一种文本匹配方法、装置、系统及存储介质与流程
本技术涉及自然语言处理,特别涉及一种文本匹配方法、装置、系统及存储介质。
背景技术:
1、文本匹配是自然语言处理中的一个重要任务,在搜索引擎、智能问答、知识检索、信息流推荐等应用系统中起核心支撑作用。例如,用户向具备智能问答功能的设备询问一个问题,该问题对应的文字信息即为待匹配文本,而用户询问的问题与设备数据库存储的标准问题通常是存在差异的,因此,设备需要从数据库中寻找与该待匹配文本相似度最高的标准问题,而设备从数据库中寻找与该待匹配文本相似度最高的标准问题的过程就是一种典型的文本匹配过程。
2、现有的文本匹配方案大多只考虑文本对之间的关系,忽略了与文本相关的上下文信息,在有些情况下,文本匹配的准确性不高,因此,如何提供一种文本匹配方法,用以结合候选文本上下文信息提升文本匹配准确性,是一亟待解决的技术问题。
技术实现思路
1、本技术提供一种文本匹配方法、装置、系统及存储介质,用以提高文本匹配准确性。
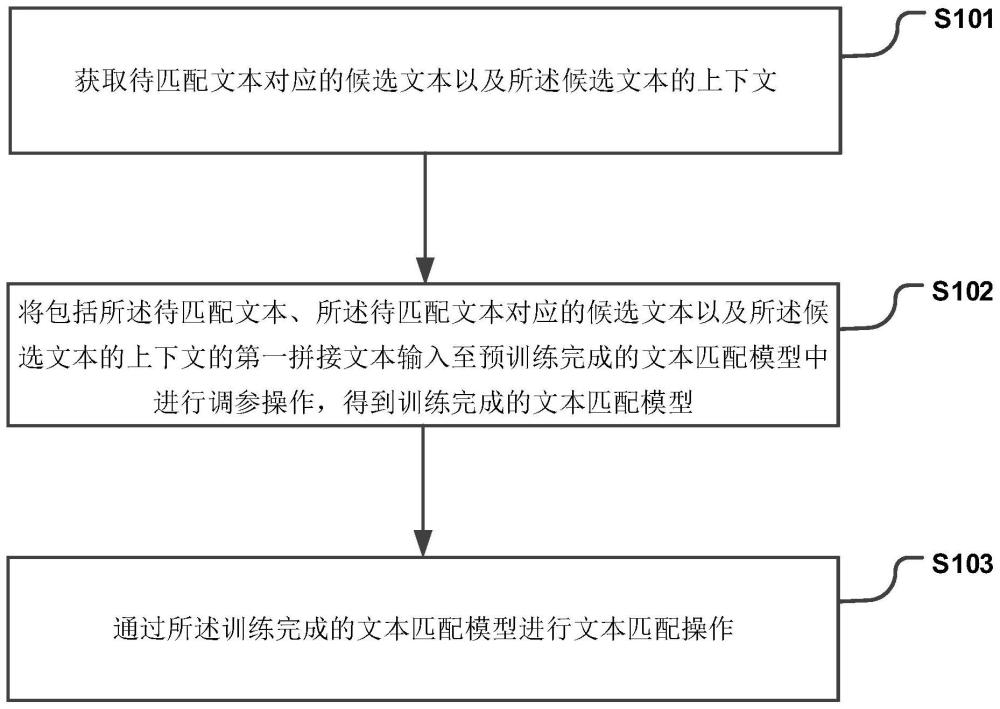
2、本技术提供一种文本匹配方法,包括:
3、获取待匹配文本对应的候选文本以及所述候选文本的上下文;
4、将包括所述待匹配文本、所述待匹配文本对应的候选文本以及所述候选文本的上下文的第一拼接文本输入至预训练完成的文本匹配模型中进行调参操作,得到训练完成的文本匹配模型;
5、通过所述训练完成的文本匹配模型进行文本匹配操作。
6、本技术的有益效果在于:能够通过待匹配文本、所述待匹配文本对应的候选文本以及候选文本的上下文组成的第一拼接文本输入至预训练完成的模型中进行调参操作,从而在文本匹配模型的训练过程中,将候选文本的上下文加入文本匹配模型的语义数据集中,从而使得训练完成的文本匹配模型在进行文本匹配时,可以结合候选文本的上下文信息进行文本匹配,提高了文本匹配的准确性。
7、在一个实施例中,所述预训练完成的文本匹配模型的预训练过程如下:
8、将用于记录开源语义的语义推理数据集中的第一文本,与第一文本匹配的第二文本,以及填充字段三者进行拼接以形成第二拼接文本,其中,所述开源语义的语义推理数据集是从预设开源网站获取的,所述与第一文本匹配的第二文本包括第一标签,所述第一标签用于表征所述与第一文本匹配的第二文本为所述第一文本的正例文本或所述第一文本的负例文本,所述第一文本的正例文本为与第一文本词汇级别相似度大于第一相似度且与第一文本语义相似度大于第二相似度的文本,所述第一文本的负例样本为与第一文本语义不同的文本;
9、将所述第二拼接文本输入至预先构建的深度学习模型中进行预训练,以得到预训练完成的文本匹配模型。
10、在一个实施例中,所述获取待匹配文本对应的候选文本以及所述候选文本的上下文,包括:
11、在获取到所述待匹配文本之后,根据所述待匹配文本进行检索以获取所述待匹配文本对应的候选文本,其中,所述待匹配文本对应的候选文本包含第二标签,所述第二标签用于表征所述待匹配文本对应的候选文本为所述待匹配文本的正例文本或所述待匹配文本的负例文本,所述待匹配文本的正例文本为与待匹配文本词汇级别相似度大于第一相似度且与待匹配文本语义相似度大于第二相似度的文本,所述待匹配文本的负例文本为与待匹配文本语义不同的文本;
12、获取与所述待匹配文本对应的候选文本相关的文本作为所述候选文本的上下文。
13、在一个实施例中,所述将包括所述待匹配文本、所述待匹配文本对应的候选文本以及所述候选文本的上下文的第一拼接文本输入至预训练完成的文本匹配模型中进行调参操作,得到训练完成的文本匹配模型,包括:
14、使用包含中英文词典的分词器对所述第一拼接文本进行分词操作;
15、将分词结果标识列表输入至预训练完成的文本匹配模型中;
16、根据所述预训练完成的文本匹配模型的输出确定分类概率向量;
17、根据所述分类概率向量确定预训练完成的文本匹配模型的损失;
18、根据所述预训练完成的文本匹配模型的损失更新所述预训练完成的文本匹配模型的参数。
19、在一个实施例中,当所述候选文本上下文不包括音频信息和图像信息时,所述根据所述预训练完成的文本匹配模型的输出确定分类概率向量,包括:
20、从预训练完成的文本匹配模型的输出中提取待匹配文本分类结果的词嵌入输入到分类器中;
21、获取分类器输出的归一化之后的分类概率向量。
22、在一个实施例中,当所述候选文本上下文包括音频信息或图像信息时,所述根据所述预训练完成的文本匹配模型的输出确定分类概率向量,包括:
23、从预训练完成的文本匹配模型的输出中提取待匹配文本分类结果的词嵌入;
24、将所述上下文中的音频特征或图像特征与所述词嵌入进行融合以得到融合特征向量;
25、将所述融合特征向量输入到分类器中;
26、获取分类器输出的归一化之后的分类概率向量。
27、在一个实施例中,所述根据所述分类概率向量确定预训练完成的文本匹配模型的损失,包括:
28、通过交叉熵损失函数计算分类概率向量和标注的相似度标签的差距;
29、确定所述分类概率向量和标注的相似度标签的差距为所述预训练完成的文本匹配模型的损失。
30、本技术还提供一种文本匹配装置,包括:
31、获取模块,用于获取待匹配文本对应的候选文本以及所述候选文本的上下文;
32、调参模块,用于将包括所述待匹配文本、所述待匹配文本对应的候选文本以及所述候选文本的上下文的第一拼接文本输入至预训练完成的文本匹配模型中进行调参操作,得到训练完成的文本匹配模型;
33、匹配模块,用于通过所述训练完成的文本匹配模型进行文本匹配操作。
34、在一个实施例中,所述预训练完成的文本匹配模型的预训练过程如下:
35、将用于记录通用语义的语义推理数据集中的第一文本,与第一文本匹配的第二文本,以及填充字段三者进行拼接以形成第二拼接文本,其中,所述与第一文本匹配的第二文本包括第一标签,所述第一标签用于表征所述与第一文本匹配的第二文本为所述第一文本的正例文本或所述第一文本的负例文本,所述第一文本的正例文本为与第一文本词汇级别相似度大于第一相似度且与第一文本语义相似度大于第二相似度的文本,所述第一文本的负例样本为与第一文本语义不同的文本;
36、将所述第二拼接文本输入至预先构建的深度学习模型中进行预训练,以得到预训练完成的文本匹配模型。
37、在一个实施例中,所述获取模块,包括:
38、第一获取子模块,用于在获取到所述待匹配文本之后,根据所述待匹配文本进行检索以获取所述待匹配文本对应的候选文本,其中,所述待匹配文本对应的候选文本包含第二标签,所述第二标签用于表征所述待匹配文本对应的候选文本为所述待匹配文本的正例文本或所述待匹配文本的负例文本,所述待匹配文本的正例文本为与待匹配文本词汇级别相似度大于第一相似度且与待匹配文本语义相似度大于第二相似度的文本,所述待匹配文本的负例文本为与待匹配文本语义不同的文本;
39、第二获取子模块,用于获取与所述待匹配文本对应的候选文本相关的文本作为所述候选文本的上下文。
40、在一个实施例中,所述调参模块,包括:
41、分词子模块,用于使用包含中英文词典的分词器对所述第一拼接文本进行分词操作;
42、输入子模块,用于将分词结果标识列表输入至预训练完成的文本匹配模型中;
43、第一确定子模块,用于根据所述预训练完成的文本匹配模型的输出确定分类概率向量;
44、第二确定子模块,用于根据所述分类概率向量确定预训练完成的文本匹配模型的损失;
45、更新子模块,用于根据所述深度学习模型的损失更新所述预训练完成的文本匹配模型的参数。
46、在一个实施例中,当所述候选文本上下文不包括音频信息和图像信息时,所述第一确定子模块用于:
47、从预训练完成的文本匹配模型的输出中提取待匹配文本分类结果的词嵌入输入到分类器中;
48、获取分类器输出的归一化之后的分类概率向量。
49、在一个实施例中,当所述候选文本上下文包括音频信息或图像信息时,所述第一确定子模块用于:
50、从预训练完成的文本匹配模型的输出中提取待匹配文本分类结果的词嵌入;
51、将所述上下文中的音频特征或图像特征与所述词嵌入进行融合以得到融合特征向量;
52、将所述融合特征向量输入到分类器中;
53、获取分类器输出的归一化之后的分类概率向量。
54、在一个实施例中,所述第二确定子模块用于:
55、通过交叉熵损失函数计算分类概率向量和标注的相似度标签的差距;
56、确定所述分类概率向量和标注的相似度标签的差距为所述预训练完成的文本匹配模型的损失。
57、本技术还提供一种文本匹配系统,包括:
58、至少一个处理器;以及,
59、与所述至少一个处理器通信连接的存储器;其中,
60、所述存储器存储有可被所述至少一个处理器执行的指令,所述指令被所述至少一个处理器执行以实现上述任意一项实施例所记载的文本匹配方法。
61、本技术还提供一种计算机可读存储介质,当存储介质中的指令由文本匹配系统对应的处理器执行时,使得文本匹配系统能够实现上述任意一项实施例所记载的文本匹配方法。
62、本技术的其它特征和优点将在随后的说明书中阐述,并且,部分地从说明书中变得显而易见,或者通过实施本技术而了解。本技术的目的和其他优点可通过在所写的说明书、权利要求书、以及附图中所特别指出的结构来实现和获得。
63、下面通过附图和实施例,对本技术的技术方案做进一步的详细描述。
- 还没有人留言评论。精彩留言会获得点赞!