基于深度神经网络且无未来信息泄露的风速预测方法
1.本发明属于风速预测技术领域,具体的为一种基于深度神经网络且无未来信息泄露的风速预测方法。
背景技术:
2.准确的风速预测在天气预报精度的提高、气象灾害的预警以及清洁风电的发展等方面至关重要。在风电领域,准确的短期风速预测可以让运营商对风电场的整体运行进行合理调控,维持稳定的供能并降低对电网的冲击。随着国内陆上风电场向低风速区逐步发展,越来越多的风电场选址在山地区域。由于地形变化等因素的影响,山地区域容易产生尾流效应并出现流动分离再附、剪切流等复杂的流动现象。因此,为了保障山区风电场的安全平稳运行,亟需发展准确预测短期风速的方法。
3.目前常用的预测方法分为如下几类:物理方法、统计方法、人工智能方法以及混合方法。物理方法需消耗大量的计算资源与时间,在中、长期预测中表现良好,但却难以满足短期预测的时效性要求。统计方法由于其固有的线性假设,导致难以对非线性风速序列进行合理的建模及预测。人工智能方法仅使用了浅层神经网络,缺乏对风速序列深层次非线性特征的提取能力。
4.随着计算机能力的飞速发展,采用深度神经网络进行风速预测也变得切实可行。虽然基于深度学习的短期风速预测模型取得了良好的预测结果,但不可否认的是,单一的神经网络模型可能难以适用于不同的风速序列。并且,实测风速序列中存在着大量的噪音信息,这严重影响了风速预测的精度。因此,结合数据预处理方法的混合预测模型得到了广泛的发展,其中模态分解方法应用地最为广泛。数据预处理操作确实能显著降低风速的随机性与高频噪声,提高风速的可预测性以及预测模型的性能,极大地提高了风速预测的精度。但是这类混合预测模型在数据预处理时对全部的风速序列数据进行了分解,在分解后的子模态上划分训练集和测试集并建立预测模型。这意味着本应未知的测试集数据被视为已知,不可避免的造成了未来信息的泄露。而当有新数据被添加进原始风速序列数据中时,需要重新进行分解,然后再代入子模态预测模型中进行预测。但即使只在原始数据的末端增加部分新数据,分解后的子模态在序列的末端也会产生明显的变化。这部分末端数据是时序预测中最为关键的信息。这意味着在原始数据的子模态上建立的预测模型可能难以应用于新的数据,导致此类混合预测模型缺少实用性。
技术实现要素:
5.有鉴于此,本发明的目的在于提供一种基于深度神经网络且无未来信息泄露的风速预测方法,采用事后评估的方式,此方法规避了数据泄露的风险,提高了实用性。
6.为达到上述目的,本发明提供如下技术方案:
7.一种基于深度神经网络且无未来信息泄露的风速预测方法,包括如下步骤:
8.步骤1:分别风速序列数据进行数据筛选和数据预处理;根据子模态能量占比大小
筛选有效成分tc并作为预测模型的输出值;采用实时滚动分解策略对风速序列数据进行预处理以得到无信息泄露的预测模型的输入值;以输入值和输出值构建数据集;
9.步骤2:确定预测步长:按照实际的预测需求,确定需要预测的未来时间步数;
10.步骤3:构建预测模型:构建结合注意力机制的双向长短期记忆网络作为预测模型,利用数据集对预测模型进行训练和测试;
11.步骤4:风速预测:利用训练得到的预测模型预测风速,得到风速预测结果。
12.进一步,所述步骤一中,从风速序列数据中筛选出有效成分tc的方法为:
13.s1:将风速序列数据划分训练集、验证集和测试集,以划分后的数据组建三个数据组,第一个数据组包括训练集,第二个数据组包括验证集,第三个数据组包括测试集;
14.s2:对三个数据组中的风速序列数据分别进行模态分解;
15.s3:基于能量原理判断指标,选择合适的子模块得到能代表风速序列数据绝大部分能量的有效分成tci,i=1,2或3,分别表示从三个数据组的风速序列数据中筛选得到的有效分成;
16.s4:按顺序将有效成分tci进行拼接,得到预测模型的目标输出值tc。
17.进一步,所述步骤s3中,当前m个子模态能量之和大于等于原始风速序列99%的能量时,tci为前m个子模态之和,子模态的er计算方式为:
[0018][0019]
其中,er(k)表示第k个子模态的能量占比;表示第k个子模态序列;x表示风速序列数据;n表示风速序列数据x的长度。
[0020]
进一步,所述步骤一中,采用实时滚动分解策略对风速序列数据进行预处理的方法为:
[0021]
(1)确定窗口长度l:分析风速序列数据x的频谱特征,寻找频率峰值点,得到对应的周期,选择周期数作为rtrd所需的窗口长度;
[0022]
(2)确定滑动步幅s;
[0023]
(3)重构风速信号:根据窗口长度l和滑动步幅s将风速序列数据x重构为二维矩阵xr,矩阵形状为(n-l+s,l),其中,n为风速序列数据x的长度;
[0024]
(4)执行rtrd:逐行分解xr,得到无信息泄露的分解结果
[0025]
进一步,所述预测模型包括依次设置的一层输入层、两层bi-lstm网络、一层注意力层和一层全连接层。
[0026]
进一步,所述lstm网络的原理为:
[0027]ft
=σ(w
xf
x
t
+w
hfht-1
+bf)
[0028]gt
=tanh(w
xg
x
t
+w
hght-1
+bg)
[0029]it
=σ(w
xi
x
t
+w
hiht-1
+bi)
[0030]ct
=f
t
⊙ct-1
+i
t
⊙gt
[0031]ot
=σ(w
xo
x
t
+w
hoht-1
+bo)
[0032]yt
=h
t
=o
t
⊙
tanh(c
t
)
[0033]
其中,x
t
为输入向量,c
t
为长期状态,h
t
为短期状态,y
t
为输出向量;w
xf
,w
xg
,w
xi
,w
xo
分别为与x
t
连接的权重矩阵,w
hf
,w
hg
,w
hi
,w
ho
分别为与h
t-1
连接的权重矩阵,bf,bg,bi,bo分别为四层偏置项;f
t
为遗忘门的控制器,由f
t
决定c
t-1
的哪些部分应被删除;g
t
为lstm网络的中间输出,其作用为分析x
t
与h
t-1
;i
t
为输入门的控制器,判断g
t
的哪些重要部分应被添加进c
t
;o
t
为输出门的控制器,判断应读取c
t
中的哪部分并应用到h
t
和y
t
中;σ表示激活函数。
[0034]
进一步,所述注意力层采用luong-attention模型,其计算方法为:
[0035]
score计算方法为:
[0036][0037]
注意力权重α
ts
计算方法为:
[0038][0039]
其中,和h
t
分别为编码器输出的全部隐藏状态以及最后一个隐藏状态;w表示权重矩阵;
[0040]
上下文向量计算方法为:
[0041][0042]
其中,α
ts
是注意力权重,是全部隐藏状态;
[0043]
注意力向量a
t
计算方法为:
[0044][0045]
其中,为上下文向量;h
t
为最后一个隐藏状态;wc表示将要学习的模型参数。
[0046]
进一步,将注意力向量a
t
输入到全连接层,得到风速预测结果。
[0047]
本发明的有益效果在于:
[0048]
现有的单点风速组合预测模型普遍采用了全分解的数据预处理策略,这种数据预处理策略存在数据泄露的风险,可能导致此类组合预测模型缺少工程上的实用性,因此,准确预测风速的有效成分显得更为关键和可行。考虑到实测风速中存在大量的高频噪声,这部分高频噪声是风速随机性与波动性的重要来源,而风速的低频有效成分占据了风速的绝大部分能量,本发明通过无信息泄露的数据预处理方法提取风速序列的有效成分,建立未来信息无泄漏的表达方法,是得到可靠实用的风场预测结果的前提。
[0049]
考虑到传统的组合预测模型普遍存在数据泄露问题,风速实测数据中也存在一定程度的噪音成分,本发明基于深度神经网络且无未来信息泄露的风速预测方法,采用无信息泄露的数据预处理策略的短期风速预测框架,旨在提供一种准确预测风速序列有效成分的方法。该预测方法包括数据筛选、基于实时滚动分解的数据预处理以及融合attention机制的bi-lstm神经网络(bi-lstm-attention)三部分内容,避免了数据泄露的风险,并对噪音成分进行了有效处理,且本发明方法采用事后评估,所以通过模态分解得到的真值是延迟获得的。
附图说明
[0050]
为了使本发明的目的、技术方案和有益效果更加清楚,本发明提供如下附图进行说明:
[0051]
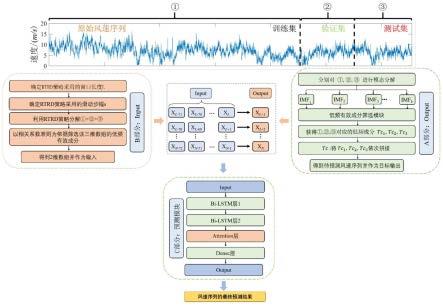
图1为本发明基于深度神经网络且无未来信息泄露的风速预测方法的原理图;
[0052]
图2为模型训练阶段、验证阶段和测试阶段(即使用阶段)数据的流动情况说明;
[0053]
图3为所有模型的单步预测曲线图。
具体实施方式
[0054]
下面结合附图和具体实施例对本发明作进一步说明,以使本领域的技术人员可以更好的理解本发明并能予以实施,但所举实施例不作为对本发明的限定。
[0055]
如图1所示,本发明基于深度神经网络且无未来信息泄露的风速预测方法,包括如下步骤。
[0056]
步骤1:分别风速序列数据进行数据筛选和数据预处理;根据子模态能量占比大小筛选有效成分tc并作为预测模型的输出值;采用实时滚动分解(real-time rolling decomposition,rtrd)策略对风速序列数据进行预处理以得到无信息泄露的预测模型的输入值;以输入值和输出值构建数据集。
[0057]
具体的,从风速序列数据中筛选出有效成分tc的方法为:
[0058]
s1:将风速序列数据划分训练集、验证集和测试集,本实施例中,风速序列数据按照6:2:2划分训练集(1~0.6n)、验证集(0.6n~0.8n)和测试集(0.8n~n),以划分后的数据组建三个数据组,第一个数据组包括训练集,第二个数据组包括训练集,第三个数据组包括测试集。
[0059]
s2:对三个数据组中的风速序列数据分别进行模态分解。采用模态分解方法对第一个数据组(1~0.6n)、第二个数据组(0.6n~0.8n)和第三个数据组(0.8n~n)范围内的风速数据进行分解,其中vmd、ssa算法需指定分解层数,而emd与iceemdan算法能自适应确定分解层数。
[0060]
s3:基于能量原理判断指标,选择合适的子模块得到能代表风速序列数据绝大部分能量的有效分成tci,i=1,2或3,分别表示从三个数据组的风速序列数据中筛选得到的有效分成。具体的,根据子模态能量占比(energy ratio,er)大小筛选有效成分tc需要的子模态数量(子模态按低频至高频的顺序排列)为:当前m个子模态能量之和大于等于原始风速序列99%的能量时,可认为tci即为前m个子模态之和。子模态的er计算方式为:
[0061][0062]
其中,er(k)表示第k个子模态的能量占比;表示第k个子模态序列;x表示风速序列数据;n表示风速序列数据x的长度。
[0063]
s4:按顺序将有效成分tci进行拼接,得到预测模型的目标输出值tc,tc是后续构建模型目标输出的数据来源,即真值。
[0064]
具体的,采用实时滚动分解策略对风速序列数据进行预处理的方法为:
[0065]
(1)确定窗口长度l:分析风速序列数据x的频谱特征,寻找频率峰值点,得到对应
的周期,选择合适的周期数作为rtrd所需的窗口长度;
[0066]
(2)确定滑动步幅s,当采取逐步预测的方式进行短期风速预测时,滑动步幅应设为1;
[0067]
(3)重构风速信号:根据窗口长度l和滑动步幅s将风速序列数据x重构为二维矩阵xr,矩阵形状为(n-l+s,l),其中,n为风速序列数据x的长度;
[0068]
(4)执行rtrd:逐行分解xr,得到无信息泄露的分解结果将每一行数据的前m个子模态相加,可以构成输入矩阵计算与tc的相关系数;利用相关系数准则判断不同分解算法下构成的最优子模态数量。
[0069]
步骤2:确定预测步长:按照实际的预测需求,确定需要预测的未来时间步数。
[0070]
步骤3:构建预测模型:构建结合注意力机制的双向长短期记忆网络(bi-lstm-attention)作为预测模型,利用数据集对预测模型进行训练和测试。具体的,本实施例中,预测模型包括依次设置的一层输入层、两层bi-lstm网络、一层注意力层和一层全连接层。
[0071]
本实施例的lstm网络采用如下方式进行t时刻隐藏状态的更新:
[0072]ft
=σ(w
xf
x
t
+w
hfht-1
+bf)
[0073]gt
=tanh(w
xg
x
t
+w
hght-1
+bg)
[0074]it
=σ(w
xi
x
t
+w
hiht-1
+bi)
[0075]ct
=f
t
⊙ct-1
+i
t
⊙gt
[0076]ot
=σ(w
xo
x
t
+w
hoht-1
+bo)
[0077]yt
=h
t
=o
t
⊙
tanh(c
t
)
[0078]
其中,x
t
为输入向量,c
t
为长期状态,h
t
为短期状态,y
t
为输出向量;w
xf
,w
xg
,w
xi
,w
xo
分别为与x
t
连接的权重矩阵,w
hf
,w
hg
,w
hi
,w
ho
分别为与h
t-1
连接的权重矩阵,bf,bg,bi,bo分别为四层偏置项;f
t
为遗忘门的控制器,由f
t
决定c
t-1
的哪些部分应被删除;g
t
为lstm网络的中间输出,其作用为分析x
t
与h
t-1
;i
t
为输入门的控制器,判断g
t
的哪些重要部分应被添加进c
t
;o
t
为输出门的控制器,判断应读取c
t
中的哪部分并应用到h
t
和y
t
中;σ表示激活函数。
[0079]
本实施例的注意力层采用luong-attention模型,其计算方法为:
[0080]
score计算方法为:
[0081][0082]
注意力权重α
ts
计算方法为:
[0083][0084]
其中,和h
t
分别为编码器输出的全部隐藏状态以及最后一个隐藏状态;w表示权重矩阵;
[0085]
上下文向量计算方法为:
[0086]
[0087]
其中,α
ts
是注意力权重,是全部隐藏状态;
[0088]
注意力向量a
t
计算方法为:
[0089][0090]
其中,为上下文向量;h
t
为最后一个隐藏状态;wc表示将要学习到的模型参数。
[0091]
最后,将注意力向量a
t
输入到全连接层,得到风速预测结果。
[0092]
步骤4:风速预测:利用训练得到的预测模型预测风速,得到风速预测结果。
[0093]
图2说明了数据在神经网络的训练阶段、验证和测试阶段是如何运行的。在图2(a)中,当构造模型的输入时,模态分解遵循实时滚动分解策略,该策略在蓝色数据窗格上进行。这种策略保证了模型的输入始终使用预测值之前的信息,即未来信息的保密性得到保证,这意味着没有信息泄露。而预测值主要是指预测风速的有效分量,用tc表示,遵循“真值”的含义。在图2(b)中,在模型训练过程中,由于数据已在完整的时间轴上收集,因此真值tc1可以在训练神经网络时通过模态分解获得。因此,可以直接计算误差并用于更新神经网络的参数。在图2(b)中,在验证和测试过程中,神经网络的参数已经确定,预测结果与真实值之间的误差tc2或tc3以延迟方式计算,而不是实时计算。这意味着误差可以在一段时间的操作后计算,并且它们仅用于证明预测的准确性。总之,无论是在训练过程中还是在验证和测试过程中,都始终坚持实时滚动分解策略,避免信息泄露是我们算法的首要原则。
[0094]
实验验证
[0095]
下面结合具体实例验证本发明基于深度神经网络且无未来信息泄露的风速预测方法。
[0096]
选取中国云南某测风塔70m高度处连续91天的10min间隔风速数据x作为输入信号,选取日期为2010.4.1~2010.6.30,共有13104组。
[0097]
一、预测结果误差评估标准
[0098]
本实施例选取了三种常用的性能指标作为衡量预测模型误差的判断标准,包括mape、mae和rmse,其定义分别如下。
[0099][0100][0101][0102]
其中:xn代表目标输出值(又称真值),代表预测值。mape、mae和rmse的值越小,预测精度越高。
[0103]
此外,定义rmse、mape、mae三个误差指标的相对提升比p
metric
,以进一步定量评价不同模型的性能表现。p
metric
的定义如下
[0104]
[0105]
其中,metric代表mape、mae和rmse三种指标,ea,eb代表模型a和模型b的预测误差。
[0106]
二、预测模型与不同模型的对比
[0107]
本实施例选择的深度学习平台为基于gpu的tensorflow 2.3,python 3.7版本,构建bi-lstm-attention模型。训练过程采用“adam”优化器,学习率lr设为0.001,损失函数选为“mean squared error”,迭代次数固定为100个epoch。模型的各层参数由人工选择与随机搜索共同确定。
[0108]
表1显示了持续模型(persistence,pr)、bp模型、gru、lstm和本发明提出的bi-lstm-attention进行了对比。表1和表2显示了不同预测模型单步预测和1-6步预测的rmse、p
mse
、mape、p
mape
、mae和p
mae
误差结果。
[0109]
表1基于vmd方法的各模型预测性能—单步预测
[0110][0111]
表2基于vmd方法的各模型预测性能—1-6步预测
[0112][0113]
从以上所有神经网络模型的对比中可以看出,本发明方法能够准确的预测占有风速序列绝大部分能量的有效成分tc,模型的单步和1-6步预测的精度均优于pr模型,且本发明所提出的bi-lstm-attention预测模型取得了最佳的预测精度,这充分证明了本发明提出的rtrd-bi-lstm-attention预测方法的有效性。具体来说,单步预测下,bi-lstm-attention预测模块相对于pr模型的精度提升比p
metric
在23.79%~32.77%之间;1-6步预测下,bi-lstm-attention预测模块相对于pr模型的精度提升比p
metric
在9.90%~18.09%之间。而当预测步长增大时,所有神经网络模型的p
metric
均有所下降,说明神经网络模型在多步风速预测时性能有所下降。
[0114]
以上所述实施例仅是为充分说明本发明而所举的较佳的实施例,本发明的保护范围不限于此。本技术领域的技术人员在本发明基础上所作的等同替代或变换,均在本发明的保护范围之内。本发明的保护范围以权利要求书为准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1