一种语音驱动人脸关键点序列生成方法及装置与流程
1.本发明涉及计算机动画和虚拟现实领域,尤其是涉及了一种语音驱动人脸关键点序列生成方法及装置。
背景技术:
2.在计算机动画和虚拟人领域,基于语音驱动虚拟人说话是一个重要的研究方向。该技术可以生成虚拟人说话序列,并同时使得虚拟人的嘴部动作、头部转动和表情能够与语音保持同步,其在影视制作、虚拟现实、游戏角色动画等众多领域有着广泛的引用需求。现阶段的数据驱动的说话人生成技术主要是基于回归的判别模型,即直接将语音信号映射到嘴唇同步人脸序列,该过程是基于监督学习,导致其在实际的模型训练过程中容易回归到一个平均脸,而且无法生成的具有多样性的说话人脸序列。
3.因此,模型训练过程生成的具有多样性的说话人脸序列仍旧是需要攻克的技术难点。
技术实现要素:
4.针对现有技术的不足,本发明提供了一种语音驱动人脸关键点序列生成方法及装置,该方法通过开源的人脸关键点检测方法构建其对应的人脸关键点序列数据集,并构建和训练基于标准流模型的语音驱动人脸关键点序列模型,将任意输入的语音序列和随机采样高斯噪声一起输入训练好的最佳参数模型中进行模型推断,生成其语音驱动人脸关键点序列。
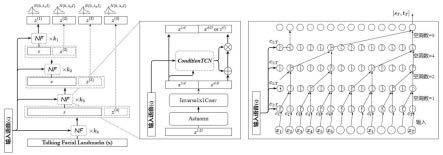
5.本发明是通过以下技术方案来实现的,所述一种基于标准流模型的语音驱动人脸关键点序列生成方法,该方法包括如下步骤:(1)数据集构建:通过摄像机拍摄大量的人脸说话视频数据,保存其语音数据,并通过开源的人脸关键点检测方法得到其对应的人脸关键点序列数据集;(2)构建模型:所述模型为一个四层的加权多尺度框架;每层有k个标准流模块;每个标准流模型模块都包含条件时空卷积神经网络模块,用于融合语音数据;具体为,每通过k个模块输出一半的隐变量数据,最后把所有的隐变量数据合并一起便之趋近于高斯分布;即在每层最后一个标准流模块中输出后一半的值,其前一半值将继续进行下一层的计算,且每一层输出的值便是模型最终的输出值,通过不断迭代优化损失函数项,使这些值服从于具有不同方差的高斯分布;且所述k1;(3)模型训练:利用步骤(1)中得到的人脸关键点序列数据集训练步骤(2)中构建的模型,具体为,将人脸关键点序列作为输入,语音序列作为条件输入,输出噪声值,通过不断迭代优化损失函数项,训练模型直至其收敛,得到最佳参数模型;所述损失函数约束该输出的噪声趋近高斯正态分布;(4)模型推断:利用将任意的语音序列和随机采样的高斯噪声输入至步骤(3)得到的最佳参数模型,得到输出的语言驱动人脸关键点序列。
6.进一步地,所述步骤(2)中k的数量由用户自定义设置。
7.进一步地,所述步骤(2)中的标准流模型模块具体为:该模块的输入是上一层标准流模块的输出,第一层将人脸关键点序列landmarks(x)作为输入,依次经过标准化网络层、1x1可逆卷积层以及条件时空卷积神经网络模块,将人脸关键点序列的数据流基于d值分为两部分输出x
1:d
和x
d:d
,所述d为x长度的一半,即d = d/2;所述条件时空卷积神经网络模块用以融合语音输入信息,最后将条件时空卷积神经网络模块输出的缩放和平移参数,将这两个参数x
1:d
和x
d:d
通过一个仿射对偶层,将数据流x分为两部分输出和,在每层的最后一个标准流模块中,其输出的后一半值将会作为一部分最终输出值;其数学表达式如下:进一步地,所述步骤(2)中的条件时空卷积神经网络模块具体为:将是语音数据和标准流模块的仿射对偶层的前一半数据在时序方向进行融合,然后通过四层一维空洞卷积输出,其每层空洞卷积的空洞参数值分别为1,2,4和8,卷积核的大小为3。
8.进一步地,所述步骤(2)中的条件时空卷积神经网络模块采用的是因果卷积操作;避免卷积操作时引入未来的信息。
9.进一步地,所述步骤(4)中随机采样的高斯噪声的不同,生成的人脸关键点序列也将具有不同头部姿态,即生成多种语音驱动的人脸关键点序列。
10.一种基于标准流模型的语音驱动人脸关键点序列生成装置,包括:构建数据集模块:通过摄像机拍摄大量的人脸说话视频数据,保存其语音数据,并通过开源的人脸关键点检测方法得到其对应的人脸关键点序列数据集;构建模型模块:所述模型为一个四层的加权多尺度框架;每层有k个标准流模块;每个标准流模型模块都包含条件时空卷积神经网络模块,用于融合语音数据;具体为,每通过k个模块输出一半的隐变量数据,最后把所有的隐变量数据合并一起便之趋近于高斯分布;即在每层最后一个标准流模块中输出后一半的值,其前一半值将继续进行下一层的计算,且每一层输出的值便是模型最终的输出值,通过不断迭代优化损失函数项,使这些值服从于具有不同方差的高斯分布;且所述k1;模型训练模块:利用构建数据集模块中得到的人脸关键点序列数据集训练构建模型模块中构建的模型,具体为,将人脸关键点序列作为输入,语音序列作为条件输入,输出噪声值,通过不断迭代优化损失函数项,训练模型直至其收敛,得到最佳参数模型;所述损失函数约束该输出的噪声趋近高斯正态分布;模型推断模块:利用将任意的语音序列和随机采样的高斯噪声输入至模型训练模块得到的最佳参数模型,得到输出的语言驱动人脸关键点序列。
11.本发明有益效果如下:将标准流模型引入说话人脸序列生成问题中,将语音到人脸说话序列的映射变成
了生成式问题,利用生成模型的优势,能够解决回归模型的局限性,且能够多样性生成说话人序列。本发明基于标准流模型,提出了一种加权多尺度框架,并且设计了一种条件时空卷积神经网络模块用于对语音进行时序建模以作为条件输入标准流模型中。大量实验表明,本发明能够生成高质量且动作自然的人脸说话序列。
附图说明
12.图1是本发明的模型框架图;图2是本发明的测试生成结果图;图3是本发明的装置流程图。
具体实施方式
13.以下结合附图对本发明的具体实施方式进行详细说明。应当理解的是,此处所描述的具体实施方式仅用于说明和解释本发明,并不用于限制本发明。
14.如图1和图3所示,一种基于标准流模型的语音驱动人脸关键点序列生成装置,包括:构建数据集模块:通过摄像机拍摄大量的人脸说话视频数据,保存其语音数据,并通过开源的人脸关键点检测方法得到其对应的人脸关键点序列数据集;构建模型模块:所述模型为一个四层的加权多尺度框架;每层有k个标准流模块;每个标准流模型模块都包含条件时空卷积神经网络模块,用于融合语音数据;具体为,每通过k个模块输出一半的隐变量数据,最后把所有的隐变量数据合并一起便之趋近于高斯分布;即在每层最后一个标准流模块中输出后一半的值,其前一半值将继续进行下一层的计算,且每一层输出的值便是模型最终的输出值,通过不断迭代优化损失函数项,使这些值服从于具有不同方差的高斯分布;且所述k1;模型训练模块:利用构建数据集模块中得到的人脸关键点序列数据集训练构建模型模块中构建的模型,具体为,将人脸关键点序列作为输入,语音序列作为条件输入,输出噪声值,通过不断迭代优化损失函数项,训练模型直至其收敛,得到最佳参数模型;所述损失函数约束该输出的噪声趋近高斯正态分布;模型推断模块:利用将任意的语音序列和随机采样的高斯噪声输入至模型训练模块得到的最佳参数模型,得到输出的语言驱动人脸关键点序列。
15.一种基于标准流模型的语音驱动人脸关键点序列生成方法,包含如下步骤:s1,数据集构建。通过摄像机拍摄大量的人脸说话视频数据,保存其语音数据,并通过开源的人脸关键点检测方法得到其对应的人脸关键点序列数据集;构建模型时,如图1中所述的模型为一个包含四层标准流模块的加权多尺度框架,首先给一段时间长度为t的语音序列以及其对应的人脸表情关键点序列,本发明是将其语音序列作条件输入模型中以生成人脸表情关键点序列。首先将人脸表情关键点序列输入模型中,然后通过多个标准流模块,每个模块通过条件时空卷积神经网络模块(conditionaltcn)将语音数据融合到主干网络中,其中每通过k个
模块输出一半的隐变量数据,最后把所有的隐变量数据合并一起便之趋近于高斯分布。由于标准流模型具有可逆性,因此在推断时,输入随机采样的高斯噪声,便可以生成以语音为条件输入的对应人脸表情关键点序列。具体而言,所述模型主要有三个部分:s1.1,加权多尺度框架。如图1所示,将人脸关键点序列x(即面部标记点talking facial landmarks(x))输入具有4层的多尺度的标准流模型,其中每层包含k个融合了语音数据的标准流模块,然后在每层最后一个模块中输出其一半的隐变量z(x),即一半的值,最后将这些隐变量合并使其趋近于不同方差的高斯分布,即在每层最后一个标准流模块中输出后一半的值,其前一半值将继续进行下一层的计算,且每一层输出的值便是模型最终的输出值,通过不断迭代优化损失函数项,使这些值服从于具有不同方差的高斯分布;且所述k的数量由用户自定义。
16.s1.2,标准流模型模块。如图1所示,该模块的输入为上一层标准流模块的输出,即第一层将landmarks(x)作为输入,依次经过标准化网络层(actnorm)、1x1可逆卷积层(inverse1x1conv),以及条件时空卷积神经网络模块(conditionaltcn),将数据流x基于d值(d为x长度的一半,即d = d/2,)分为两部分输出x
1:d
和x
d:d
;所述条件时空卷积神经网络模块用以融合语音输入信息,最后将条件时空卷积神经网络模块输出的缩放和平移参数,将这两个参数、x
1:d
和x
d:d
通过一个仿射对偶层(affine couple layer),将数据流x分为两部分输出和,在每层的最后一个标准流模块中,其输出的后一半值将会作为一部分最终输出值;其数学表达式如下:s1.3,条件时空卷积神经网络模块。如图1所示,该模块的输入是语音数据,以及标准流模块的前一半数据x
1:d
,两者在时序方向进行融合,将和语音c的信息输入条件时空卷积神经网络模块中,通过四层一维空洞卷积输出,得到后续仿射对偶层的缩放和平移两个参数;其每层空洞卷积的空洞参数值分别为1,2,4和8,卷积核的大小为3。
17.所述条件时空卷积神经网络模块采用的是因果卷积操作;避免卷积操作时引入未来的信息。
18.s2,训练模型。采集大量的说话人音视频同步数据,提取音频的mfcc特征,以及视频每帧的人脸关键点坐标,构建模型并训练模型直至收敛,得到最佳参数模型。图2是模型的测试生成结果图,分别展示了输入三个音频后经过算法得到的不同人脸关键点序列,其中t代表在该序列内不同时间上的取值。
19.s3,模型推断。利用将任意的语音序列和随机采样的高斯噪声输入至s2中训练好的最佳参数模型,对任意输入语音生成说话人表情关键点序列,即语言驱动人脸关键点序列。
20.以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修
改或者替换,并不使相应技术方案的本质脱离本发明实施例技术方案的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1