以及视频数据,根据获得的音频数据转化得到文本数据;可选地,所述获取模块210,用于:半结构化主题模拟访谈的结果是由被测者完成预设调研问卷测试的结果得到,预设调研问卷基于情绪问题专家的调研结果;半结构化访谈在移动终端中通过应用程序或小程序实现。
36.特征提取模块220,用于通过预设方法分别对所述音频数据、视频数据以及文本数据进行特征提取,分别得到音频特征数据、视频特征数据以及文本特征数据;可选地,所述特征提取模块220,用于:音频数据采用opensmile提取egemaps特征集作为音频特征;视频数据采用openface提取面部运动单元出现的概率和强度作为视觉特征;文本数据采用预训练中文bert模型提取文本特征。
37.归一化模块230,用于基于一维时域卷积操作,对所述音频特征数据、视频特征数据以及文本特征数据进行归一化;编码模块240,用于分别对归一化后的音频特征数据、视频特征数据以及文本特征数据进行携带时域信息的位置编码,得到第一输入特征数据;信息交换模块250,用于通过第一特征数据以及crossmodal-transformer跨模态融合模型进行音频模态、视频模态以及文本模态上的语义对齐与信息交换,得到音频模态、视频模态以及文本模态上特征数据相互影响后的第二输入特征数据;可选地,所述信息交换模块250,用于:将每个模态的输入特征数据转换成一组不同的键/值对,通过crossmodal-transformer跨模态融合模型与目标模态特征数据相互作用,获得一组接受目标模态以外的其他模态信息的不同的键/值对,使用接受其他模态信息的不同的键/值对替换目标模态特征数据的键/值对。
38.串联模块260,用于将第二输入特征数据中的音频模态数据、视频模态数据以及文本模态数据进行串联;评估模块270,用于基于串联后的第二输入特征数据以及crossmodal-transformer跨模态融合模型的全连接层,得到跨模态融合情绪识别结果,完成对所述被测者情绪的识别和评估。
39.可选地,所述评估模块270,用于:将串联后的接受其他模态信息的不同的键/值对输入全连接层进行分类,得到情绪识别方法的分类输出结果,根据分类输出结果判断是否存在情绪问题,输出判断结果;对分类输出结果进行回归操作,得到回归输出结果,根据所述回归输出结果评估情绪问题的严重程度,输出情绪问题的严重程度数值。
40.本发明提出的方法,在半结构化访谈形式上,本方法具有高生态效度,便于在移动终端规范化进行大范围施测。在算法性能上,本方法基于中文多跨模态数据集构建,适用于国内大范围应用,所取得的跨模态情绪识别实验结果与评估实验结果,在多种融合方式多个指标上综合优于现有方法机器学习方法和深度学习方法,有助于实现自动化情绪辅助识别与评估。本方法关注存在强信号或相关性的其他模态中的信息,能够以手动对齐无法轻易揭示的方式捕获远程跨模态关联情况,解决了跨模态融合方法内在不对齐以及长时的语义关联性问题,情绪识别评估方法的效果有显著提升。
41.图3是本发明实施例提供的一种电子设备300的结构示意图,该电子设备300可因配置或性能不同而产生比较大的差异,可以包括一个或一个以上处理器(central processing units,cpu)301和一个或一个以上的存储器302,其中,所述存储器302中存储有至少一条指令,所述至少一条指令由所述处理器301加载并执行以实现上述半结构化访谈与跨模态融合的情绪识别方法的步骤。
42.在示例性实施例中,还提供了一种计算机可读存储介质,例如包括指令的存储器,上述指令可由终端中的处理器执行以完成上述半结构化访谈与跨模态融合的情绪识别方法。例如,所述计算机可读存储介质可以是rom、随机存取存储器(ram)、cd-rom、磁带、软盘和光数据存储设备等。
43.本领域普通技术人员可以理解实现上述实施例的全部或部分步骤可以通过硬件来完成,也可以通过程序来指令相关的硬件完成,所述的程序可以存储于一种计算机可读存储介质中,上述提到的存储介质可以是只读存储器,磁盘或光盘等。
44.以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1