一种深度聚类的方法、装置及系统与流程
本技术涉及人工智能(artificial intelligence,ai)领域,尤其涉及一种深度聚类的方法、装置及系统。
背景技术:
1、人工智能(artificial intelligence,ai)是利用数字计算机或者数字计算机控制的机器模拟、延伸和扩展人的智能,感知环境、获取知识并使用知识获得最佳结果的理论、方法、技术及应用系统。换句话说,人工智能是计算机科学的一个分支,它企图了解智能的实质,并生产出一种新的能以人类智能相似的方式作出反应的智能机器。人工智能也就是研究各种智能机器的设计原理与实现方法,使机器具有感知、推理与决策的功能。人工智能领域的研究包括机器人,自然语言处理,计算机视觉,决策与推理,人机交互,推荐与搜索,ai 基础理论等。
2、机器学习是实现人工智能的一种方法,该方法的目标是设计和分析一些让计算机可以自动“学习”的算法,也即是模型,所设计的算法称为机器学习模型。机器学习模型是一类从数据中自动分析获得规律,并利用规律对未知数据进行预测的算法。机器学习模型包括多种多样,根据模型训练时是否需要依赖训练数据对应的标签,机器学习模型可以分为:1、有监督学习模型;2、无监督学习模型。
3、聚类算法是机器学习中的一种无监督学习模型,广泛应用于数据挖掘,模式识别等数据科学领域。传统的聚类算法在复杂的高维数据上效果往往不够好。随着深度学习,特别是无监督学习的发展,基于深度神经网络的聚类算法在高维数据上取得了比传统聚类算法更好的效果。
4、现有的深度聚类算法以参数化聚类算法为主,即聚类前需要提前指定聚类类别的数量。然而在现实中,对于某类需要聚类的数据,其具体的分类的数量往往是无法提前预知的,从而导致参数化聚类算法在实际中无法应用。由于现有深度聚类算法在聚类时需要预先指定分类的数量来构建固定网络结构,导致算法灵活性低,实用性差。
技术实现思路
1、本技术实施例提供的一种深度聚类的方法、装置及系统,在聚类时不需要预先指定分类的数量,能够动态优化网络结构,算法灵活性高,实用性强。
2、第一方面,本技术实施例提供一种深度聚类的方法,包括:第一深度聚类模型的输出层包括一个或多个第一神经元,一个或多个第一神经元用于输出原始数据的一个或多个第一分类,方法包括:获得一个或多个第一神经元输出的一个或多个第一分类;在第一目标分类对应的至少两个数据之间的相似性满足拆分条件的情况下,将第一深度聚类模型输出层的目标神经元进行拆分,得到第二深度聚类模型;第一目标分类为一个或多个第一分类中的至少一个,第一目标分类对应的数据包括多个数据,目标神经元为一个或多个第一神经元中输出第一目标分类的第一神经元,第二深度聚类模型的输出层包括多个第二神经元,第二神经元用于输出第二分类。以此,可以在不知道具体数据分类的数量的前提下,基于类内数据的相似性度量,进行神经元拆分,让深度神经网络自动动态调整神经元个数,更新深度聚类模型输出层的维度,从而自动推断聚类的分类的数量,完成聚类。该方法可适配各种参数化的深度聚类算法,取得非参数化聚类的最优结果,最优结果满足同一类别的数据相似、不同类别的数据不相似的要求。
3、在一些可以实现的实施方式中,第一神经元输出的一个或多个第一分类的数量为预先设定。以此,可以在不知道具体数据分类的数量的前提下,基于参数化的深度聚类模型获得原始数据对应的一个或多个第一分类,该一个或多个第一分类并不是最优聚类结果。
4、在一些可以实现的实施方式中,原始数据包括图片数据、文本数据、语音数据、医学影像或视频数据。以此采用本技术实施例提供的一种深度聚类的方法得到的深度聚类模型可以应用于自动驾驶设备、终端设备等人工智能装备中,完成模式识别,数据挖掘等实际任务。
5、在一些可以实现的实施方式中,通过以下步骤获得第一目标分类对应的至少两个数据之间的相似性:确定第一目标分类对应的至少两个数据的概率分布;根据第一目标分类对应的至少两个数据的概率分布的相似性获得第一目标分类对应的至少两个数据之间的相似性。以此,可以获得两个不同类别的数据之间的相似性度量。
6、在一些可以实现的实施方式中,拆分条件包括:第一js散度大于拆分的阈值,第一js散度用于指示第一目标分类对应的至少两个数据之间的相似性。以此可以将第一深度聚类模型输出层的目标神经元进行一次或多次拆分,得到多个第二神经元,通过同一类别内的两个数据之间的js散度判断拆分条件,在满足拆分条件下进行神经元的拆分,使得深度神经网络可以自动动态调整神经元个数,优化深度聚类模型的结构,有效解决深度聚类模型不够灵活的问题。
7、在一些可以实现的实施方式中,所述拆分的阈值为ts:
8、
9、其中,k1和k2为多个第一分类中与目标分类不同的两个第一分类,js(k1||k2)为k1和k2两个类别之间的js散度值;λ为平衡参数,k为第一分类的数量。以此,可以自动计算类内数据间的js散度和拆分的阈值,进一步限定拆分条件为同类别内的两个数据之间的js散度大于拆分的阈值,从而在不影响原有算法性能的条件下,准确对数据真实分类的数量进行估计。
10、在一些可以实现的实施方式中,第二深度聚类模型的多个第二神经元输出多个第二分类,第二分类的数量为第二神经元的数量。以此可以根据拆分后神经元的数目自动推断出拆分后的分类的数量,从而在不影响原有算法性能的条件下,准确对数据真实分类的数量进行估计。
11、在一些可以实现的实施方式中,第二深度聚类模型输出层的多个第二神经元的每个权重均为所述目标神经元的权重与多个高斯噪声的叠加值。以此,可以确定拆分后的深度聚类模型的神经元权重,进一步优化深度聚类模型,有效解决深度聚类模型不够灵活的问题。
12、在一些可以实现的实施方式中,方法包括训练第二深度聚类模型:以原始数据和第二分类的数量为第二深度聚类模型的输入;以第一损失函数收敛为目标训练第二深度聚类模型,优化更新所述第二深度聚类模型输出层的多个第二神经元的多个权重,获得训练好的第二深度聚类模型。以此,可以使得神经元拆分后的深度神经网络在训练过程中自动动态调整神经元的权重,优化深度聚类模型的输出,有效解决深度聚类模型不够灵活和准确的问题。
13、在一些可以实现的实施方式中,根据训练后的所述第二深度聚类模型确定原始数据的多个第二分类。以此,可以有效解决深度聚类模型输出的分类结果不够准确的问题。
14、在一些可以实现的实施方式中,在第一目标分类对应的至少两个数据之间的相似性无法满足拆分条件的情况下,方法还包括:在第一目标分类对应的数据与第二目标分类对应的数据的相似性满足聚合条件的情况下,将第一深度聚类模型的输出层的多个目标神经元进行聚合,得到第三深度聚类模型;第二目标分类为所述一个或多个第一分类中的至少一个,多个目标神经元为一个或多个第一神经元中输出第一目标分类和第二目标分类的多个第一神经元;第三深度聚类模型的输出层包括一个或多个第三神经元,一个或多个第三神经元为多个目标神经元聚合后得到的神经元,第三神经元用于输出第三分类。以此可以在不知道具体数据分类的数量的前提下,基于类别之间数据的相似性度量,进行神经元聚合,让深度神经网络自动动态调整神经元个数,更新深度聚类模型输出层的维度,从而自动推断聚类的分类的数量,完成聚类。
15、在一些可以实现的实施方式中,聚合条件包括:包括:第二js散度小于聚合的阈值,第二js散度用于指示第一目标分类对应的数据与第二目标分类对应的数据之间的相似性。以此,可以将第一深度聚类模型输出层的多个目标神经元进行一次或多次聚合,得到一个或多个第三神经元;根据不同类别的数据之间的js散度决定进行神经元聚合,使得深度神经网络自动动态调整神经元个数,优化深度聚类模型的结构,有效解决深度聚类模型不够灵活的问题。
16、在一些可以实现的实施方式中,聚合的阈值为tm:
17、
18、聚合条件为:js(k-1||k)<tm;其中,js(k-1||k)为所述多个目标分类中的第k类数据和第k-1类数据之间的js散度。以此,可以自动计算类间数据的js散度和聚合的阈值ts,从而在不影响原有算法性能的条件下,准确对数据真实分类的数量进行估计。
19、在一些可以实现的实施方式中,第三深度聚类模型的一个或多个第三神经元输出一个或多个第三分类,第三分类的数量为所述第三神经元的数量。以此可以自动推断出聚合后的分类的数量,从而在不影响原有算法性能的条件下,准确对数据真实分类的数量进行估计。
20、在一些可以实现的实施方式中,所述第三深度聚类模型的一个或多个第三神经元的一个或多个权重为所述第一深度聚类模型的多个目标神经元的权重的平均值。以此,可以进行神经元权重的聚合,使得深度神经网络在聚合过程中自动动态调整神经元的权重,进一步优化深度聚类模型,有效解决深度聚类模型不够灵活的问题。
21、在一些可以实现的实施方式中,方法包括训练所述第三深度聚类模型:以所述原始数据和第三分类的数量为所述第二深度聚类模型的输入;以第二损失函数收敛为目标训练所述第三深度聚类模型,优化更新所述第三深度聚类模型输出层的多个第三神经元的多个权重,训练所述第三深度聚类模型,获得训练好的所述第三深度聚类模型。以此,使得聚合后的深度神经网络在训练过程中自动动态调整神经元的权重,优化深度聚类模型输出层的神经元权重,有效解决深度聚类模型的输出不够准确的问题。
22、在一些可以实现的实施方式中,根据训练好的所述第三深度聚类模型确定所述原始数据的一个或多个第三分类。以此,有效解决深度聚类模型输出不够准确的问题。
23、第二方面,本技术实施例提供一种深度聚类的方法,第一深度聚类模型的输出层包括多个第一神经元,多个第一神经元用于输出原始数据的多个第一分类,方法包括:获得多个第一神经元输出的多个第一分类;在多个目标分类对应的数据之间的相似性满足聚合条件的情况条件下,将第一深度聚类模型的输出层的多个目标神经元进行聚合,得到第二深度聚类模型;多个目标分类为多个第一分类中的至少两个,目标神经元为多个第一神经元中输出目标分类的第一神经元,第二深度聚类模型的输出层包括多个第二神经元,第二神经元为目标神经元聚合后得到的神经元,第二神经元用于输出第二分类。其有益效果如第一方面所述,此处不再赘述。
24、在一些可以实现的实施方式中,在多个目标分类对应的数据之间的相似性不满足聚合条件的情况下,方法还包括:在任意一个目标分类对应的至少两个数据之间的相似性满足拆分条件的情况下,将第一深度聚类模型的输出层的目标神经元进行拆分,得到第三深度聚类模型;目标分类对应的数据包括多个数据,目标神经元为一个或多个第一神经元中输出目标分类的第一神经元,第三深度聚类模型的输出层包括一个或多个第三神经元,一个或多个第三神经元为目标神经元拆分后得到的神经元,第三神经元用于输出第三分类。
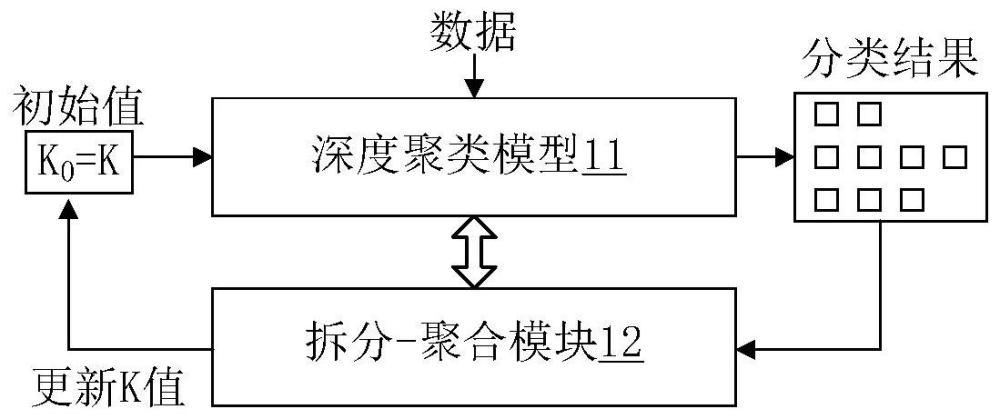
25、第三方面,本技术实施例提供一种深度聚类的装置,包括:用于执行如第一方面的方法,包括:第一深度聚类模型,用于输出一个或多个第一神经元输出的一个或多个第一分类;第一深度聚类模型的输出层包括一个或多个第一神经元,一个或多个第一神经元用于输出原始数据的一个或多个第一分类;拆分-聚合模块,用于在目标分类对应的至少两个数据之间的相似性满足拆分条件的情况下,将第一深度聚类模型的输出层的目标神经元进行拆分,得到第二深度聚类模型;目标分类为一个或多个第一分类中的至少一个,目标分类对应的数据包括多个数据,目标神经元为一个或多个第一神经元中输出目标分类的第一神经元,第二深度聚类模型的输出层包括多个第二神经元,多个第二神经元为目标神经元拆分后得到的神经元,第二神经元用于输出第二分类。其有益效果如第一方面,此处不在赘述。
26、第四方面,本技术实施例提供一种深度聚类的装置,用于执行如第二方面的方法,包括:第一深度聚类模型,用于输出一个或多个第一神经元输出的一个或多个第一分类;第一深度聚类模型的输出层包括一个或多个第一神经元,一个或多个第一神经元用于输出原始数据的一个或多个第一分类;拆分-聚合模块,用于在多个目标分类对应的数据之间的相似性满足聚合条件的情况下,将第一深度聚类模型的输出层的多个目标神经元进行聚合,得到第二深度聚类模型;多个目标分类为多个第一分类中的至少两个,目标神经元为多个第一神经元中输出目标分类的第一神经元,第二深度聚类模型的输出层包括多个第二神经元,第二神经元为目标神经元聚合后得到的神经元,第二神经元用于输出第二分类。
27、第五方面,本技术实施例提供一种深度聚类的系统,系统包括:智能设备,用于采集图片数据、文本数据、语音数据、医学影像或视频数据;深度聚类的装置,用于执行如第一方面任意一项的方法,或执行如第二方面任意一项的方法,对图片数据、文本数据、语音数据、医学影像或视频数据进行聚类。其有益效果如第一方面,此处不在赘述。
28、第六方面,本技术实施例提供一种计算设备,计算设备包括处理器和存储器;处理器用于执行存储器中存储的指令,以使得计算设备执行如第一方面任意一项的方法,或执行如第二方面任意一项的方法,。其有益效果如第一方面,此处不在赘述。
29、第七方面,本技术实施例提供一种计算设备集群,包括至少一个计算设备,每个计算设备包括处理器和存储器;至少一个计算设备的处理器用于执行至少一个计算设备的存储器中存储的指令,以使得计算设备集群执行如第一方面任意一项的方法,或执行如第二方面任意一项的方法。
30、第八方面,本技术实施例提供一种包含指令的计算机程序产品,当指令被计算设备集群运行时,使得计算设备集群执行如第一方面任意一项的方法,或执行如第二方面任意一项的方法。其有益效果如第一方面,此处不在赘述。
31、第九方面,本技术实施例提供一种计算机可读存储介质,包括计算机程序指令,当计算机程序指令由计算设备集群执行时,计算设备集群执行如第一方面任意一项的方法,或执行如第二方面任意一项的方法。其有益效果如第一方面,此处不在赘述。
- 还没有人留言评论。精彩留言会获得点赞!