一种基于线性矩阵求解的OpenFOAM加速方法、装置、设备及介质
一种基于线性矩阵求解的openfoam加速方法、装置、设备及介质
技术领域
1.本发明属于计算流体力学领域,具体涉及一种基于线性矩阵求解的openfoam加速方法、装置、设备及介质。
背景技术:
2.openfoam是由c++编写的面向对象cfd程序库,与其他商业软件fluent、cfx等类似,它包括一系列的前处理工具、偏微分方程求解器和后处理工具,提供了一个求解器的框架,包括网格生成、有限体积离散方法、线性方程组求解、数据结构以及输入输出处理。求解的问题涉及工程、科学等领域,能够求解化学反应、湍流、传热、传递等复杂流动,还可以求解固体动力学和电磁学等问题。
3.openfoam中的线性求解性能也是人们关注的热点问题。在openfoam中,物理模型经过有限体积法离散所得到的矩阵都采用一种ldu的格式进行存储,这种格式的优点是对于稀疏矩阵,其中的大部分零元不占用额外的存储空间,较为节省空间,尤其是在非零元相对对角线成对称分布时更是如此。然而ldu矩阵在节省空间的同时,也带来了访问效率低的问题,尤其是在线性矩阵系统迭代求解过程中,由于有大量的矩阵向量乘操作,需要频繁地访问矩阵元素,进而形成了性能瓶颈。有研究表明,在算例运行过程中计算最密集的部分是线性方程组求解,占据了整个程序执行的80%左右。对于异构加速的强大运算能力程序算法特别是密集型算法还不成熟,现有技术中的求解效率较低,存储空间占用较大。
技术实现要素:
4.为了克服现有技术的缺点,本发明的目的在于提供一种基于线性矩阵求解的openfoam加速方法、装置、设备及介质,以解决现有技术中的求解效率较低,存储空间占用较大的问题。
5.为了达到上述目的,本发明采用以下技术方案实现:
6.第一方面,本发明提供一种基于线性矩阵求解的openfoam加速方法,包括:
7.步骤1:在openfoam中进行网格信息读入,生成ldu格式的矩阵;设置ldu
→
csr矩阵转化系统,在dcu中编译相关代码;
8.步骤2:通过dcu运行openfoam算例,读入算例网格信息,将原有的ldu格式的矩阵转换成csr格式的矩阵,完成矩阵向量转化;
9.步骤3:cpu拷贝传入的数据,并且将cpu端拷贝好的数据传输给dcu内存,调用dcu的内核迭代计算矩阵,收敛后输出csr格式数据;
10.步骤4:将输出的csr格式数据重新转化为openfoam识别的ldu格式数据,并将计算结果传回openfoam。
11.进一步的,所述在dcu中编译相关代码为:
12.编写ldu
→
csr格式转换的伪代码,将此伪代码转换成hip代码,并且将解算器采用
hip代码进行编写集成到dcu中。
13.进一步的,所述ldu格式的矩阵为openfoam数据储存格式,在openfoam算例文件controldict文件中添加库引用,在算例文件fvsolution文件中使用dcu解算器求解各个物理量。
14.进一步的,所述步骤2具体包括:
15.运行openfoam算例,调用dcu加速卡,在导入网格后,openfoam根据网格存储相应的ldu格式数据;对角元素和上三角下三角元素分别存储在三个向量ldumatrix.diag()、ldumatrix.upper()、ldumatrix.lower()中,上下两个三角元素的索引值共用两个索引向量;upperaddr存储了上三角元素的行索引,同时表达了下三角对应元素的列索引,loweraddr既能表达上三角元素的列索引,又能表达下三角元素的行索引;采用格式转换代码将ldu格式数据转换成csr格式储存的数据;csr格式主要通过三个数组来表示矩阵的内容,其中value为矩阵中非零元素的值,col_index存储了非零元的列索引,row_offsets存储了每行第一个非零元在value中的索引,计算每个非零元的行索引,定位非零元。
16.进一步的,所述矩阵向量转化具体为:首先遍历ldu矩阵的阶数和下三角、上三角元素的个数,计算各行有多少个非零元素,按照顺序分别插入下三角矩阵元素、对角矩阵元素和上三角矩阵元素,对每一个矩阵元素分别计算矩阵值以及其对应的索引值,返回新生成的csr格式矩阵。
17.进一步的,所述步骤3具体包括:
18.格式转换完成后,开始调用dcu加速卡中的解算器求解,所述解算器根据openfoam中的pcg或pbicg算法在dcu上进行修改,使用转换完成后的csr格式进行计算;计算完成后输出csr格式数据,并且释放dcu内存。
19.进一步的,所述步骤4中将计算结果传回openfoam后通过后处理工具查看结果,处理工具为paraview或tecplot。
20.第二方面,本发明提供一种基于线性矩阵求解的openfoam加速装置,包括:
21.矩阵生成及矩阵转换系统设置模块,用于在openfoam中进行网格信息读入,生成ldu格式的矩阵;设置ldu
→
csr矩阵转化系统,在dcu中编译相关代码;
22.算例网格信息读入模块及矩阵向量转化模块,用于通过dcu运行openfoam算例,读入算例网格信息,将原有的ldu格式的矩阵转换成csr格式的矩阵,完成矩阵向量转化;
23.矩阵迭代计算及csr格式数据输出模块,用于通过cpu拷贝传入的数据,并且将cpu端拷贝好的数据传输给dcu内存,调用dcu的内核迭代计算矩阵,收敛后输出csr格式数据;
24.矩阵格式重新转化及查看模块,用于将输出的csr格式数据重新转化为openfoam识别的ldu格式数据,并将计算结果传回openfoam。
25.第三方面,本发明提供一种计算机设备,包括存储器、处理器以及存储在所述存储器中并可在所述处理器上运行的计算机程序,其特征在于,所述处理器执行所述计算机程序时实现上述任一项所述的一种基于线性矩阵求解的openfoam加速方法。
26.第四方面,本发明提供一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现上述任一项所述的一种基于线性矩阵求解的openfoam加速方法。
27.本发明至少具有以下有益效果:
28.本发明在openfoam读入网格信息生成ldu矩阵之后,添加一个矩阵格式的转换操作,通过编译相关的代码程序,使得算法能在dcu加速卡上运行,然后通过dcu运行openfoam算例,将原有的ldu矩阵格式转化为dcu能够计算的csr矩阵格式,采用csr格式相较传统密集存储方法节省了大量空间;最后调用dcu的内核迭代计算矩阵,计算完成后将结果重新转化成openfoam识别的ldu矩阵,使得在求解过程中节省了大量的计算时间,从而提高了openfoam的求解性能,同时也为人们在gpu加速性能上提供了参考。
附图说明
29.构成本发明的一部分的说明书附图用来提供对本发明的进一步理解,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。在附图中:
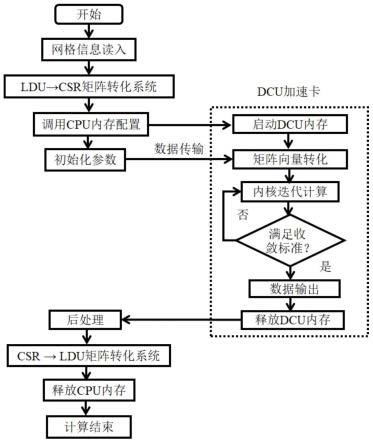
30.图1为本发明openfoam线性矩阵求解结构设计流程图;
31.图2为本发明openfoam dcu解算器编译结构图;
32.图3为本发明openfoam算例解算器配置方法图;
33.图4为本发明ldu
→
csr矩阵转换格式图;
34.图5为本发明一种基于线性矩阵求解的openfoam加速装置模块示意图。
具体实施方式
35.下面将参考附图并结合实施例来详细说明本发明。需要说明的是,在不冲突的情况下,本发明中的实施例及实施例中的特征可以相互组合。
36.以下详细说明均是示例性的说明,旨在对本发明提供进一步的详细说明。除非另有指明,本发明所采用的所有技术术语与本发明所属领域的一般技术人员的通常理解的含义相同。本发明所使用的术语仅是为了描述具体实施方式,而并非意图限制根据本发明的示例性实施方式。
37.实施例1
38.如图1所示,一种基于线性矩阵求解的openfoam加速方法,包括:
39.步骤1:在openfoam中进行网格信息读入,生成ldu格式的矩阵;设置ldu
→
csr矩阵转化系统,在dcu(deep computing unit深度计算器)中编译相关代码。
40.在dcu解算器中完成hip代码编写。
41.编译相关代码,和单纯的cpu程序不同,dcu扩展加速方法需要利用dcu设备的运算能力,必须由特定的编译器生产dcu设备端的可执行指令。因此openfoam dcu解算器集成使用一种跨框架的混合编译模型。如图2所示,扩展自openfoam标准解算器基类ldumatrix::solver的dcu解算器封装使用openfoam框架中的wmake编译,解算器使用的dcu加速hip方法使用hipcc编译。
42.在dcu加速卡中编写格式转换的hip代码,编写ldu
→
csr伪代码,具体为:首先遍历ldu矩阵的阶数和下三角、上三角元素的个数,计算各行有多少个非零元素,然后按照顺序分别插入下三角矩阵元素、对角矩阵元素和上三角矩阵元素,对每一个矩阵元素分别计算矩阵值以及其对应的索引值,然后返回新生成的csr格式矩阵,ldu
→
csr的伪代码为:
43.for i=0to nonzerotriangleelementnumber:
44.lowerrowindex=loweraddr[i];
[0045]
upperrowindex=upperaddr[i];
[0046]
rowoffsets[lowerrowindex+1]++;
[0047]
rowoffsets[upperrowindex+1]++;
[0048]
//update rowoffsets
[0049]
rowoffsets[0]=0;
[0050]
for i=0 to rownumber:
[0051]
rowoffsets[i+1]+=rowoffsets[i];
[0052]
//first insert lower triangle elements
[0053]
for i=0 to nonzerotriangleelementnumber:
[0054]
rowindex=upperaddr[i]
[0055]
colindex=loweraddr[i]
[0056]
offsets=rowoffsets[row]++;
[0057]
value[offsets]=lower[i];
[0058]
colindex[offsets]=colindex;
[0059]
//secondly insert diagonal elements
[0060]
for i=0 to rownumber:
[0061]
offsets=rowoffsets[i]++;
[0062]
value[offsets]=diag[i];
[0063]
colindex[offsets]=i;
[0064]
//thirdly insert upper triangle elements
[0065]
for i=0 to nonzerotriangleelementnumber:
[0066]
rowindex=loweraddr[i];
[0067]
colindex=upperaddr[i];
[0068]
offsets=rowoffsets[i];
[0069]
value[offsets]=upper[i];
[0070]
将此伪代码转换成hip代码,并且将解算器采用hip代码进行编写集成到dcu中。
[0071]
dcu是一款专门用户ai人工智能和深度学习的加速卡,与gpu类似,hip是dcu加速卡上的编程语言。
[0072]
步骤2:通过dcu运行openfoam算例,读入算例网格信息,将原有的ldu格式的矩阵转换成csr格式的矩阵,完成矩阵向量转化。
[0073]
ldu格式的矩阵主要为openfoam数据储存格式,openfoam实现了一个ldumatrix类来表示ldu矩阵。csr格式在稀疏矩阵中较为常见,它只保存稀疏矩阵中的非零元素和非零元素对应的列索引值以及每行首个非零元素在所有非零元中的位置偏移,这种存储方法相较传统密集存储方法节省了大量空间。
[0074]
如图3所示,在openfoam算例文件controldict文件中添加库引用,在算例文件fvsolution文件中使用dcu解算器求解各个物理量。
[0075]
运行openfoam算例,并且调用dcu异构加速卡,在导入网格后,openfoam会根据网格存储相应的ldu格式数据,其中对角元素和上三角下三角元素分别存储在三个向量(ldumatrix.diag(),ldumatrix.upper(),ldumatrix.lower())中,上下两个三角元素的
索引值共用两个索引向量,其中upperaddr存储了上三角元素的行索引,同时表达了下三角对应元素的列索引,loweraddr既能表达上三角元素的列索引,又能表达下三角元素的行索引。采用格式转换代码可以将ldu格式数据转换成csr格式储存的数据;csr格式主要通过三个数组来表示矩阵的内容,其中value为矩阵中非零元素的值,col_index存储了非零元的列索引,row_offsets存储了每行第一个非零元在value中的索引,据这个值可以计算每个非零元的行索引,从而正确定位非零元,如图4所示。
[0076]
步骤3:cpu拷贝传入的数据,并且将cpu端拷贝好的数据传输给dcu内存,调用dcu的内核迭代开始计算矩阵,判断是否满足收敛标准,如果不满足,则返回内核继续迭代,如果达到收敛,则输出csr格式数据,释放dcu内存。
[0077]
格式转换完成后,开始调用dcu异构加速卡中的解算器求解,该解算器主要根据openfoam中原有的pcg、pbicg等算法在dcu上进行修改,使用转换完成后的csr格式进行计算,节省计算时间。计算完成后输出csr格式数据,并且释放dcu内存。
[0078]
内核迭代为在dcu上运行的解算器,该算法在原有的openfoam中的pcg、pbicg等迭代算法上进行修改,使之能在dcu上运行。
[0079]
步骤4:将输出的csr格式数据重新转化为openfoam识别的ldu格式数据,并将计算结果传回openfoam,通过后处理工具查看结果。
[0080]
处理工具为:paraview、tecplot等第三方工具。
[0081]
将csr格式数据重新转化为openfoam中原有的ldu格式数据,由于openfoam中的ldu矩阵格式是openfoam特有的格式,在数据输出中需要重新转化。
[0082]
实施例2
[0083]
如图5所示,一种基于线性矩阵求解的openfoam加速装置,包括:
[0084]
矩阵生成及矩阵转换系统设置模块,用于在openfoam中进行网格信息读入,生成ldu格式的矩阵;设置ldu
→
csr矩阵转化系统,在dcu中编译相关代码;
[0085]
算例网格信息读入模块及矩阵向量转化模块,用于通过dcu运行openfoam算例,读入算例网格信息,将原有的ldu格式的矩阵转换成csr格式的矩阵,完成矩阵向量转化;
[0086]
矩阵迭代计算及csr格式数据输出模块,用于通过cpu拷贝传入的数据,并且将cpu端拷贝好的数据传输给dcu内存,调用dcu的内核迭代计算矩阵,收敛后输出csr格式数据;
[0087]
矩阵格式重新转化及查看模块,用于将输出的csr格式数据重新转化为openfoam识别的ldu格式数据,并将计算结果传回openfoam。
[0088]
实施例3
[0089]
本发明提供一种计算机设备,包括存储器、处理器以及存储在所述存储器中并可在所述处理器上运行的计算机程序,其特征在于,所述处理器执行所述计算机程序时实现实施例1所述的一种基于线性矩阵求解的openfoam加速方法。
[0090]
实施例4
[0091]
本发明提供一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现实施例1所述的一种基于线性矩阵求解的openfoam加速方法。
[0092]
本领域内的技术人员应明白,本发明的实施例可提供为方法、系统、或计算机程序产品。因此,本发明可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实
施例的形式。而且,本发明可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、cd-rom、光学存储器等)上实施的计算机程序产品的形式。
[0093]
本发明是参照根据本发明实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
[0094]
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
[0095]
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
[0096]
最后应当说明的是:以上实施例仅用以说明本发明的技术方案而非对其限制,尽管参照上述实施例对本发明进行了详细的说明,所属领域的普通技术人员应当理解:依然可以对本发明的具体实施方式进行修改或者等同替换,而未脱离本发明精神和范围的任何修改或者等同替换,其均应涵盖在本发明的权利要求保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1