基于多源异构信息融合的自动驾驶目标检测与跟踪方法
1.本发明涉及自动驾驶技术领域,尤其是涉及基于多源异构信息融合的自动驾驶目标检测与跟踪方法。
背景技术:
2.近年来,交通事故以及交通拥堵现象频繁发生,给人类生命财产安全造成了极大威胁。随着科技的不断进步,自动驾驶已成为解决这类难题的关键手段。目标检测与目标跟踪技术在自动驾驶领域占据重要地位,但由于驾驶环境具有复杂性和动态性且单一传感器能力有限,需要融合多种传感器以确保对目标稳健、准确、可靠的检测与跟踪。
3.在自动驾驶目标检测领域,得益于视觉目标检测技术的快速发展,多传感器融合检测技术由雷达为主、相机辅助渐渐转变为雷达为辅、相机为主的策略。利用雷达对目标定位能力强的特性,辅助相机目标检测算法的执行成为近两年研究的重点。yolov5目标检测算法是近两年诞生的一款实时高效的单阶段目标检测算法,十分适用于道路环境多变的自动驾驶领域。如果在yolov5目标检测算法中提前告知检测网络应该重点检测图像中哪部分区域,那么又会使检测速度与精度提升一个阶段。
4.在自动驾驶目标跟踪领域,传统的仅依靠视觉的跟踪技术稳定性不高,尤其是目标被障碍物遮挡后容易导致相机出现跟踪失败的情况。因此,采用多传感器融合跟踪方法是提高自动驾驶目标跟踪稳定性的一种有效措施,利用雷达与相机等多传感器对目标进行跟踪能满足不同道路状况下对目标持续稳定跟踪的需求。
技术实现要素:
5.基于上述背景,本发明基于yolov5目标检测算法对相机数据处理,基于kcf目标跟踪算法对雷达数据处理,并采用雷达为辅、相机为主的策略融合两传感器数据,从而实现车辆目标的精准检测与稳定跟踪。
6.基于多源异构信息融合的自动驾驶目标检测与跟踪方法,包括如下步骤:
7.s1、将车载毫米波雷达与相机采集数据进行时间与空间配准,然后通过坐标变换将毫米波雷达点投影至相机图像坐标系中;
8.s2、构建雷达特征图,利用雷达定位能力强的特点,为相机目标检测算法提供空间注意力模块;
9.s3、将senet通道注意力模块以及雷达特征图空间注意力模块引入目标检测算法yolov5的backbone结构中,从而使目标检测算法更关注于目标可能存在的区域,以提高目标检测的速度与精度;
10.s4、构建融合扩展卡尔曼滤波与数据关联算法的kcf目标跟踪算法;
11.s5、在相机未被遮挡情况下,融合目标检测算法与目标跟踪算法对车辆目标追踪;在相机被遮挡情况下,基于目标跟踪算法对车辆目标追踪。
12.进一步的,s1步骤的具体处理过程如下:
13.s11、为实现毫米波雷达与相机的时间配准,由于两传感器的采样频率不同,利用雷达采样后触发相机采样的方式实现两传感器时间上的配准问题;
14.s12、为实现毫米波雷达与相机的空间配准,由于两传感器对目标的坐标描述不同,需要将两传感器的数据统一到同一坐标系中,车载毫米波雷达与相机的空间转换模型可以表示为:
[0015][0016]
式中,[x
r y
r z
r 1]
t
为毫米波雷达坐标下目标的坐标;[u v 1]
t
为像素坐标系下目标的坐标;r为3
×
3的单位正交旋转矩阵;t为3
×
1的平移矩阵;i为单位矩阵;d
x
与dy分别表示每个像素在横、纵轴上的物理单位下的大小;f为相机的焦距;k为缩放因子;xr、yr、zr为目标在毫米波雷达坐标系下的三维坐标;u、v为目标在像素坐标系下的二维坐标;zc为相机坐标系下的坐标;u0、v0为在坐标系旋转变换操作之前像素坐标系中的二维坐标。
[0017]
s13、基于配准后的数据,将毫米波雷达点投影至相机图像中。
[0018]
进一步的,s2步骤的具体处理过程如下:
[0019]
s21、生成一个和图像同样大小的空白单通道雷达特征图,雷达特征图中每个像素点的初始值设置为0;
[0020]
s22、在初始化雷达特征图中各像素点值为0以后,以雷达特征图中单个雷达投影点为中心构建roi感兴趣区域,即雷达探测到的目标可能位置,然后将雷达特征图的roi感兴趣区域中的像素点值设为1;
[0021]
s23、当目标距离越近或目标尺寸越大时,经聚类处理后雷达反射点越多;可看做,roi区域的面积大小与聚类后雷达点数量有关并成线性关系,即:
[0022]
s=αn+β
[0023]
式中,n为雷达反射点的个数;α和β为超参数;
[0024]
α和β通过最大化roi与真实标记框的iou进行学习得到,公式如下:
[0025][0026]
式中,n为学习超参数过程中输入样本数;mi为第i个样本中物体的标记框个数;
[0027]
iou的计算公式如下:
[0028][0029]
式中,roi表示roi感兴趣区域;gt表示真实标记框区域;s表示求取面积:
[0030]
s24、最终,生成roi感兴趣区域内像素值为1、其他部分像素值为0的表示目标位置信息的雷达特征图。
[0031]
进一步的,s3步骤的具体处理过程如下:
[0032]
s31、senet全称是squeeze-and-excitation networks,即压缩和激励网络;其中,squeeze部分即把输入(h,w,c)特征图压缩为(1,1,c),excitation部分将压缩后的(1,1,c)特征图送入一个全连接层从而对每个通道的重要性进行预测,得到不同通道重要性大小后再作用到输入特征图对应的通道上,便于目标检测网络能够对特征图的不同通道特征施加不同注意力,即senet的作用是对输入特征图的不同通道提供不同权重,从而使目标检测算法更加高效准确;
[0033]
s32、将senet通道注意力模块加在目标检测算法yolov5中backbone结构的最后一层,将通道权重值分别和特征图对应通道的二维矩阵相乘,从而让网络可以更加专注于特征图中权值大的通道;
[0034]
s33、将senet通道注意力模块处理后的特征图与雷达特征图相乘,使特征图同时受通道注意力权重和空间位置注意力权重影响,以此构建融合雷达信息的通道-空间注意力机制模块;
[0035]
s34、将通道-空间注意力模块插入至目标检测算法yolov5的backbone结构的最后一层,以获取目标可能存在的候选区域和先验信息,从而使目标检测算法更加快速高效的检测出目标。
[0036]
进一步的,s4步骤的具体处理过程如下:
[0037]
s41、在雷达探测坐标系下,采用bicycle动力学模型对车辆目标进行建模,用描述车辆运动状态,主车与前车目标之间的相对运动方程为:
[0038][0039]
式中,a,b为模型的输入量;b为前车的轴距;v为主车与前车的相对速度;为前车的前轮转向角;θ为前车的方向角;xr、yr为车辆当前的坐标;
[0040]
将上式离散化,则满足:
[0041][0042]
式中,δa与δb为干扰噪声;δ
p
与δs为相乘噪声,表示了当车辆转向角与速度变化时车辆运动状态不确定性的增加;上述四种噪声相互独立,且都为均值为0、协方差已知的高斯白噪声;
[0043]
k时刻毫米波雷达的测量方程为:
[0044][0045]
式中,测量噪声v
ρ
、v
θ
分别为均值为0、协方差为δ
ρ2
、δ
θ2
的高斯白噪声;ρ
(k)为k时刻毫米波雷达测量得到的目标的径向距离;θ(k)为k时刻毫米波雷达测量得到的目标的方向角;
[0046]
s42、由于kcf目标跟踪算法中的扩展卡尔曼滤波每次只能跟踪一个目标,所以需要引入数据关联方法使毫米波雷达同时跟踪多个目标;
[0047]
由于数据关联算法中用到的是基于聚类和参考过程之后的质心数据,所以首先计算极坐标系统(即毫米波雷达坐标系)中每个目标(旧质心)与观测值(新质心)之间的距离;从上述距离中找到全局最小的距离,将被追踪目标与以此距离链接的新质心相关联;直到所有未关联的新质心和追踪目标都已关联,输出关联关系;
[0048]
s43、将被关联的质心传递给kcf目标跟踪算法中,以使扩展卡尔曼滤波的更新阶段完成新的状态估计,从而使毫米波雷达实时跟踪多个目标。
[0049]
进一步的,s5步骤的具体处理过程如下:
[0050]
s51、将有雷达点投影的图像序列分两路进入目标检测线程与目标跟踪线程;在目标检测线程中,最终得到目标的检测框;在目标跟踪线程中,将检测框内的目标作为训练样本,对目标跟踪算法中的跟踪框进行初始化;
[0051]
s53、将后续图像样本与训练样本放入目标跟踪算法的核相关滤波器中做相关操作(即通过训练样本训练一个核相关滤波器,在后续图像样本上滑动滤波器得到每一个位置上滤波器的响应值),取滤波器响应峰值max_res与设定阈值比较;若高于或等于设定阈值,认为跟踪目标成功,此时响应值峰值点作为新的跟踪框的位置,继续迭代更新目标跟踪框;若低于设定阈值,则认为跟踪失败,跳至目标跟踪线程。
[0052]
综上,本发明采用上述自动驾驶目标检测与跟踪方法,通过雷达定位信息辅助相机目标检测算法为yolov5算法的输入图像中目标可能存在的位置提供了先验信息和候选权重,同时在yolov5算法中引入senet通道注意力机制模块,使yolov5检测算法可以在运行中对不同重要性的图像通道施加不同的注意力,从而提高yolov5目标检测算法对于道路目标检测的速度与准确性。通过融合yolov5目标检测算法与kcf目标跟踪算法实现相机对于目标的实时跟踪,由于检测算法输出的检测框可以用来初始化kcf目标跟踪算法,提高了相机目标跟踪的整体性。当相机中目标被遮挡或者相机跟踪效果不理想时,跳至由扩展卡尔曼滤波与数据关联相结合的雷达跟踪线程,有效提高了智能汽车对于目标跟踪的稳定性。
附图说明
[0053]
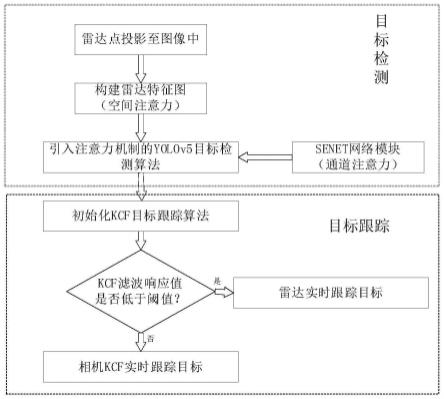
图1为本发明的目标检测与跟踪的整体流程图;
[0054]
图2为本发明中通道-空间注意力机制模块的构建原理图;
[0055]
图3为本发明中改进后的yolov5目标检测算法的模型图;
[0056]
图4为本发明中kcf目标跟踪算法的模型图;
[0057]
图5为本发明中融合yolov5与kcf算法的相机目标跟踪原理图;
[0058]
图6为本发明方法在车辆正常行驶过程中采集到的图像;
[0059]
图7为本发明方法在前车转弯过程中采集到的图像。
具体实施方式
[0060]
以下结合附图和实施例对本发明的技术方案作进一步说明。
[0061]
本发明采用yolov5检测框架,在其中做了一些改进,构建了雷达特征图空间注意力模块提供目标在相机图像中的位置权重矩阵,引入senet通道注意力模块提供图像各通道的权重矩阵,最后,将雷达空间注意力模块和senet通道注意力模块结合,构成目标检测的注意力机制模块,并将该注意力机制模块加入至yolov5检测框架的backbone层与neck层之间,形成具有注意力机制的融合雷达信息的目标检测网络,有效提高了智能汽车目标检测的速度与准确性。
[0062]
本发明采用相机与雷达多线程跟踪框架,在相机跟踪部分,融合yolov5目标检测与kcf目标跟踪算法,充分发挥kcf算法在线训练的优势,直接将yolov5检测算法输出的检测框输入给kcf跟踪算法进行跟踪算法的初始化即可迭代实现对目标的连续跟踪。当雨雾天或目标被遮挡等相机跟踪效果不理想情况下转至雷达跟踪线程实现对目标的跟踪。雷达跟踪部分,将ekf扩展卡尔曼滤波与数据关联方法相结合实现雷达对多个道路目标的同时跟踪。
[0063]
具体地,如图1所示的自动驾驶目标检测与跟踪方法,包括以下步骤:
[0064]
s1、将车载毫米波雷达与相机采集数据进行时间与空间配准,然后通过坐标变换将毫米波雷达点投影至相机图像坐标系中;
[0065]
s2、构建雷达特征图,利用雷达定位能力强的特点,为相机目标检测算法提供空间注意力模块;
[0066]
s3、将senet通道注意力模块以及雷达特征图空间注意力模块引入目标检测算法yolov5的backbone结构中,从而使目标检测算法更关注于目标可能存在的区域,以提高目标检测的速度与精度;
[0067]
s4、构建融合扩展卡尔曼滤波与数据关联算法的kcf目标跟踪算法;
[0068]
s5、在相机未被遮挡情况下,融合目标检测算法与目标跟踪算法对车辆目标追踪;在相机被遮挡情况下,基于目标跟踪算法对车辆目标追踪。
[0069]
其中,在s1步骤中,由于传感器需要在时间上同步,即需要不同传感器采集到同一时间的信息,所以在时间同步问题上应该以频率最低的传感器为时间基准。因为雷达采集频率低,所以以雷达采集数据频率为准。
[0070]
要将毫米波雷达检测的目标转移至相机拍到的图像上,需要完成毫米波雷达坐标系、三维世界坐标系、相机坐标系、图像坐标系和像素坐标系之间的坐标转换关系。首先,应该将毫米波雷达坐标系转换至以相机位为中心的世界坐标系,
[0071][0072]
再将世界坐标系转化为相机坐标系,
[0073][0074]
再将相机坐标系转化为图像坐标系,
[0075][0076]
再将图像坐标系转化为像素坐标系,
[0077][0078]
基于公式(1)-(4),可实现世界坐标系到像素坐标系的转换,即
[0079][0080]
最终,即可得到毫米波雷达到相机的空间转换模型,
[0081][0082]
式中,[x
r y
r z
r 1]
t
为毫米波雷达坐标下目标的坐标,其对应的像素坐标为[x
c y
c z
c 1]
t
;[u v 1]
t
为像素坐标系下目标的坐标;r为3
×
3的单位正交旋转矩阵;t为3
×
1的平移矩阵;i为单位矩阵;d
x
与dy分别表示每个像素在横、纵轴上的物理单位下的大小;f为相机的焦距;k为缩放因子;xr、yr、zr为目标在毫米波坐标系下的三维坐标;u、v为目标在像素坐标系下的二维坐标;zc为相机坐标系下的坐标;u0、v0为在坐标系旋转变换操作之前像素坐标系中的二维坐标。
[0083]
进一步的,在s2步骤中,由于目标检测框架用到的是yolov5检测框架,处理的信息为图像或视频格式,所以要将毫米波雷达信息融入目标检测算法中需要以图像格式表达雷达信息。因此,先将雷达点依靠坐标变换投入图像坐标系中,然后生成一副和图像一样大小的空白单通道图片。将图中所有像素点都设为0,然后以图中雷达点为中心生成一定面积的roi区域,roi面积公式表示为:
[0084]
s=αn+β
ꢀꢀꢀ
(7)
[0085]
式中,n为雷达反射点的个数;α和β为超参数。
[0086]
α和β可以通过最大化roi与目标真实标记框之间的iou进行学习得到,公式为:
[0087][0088]
式中,n为学习超参数过程中输入样本数;mi为第i个样本中物体的标注框个数。
[0089]
iou计算公式为:
[0090][0091]
式中,roi表示雷达点产生的roi;gt表示目标真实标记框;s表示求取面积。
[0092]
确定roi面积后,在生成的roi区域内设置像素点为1,最终得到雷达点生成的roi区域内像素值为1,其他区域像素值为0的雷达特征图。
[0093]
雷达特征图实际上相当于表示目标在图像中位置的权值矩阵,通过让相机图像与雷达特征图相乘,可以帮助目标检测算法抑制掉目标不存在位置处的像素点值,从而让目标检测算法集中在像素值为1即雷达探测到目标可能存在的位置。
[0094]
进一步的,在s3步骤中,senet是不同于上文雷达特征图在空间维度而是在通道维度帮助目标检测算法集中在有效目标上的网络结构。该网络通过对图像中通道关系进行建模来提升网络的性能,其中包含squeeze和excitation两个关键操作,最终显示建模特征通道之间的相互依赖关系。
[0095]
在senet中,squeeze操作顺着空间维度进行特征压缩,将每个二维的特征通道变成一个实数,并将输出的维度和输入的特征通道数相匹配。表征在特征通道上响应的全局分布,并使靠近输入的层也可以获得全局的感受野;excitation操作类似于循环神经网络中门的机制,通过参数为每个特征通道生成权重,其中参数被学习用来显示地建模特征通道间的相关性。最终,将excitation输出的权重看作是经过特征选择后每个特征通道的重要性,然后通过乘法逐通道加权到输入图像的每个通道上。
[0096]
总之,senet即通过学习的方式自动获取图像中每个通道的重要程度,然后依照这个重要程度来提升对当前任务有用的特征并抑制对当前任务用处不大的特征。
[0097]
因此,在以上步骤中,我们构建了表示目标位置权重的雷达特征图,又描述了表示相机图像不同通道权值的senet网络结构,我们将二者结合,形成通道-空间注意力模块,其表示如图2所示。将该通道-空间注意力模块加至yolov5目标检测算法的backbone结构中,即形成基于通道-空间注意力机制的yolov5目标检测算法,该目标检测算法结构如图3所示。
[0098]
进一步的,在s4步骤中,由于毫米波雷达测量原理为多普勒效应,因此毫米波雷达所测数据是在极坐标系下目标的距离、速度和方向角。由于卡尔曼滤波算法仅适用于线性系统,而毫米波雷达在状态更新中涉及极坐标系到笛卡尔坐标的转化这一非线性过程。因此,在这种情况下,不能用卡尔曼滤波来对毫米波雷达进行跟踪。扩展卡尔曼滤波原理与卡尔曼滤波相近,不同之处在于测量矩阵中扩展卡尔曼滤波进行了泰勒级数展开并作了一阶线性化截断处理。因此,我们采用ekf扩展卡尔曼滤波算法对毫米波雷达进行跟踪。
[0099]
由于ekf算法(扩展卡尔曼滤波算法)只能跟踪单个目标,而道路行驶环境中智能汽车可能面临不止一个目标,因此将数据关联方法与扩展卡尔曼滤波相结合,满足毫米波
雷达对多个目标实时跟踪的要求。结合ekf算法与数据关联的毫米波雷达目标跟踪算法原理如图4所示。
[0100]
进一步的,在s5步骤中,在本文目标检测部分采用了相机为主雷达辅助的策略,在目标跟踪部分仍然采用该策略。当遇到极端雨雾等可见度不高以及目标被遮挡等条件下相机跟踪效果不好时转至雷达跟踪。相机跟踪方法融合了yolov5目标检测与kcf目标跟踪算法。
[0101]
yolov5算法的优势在于通过深层卷积网络对目标特征进行提取,并采用fpn+pan的多尺度融合检测策略,可以提高目标检测的准确性与鲁棒性。但是,基于深度学习的检测算法对于训练样本有很高要求,如果当前样本与训练样本差别很大就会出现检测算法检测不到目标的情况,导致例如特斯拉无人车撞上白色卡车这种惨案的发生。在检测算法检测不到目标的情况下就不能持续稳定的跟踪目标。kcf跟踪算法采用在线学习训练策略,不需要预先准备大量样本对模型进行训练。在跟踪过程中基于视频当前帧训练一个滤波器,使用该滤波器确定下一帧目标的位置,然后以新目标位置更新滤波器,如此重复迭代实现目标跟踪。因此,将yolov5目标检测算法检测到的目标检测框输出给kcf跟踪算法即可实现相机对目标的持续跟踪。整个跟踪系统原理如图5所示,检测阶段采集图像如图6所示,跟踪阶段采集图像如图7所示。
[0102]
以上是本发明的具体实施方式,但本发明的保护范围不应局限于此。任何熟悉本领域的技术人员在本发明所揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内,因此本发明的保护范围应以权利要求书所限定的保护范围为准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1