一种基于稀疏特征选择的多视角人脸识别系统
1.本发明涉及人脸识别技术领域,尤其涉及针对高维人脸图像数据的多视角低维子空间学习模型。
背景技术:
2.在人脸识别领域,通常数据的维度会非常高,因而带来“维度灾难问题”。进一步的,随着传感器技术的发展,可以通过不同类型的传感器采集到不同类型的人脸数据,进一步加重了维度灾难问题。因此,如何有效的学习到多视角高维人脸数据的低维子空间表示,并以此提高人脸识别系统的识别性能,成为该领域的热点研究问题。
3.一个最直接的处理人脸多视角高维数据的方法是将所有视角数据拼接,并送入单视角的降维方法中获得多视角数据的低维子空间表示,如主成分分析(pca)、稀疏主成分分析(spca)局部保持投影(lpp)等,同时随着深度卷积神经网络的发展,还可以采用1-d卷积神经网络实现降维。但这样的做法忽略了各视角之间的特性,并且没有考虑噪声视角对低维子空间学习的副作用,往往很难取得良好的结果。
4.为了更好的处理人脸多视角高维空间数据,近年来发展了大量的多视角降维方法,其中最为经典的方法就是典型相关分析(cca)。cca致力于将两个视角投影到一个低维子空间中,在这个空间中各视角有着最大的相关性。除此之外还有多视角谱嵌入(mse),多视角协同降维方法(mcdr)等,都在学习多视角低维子空间中取得了良好的结果。然而,上述方法都存在下边两个问题:首先是在子空间学习中将所有的视角都放入学习过程中去;其次是通常对投影矩阵施加正交约束,由此限制了投影矩阵的灵活性,从而限制了子空间的辨识能力。而本发明可解决上述两个问题,可同时实现稀疏视角选择与特征选择,与此同时,赋予了投影矩阵更高的灵活性以学习到更好的低维子空间,由此可以学习到多视角人脸数据在低维子空间中更有效的表征。
技术实现要素:
5.针对高维多视角人脸数据子空间学习中的噪声视角及特征问题,本发明利用两种不同的范数组合以实现稀疏视角选择与特征选择,进一步的,通过引入恢复矩阵放松对投影矩阵的正交约束,从而灵活的学习到多视角低维子空间,以提高人脸识别系统的识别能力。
6.本发明在优化过程中设计了一种坐标下降法来交替优化投影矩阵和恢复矩阵。首先引入两个辅助矩阵对原有的目标函数进行等价转换,使其更易求解。进一步的,针对固定恢复矩阵,将原有问题转化为仅包含投影矩阵的子问题,从而直接得到当前迭代中投影矩阵的闭解,进而固定投影矩阵,求得恢复矩阵在当前迭代的最优解。最后,测试样本可通过学习的最优投影矩阵映射到低维子空间,获取有效的特征表征。
7.本发明可以获得多视角高维空间中的低维特征表示,从而应用到不同的任务中去,如无监督聚类任务或者是有监督分类任务。通过在人脸数据集的大量实验及分析,验证
了所提方法的有效性。实验结果表明所提方法可以在无监督场景及有监督场景上取得优异的性能。
8.本发明有益的效果是:通过设计一种基于稀疏特征选择的多视角人脸识别系统,可以将噪声视角与噪声特征对多视角高维子空间学习的负面影响降至最低,同时通过放松对投影矩阵的正交约束,可以有效的提升其灵活性,从而获取更有效的低维子空间特征表征,并处理不同场景的人脸识别任务,应用广泛。
附图说明
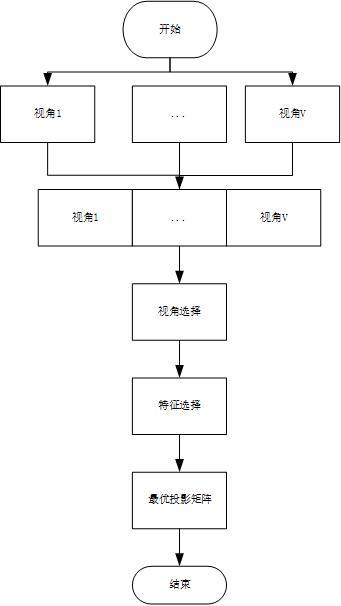
9.本发明整体流程图见附件图1
具体实施方式
10.下面结合附图和实例对本发明作进一步介绍:
11.步骤1:输入数据集其中n为样本总数,xv为第v个视角的数据,v为视角总数,dv为第v个视角的维度。
12.步骤2:通过投影矩阵将多视角数据矩阵投影至低维子空间,同时采用f范数对投影矩阵进行组结构稀疏约束,采用的f范数为:其中是矩阵pv的第i行,是pv的第i行第j列元素。
13.步骤3:采用l21范数对投影矩阵进行行稀疏约束,所采用的l21范数为:
14.步骤4:引入恢复矩阵将低维子空间恢复至原始空间,通过最小误差的方式构造目标函数,仅对恢复矩阵r进行正交约束r
t
r=id,而不对投影矩阵进行正交约束,因而使得投影矩阵学习低维子空间时更具灵活性,从而提升低维子空间的辨识能力,优化目标函数具体定义为:其中id为维度为d的对角矩阵,t为矩阵转置操作,λ1、λ2分别为两个非负正则参数,用以控制两个范数的惩罚强度。
15.步骤5:该目标函数的求解优化可以通过坐标下降法解决,首先通过引入两个辅助矩阵a和b对(3)进行等价转化:
其中,diag()为对应矩阵的对角元素,ε是一个无穷小的数。
16.针对问题(4),固定投影矩阵p优化恢复矩阵r:对问题(4)针对p求偏导并使其为0,可得:由(6)可以得到p在当前迭代的闭解:p=(x
t
x+λ1a+λ2b)-1
x
t
xr
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(7)
17.固定投影矩阵p优化恢复矩阵r:当p固定时,问题(4)可以变为:则r的最优解为r=u
′v′
t
,其中u
′
、v
′
t
由svd分解得到,即x
t
xp=u
′
σv
′
t
。
18.步骤6:测试未知数据,一旦学习得到投影矩阵p,可以通过(9)得到测试样本的低维空间表示z:z=xp
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(9)并进一步应用至无监督场景、有监督场景的不同下游任务,即采用谱聚类方法获得聚类结果,或者采用最近邻方法获得分类结果。实验设计
19.实验数据集选取:实验选择人脸数据集orl进行实验。orl包含40个测试者,每个测试者各取10张不同角度的灰度人脸图像,共400张。针对灰度图像,进一步的提取lbp特征(3304维),gabor特征(6750维),联合原始的像素强度(4096维)特征形成高维多视角数据集。
20.我们将子空间的维度d的搜索范围设置为[35,50,100,160,200],将两个正则参数λ1、λ2的搜索范围分别设置为[0.05,0.1,0.2,0.4,0.8,1.6,3.2,6.4,10,100]和[0.01,0.1,1,10,100]。所有的实验都在搭载xeon e5-2620 cpu,64gb内存,windows server 2012r2系统和matlab上完成。
[0021]
对于无监督聚类任务,随机选取80%用以训练,剩余样本用于调节参数以获取最优性能。对于有监督分类任务,随机选取不同比例的样本用以训练,剩余样本用以测试。所有结果均为独立实验30次后的平均结果。
实验结果
[0022]
表1为所提方法在orl数据集上的三个聚类评价指标的结果,三个指标分别为acc,f-score和ri,最好结果均用黑体标出。
[0023]
表1orl数据集聚类任务下不同算法的聚类结果
[0024]
从表1可以看出,所提方法在三个指标中均取得了最优结果,显示出了良好的特征表征能力。导致该种实验表现的原因是所提方法同时考虑到了噪声视角及噪声特征对子空间学习的负面影响,在学习过程种仅选择了最具信息量的视角及特征参与子空间学习,从而保证了低维子空间的特征表示能力。
[0025]
表2为有监督任务场景下,在不同比例的标签训练样本情况下,orl的识别准确率acc结果,最好的结果已使用粗体标出。表2有监督分类任务下不同算法的accuracy
[0026]
表2的结果表明所设计的mvdrhsfs可以在不同比例的训练数据中均达到最优的识别结果;同时也可以看出,识别的精度也会随着训练数据的增加而变化,进一步说明了监督信号的重要性。相较于单视角方法pca,spca和lpp,所设计的mvdrhsfs可以针对各视角的特性采用对应的投影子矩阵进行视角选择,从而达到剔除噪声视角的结果;相较于多视角降维方法mse和mcdr,所设计方法可以进行稀疏特征选择,从而剔除掉噪声特征,使得子空间
的特征表征能力更强。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1