基于SDN的Ceph异构分布式存储系统及其读写优化方法
基于sdn的ceph异构分布式存储系统及其读写优化方法
技术领域
1.本发明涉及分布式存储技术领域,具体涉及一种基于sdn的ceph异构分布式存储系统及其读写优化方法。
背景技术:
2.ceph是一个基于对象的分布式存储系统,其在广泛应用的同时,如何高效地存储和管理海量数据的问题受到了工业界和学术界的关注。经典的ceph云存储系统只将节点的存储容量作为数据选择存储节点的唯一依据,并没有考虑到网络状态、节点的异构性和负载状况,这种节点选择方法影响了系统在网络性能差和异构节点负载不均衡情况下的读写性能,而要在传统的网络构架中获取网络状态和节点负载信息需要繁琐的配置和大量的测量开销。
技术实现要素:
3.本发明所要解决的是ceph分布式云存储系统在网络性能差和异构节点负载不均衡情况下的读写性能问题,提供一种基于sdn的ceph异构分布式存储系统及其读写优化方法。
4.为解决上述问题,本发明是通过以下技术方案实现的:
5.一种基于sdn的ceph异构分布式存储系统的读写优化方法,包括步骤如下:
6.步骤1、ceph存储节点采集自身异构节点信息,并上传给sdn控制器进行整合;sdn控制器将整合后的系统异构节点信息下发给ceph监控节点;ceph监控节点基于节点异构资源分类策略对系统中的对象存储设备进行分类,得到最终的对象存储设备最小分类集;
7.步骤2、ceph监控节点以设定的权重变化步长依次改变最终的对象存储设备最小分类集中的每个对象存储设备及其同类对象存储设备的crush权重值;在此过程中,系统中的各ceph存储节点周期性采集自身的cpu利用率和内存利用率、以及所含各对象存储设备的占有pg比例、读i/o请求数据量和写i/o请求数据量,并上传给sdn控制器;sdn控制器周期性采集系统中的各ceph存储节点的网络消耗带宽;
8.步骤3、sdn控制器利用周期性采样所得到的网络消耗带宽、cpu利用率、内存利用率、占有pg比例、读i/o请求数据量和写i/o请求数据量构建读性能训练数据样本集和写性能训练数据样本集,并下发给ceph监控节点;
9.对于读性能训练数据样本集的一条读性能训练数据样本,其输入参数矩阵为一次周期性采样所得到的所有对象存储设备的网络消耗带宽、cpu利用率、内存利用率、占有pg比例和写i/o请求数据量所构成的矩阵,其输出参数向量为一次周期性采样所得到的所有对象存储设备的读i/o请求数据量所构成的向量;
10.对于写性能训练数据样本集的一条写性能训练数据样本,其输入参数矩阵为一次周期性采样所得到的所有对象存储设备的网络消耗带宽、cpu利用率、内存利用率、占有pg比例和读i/o请求数据量所构成的矩阵,其输出参数向量为一次周期性采样所得到的所有
对象存储设备的写i/o请求数据量所构成的向量;
11.步骤4、ceph监控节点利用读性能训练数据样本集和写性能训练数据样本集分别对随机森林模型进行训练,并分别基于训练好的随机森林模型对读性能训练数据样本和写性能训练数据样本的输入参数矩阵中的各参数的重要性进行分析,得到读影响权重向量和写影响权重向量;
12.步骤5、当用户需要进行读和/或写优化时:
13.在读优化过程中,ceph存储节点采集当前时刻下系统中的各个对象存储设备的cpu利用率、内存利用率、占有pg比例和写i/o请求数据量,并上传给sdn控制器;sdn控制器采集当前时刻下系统中的各个对象存储设备的网络剩余带宽,并将网络剩余带宽、cpu利用率、内存利用率、占有pg比例和写i/o请求数据量整合为当前时刻的读负载信息下发给ceph监控节点;ceph监控节点先对当前时刻的读负载信息进行归一化处理后构建读决策矩阵,再将读决策矩阵和读影响权重向量送入到多属性决策topsis模型中得到读贴合度向量,后基于该读贴合度向量,将读贴合度低的对象存储设备中的读数据量转到读贴合度高的对象存储设备中执行;
14.在写优化过程中,ceph存储节点采集当前时刻下系统中的各个对象存储设备的cpu利用率、内存利用率、占有pg比例和读i/o请求数据量,并上传给sdn控制器;sdn控制器采集当前时刻下系统中的各个对象存储设备的网络剩余带宽,并将网络剩余带宽、cpu利用率、内存利用率、占有pg比例和读i/o请求数据量整合为当前时刻的写负载信息下发给ceph监控节点;ceph监控节点先对当前时刻的写负载信息进行归一化处理后构建读决策矩阵,再将读决策矩阵和读影响权重向量送入到多属性决策topsis模型中得到读贴合度向量,后基于该读贴合度向量,将读贴合度低的对象存储设备中的读数据量转到读贴合度高的对象存储设备中执行。
15.上述步骤1中节点异构资源分类策略的具体过程如下:
16.步骤1.1、基于系统中的每一个对象存储设备的异构性能,构建该对象存储设备osdj的异构性能集αj={e1,e2,...,ei};其中ei表示第i个异构性能影响因子,1≤i≤i,i表示异构性能影响因子的个数;
17.步骤1.2、先令初始的对象存储设备最简性能集β={α1},并令初始的对象存储设备最小分类集δ={};再从第2个对象存储设备开始遍历剩余的对象存储设备αj′
的异构性能集αj′
,其中2≤j
′
≤j:若当前对象存储设备最简性能集与对象存储设备osdj′
的异构性能集αj′
的并集不等于当前对象存储设备最简性能集,则将对象存储设备osdj′
的异构性能集αj′
合并至当前对象存储设备最简性能集中,并将对象存储设备osdj′
合并至当前对象存储设备最小分类集中;否则,当前对象存储设备最简性能集和当前对象存储设备最小分类集不变;遍历完成后得到最终的对象存储设备最小分类集。
18.上述异构性能影响因子包括节点带宽上限、cpu大小、内存大小和对象存储设备类型。
19.上述步骤2的具体过程如下:
20.步骤2.1、令系统中的每一个对象存储设备的crush权重值均为1;
21.系统中的各ceph存储节点以设定的时间间隔t和采集次数n,周期性采集自身的cpu利用率和内存利用率、以及所含各对象存储设备的占有pg比例、读i/o请求数据量和写
i/o请求数据量,并上传给sdn控制器;与此同时,sdn控制器以设定的时间间隔t和采集次数n,周期性采集系统中各ceph存储节点的网络消耗带宽;
22.n次采样完成后,sdn控制器得到n次采集过程中的集群读性能的平均值和集群写性能平均值
23.步骤2.2、循环选中最终的对象存储设备最小分类集中的每个对象存储设备;
24.步骤2.3、令当前选中的对象存储设备及其同类对象存储设备的crush权重值为1+is,其余对象存储设备的crush权重值为1;其中i为步长增加次数,i=1,2,
…
;s为设定的权重变化步长;
25.系统中的各ceph存储节点以设定的时间间隔t和采集次数n,周期性采集自身的cpu利用率和内存利用率、以及所含各对象存储设备的占有pg比例、读i/o请求数据量和写i/o请求数据量,并上传给sdn控制器;与此同时,sdn控制器以设定的时间间隔t和采集次数n,周期性采集系统中各ceph存储节点的网络消耗带宽;
26.n次采样完成后,sdn控制器得到n次采集过程中的集群读性能的平均值和集群写性能平均值
27.步骤2.4、sdn控制器判断本次集群读性能的平均值是否大于上次集群读性能的平均值且本次集群写性能的平均值是否大于上次集群写性能的平均值
28.如果同时满足,即且则转至步骤2.2;
29.否则,令i=i+1,并返回步骤2.3。
30.上述步骤5中,在读决策矩阵中,网络剩余带宽和占有pg比例为正值,cpu利用率、内存利用率和写i/o请求数据量为负值;在写决策矩阵中,网络剩余带宽和占有pg比例为正值,cpu利用率、内存利用率和读i/o请求数据量为负值。
31.实现上述读写优化方法的基于sdn的ceph异构分布式存储系统,由ceph节点、openflow交换机和sdn控制器组成。ceph节点位于系统架构的底层;ceph节点包括至少一个ceph存储节点和至少一个ceph监控节点,ceph存储节点与ceph监控节点相互之间实现拓扑连接;每个ceph存储节点中包含至少一个对象存储设备;ceph监控节点维护集群所有ceph节点的全局配置信息。openflow交换机位于系统架构的中间层;openflow交换机连接sdn控制器和ceph节点,负责数据之间的传送。sdn控制器位于系统架构的顶层;sdn控制器监测需要的对象存储设备信息,ceph监控节点远程调用sdn控制器收集到的信息,为选择ceph存储节点上的对象存储设备做出决策参考。
32.与现有技术相比,本发明首先设计了一个基于sdn(software defined network,软件定义网络)技术的云存储系统模型;然后基于节点异构资源分类策略将osd(object storage device,对象存储设备)进行分类;随后利用sdn技术实时获取网络和负载情况,并建立基于随机森林获得性能影响因子的影响权重;最后结合osd状态和影响权重,利用多属性决策topsis模型计算osd的读写贴合度,进而自适应地优化集群读写性能。这样做既考虑了集群节点网络状态,又考虑了节点上osd的负载均衡,其可以自适应地将读写负载集中在
不同性能类型的osd上,并保证异构osd设备的负载均衡,从而增加了集群的可靠性。
附图说明
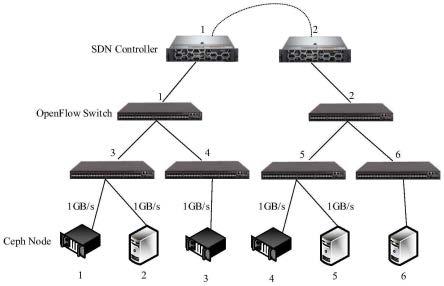
33.图1为基于sdn的ceph异构分布式存储系统架构。
具体实施方式
34.为使本发明的目的、技术方案和优点更加清楚明白,以下结合具体实例,对本发明进一步详细说明。
35.软件定义网络作为一种新的网络模式,主要思想是控制平面和数据平面相分离,打破封闭的垂直体系,并引入对网络编程的能力,通过全局的视角增强对整体系统的管控,显著提升了大规模集群存储中数据的传输、控制和管理效率。由于在传统的网络架构中获取分布式存储系统监控节点和存储节点的网络状态和负载信息需要繁琐的配置和大量的测量开销,因此如果将基于sdn(software defined network,软件定义网络)的网络测量技术运用到分布式存储系统的网络状态信息测量中,可以用更小的硬件配置和测量开销获取存储节点的消耗带宽和剩余带宽,并且可以方便地与底层存储节点通过udp数据包进行信息交互,这样的网络模型方便我们监控系统全局的网络状况和负载信息,从而达到利用这些信息优化ceph云存储系统的读写性能的目的。为此,本发明设计了如图1所示基于sdn的ceph异构分布式存储系统,由ceph节点、openflow交换机和sdn控制器组成。
36.系统架构的底层为2个以上拓扑连接的ceph节点。ceph节点包括至少一个ceph存储节点和至少一个ceph监控节点,ceph存储节点与ceph监控节点相互之间实现拓扑连接。每个ceph存储节点可以包含至少一个osd(object storage device,对象存储设备)。ceph监控节点维护集群所有节点的全局配置信息。在图1所示的实例中,ceph节点1、3和4既是ceph存储节点,又是ceph监控节点,ceph节点2、5和6仅是ceph存储节点。
37.系统架构的中间层为至少一个openflow交换机。当openflow交换机为2个以上时,这些openflow交换机相互之间实现拓扑连接。openflow交换机向上连接sdn控制器,向下连接ceph节点,负责数据之间的传送。
38.系统架构的顶层为至少一个sdn控制器。当sdn控制器为2个以上时,这些sdn控制器相互之间实现拓扑连接。sdn控制器利用负载均衡监测模块监测需要的osd信息,ceph监控节点远程调用sdn控制器收集到的信息,为选择ceph存储节点上的osd做出决策参考。这种系统架构利用控制平面和数据平面相分离的网络模式方便我们对底层网络和负载情况进行监测。
39.基于上述系统,本发明所提出的一种基于sdn的ceph异构分布式存储系统的读写优化方法,其包括步骤如下:
40.(1)读写优化准备阶段:
41.步骤1、首先系统底层ceph存储节点采集自身异构节点信息,并上传给sdn控制器进行整合。然后sdn控制器将整合后的系统异构节点信息下发给ceph监控节点。最后ceph监控节点基于节点异构资源分类策略对系统中的对象存储设备进行分类,得到最终的对象存储设备最小分类集。
42.上述节点异构资源分类策略具体过程如下:
43.步骤1.1、基于系统中的每一个对象存储设备的异构性能,构建该对象存储设备osdj的异构性能集αj={e1,e2,...,ei};其中ei表示第i个异构性能影响因子,1≤i≤i,i表示异构性能影响因子的个数。异构性能影响因子的个数根据性能需求选取,在本实施例中,异构性能影响因子包括带宽上限(gb/s)、cpu和内存大小、以及osd类型(hdd类型或ssd类型)。由此得到系统中所有对象存储设备的异构性能集α={α1,α2,...,αj},1≤j≤j,j表示基于sdn的ceph异构分布式存储系统中osd的总数。
44.步骤1.2、先令初始的对象存储设备最简性能集β={α1},并令初始的对象存储设备最小分类集δ={};再从第2个对象存储设备开始遍历剩余的对象存储设备αj′
的异构性能集αj′
,其中2≤j
′
≤j:若当前对象存储设备最简性能集与对象存储设备osdj′
的异构性能集αj′
的并集不等于当前对象存储设备最简性能集,即β∪αj′
≠β,则将对象存储设备osdj′
的异构性能集αj′
合并至当前对象存储设备最简性能集中,即β=β∪αj′
,并将对象存储设备osdj′
合并至当前对象存储设备最小分类集中,即δ=δ∪osdj′
;否则,当前对象存储设备最简性能集β和当前对象存储设备最小分类集δ不变。遍历完成后,得到最终的对象存储设备最简性能集β={α1,α2,...,α
l
}和最终的对象存储设备最小分类集δ={osd1,osd2,...,osd
l
},其中l≤j,osd
l
是osd异构性能集α
l
对应的osd的编号。
45.ceph社区在设计之初,并没有考虑到节点异构的混合存储环境中如何充分挖掘异构存储节点的性能问题,需要领域专家手工编辑将系统中异构资源分类,从而适应不同的存储性能需求,费时费力。然而,基于本发明提出的异构资源分类策略可以自动化地将系统中的osd进行分类,得到不同性能类别的osd,即得到最简性能集和最小分类集,就能减少人工编辑的成本。此外,这样后续只需要对最小分类集中的osd进行网络状况和负载的采集,而不需要对系统中所有的osd进行网络状况和负载的采集,就能减少对osd负载监测的开销。最后,通过将云存储系统的存储资源池进行了细粒度的划分,保证了每种资源池中osd的读写性能几乎一致,这样做的好处是可以按性能需求将指定的存储池分配给相应的客户端,从而减少异构系统中的资源浪费。
46.步骤2、ceph监控节点以设定的权重变化步长依次改变最终的对象存储设备最小分类集中的每个对象存储设备及其同类对象存储设备的crush权重值;在此过程中,系统中的各ceph存储节点周期性采集自身的cpu利用率和内存利用率、以及所含各对象存储设备的占有pg比例、读i/o请求数据量和写i/o请求数据量,并上传给sdn控制器;sdn控制器周期性采集系统中的各ceph存储节点的网络消耗带宽。
47.步骤2.1、令系统中的每一个对象存储设备的crush权重值均为1。
48.系统中的各ceph存储节点以设定的时间间隔t和采集次数n,周期性采集自身的cpu利用率和内存利用率、以及所含各对象存储设备的占有pg比例、读i/o请求数据量和写i/o请求数据量,并上传给sdn控制器。与此同时,sdn控制器以设定的时间间隔t和采集次数n,周期性采集系统中各ceph存储节点的网络消耗带宽。
49.n次采样完成后,sdn控制器得到n次采集过程中的集群读性能的平均值和集群写性能平均值
50.步骤2.2、循环选中最终的对象存储设备最小分类集中的每个对象存储设备;
51.步骤2.3、令当前选中的对象存储设备及其同类对象存储设备的crush权重值为1+
is,其余对象存储设备的crush权重值为1。其中i为步长增加次数,i=1,2,
…
;s为设定的权重变化步长,在本发明中,n的取值范围为[1,10]。
[0052]
系统中的各ceph存储节点以设定的时间间隔t和采集次数n,周期性采集自身的cpu利用率和内存利用率、以及所含各对象存储设备的占有pg比例、读i/o请求数据量和写i/o请求数据量,并上传给sdn控制器。与此同时,sdn控制器以设定的时间间隔t和采集次数n,周期性采集系统中各ceph存储节点的网络消耗带宽。
[0053]
n次采样完成后,sdn控制器得到n次采集过程中的集群读性能的平均值和集群写性能平均值
[0054]
步骤2.4、sdn控制器判断本次集群读性能的平均值是否大于上次集群读性能的平均值且本次集群写性能的平均值是否大于上次集群写性能的平均值
[0055]
如果同时满足,即且则表明继续增加当前选中的对象存储设备及其同类对象存储设备的crush权重值时集群的读写性能将不再增加,转至步骤2.2,选中最终的对象存储设备最小分类集中的下一个对象存储设备,直到遍历完最终的对象存储设备最小分类集中的每个对象存储设备;
[0056]
否则,令i=i+1,并返回步骤2.3,直到当前选中的对象存储设备及其同类对象存储设备的集群的读写性能将不再增加。
[0057]
ceph云存储系统利用crush算法(controlled replication under scalable hashing,一种基于哈希的伪随机数据分布算法)计算数据存储的位置。osd原始的crush权重值仅仅与其磁盘容量正相关换算而来,pg(placement group,一组数据对象的集合)按照osd的crush权重值分布在osd上,即osd的crush权重值越大,则其上分布的pg数量越多。
[0058]
集群读性能的平均值和集群写性能的平均值通过一种主流的基准测试工具fio(版本3.7)获取。ceph监控节点首先利用内置命令将云存储空间映射出一块磁盘挂载在ceph存储节点上;然后在设定的测试时间段内,ceph存储节点利用fio工具持续测试映射出的磁盘的读写性能并得到平均值,即为集群的读写性能的平均值;最后ceph存储节点将集群读写性能信息上传给sdn控制器,sdn控制器再将集群读写性能的变化作为选中的osd信息采集的终止判断条件。
[0059]
步骤3、sdn控制器利用周期性采样所得到的网络消耗带宽、cpu利用率、内存利用率、占有pg比例、读i/o请求数据量和写i/o请求数据量构建读性能训练数据样本集和写性能训练数据样本集,并下发给ceph监控节点。
[0060]
网络消耗带宽、cpu利用率和内存利用率属于ceph存储节点的负载信息,每个对象存储设备的网络消耗带宽、cpu利用率和内存利用率即为该对象存储设备所属ceph存储节点的网络消耗带宽、cpu利用率和内存利用率。占有pg比例、读i/o请求数据量和写i/o请求数据量属于对象存储设备的负载信息。sdn控制器将每一次周期性采样所得到的所有对象存储设备的消耗带宽bw、cpu利用率cpu、内存利用率mem、占有pg比例pgs和写i/o请求数据量w_io所构成的矩阵作为读性能训练数据样本集中一条读性能训练数据样本的输入参数矩阵,对应地将每一次周期性采样所得到的所有对象存储设备的读i/o请求数据量r_io所
构成的向量作为读性能训练数据样本集中一条读性能训练数据样本的输出参数向量。其中读性能训练数据样本集sr为:
[0061]
sr={{consume
r1
,r_io
r1
};{consume
r2
,r_io
r2
};...;{consume
rp
,r_io
rp
}}
[0062]
consume
rp
={bw
rp
,cpu
rp
,mem
rp
,pgs
rp
,w_io
rp
},p∈[1,pr]
[0063]
sdn控制器将每一次周期性采样所得到的所有对象存储设备的消耗带宽bw、cpu利用率cpu、内存利用率mem、占有pg比例pgs和读i/o请求数据量r_io所构成的矩阵作为写性能训练数据样本集中一条写性能训练数据样本的输入参数矩阵,对应地将每一次周期性采样所得到的所有对象存储设备的写i/o请求数据量w_io所构成的向量作为写性能训练数据样本集中一条写性能训练数据样本的输出参数向量。其中写性能训练数据样本集sw为:
[0064]
sw={{consume
w1
,w_io
w1
};{consume
w2
,w_io
w2
};...;{consume
wp
,w_io
wp
}}
[0065]
consume
wp
={bw
wp
,cpu
wp
,mem
wp
,pgs
wp
,r_io
wp
},p∈[1,pw]
[0066]
由于本发明采集osd负载信息是以建立osd性能预测模型获取性能因子的影响权重为目的,所以系统以osd资源消耗集consume
rp
和consume
wp
建立性能预测模型,并用osd资源剩余集优化优化决策,这样做有两个好处:ⅰ.将多个客户端对同一个osd的资源消耗归一化成总的资源消耗,比如读写请求数据量归一化成总读请求数据量和总写请求数据量,单位为kb/s,这种方法获取的性能因子影响权重具有更好的自适应性,屏蔽了不同数量的客户端资源消耗带来的性能预测模型的差异;ⅱ.用osd资源剩余集做决策更有利于集群的负载均衡。
[0067]
步骤4、ceph监控节点利用读性能训练数据样本集和写性能训练数据样本集分别对随机森林模型进行训练,并分别基于训练好的随机森林模型对读性能训练数据样本和写性能训练数据样本的输入参数矩阵中的各参数的重要性进行分析,得到读影响权重向量和写影响权重向量。
[0068]
利用读性能训练数据样本集对随机森林模型进行训练,并利用此时训练好的随机森林模型(基于读的osd预测模型)对读性能训练数据样本的输入参数矩阵中的各参数,即消耗带宽、cpu利用率、内存利用率、占有pg比例和写i/o请求数据量的重要性进行分析,得到消耗带宽、cpu利用率、内存利用率、占有pg比例和写i/o请求数据量的影响权重所组成的读影响权重向量。
[0069]
利用写性能训练数据样本集对随机森林模型进行训练,并利用此时训练好的随机森林模型(基于写的osd预测模型)对写性能训练数据样本的输入参数矩阵中的各参数,即消耗带宽、cpu利用率、内存利用率、占有pg比例和读i/o请求数据量的重要性进行分析,得到消耗带宽、cpu利用率、内存利用率、占有pg比例和读i/o请求数据量的影响权重所组成的写影响权重向量。
[0070]
根据随机森林预测模型训练得到的osd预测模型rf_reg,可以利用随机森林模型的内置函数rf_reg.feature_importances_对其模型输入数据中的各项osd性能影响因子参数的重要性进行特征重要性分析,继而得到各个性能因子的影响权重。对于读影响权重向量wr由剩余带宽的影响权重w
br
、cpu利用率的影响权重w
cr
、内存利用率的影响权重w
mr
、占有pg比例的影响权重w
pr
和写i/o请求数据量的影响权重w
lr
所组成,即wr=[w
brwcrwmrwprwlr
]。对于写影响权重向量ww由剩余带宽的影响权重w
bw
、cpu利用率的影响权重w
cw
、内存利用率的影响权重w
mw
、占有pg比例的影响权重w
pw
和写i/o请求数据量的影响权重w
lw
所组成,即ww=
[w
bwwcwwmwwpwwlw
]。
[0071]
本发明首先将osd的资源消耗集分为读性能训练集和写性能训练集,方便分析系统读性能因子和写性能因子非线性的影响权重关系,从而做出适当的系统读和写优化决策目标。当优化系统读性能时,osd消耗的不同资源影响权重是不同的,比如hdd类型的osd执行读操作时,消耗的带宽资源较大,大约是ssd类型的osd的3倍。当优化系统写性能时,osd消耗的不同资源影响权重也是不同的,比如ssd类型的osd执行写操作时,消耗的带宽资源较大,大约是hdd类型的osd的2倍。这样的权重关系有益于在实际的生产环境中定向定量的增加特定类型对象存储设备的资源,增加集群的可靠性。
[0072]
(2)实际读和/或写优化阶段:
[0073]
步骤5、当用户需要进行读和/或写优化时,向ceph监控节点发送读和/或写优化指令,ceph监控节点基于优化指令触发ceph存储节点和sdn控制器采集采集负载信息。比如当用户对系统读性能时延敏感时,需要进行读优化,当用户对系统写性能时延敏感时,需要进行写优化。读优化和写优化可以分开进行,也可以同时进行,其可以通过指针flag来实现:比如flag为0,优化读;flag为1,优化写;flag为2,优化读写同时。
[0074]
在读优化过程中,ceph存储节点采集当前时刻下系统中的各个对象存储设备的cpu利用率、内存利用率、占有pg比例和写i/o请求数据量,并上传给sdn控制器;sdn控制器采集当前时刻下系统中的各个对象存储设备的网络剩余带宽br,并将网络剩余带宽信息br、cpu利用率cr、内存利用率mr、占有pg比例pr和写i/o请求数据量lr整合为当前时刻的读负载信息下发给ceph监控节点;ceph监控节点先对当前时刻的读负载信息进行归一化处理后构建读决策矩阵xr,再将读决策矩阵和读影响权重向量送入到多属性决策topsis模型中得到读贴合度向量,后基于该读贴合度向量,将读贴合度低的对象存储设备中的读数据量转到读贴合度高的对象存储设备中执行;
[0075]
读决策矩阵xr为:
[0076][0077]
读影响权重向量wr为:
[0078]
wr=[w
brwcrwmrwprwlr
]
[0079]
本发明在步骤2收集对象存储设备的消耗带宽作为影响其性能的训练参数,而在读优化决策时却利用对象存储设备剩余带宽作为读决策矩阵xr的输入参数。这是因为在获取对象存储设备读请求的带宽性能因子的影响权重时,随机森林模型需要输入实际消耗的带宽资源作为训练集输出相应的性能因子影响权重,然后利用对象存储设备的剩余带宽资源和带宽性能因子影响权重做出读优化决策。
[0080]
读加权决策矩阵zr为:
[0081]
zr=wr×
xr[0082]
读加权决策矩阵的正理想解z
r+
为:
[0083]zr+
=max{z
r_ij
|i=1,2,...,n;j=1,2,...,5}
[0084]
读加权决策矩阵的正理想解z
r-为:
[0085]zr+
=min{z
r_ij
|i=1,2,...,n;j=1,2,...,5}
[0086]
每个对象存储设备到读正理想解的距离为:
[0087][0088]
每个对象存储设备到读负理想解的距离为:
[0089][0090]
每个对象存储设备的读贴近度为:
[0091][0092]
其中n为系统中对象存储设备的个数。
[0093]
在写优化过程中,ceph存储节点采集当前时刻下系统中的各个对象存储设备的cpu利用率、内存利用率cr、占有pg比例和读i/o请求数据量,并上传给sdn控制器;sdn控制器采集当前时刻下系统中的各个对象存储设备的网络剩余带宽br,并将网络剩余带宽br、cpu利用率cr、内存利用率mr、占有pg比例pr和读i/o请求数据量lw整合为当前时刻的写负载信息下发给ceph监控节点;ceph监控节点先对当前时刻的写负载信息进行归一化处理后构建读决策矩阵xw,再将读决策矩阵和读影响权重向量送入到多属性决策topsis模型中得到读贴合度向量,后基于该读贴合度向量,将读贴合度低的对象存储设备中的读数据量转到读贴合度高的对象存储设备中执行。
[0094]
写决策矩阵xw为:
[0095][0096]
写影响权重向量ww为:
[0097]ww
=[w
bwwcwwmwwpwwlw
]
[0098]
本发明在步骤2收集对象存储设备的消耗带宽作为影响其性能的训练参数,而在写优化决策时却利用对象存储设备剩余带宽作为写决策矩阵xw的输入参数。这是因为在获取对象存储设备写请求的带宽性能因子的影响权重时,随机森林模型需要输入实际消耗的带宽资源作为训练集输出相应的性能因子影响权重,然后利用对象存储设备的剩余带宽资源和带宽性能因子影响权重做出写优化决策。
[0099]
写加权决策矩阵zw为:
[0100]zw
=ww×
xw[0101]
写加权决策矩阵的正理想解z
w+
为:
[0102]zw+
=max{z
w_ij
|i=1,2,...,n;j=1,2,...,5}
[0103]
写加权决策矩阵的正理想解z
r-为:
[0104]zw+
=min{z
w_ij
|i=1,2,...,n;j=1,2,...,5}
[0105]
每个对象存储设备到写正理想解的距离为:
[0106][0107]
每个对象存储设备到写负理想解的距离为:
[0108][0109]
每个对象存储设备的写贴近度c
w_i+
为:
[0110][0111]
其中n为系统中对象存储设备的个数。
[0112]
topsis模型中加入了性能影响因子的预测影响权重,负责为正在提供服务的osd打分,然后选出一个或一组osd优化ceph集群的读写性能,这样做可以更好地避免局部优化“热点”瓶颈问题,考虑的是集群全局的负载均衡,包括同种性能类型和不同性能类型的对象存储设备的负载均衡,增加了系统的可靠性。这样在系统原有的osd选择算法的基础上考虑了对象存储设备网络性能和负载的5个指标,以此作为osd权重因子的约束条件,然后通过建立和求解多属性决策模型就可以确定一个或一组osd的选择。更进一步,当系统根据实时的网络和负载状态将对象存储设备打分后,用户可以根据实际需求定时定量的选择优化对象存储设备的范围,并决定执行哪种性能优化,使得整个优化决策过程可控性更强。
[0113]
贴合度(读贴近度和写贴近度)的大小本身表达了转移负载(读负载和写负载)的比例,读贴近度和写贴近度的值都为[0,1]。贴合度的值越大,表明osd的负载越小,系统可以将更多的负载集中在贴合度值大的osd上优化系统的读和写性能;贴合度的值越小,表明osd的负载越大,系统可以减少集中在贴合度值小的osd上的负载优化系统的读和写性能。基于贴合度,读数据量和写数据量的转移量的多少由osd实时网络和负载状态决定,即osd的性能越差,则osd的读数据量和写数据量要相应的减少;osd的性能越好,则可以考虑增加osd的读数据量和写数据量。
[0114]
需要说明的是,尽管以上本发明所述的实施例是说明性的,但这并非是对本发明的限制,因此本发明并不局限于上述具体实施方式中。在不脱离本发明原理的情况下,凡是本领域技术人员在本发明的启示下获得的其它实施方式,均视为在本发明的保护之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1