一种基于自适应池化方式的图像分类方法
1.本发明涉及模式识别、深度学习等相关技术领域,具体地,是一种使用了自适应池化方式的图像分类方法。
背景技术:
2.随着深度学习的快速发展,深度神经网络能够在较为困难的学习任务上取得出色的表现,其中卷积神经网络一般会利用池化的方法来减小激活映射的大小,池化层的引入是仿照人的视觉系统对视觉输入对象进行降维和抽象,这个过程对于增加接受域和减少后续卷积的计算需求是至关重要的,池化操作的一个重要特性是最小化与初始激活映射相关的信息损失,并且不会对计算和内存开销造成重大影响,由于池化层会不断的减小数据的空间大小,因此参数量和计算量也会下降,在一定程度上也控制了过拟合。
3.为此,池化层成为当前卷积神经网络中常用的组件之一,用于模仿人的视觉系统对数据进行降维,能够用更高层次的特征表示图像,池化层一般的操作有:最大值池化、均值池化、随机池化、中值池化等等。其中最大值池化和均值池化是最常见并且应用最多的池化操作,最大值池化在前向传播过程中,选择图像区域中特征点的最大值作为该区域池化后的值,最大值池化的优点在于它能学习到图像的边缘和纹理结构;均值池化在前向传播过程中,选择图像区域中所有特征点的均值作为该区域池化后的值,它的优点是可以减小估计均值的偏移,更好的捕捉背景特征。
4.尽管最大值池化和均值池化都能在卷积神经网络中有较好的表现,但是由于最大值池化永远只会考虑区域中的最大值,而均值池化永远只会考虑区域的平均值,忽略了其它值的影响和作用,比如说该区域内的第二个或第三个最大的特征值,从而可能导致保留的信息不够准确,在减少激活映射中也可能会丢失更多的信息。
技术实现要素:
5.本发明的目的是为了解决现有技术中的缺点,旨在提出的一种基于自适应池化方式的图像分类方法,能够自适应的选择每个区域内对应的池化输出值,弥补了最大值池化和均值池化只能进行选取最大值和均值的缺点,在增加接受域和减少后续卷积计算的同时,能够保留更多的信息。
6.为了实现上述目的,本发明采用了如下的技术方案,
7.一种基于自适应池化方式的图像分类方法,所述方法包括以下步骤:
8.步骤1:获取数据集并定义模型,初始化自适应池化层的α值;
9.步骤2:定义优化器、损失函数和学习率衰减策略,设定超参数大小,包括学习率、迭代次数、批大小、控制α更新的λ和ξ;
10.步骤3:将训练集送入模型,开始迭代训练,迭代次数设为epoch;
11.步骤3-1:神经网络前向传播,当经过第i层池化层时,将当前第i层的输入特征图通过给定的卷积核尺寸k
0.×k1.、填充大小p和步长大小s,使用滑动窗口的操作,提取出滑
动的n个局部区域块,记为i=[x1,x2,...,xn,],其中,每个局部区域块的大小为k
0.×k1.,其中一个区域内的特征值记为xi={x1,x2,...,x
t
},t=k
0.×k1.;
[0012]
步骤3-2:若epoch=1,则n个局部区域块使用初始化后的α值,否则使用上轮迭代后的α值;
[0013]
步骤3-3:n个局部区域块,每个局部区域块特征值为xi={x1,x2,...,x
t
},通过均值、方差和自由度计算得到n个与之对应的t分布,将其经过仿射变换得到预调整值α
′
,由α和两个超参数λ、ξ进行更新α大小;
[0014]
步骤3-4:n个局部区域块,每个局部区域块特征值为xi={x1,x2,...,x
t
},结合更新后的α值,经过自适应池化方式后得到池化后的特征值bi,bi可以由α值控制选择出xi中的任意一个特征值,最后该自适应方式的输出为b=[b1,b2,...,bn,];
[0015]
步骤3-5:将该自适应输出b=[b1,b2,...,bn,],经由滑动窗口的逆操作,折叠后还原回特征图的张量形式,得到该层池化层的输出特征图;
[0016]
步骤4:前向传播结束后,经由分类器对模型输出的特征进行分类,计算损失并反向传播,直至迭代结束;
[0017]
其中,在步骤3-1中,第i层的输入特征图的大小为[n,c,w,h],其中n为batch size的大小,c为特征图的通道数,w和h为特征图的尺寸;根据卷积核尺寸k
0.×k1.、填充大小p和步长大小s,每个通道上的特征图大小,经由滑动窗口的方式得到n个k
0.×k1.大小的局部区域块,其中:
[0018][0019]
其中,i∈{0,1},且spatialsiez
0.=w,spatialsiez
1.=h;每个通道上形成的n个局部区域块分别对应有一个α值。
[0020]
其中,在步骤3-4中,所述的自适应池化方法为:
[0021][0022]
其中,每个局部区域块的特征值为x={x1,x2,...,x
t
},t=k
0.×k1.,b(α)为该局部区域块池化后的结果,α为控制区域内自适应池化程度的参数,并赋有初始值。
[0023]
其中,在步骤3-3中,在神经网络第一轮结束之后,对于池化层的输入特征图,展开为n个局部区域块,每个局部区域块得到与之对应的t分布,通过对其均值μ、方差σ及自由度n进行仿射变换后,得到新的预调整值α
′
。
[0024]
其中,在步骤3-3中,能动态调整α值,关键在于获得预调整值α
′
,α
′
由均值μ、方差σ及自由度n进行仿射变换后获得,仿射变换的方式通过线性插值的方法得到:
[0025]
在一个确定的自由度n时,有:
[0026]
α
′
=w
11
α
′
11
+w
12
α
′
12
+w
21
α
′
21
+w
22
α
′
22
,
[0027]
其中,且σ1、σ2、μ1、μ2、α
′
11
、α
′
12
、α
′
21
、αv2′
为根据训练数据反复实验所得到的结果。
[0028]
其中,在步骤3-3中,经由仿射变换后得到的预调整值α
′
,需要经过两个超参数λ和
ξ控制最终进行α值的更新,更新控制方式为:
[0029]
α=λα+ξα
′
,
[0030]
其中,λ,ξ∈[0,1],且λ+ξ=1。
[0031]
其中,在步骤3-5中,将每个局部区域块进行池化后,将池化后的结果按照逆向展开的方式,将所有局部区域块的特征点,按照展开时的空间位置关系,重新折叠回特征图的张量形式,该形式也即是自适应池化层最终的输出结果。
[0032]
其中,在步骤1中,α在网络初始进行训练时设有初始值,根据所述的自适应池化方法,其有如下性质:
[0033][0034][0035][0036]
因此当初始值为趋于0或无穷大时,初始化的池化方式近似于平均池化或最大值池化的方式,当随着不断动态调整α值时,池化的输出选择也会在不断发生改变,通过控制α的值,从而可以选择区域内任意的一个特征点进行输出。
[0037]
其中,在步骤3-3中,更新α时存在两种特殊形式:(1)当λ=0,ξ=1时,即将仿射变换后得到的预调整值α
′
直接作为新的α值;(2)当λ=1,ξ=0时,即整个模型都只使用α的初始值进行训练和测试,不进行α的动态更新:若α的初始值趋于0时,表示模型中一直使用均值池化的方式;若α的初始值趋于正无穷时,表示模型中一直使用最大值池化的方式。
[0038]
其中,在步骤3-3中,自由度n由当前池化层所给定的卷积核尺寸大小决定,即:
[0039]
n=k
0.×k1.,
[0040]
其中k
0.×k1.为池化层的卷积核尺寸。
[0041]
上述方案中,当α趋于0时,b(α)相当于均值池化;当α趋于正无穷时,b(α)相当于最大值池化。
[0042]
优选的,α的初始值可以选择为趋于0的值或是一个较大的正值,对应为初始均值池化或是最大值池化。
[0043]
优选的,对于更新α的值的两个超参数,可以选择为λ=0,ξ=1,即为使用预调整的α
′
值更新α值;或者选择为λ=1,ξ=0,即为不使用动态更新的的方式,相当于使用均值池化或是最大值池化,因此自适应池化兼容均值池化和最大值池化的方法,其可选择性和可操作性更强。
[0044]
优选的,可以将不同通道的同一个位置所提取出的局部区域块共享一个α值,进一步减少参数的使用。
[0045]
优选的,自适应池化的方式除了可以应用于图像分类任务,同样可以应用于视觉问答任务和图像标注任务等等。
[0046]
与现有的技术相比,本发明具有如下优点和有益效果:
[0047]
1、本发明可以弥补最大池化和均值池化的缺点,通过控制α的值从而可以有选择的输出局部区域内特征点的任意一个值,也可以输出整个局部区域内的均值,避免了在整个特征图上只能选择进行最大值或者均值的输出,导致输出信息不准确等问题。
[0048]
2、本发明也可以兼容最大值池化和均值池化方法,给定初始值α,当α趋于0时,自
适应池化等同于均值池化;当α趋于正无穷时,自适应池化等同于最大池化;当不进行参数α的更新时,相当于整个模型在使用最大池化或者均值池化,有可选择性和可操作性更强的特点。
[0049]
3、本发明综合考虑了图像的整体数据特征和纹理信息,其观察的信息和对输出的选择更加全面,并可以直接代替任何最大池化和均值池化等池化方式的网络中,具有可移植性。
[0050]
4、本发明能够自主学习α值,在不同的数据集和不同的训练方法下,都可以学习出较为合适的池化方式,不需要额外的人为干预,同时避免了传统模型中只能采用固定的一种池化方式。
[0051]
5、本发明可以适应不同的深度学习任务,除了可以适应不同的图像分类任务,例如二分类、多分类任务等等;还可以在其它任务上进行使用,例如视觉问答任务、图像标注任务等等。
[0052]
6、本发明可以解决相关技术在图像分类任务存在分类正确率低的问题,可以在激活映射中保留更多的信息,显著提高了分类的准确性和鲁棒性,同时也可以对数据进行降维,达到减少运算量的目的。
附图说明
[0053]
为了更清楚地说明本发明实施例中的技术方案,下面将对实施例或现有技术描述中所需要实用的附图作简单地介绍。
[0054]
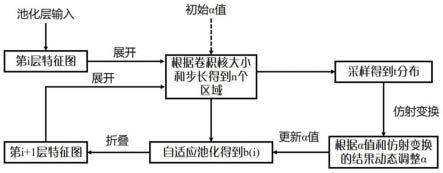
图1为本发明的自适应池化方式的算法框架;
[0055]
图2为本发明的自适应池化方式的算法流程图;
[0056]
图3为本发明的自适应池化方式与最大值池化、均值池化的对比示意图;
[0057]
图4为本发明的自适应池化中特征图的变化过程。
具体实施方式
[0058]
下面结合附图对本发明作进一步的详细说明。以下实施例将有助于本领域的技术人员进一步理解本发明,但不以任何形式限制本发明。应当指出的是,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例,对本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变化和改进。这些都属于本发明的保护范围。
[0059]
实施例:如图1和图2所示为一种基于自适应池化方式的图像分类方法,该方法在整个模型训练中的过程具体包括:
[0060]
(1)初始化实验迭代次数为k,i=1;
[0061]
(2)模型中所有池化层层数为m,j=1,模型前向传播,直到第j层池化层;
[0062]
(3)通过池化层所给定的卷积核尺寸k
0.×k1.、填充大小p和步长s,使用滑动窗口的方式,将池化层的输入特征图,展开为n个局部区域块,其中,
[0063][0064]
其中i∈{0,1},且spatialsiez
[i]
为特征图的尺寸,若迭代次数i=1,则需要初始
化α值;
[0065]
(4)若迭代次数i=1,则直接使用自适应池化的方式得到每个局部区域块的输出,自适应池化的方式为:
[0066][0067]
其中,x={x1,x2,...,x
t
},x为该局部区域块所对应的数据;
[0068]
(5)若迭代次数i》1,则判断是否需要更新α值,若不需要更新α值,则直接使用α初始值再应用自适应池化的方式进行输出,若需要更新α值,则更新α值后再使用自适应池化的方式进行输出;
[0069]
(6)若需要更新α值,则执行步骤(7)、步骤(8)、步骤(9);否则,执行步骤(10);
[0070]
(7)将特征图通过采样每个区域后得到一系列t分布,其中自由度为卷积核的尺寸,即自由度n为:
[0071]
n=k
0.×k1.,
[0072]
其中k
0.×k1.为池化层的卷积核尺寸;
[0073]
(8)根据其采样后所得的均值μ、方差σ和自由度n计算预调整值α
′
,计算方法是通过由线性插值法得出:
[0074]
对于一个确定的自由度n而言:
[0075]
α
′
=w
11
α
′
11
+w
12
α
′
12
+w
21
α
′
21
+w
22
α
′
22
,
[0076]
其中,且σ1、σ2、μ1、μ2、α
′
11
、α
′
12
、α
′
21
、α
′
22
为在训练数据上反复训练和实验的结果。
[0077]
(9)更新α值时,控制α更新的两个超参数为λ和ξ,按照如下方式进行更新:
[0078]
α=λα+ξα
′
,
[0079]
其中,λ,ξ∈[0,1],且λ+ξ=1;若ξ>0,则需要更新;若ξ=0,则模型一直使用α初始值的方式;
[0080]
(10)将每个局部区域块通过自适应池化得到的输出,通过滑动窗口的逆操作折叠为特征图的张量形式,即该层池化层所对应的输出;
[0081]
(11)判断模型中的每层池化层是否全部执行,即判断j=m是否成立:若成立,则进入步骤(12);否则,j=j+1,返回步骤(2);
[0082]
(12)模型前向传播完毕,开始反向传播;
[0083]
(13)判断当前迭代是否执行完毕,即判断i=k是否成立:若成立,则进入步骤(14);否则,i=i+1,返回步骤(1)开启下一轮迭代;
[0084]
(14)模型训练完毕,进行模型测试,结束。
[0085]
具体的,所述的自适应池化的方式为:
[0086][0087]
其中,x={x1,x2,...,x
t
},x为该局部区域块所对应的数据,自适应池化有如下几个基本性质:
[0088][0089][0090][0091]
而最大值池化为:
[0092][0093]
即对区域内的特征点取最大值,nm为该区域内特征点的数目;
[0094]
均值池化为:
[0095][0096]
即对区域内的特征点取平均值,nm为该区域内特征点的数目;
[0097]
在自适应池化中,当α趋于正无穷时,自适应池化的结果相当于最大值池化;当α趋于0时,自适应池化的结果相当于均值池化;当α趋于负无穷时,自适应池化的结果是取区域内特征点的最小值;当α趋于其它值时,自适应池化的结果也会给出其他值,弥补了最大值池化只能选取最大值,均值池化只能选取平均值,而忽略了其它可能的特征点取值所带来的影响和作用。
[0098]
更进一步的,如图3所示,分别是使用最大值池化、均值池化和自适应池化在局部区域内池化的结果,使用卷积核尺寸为3
×
3,自适应池化的方式是兼容最大值池化和均值池化的,若将α的初始值设置为一个较大的正值或是一个接近0的值,同时不设置α的更新,则自适应池化也就可以认为是最大值池化或均值池化。
[0099]
具体的,在进行更新值α时,需要根据数据集进行计算仿射变换公式,通过预先动态的调整α初始值,经过采样分布后得到相应的均值μ和方差σ,选取最优的数据进行线性插值法得到相应的仿射变换公式,从而在训练过程中使用得到的仿射变换公式进行计算预调整值α
′
。
[0100]
更进一步的,如图4所示是一次自适应池化过程中的特征图变化过程,输入特征图会展开为n个局部区域块,每个局部区域块的大小与卷积核的大小相同,当经过自适应池化得到输出特征值后,会进行逆操作将特征值折叠回下层输入特征图的张量形式。
[0101]
在本发明的描述中,需要理解的是,除非另有说明,“n个”的含义是一个或一个以上。对于本领域的普通技术人员而言,可以具体情况理解上述术语在本发明中的具体含义;以上公开的本发明优选实施例只是用于帮助阐述本发明。优选实施例并没有详尽叙述所有的细节,也不限制该发明仅为的具体实施方式。显然,根据本说明书的内容,可作很多的修改和变化。本说明书选取并具体描述这些实施例,是为了更好地解释本发明的原理和实际应用,从而使所属技术领域技术人员能很好地理解和利用本发明。本发明仅受权利要求书及其全部范围和等效物的限制。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1